Data Partitioning in PySparkの翻訳です。Databricksでウォークスルーしていきます。この他にもパーティションの記事を訳してます。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
本書では、PythonでPySparkを用いたデータのパーティショニングを学びます。
PySparkにおいて、データのパーティショニングは大規模なデータセットを同時に処理できるように小規模なチャンクやパーティションに分割するプロセスを指します。ワークロードを複数のマシンやプロセッサに分割することで、より効率的に大規模データセットを処理できるので、これは分散処理の観点では重要なものとないrます。
データパーティショニングの利点
- パフォーマンスの改善: データを小規模なパーティションに分割することで、複数マシンで並列に処理できるようになり、処理時間の高速化、パフォーマンスの改善につながります。
- スケーラビリティ: パーティショニングによって水平のスケーラビリティを実現するので、データの量が増加した場合には、データ処理コードを変更することなしに、増加した負荷に対応するためにクラスターにより多くのマシンを追加できることを意味します。
- 耐障害性の改善: また、パーティショニングによってデータを複数のマシンに分散できるので、単体のマシンの障害が起きた場合のデータの損失を防ぐ助けとなります。
- データの整理: パーティショニングによって、時間や地理情報のようにより意味のある方法でデータを整理することができ、データの分析やクエリーがより簡単になります。
本書では、データのパーティションに対するいくつかの方法を見ていきます。
PySparkにおけるデータパーティショニングの方法
- ハッシュパーティショニング
- レンジパーティショニング
- partitionByの使用
ハッシュパーティショニングの使用
これはPySparkにおけるデフォルトのパーティショニング手法です。指定されたカラムに基づいてそれぞれのレコードにユニークなハッシュ値を割り当て、対応するパーティションにレコードを配置します。これによって、指定されたカラムで同じ値を持つレコードが同じパーティションに配置されることを保証します。ハッシュパーティショニングは、指定されたカラムのハッシュ値に基づいてデータセットをパーティションに分割する手法です。
ハッシュパーティショニング実装のステップ
- ステップ1: 最初に3つのカラムid, name, ageを持つサンプルデータフレームを作成するために必要なすべてのライブラリをインポートします。
- ステップ2: idカラムに基づいてデータフレームに対するハッシュパーティショニングを実行するために、repartition関数を使用します。
- ステップ3: 背後にあるRDDにアクセスするためにrddメソッドを用いて、それぞれのパーティションのすべての要素の配列を返却するglomメソッドを呼び出すことで、パーティショニングを確認することができます。
# サンプルデータフレームの作成
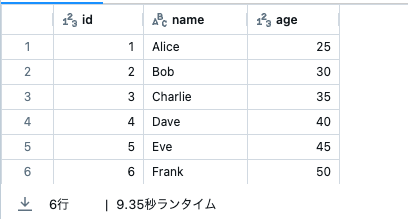
df = spark.createDataFrame([
(1, "Alice", 25),
(2, "Bob", 30),
(3, "Charlie", 35),
(4, "Dave", 40),
(5, "Eve", 45),
(6, "Frank", 50)
], ["id", "name", "age"])
# データフレームの表示
display(df)
# "id"カラムをベースとしてデータフレームに対するハッシュパーティショニングの実行
df = df.repartition(4, "id")
# それぞれのパーティションの要素を表示
print(df.rdd.glom().collect())
以下のアウトプットでは、パーティショニングされたデータを含むネストされた配列を持つデータフレームを確認できます。
[
[Row(id=2, name='Bob', age=30), Row(id=4, name='Dave', age=40), Row(id=5, name='Eve', age=45)],
[Row(id=1, name='Alice', age=25), Row(id=6, name='Frank', age=50)],
[],
[Row(id=3, name='Charlie', age=35)]
]
レンジパーティショニングの使用
この手法は、指定されたカラムの値のレンジに基づいてデータをパーティションに分割します。例えば、日付のレンジに基づいてデータセットをパーティションに分割することができ、それぞれのパーティションには特定の期間のレコードが含まれることになります。この手法では、ageカラムに基づき、データセットに対してレンジパーティションを実行するために、repartitionByRange() 関数を使用します。
# サンプルデータフレームの作成
df = spark.createDataFrame([
(1, "Alice", 25),
(2, "Bob", 30),
