Marketing Analytics on the Databricks Lakehouse using Fivetran and dbt - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
マーケティングチームは、マーケティングとセールスキャンペーンをドライブするために多くの異なるプラットフォームを用いており、膨大な量の価値を生み出しますが、データは分断されています。これらのデータとすべてまとめることで、キャンペーンの収益を最大50%増加させたPublicis Groupeのように、大きな投資対効果をもたらす役に立ちます。
単一のプラットフォームでデータウェアハウスとAIユースケースを統合するDatabricksレイクハウスは、マーケティング分析ソリューションを構築するには理想的な場所となります。信頼できる唯一の情報源を保持し、AI/MLユースケースを解放します。また、解約分析、生涯価値分析、顧客セグメンテーション、広告効果測定を含む広範なマーケティング分析ユースケースを実現可能にする2つのDatabricksのパートナーソリューション、Fivetranとdbtを活用します。
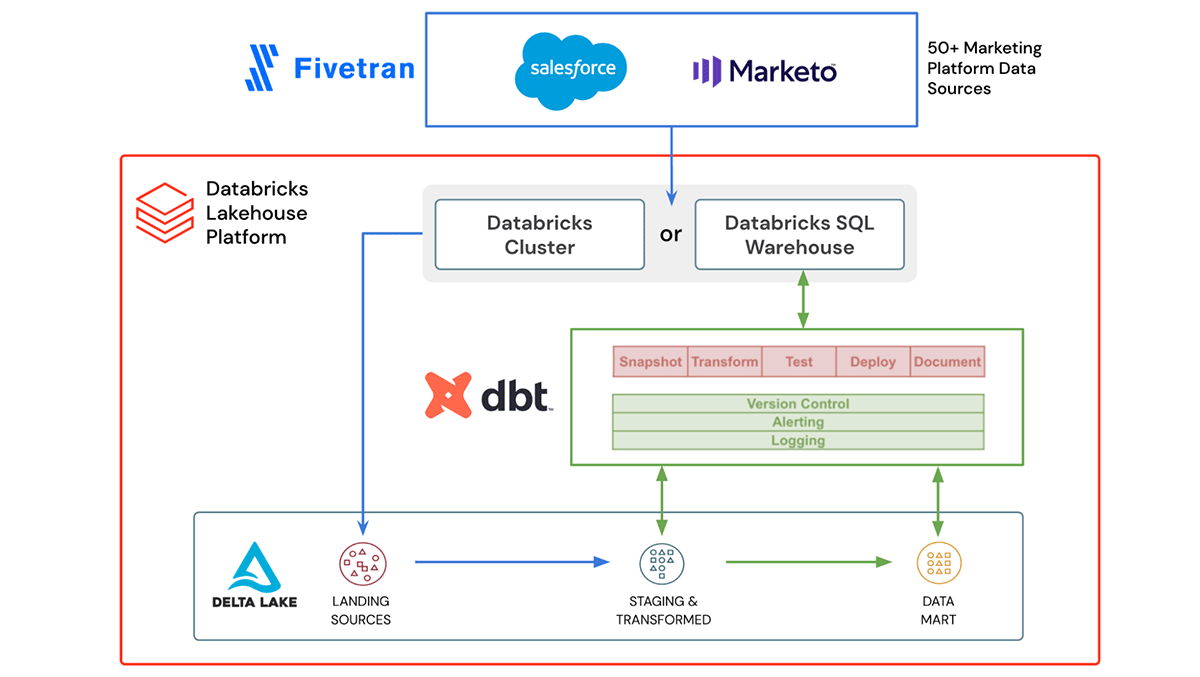
DatabricksクラスターとDatabricks SQLを用いて、FivetranとdbtはDelta Lakeに対して読み書きを行えます
