本記事では、Databricksで一行のPythonもSQLも記述することなしにBIダッシュボードを構築する流れを紹介します。
ここで紹介している内容はあくまでサンプルです。実際に業務で活用するには追加の作業、あるいはコーディングが必要となる場合があります。
データへのアクセス
本書では、すでにDatabricks環境にあるサンプルデータを使用します。
-
Databricksワークスペースにログインし、サイドバーのペルソナスイッチャーからSQLを選択します。Databricks SQLに移動します。
-
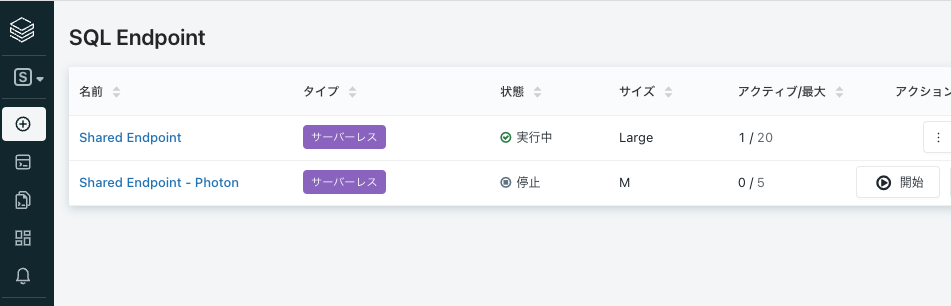
SQLエンドポイント(Databricks SQLにおける計算資源)が起動していない場合には、サイドメニューからSQLエンドポイントを選択し、SQLエンドポイントを起動します。
-
サイドメニューのデータを選択します。データエクスプローラに移動します。
