Spark Select and Select-expr Deep Dive | by somanath sankaran | Analytics Vidhya | Mediumの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
この記事はcsvの読み込みに対するディープダイブの後のsparkディープダイブシリーズの3番目の記事です。
この記事はpysparkにおけるselectとfilterの表現の取り扱いについて言及しています。
- Selectとエイリアスのカラム
- フレキシブルなSelectExpr(Hiveの人たち向け)
- Pythonの力(リストの内包表現)とselectの活用
ステップ1: 入力データフレームの作成
Sparkセッションのread csvメソッドを使ってデータフレームを作成します。

ステップ2: DFにおけるSelect
ドキュメントによると、df.selectは以下を受け付けます。
- 文字列のリスト
- Columnのリスト
- エクスプレッション
- "*"(スター)
1. 文字列のリスト
Pythonの文字列オブジェクトのリストとしてカラム名を渡すことができます。
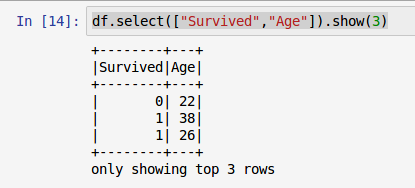
2. Columnのリスト
pyspark.sql.functionsのspark Columnクラスをインポートし、Columnのリストを渡すことができます。

4. スター("*")
スター構文は基本的にsqlのselect *と同じようにすべてのカラムを選択します。

ステップ2: エイリアスによるSelect
一般的なユースケースの一つは、何かしらのデータ操作を行い、データをshowではなく新規データフレームとして割り当てるというものです。
例えば、Fairを70倍してUSドルからインドルピーに変換し、カラム名をFare_INDにするものとします。
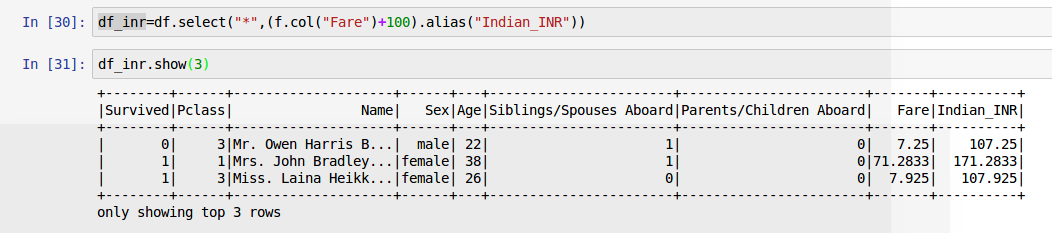
ここで、全ての列を選択し、新たな列Indian_INRを追加します。
フレキシブルなSelectExprとエイリアスのカラム
もしあなたが私のようにsql/Hiveユーザーであ理、あるいはsparkのcase構文を思い出せないとしたらどうしましょうか。
心配しないで下さい。selectExprがあなたを助けてくれます。
-
SelectExprはフレキシブルなsql文やフィールドの追加に役立ちます。
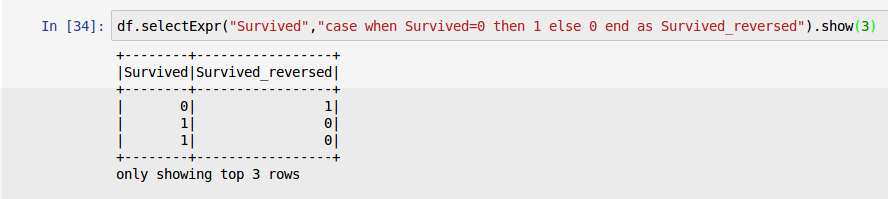
-
lengthのようなビルトインのHive関数を利用できます。
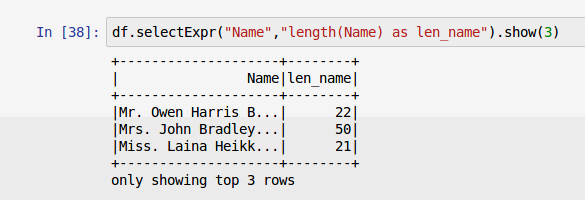
-
selectExprを用いることでデータ型のキャストも簡単です。

-
SelectExprを用いて定数を追加します。
一般的なユースケースの一つは、current_dateのような定数フィールドを追加するというものです。
SelectExprを用いることで簡単に達成できます。

3. Pythonの力(リストの内包表現)とselectの活用
selectはListを受け付けるので、特定のカラムを選択するのにリストの内包表現を使うことがd系ます。データフレームを操作するためにColumnのリストがユーザーに与えられているとします。
必要なカラムを選択すルタめにif句を用いたリストの内包表現(あるいはジェネレーター表現)を利用することができます。

Githubリンク:
https://github.com/SomanathSankaran/spark_medium/tree/master/spark_csv
学んで、他の人も学ぶようにしましょう!!