Fivetranを用いることで、複雑なパイプラインを構築、管理する必要なしに50以上のマーケティングプラットフォームをDelta Lakeに容易にデータを取り込むことができます。マーケティングプラットフォームのAPIの変更があった場合、Fivetranはインテグレーションをアップデートし、修正するので、マーケティングデータはあなたのデータパイプラインに流れ込み続けます。
dbtは、シンプルなSQLを用いてレイクハウスのユーザーはデータパイプラインを構築できる人気のあるオープンソースフレームワークです。すべてのものは、テキストとしてディレクトリで整理されるので、バージョン管理、デプロイメント、テスト可能性が容易になります。データがDelta Lakeに取り込まれると、データを変換、テスト、ドキュメント化するためにdbtを活用することができます。そして、取り込まれたデータに基づいて構築された変換済みマーケティング分析データマートは、新たなマーケティングキャンペーンや取り組みを推進するために活用できる準備が整ったことになります。
Fivetranとdbtの両方は、Databricksプラットフォーム内でデータ、分析、AIツールを検索し、セキュアに直接接続できるワンストップポータルであるPartner Connectに組み込まれています。数クリックだけで、お使いのDatabricksワークスペースから直接これらのツール(それ以外のツールも)を設定し、接続することができます。
マーケティング分析ソリューションの構築方法
このハンズオンデモでは、Fivetranを用いてMarketoとSalesforceのデータをDatabricksに取り込み、マーケティング分析データモデルを変換、テスト、ドキュメント化するためにdbtを使用する方法を説明します。