SQLエンドポイントが選択されていない場合には、右上で上のステップで起動したSQLエンドポイントを選択します。デフォルトでは
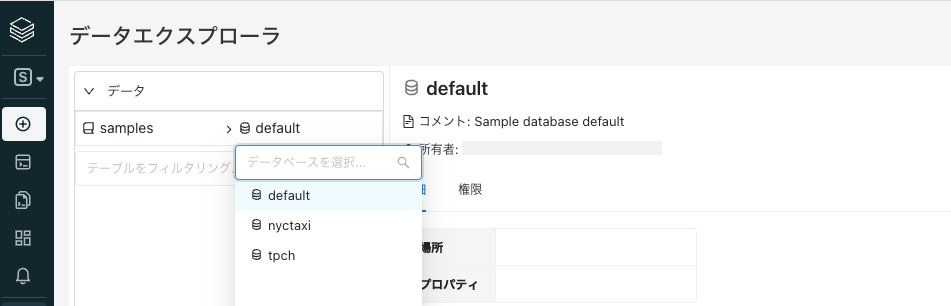
hive_metastoreが選択されていますが、ここをクリックしてsampleを選択します。これはサンプルデータを格納しているサンプルカタログです。
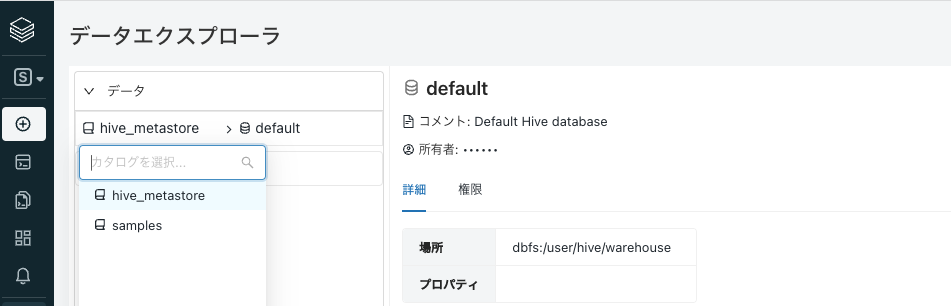
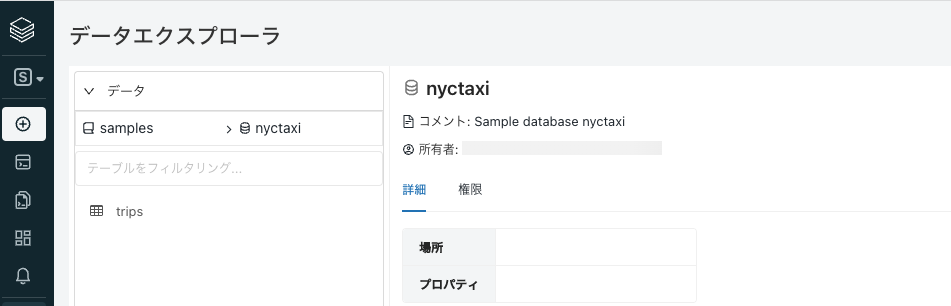
さらにデータベースnytaxiを選択します。このデータベースにはニューヨークのタクシー乗降記録のデータが含まれています。
-
テーブル
tripsを選択します。テーブルのメタデータが表示されます。
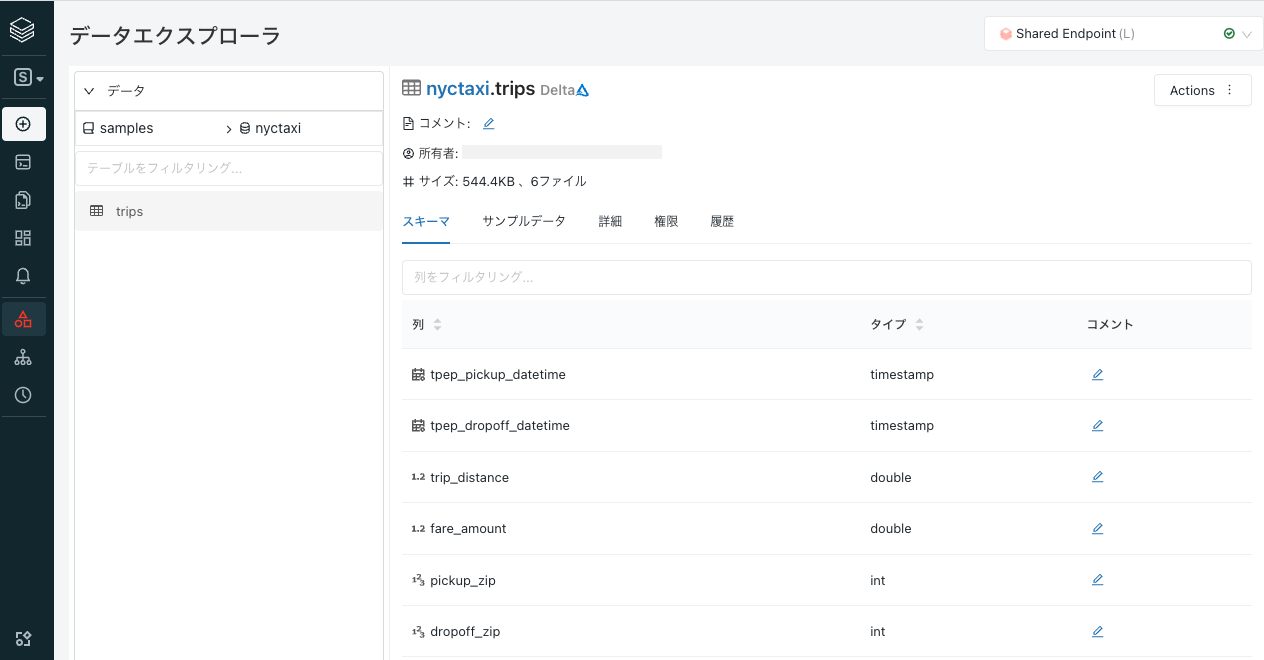