(3, "Charlie", 35),
(4, "Dave", 40),
(5, "Eve", 45),
(6, "Frank", 50)
], ["id", "name", "age"])
# "age"カラムに基づきデータフレームに対するレンジパーティションの実行
df = df.repartitionByRange(3, "age")
# それぞれのパーティションの要素を表示
print(df.rdd.glom().collect())
以下の出力では、repartitionByRange()関数で指定されたようにデータフレームが3つのパーツにパーティショニングされたことを確認できます。
[[Row(id=1, name='Alice', age=25), Row(id=2, name='Bob', age=30)],
[Row(id=3, name='Charlie', age=35), Row(id=4, name='Dave', age=40)],
[Row(id=5, name='Eve', age=45), Row(id=6, name='Frank', age=50)]]
partitionBy()メソッドの使用
PySparkのpartitionBy() methodは、データフレームを一つ以上のカラムの値に基づいてより管理しやすい小規模なパーティションに分割するために使用されます。このメソッドは引数として一つ以上のカラム名を受け取り、それらのカラムの値に基づいてパーティショニングにされた新規のデータフレームを返却します。ここでは、Cricket_data_set_odi.csvのリンクからダウンロードできるクリケットのデータセットを使用します。partitionBy() 関数を用いたデータのパーティショニングのステップを見ていきましょう。
- ステップ1: 必要なモジュールをインポートし、CSVを読み込んでスキーマを表示します。
Databricksでは、CSVファイルをワークスペースファイルとしてインポートしておきます。読み込む際にはこちらにあるように、パスにfile:接頭辞をつけます。
# データフレームの作成
df = spark.read.option("header", True).csv(
"file:/Workspace/Users/takaaki.yayoi@databricks.com/20240323_spark_partitioning/Cricket_data_set_odi.csv"
)
# スキーマの表示
df.printSchema()
root
|-- Team: string (nullable = true)
|-- Player_ID: string (nullable = true)
|-- Player: string (nullable = true)
|-- Matches: string (nullable = true)
|-- Runs: string (nullable = true)
|-- Wickets: string (nullable = true)
|-- Hundreds: string (nullable = true)
|-- Fifties: string (nullable = true)
|-- Speciality: string (nullable = true)
-
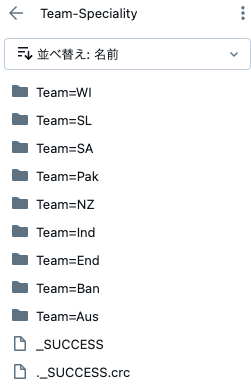
ステップ2: このステップでは“Team”と“Speciality”のカラムを使用します。チームと専門性をベースとしたすべてのパーティションは、
write.option()関数を用いて“Team-Speciality”フォルダに格納され、パーティショニングは**partitionBy()**関数を用いて行われます。
# この例では、上のデータフレームから、TeamとSpecialityをパーティションキーとして使用します。
df.write.option("header", True) \
.partitionBy("Team", "Speciality") \
.mode("overwrite") \
.csv("file:/Workspace/Users/takaaki.yayoi@databricks.com/20240323_spark_partitioning/Team-Speciality")
まとめ
PySparkアプリケーションのパフォーマンスにデータのパーティショニングが重大なインパクトを与えることに注意することが重要です。適切なパーティショニングは、コードのスピードと効率性を大きく改善しますが、不適切なパーティショニングは貧弱なパフォーマンスとリソースの不十分な活用につながります。
データ革命の波に乗り遅れないでください!すべての業界で、データのパワーを活用することで新たな高みに到達しています。21世紀の最もホットなトレンドの一部となり、スキルを磨きましょう。
テクノロジーの未来に飛び込みましょう - GeeksforGeeksのComplete Machine Learning and Data Science Programを探索し、流れに先んじましょう。