このデモのすべてのコードはworkflows-examples repositoryのGithubから利用できます。
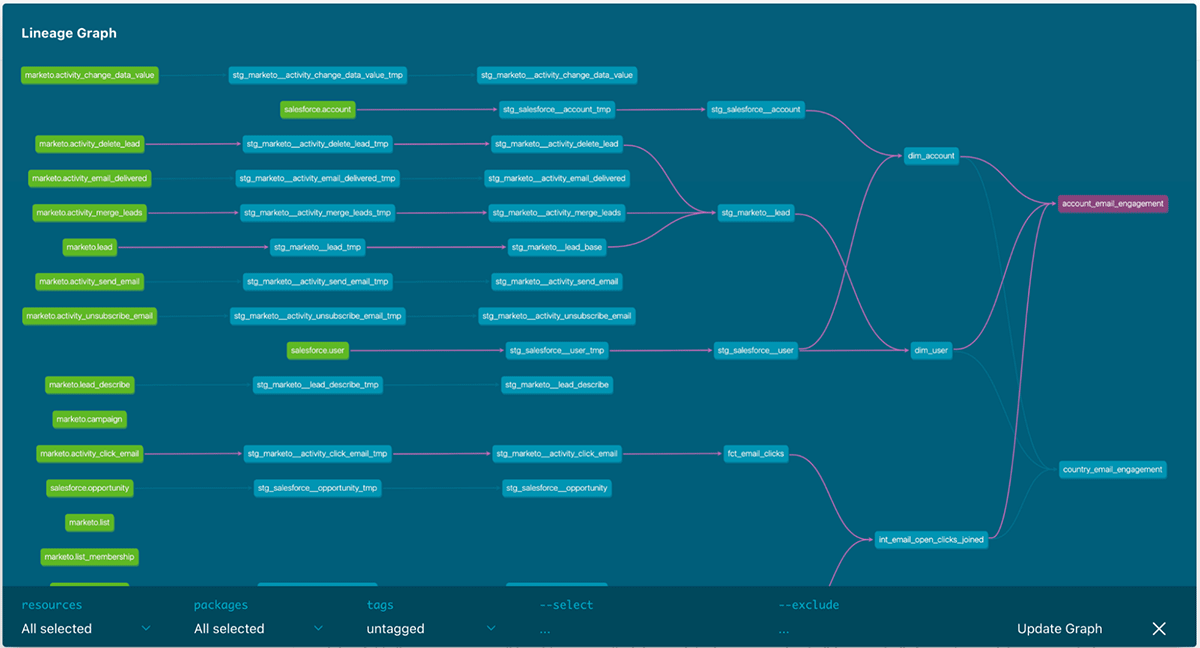
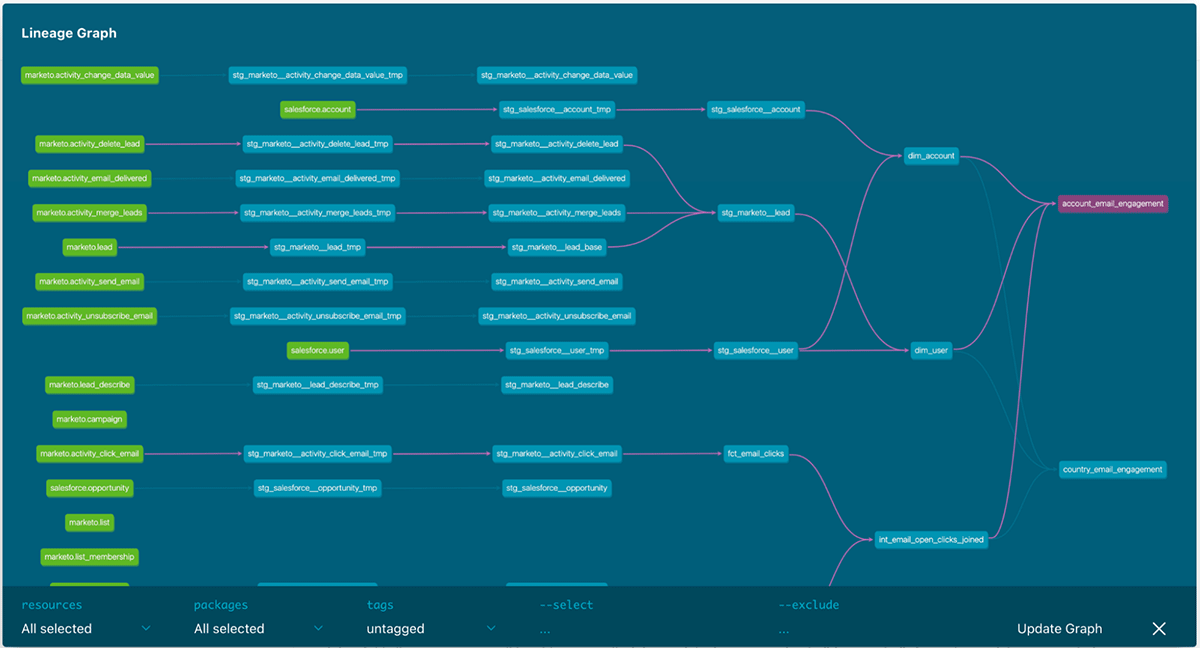
データソースとモデルを示すdbtのリネージュグラフ
最終的なdbtモデルのリネージュグラフはこのようになります。Fivetranのソーステーブルは左側の緑であり、最終的なマーケティング分析モデルは右側となります。モデルを選択することで、それぞれのモデルのに応する依存関係が紫でハイライトされます。
Fivetranを用いたデータ取り込み
Fivetranには数多くのマーケティング分析データソースのコネクターがあります
Delta Lakeへのマーケティングデータの取り込みをスタートするために、Fivetranで新規のSalesforceとMarketoのコネクションを作成します。また、Fivetranは、自動でDelta Lakeにそれぞれのデータソースのスキーマを作成し、管理します。このデータを変換、クレンジング、集計するために、あとでdbtを活用します。
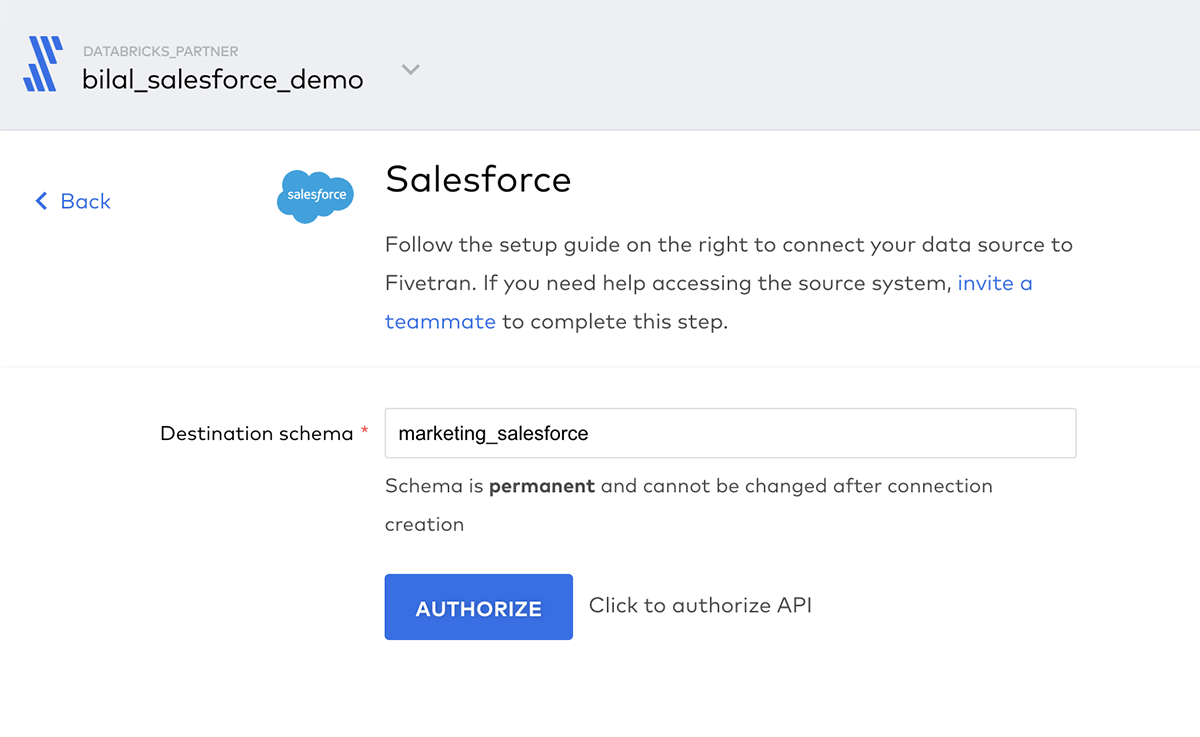
Salesforceデータソースに対するスキーマの定義
デモのために、Delta Lakeに作成されるスキーマをmarketing_salesforceとmarketing_marketoと名付けます。スキーマが存在しない際、Fivetranは最初の取り込みロード処理の一部としてこれらを作成します。
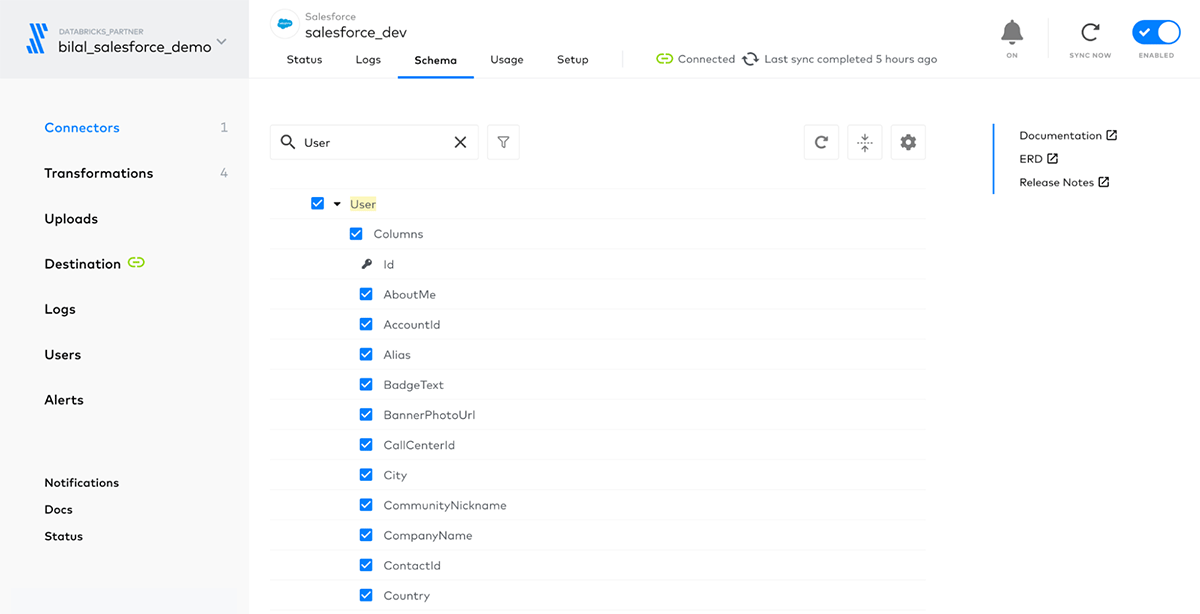
