はい、流行り物に乗りました。
中身に関する記事は結構書かれていると思いますので、Databricks環境でどう動かすのかにのみフォーカスします。
APIキーの取得
こちらにサインアップします。
メニューからView API keysを選択します。
Create new secret keyをクリックし、表示されるキーをメモしておきます。
クラスターの設定
- 最近のランタイムであれば問題なく動きます。ここでは12.0 ML betaを使っています。

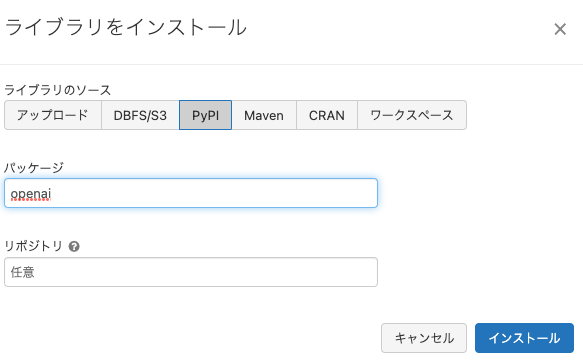
- ライブラリをインストールします。
PyPIからopenaiをインストールする様にします。
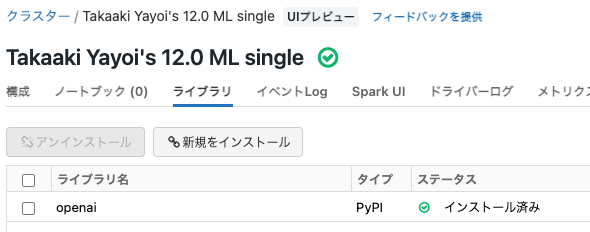
- クラスターが起動し、ライブラリがインストールされたことを確認します。
シークレットの設定
Pythonのサンプルでは環境変数経由でAPIキーを読み込んでいますが、この方法はDatabricksでは非推奨なので、シークレットを使います。
-
ローカルマシンでDatabricks CLIをセットアップします。
-
databricks configure --tokenを実行して、Databricks CLIの接続設定を行います。 -
ターミナル(コマンドプロンプト)で以下のコマンドを実行します。
Bashdatabricks secrets put --scope <スコープ名> --key <キー名> -
エディタが表示されるのでAPIキーの取得で取得したキーを入力します。
-
保存してエディタを終了します。これでシークレットが保存されました。
ノートブックでOpenAI APIを実行
こちらのPythonバインディングのサンプルを参考にします。
Python
import os
import openai
# シークレットからAPIキーを取得
openai.api_key = dbutils.secrets.get("demo-token-takaaki.yayoi", "openai")
呼び出しやすくなる様に関数にします。APIの仕様はこちらにあります。
Python
def openai_completion(prompt):
response = openai.Completion.create(model="text-davinci-003", prompt=prompt, max_tokens=3000)
# コンプリーションを表示
print(response.choices[0].text)
あとは色々遊んでみます。
Python
openai_completion("Databricksとはなんですか")

Python
openai_completion("鳥と猫は同居できますか")

Python
openai_completion("若者とは何歳までですか")

きちんと返してくれる、すごいです。これで基本は動かせたので他にも何ができるか試してみます。手前味噌であれですが、新しいものをクイックに試す際にきれいな状態の実行環境をすぐに用意できるDatabricksクラスターは便利だと思います。