Delta Lakeテーブルとして同期するデータソースオブジェクトを選択
Delta Lakeにどのオブジェクトを同期するのかを選択することができ、これらのオブジェクトのそれぞれが別々のテーブルとして保存されます。また、Fivetranは、それぞれテーブルで何のカラムが同期されているのかの管理、参照をシンプルにします。
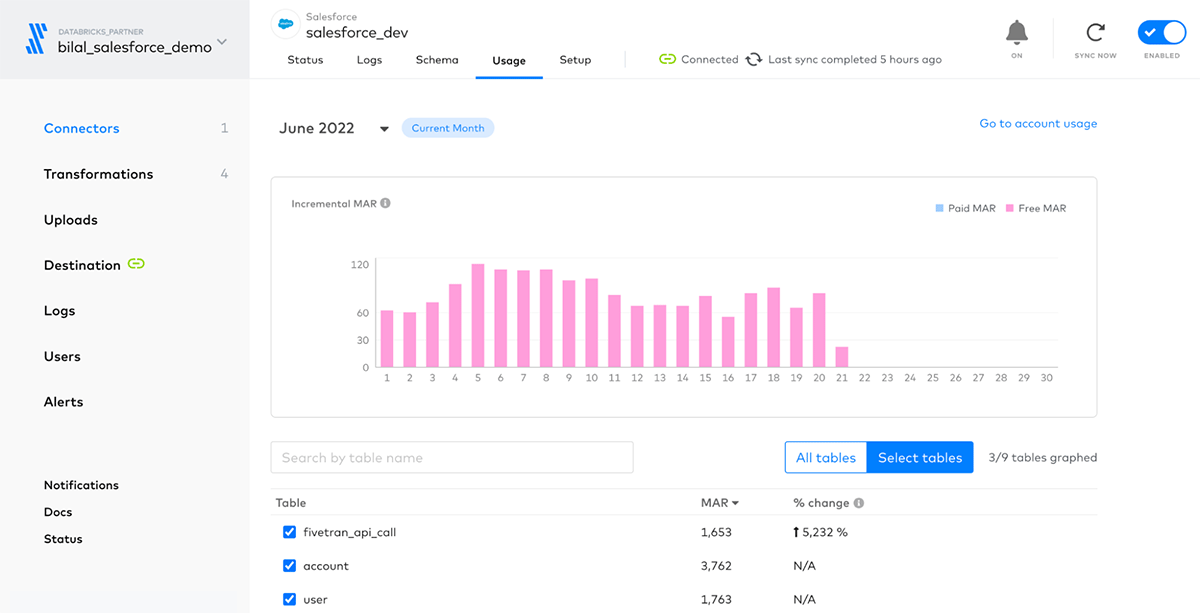
同期された月間アクティブ行をモニタリングするためのFivetranダッシュボード
さらに、それぞれのテーブルが日次、月次で何行同期されたのかを示すアクティブ行が何行あるのかを分析するために、Fivetranはモニタリングダッシュボードを提供します。
dbtを用いたデータモデリング
すべてのマーケティングデータをDelta Lakeに取り込んだので、以下のステップに沿ってデータモデルを作成するためにdbtを活用します。
ローカルでdbtプロジェクトをセットアップし、Databricks SQLに接続
set-up instructions for dbt Core and dbt-databricksの手順に従って、お好きなIDEでローカルdbt開発環境をセットアップします。
以下の情報を聞いてくるdbt initを用いて、新規dbtプロジェクトを作成し、Databricks SQLウェアハウスに接続します。
$ dbt init
Enter a name for your project (letters, digits, underscore):
Which database would you like to use?
[1] databricks
[2] spark
Enter a number: 1
host (yourorg.databricks.com):
http_path (HTTP Path):
token (dapiXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX):
schema (default schema that dbt will build objects in):
threads (1 or more) [1]:
プロファイルを設定すると、以下を用いて接続をテストすることができます。
$ dbt debug
ステージングのためにFivetran dbtモデルパッケージをインストール
MarketとSalesforceデータを用いた最初のステップは、我々のモデルのソースとしてテーブルを作成することです。幸運なことに、Fitetranでは、ビルド済みのFivetran dbtモデルパッケージを提供しており、容易にセットアップして実行できるようになっています。このデモでは、marketo_sourceとsalesforce_sourceを活用します。
パッケージをインストールするには、あなたのdbtプロジェクトのルートに** packages.yml**ファイルを追加し、marketo-source、salesforce-source、fivetran-utilsパッケージを追加するだけです。
packages:
- package: dbt-labs/spark_utils
version: 0.3.0
- package: fivetran/marketo_source
version: [">=0.7.0", "<0.8.0"]
- package: fivetran/salesforce_source
version: [">=0.4.0", "<0.5.0"]
パッケージをダウンロードし使用するには、以下を実行します。
$ dbt deps
packagesフォルダにFivetranパッケージがインストールされていることを確認できるはずです。
Fivetran dbtモデルdbt_project.ymlの更新
Fivetranパッケージが適切にDatabrikcsで動作するようにするために、dbt_project.ymlファイルに幾つかの設定を行う必要があります。
dbt_project.ymlファイルは、あなたのdbtプロジェクトのルートフォルダにあるはずです。
spark_utilsでdbt_utilsマクロを上書き
Fivetran dbtモデルはdbt_utilsパッケージのマクロを活用しますが、これらのマクロのいくつかをDatabricksで動作するように変更する必要がありますが、これはspark_utilsパッケージを用いることで簡単に行えます。
これは、dbt_project.ymlファイルでdispatch configを用いて設定できる特定のdbt_utilsマクロに対してシム(既存のコードの動作を修正するために使われるコード)を指定することで動作し、これによってdbt_utils名前空間からマクロを解決する際に、dbtは最初にspark_utilsパッケージのマクロを検索します。
dispatch:
- macro_namespace: dbt_utils
search_order: ['spark_utils', 'dbt_utils']
marketo_sourceとsalesforce_sourceスキーマの変数
Fivetranパッケージでは、Fivetranによってデータが取り込まれた際に、どこに取り込むのかを指定するために、カタログ(dbtではデータベースとして参照されます)とスキーマを指定することが必要となります。
適切なカタログ名、スキーマ名としてこれらの変数をdbt_project.ymlファイルに追加します。_databaseが空の場合、デフォルトカタログのhive_metastoreが使用されます。Fivetranでコネクションを作成する際に定義したものがスキーマ名となります。
vars:
marketo_source:
marketo_database: # leave blank to use the default hive_metastore catalog
marketo_schema: marketing_marketo
salesforce_source:
salesforce_database: # leave blank to use the default hive_metastore catalog
salesforce_schema: marketing_salesforce
Fivetranステージングモデルのターゲットスキーマ
Fivetranによって作成されるすべてのステージングテーブルが、デフォルトのターゲットスキーマに作成することを避けるには、別のステージングスキーマを定義することが有効です。
dbt_project.ymlファイルにステージングのスキーマ名を追加すると、デフォルトのスキーマ名の末尾に追加されます。
models:
marketo_source:
+schema: your_staging_name # leave blank to use the default target_schema
salesforce_source:
+schema: your_staging_name # leave blank to use the default target_schema
上の内容に基づいて、profiles.ymlで定義されているターゲットスキーマがmkt_analyticsの場合、marketo_sourceとsalesforce_sourceテーブルで使用されるスキーマは、mkt_analytics_your_staging_nameとなります。
不在テーブルの無効化
このステージでは、適切に動作することをテストするためにFivetranのモデルパッケージを実行することができます。
dbt run –select marketo_source
dbt run –select salesforce_source
Fivetranで同期するものとして選択しなかったことで、テーブルが存在しないためにいずれかのモデルが失敗した場合、dbt_project.ymlファイルを更新することで、ソーススキーマでこれらのモデルを無効化することができます。
例えば、メールが未達となり、メールテンプレートテーブルがMarketソーススキーマに存在しない場合、モデルの設定に以下を追加することで、これらオンテーブルのモデルを無効化することができます。
models:
marketo_source:
+schema: your_staging_name
tmp:
stg_marketo__activity_email_bounced_tmp:
+enabled: false
stg_marketo__email_template_history_tmp:
+enabled: false
stg_marketo__activity_email_bounced:
+enabled: false
stg_marketo__email_template_history:
+enabled: false
マーケティング分析モデルの開発
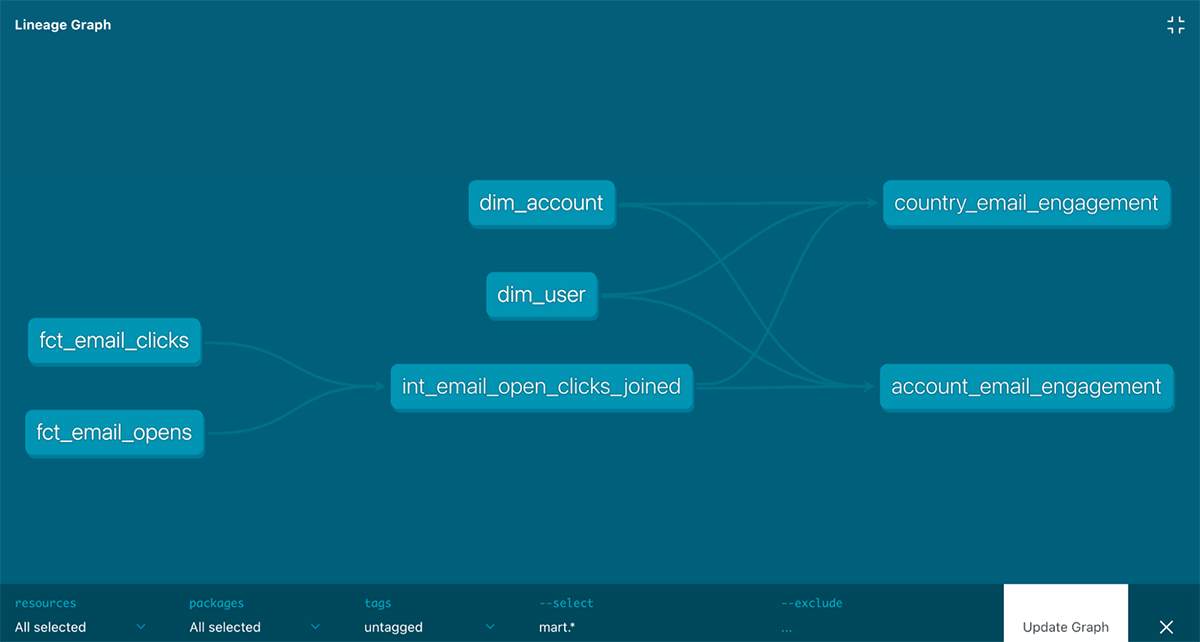
スタースキーマと集計テーブルのデータモデルを示すdbtのリネージュグラフ
ここまででFivetranパッケージは、マテリアライズされた集計テーブルを伴うスタースキーマデータモデルとなるマーケティング分析ユースケースのデータモデルを開発し始めたモデルの作成、テスト、ステージングを行なってきました。
例えば、最初のマーケティング分析ダッシュボードとして、特定の企業や地域でメールのキャンペーンが開かれ、クリックされた数に基づいて、どの程度エンゲージメントできているのかを見たいと考えます。
このためには、Salesforceユーザーのメール、Salesforceのaccount_id、Marketoのlead_idを用いてSalesforceのテーブルとMarketoテーブルをjoinします。
以下のように、martフォルダ配下にモデルが整理されます。
marketing_analytics_demo
|-- dbt_project.yml
|-- packages.yml
|-- models
|-- mart
|-- core
|-- intermediate
|-- marketing_analytics
Githubの/models/martディレクトリにすべてのモデルのコードを確認することができ、以下ではサンプルとともにそれぞれのフォルダが何であるのかを説明します。
コアモデル
コアモデルは、すべての後段のモデルの構築に用いられるファクトとディメンジョンテーブルとなります。
dim_userモデルのdbt SQLコードです。
with salesforce_users as (
select
account_id,
email
from {{ ref('stg_salesforce__user') }}
where email is not null and account_id is not null
),
marketo_users as (
select
lead_id,
email
from {{ ref('stg_marketo__lead') }}
),
joined as (
select
lead_id,
account_id
from salesforce_users
left join marketo_users
on salesforce_users.email = marketo_users.email
)
select * from joined
また、フォルダのyamlファイルを用いてモデルに対するドキュメントとテストを追加することができます。
追加されているcore.ymlファイルには2つのシンプルなテストが含まれています。
version: 2
models:
- name: dim_account
description: "The Account Dimension Table"
columns:
- name: account_id
description: "Primary key"
tests:
- not_null
- name: dim_user
description: "The User Dimension Table"
columns:
- name: lead_id
description: "Primary key"
tests:
- not_null
中間モデル
最終的な後段のモデルのいくつかは同じ計算メトリクスに依存しており、SQLの繰り返しを避けるために、再利用可能な中間モデルを作成することができます。
int_email_open_clicks_joinedモデルに対するdbt SQLコードです。
with opens as (
select *
from {{ ref('fct_email_opens') }}
), clicks as (
select *
from {{ ref('fct_email_clicks') }}
), opens_clicks_joined as (
select
o.lead_id as lead_id,
o.campaign_id as campaign_id,
o.email_send_id as email_send_id,
o.activity_timestamp as open_ts,
c.activity_timestamp as click_ts
from opens as o
left join clicks as c
on o.email_send_id = c.email_send_id
and o.lead_id = c.lead_id
)
select * from opens_clicks_joined
マーケティング分析モデル
これらが。マーケティング、セールスチームによって活用されるダッシュボードやレポートを強化するために用いられる最終的なマーケティング分析モデルです。
country_email_engagementモデルのdbt SQLコードです。
with accounts as (
select
account_id,
billing_country
from {{ ref('dim_account') }}
), users as (
select
lead_id,
account_id
from {{ ref('dim_user') }}
), opens_clicks_joined as (
select * from {{ ref('int_email_open_clicks_joined') }}
), joined as (
select *
from users as u
left join accounts as a
on u.account_id = a.account_id
left join opens_clicks_joined as oc
on u.lead_id = oc.lead_id
)
select
billing_country as country,
count(open_ts) as opens,
count(click_ts) as clicks,
count(click_ts) / count(open_ts) as click_ratio
from joined
group by country
dbtモデルの実行およびテスト
これでモデルの準備が整い、以下を用いてすべてのモデルを実行することができます。
$ dbt run
次に以下でテストを実行します。
$ dbt test
dbtドキュメントのリネージュグラフの参照
マーケティング分析モデルのdbtリネージュグラフ
モデルの実行が成功すると、以下を用いてドキュメントとリネージュグラフを生成することができます。
$ dbt docs generate
ローカルで以下を実行して参照します。
$ dbt docs serve
dbtモデルをプロダクションにデプロイする
ローカルでdbtモデルを開発してテストしたら、プロダクションにデプロイ選択肢は複数あり、そのうちの一つがDatabricksワークフローにおけるdbtタスクタイプ(プライベートプレビュー)です。
あなたのdbtプロジェクトはGitリポジトリ上でバージョン管理されている必要があります。Gitリポジトリをポイントすることで、Databricksワークフローでdbtタスクを作成することができます。
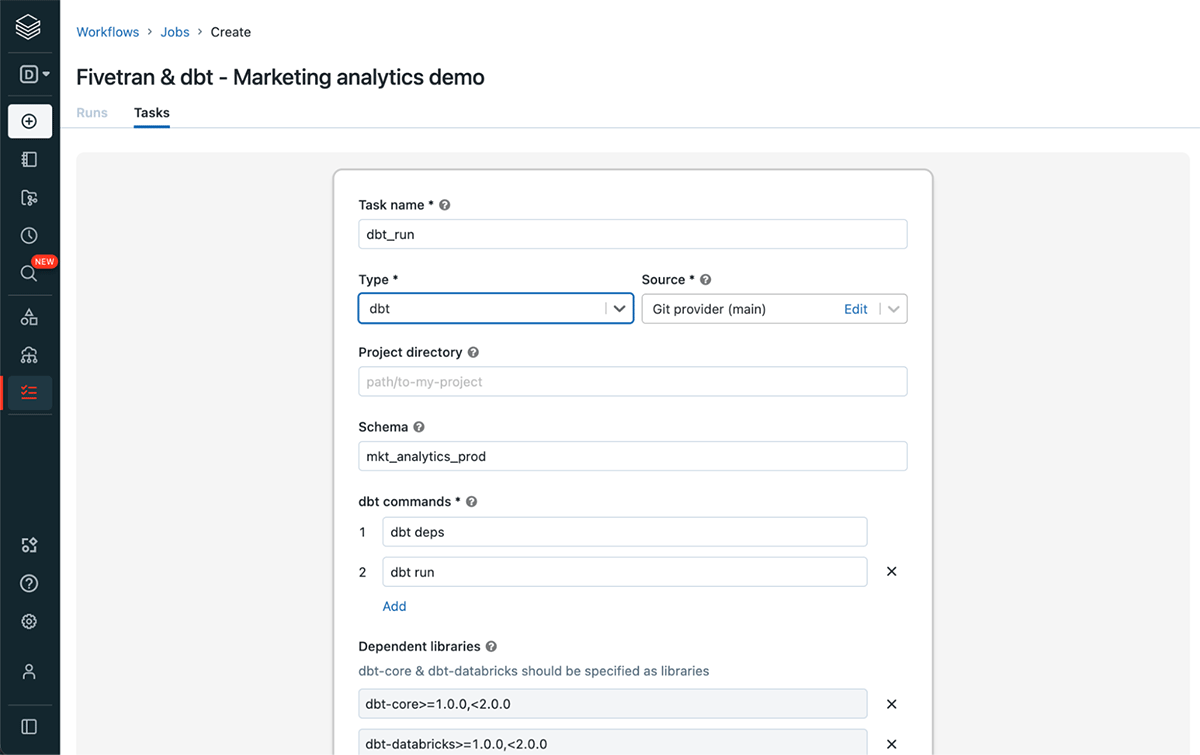
dbtをオーケストレートするためにDatabricksワークフローでdbtタスクタイプを使用
dbtプロジェクトでパッケージを使用しているので、最初のコマンドは最初のタスクとしてのdbt depsに次いでdbt runであり、次のタスクとしてdbt testを実行することになります。
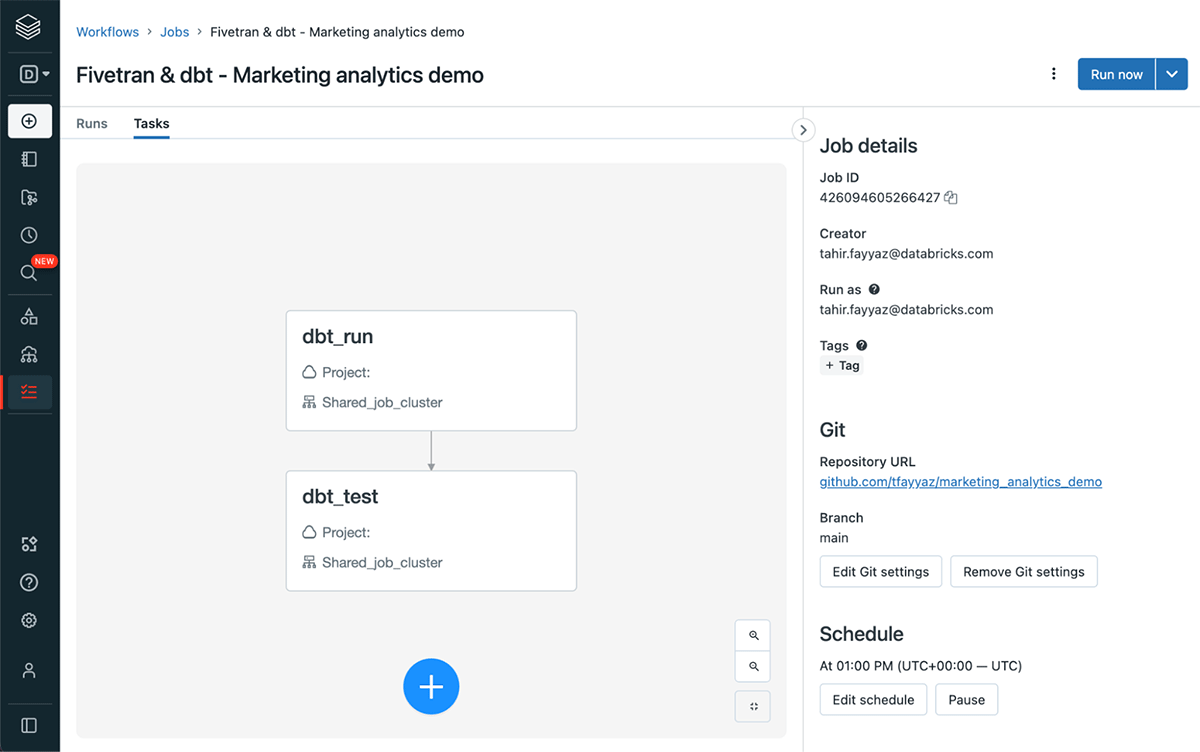
2つの依存関係を持つdbtタスクからなるDatabricksワークフローのジョブ
そして、run nowを用いて即座にワークフローを実行するか、特定のスケジュールでdbtプロジェクトを実行するためにスケジュールをセットアップすることもできます。
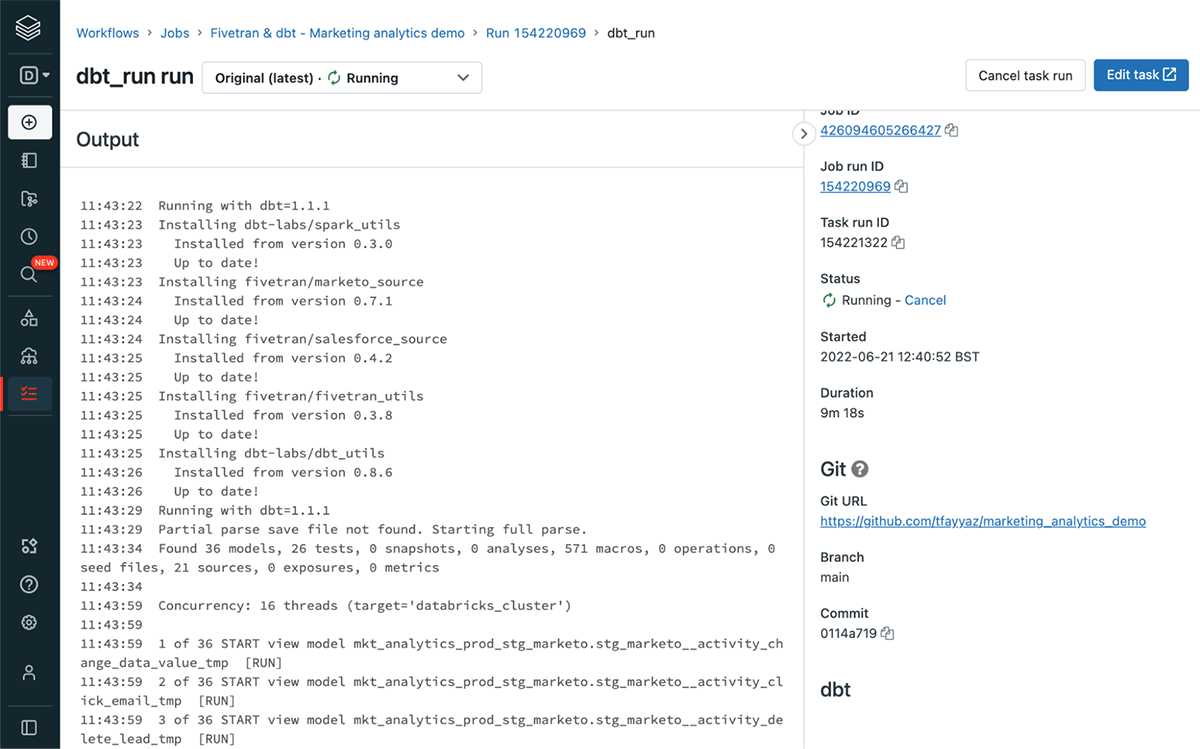
それぞれのdbt実行に対するdbtログの参照
それぞれの処理実行ごとにdbtコマンドごとのログを参照できるので、デバッグや問題の修正に役立ちます。
Fivetranとdbtを用いてマーケティング分析を強化する
上で説明したように、FivetranとdbtをDatabrikcsレイクハウスプラットフォームと組み合わせることで、セットアップ、管理が容易で、任意のデータモデリング要件に対応できる柔軟性を持つパワフルなマーケティング分析ソリューションを容易に構築できるようになります。
自分のソリューションの構築を始めるには、DatabricksとFivetran、dbtとのインテグレーションに関するドキュメントを参照いただき、クイックにスタートできるようにmarketing_analytics_demo project exampleを再利用してください。
Databricksワークフローにおけるdbtタスクタイプはプライベートプレビューです。dbtタスクタイプを試したい場合には、Databricks担当者にコンタクトしてください