ダッシュボードの作成
通常の手順では、要件に応じてこのテーブルに対してSQLクエリーを定義し、クエリーの結果をどのようにビジュアライズするのか(例:棒グラフ、折れ線グラフなど)を定義しダッシュボードの部品(ビジュアライゼーション)とします。そして、最後に部品を組み合わせてダッシュボードを作成するという流れになります。
よりクイックにダッシュボードを作成したいという場合には、クイックダッシュボードを作成することができます。
画面右上のAction > Create a quick dashboardを選択します。
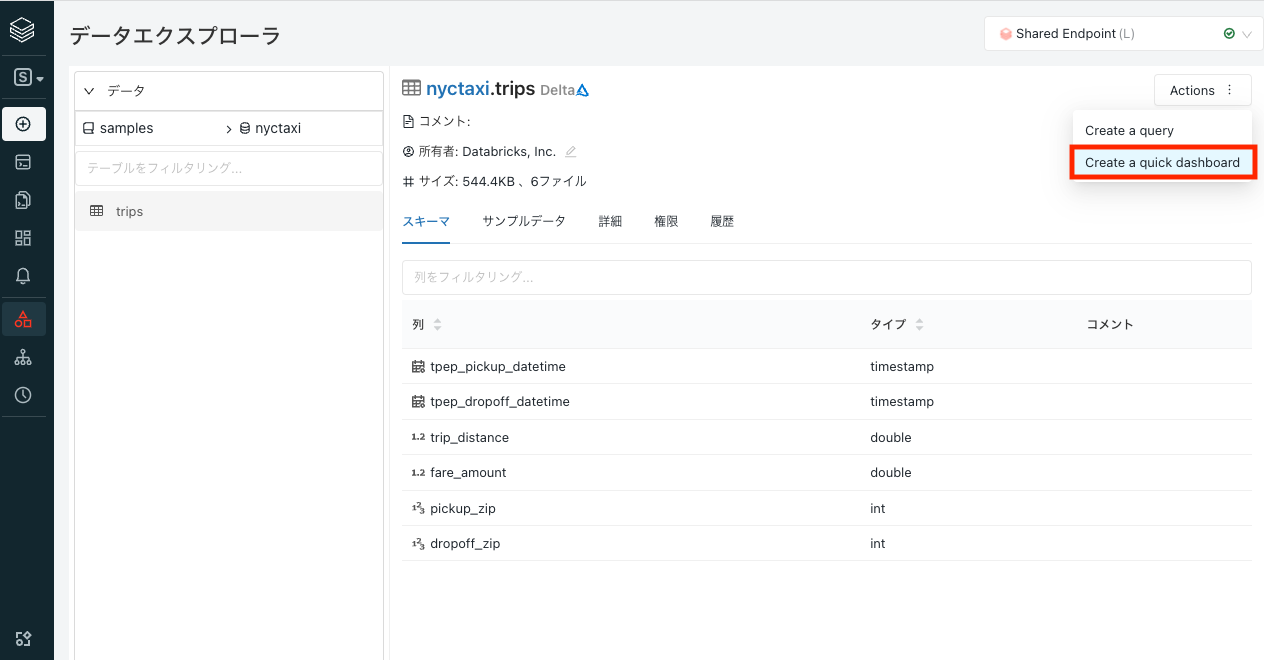
ダッシュボードに含めるカラムを選択する画面に移動します。
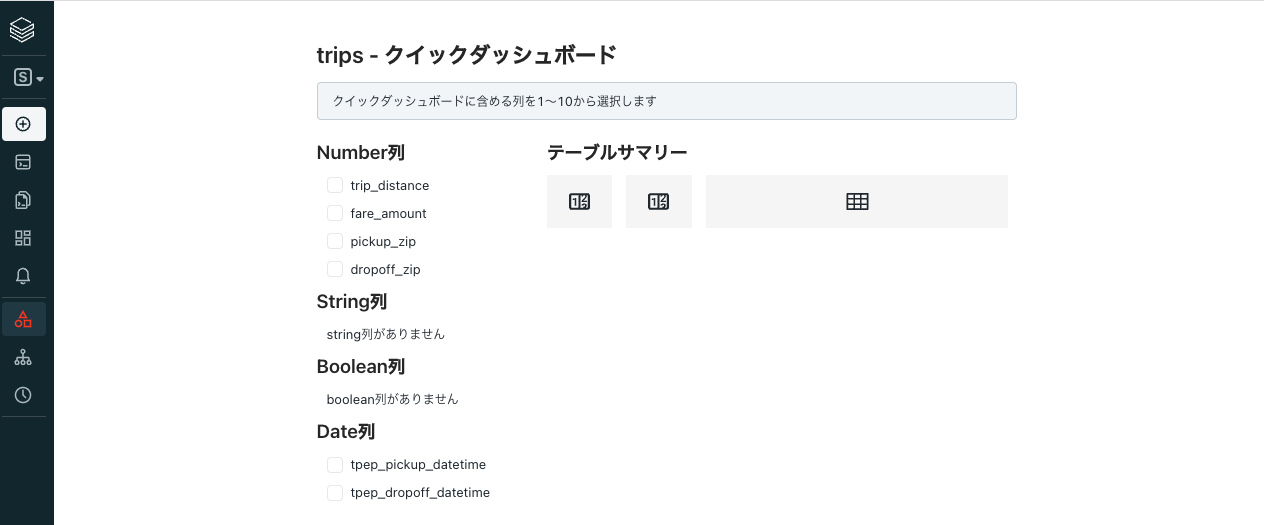
ダッシュボードに含める列のチェックボックスを選択し、Createをクリックします。
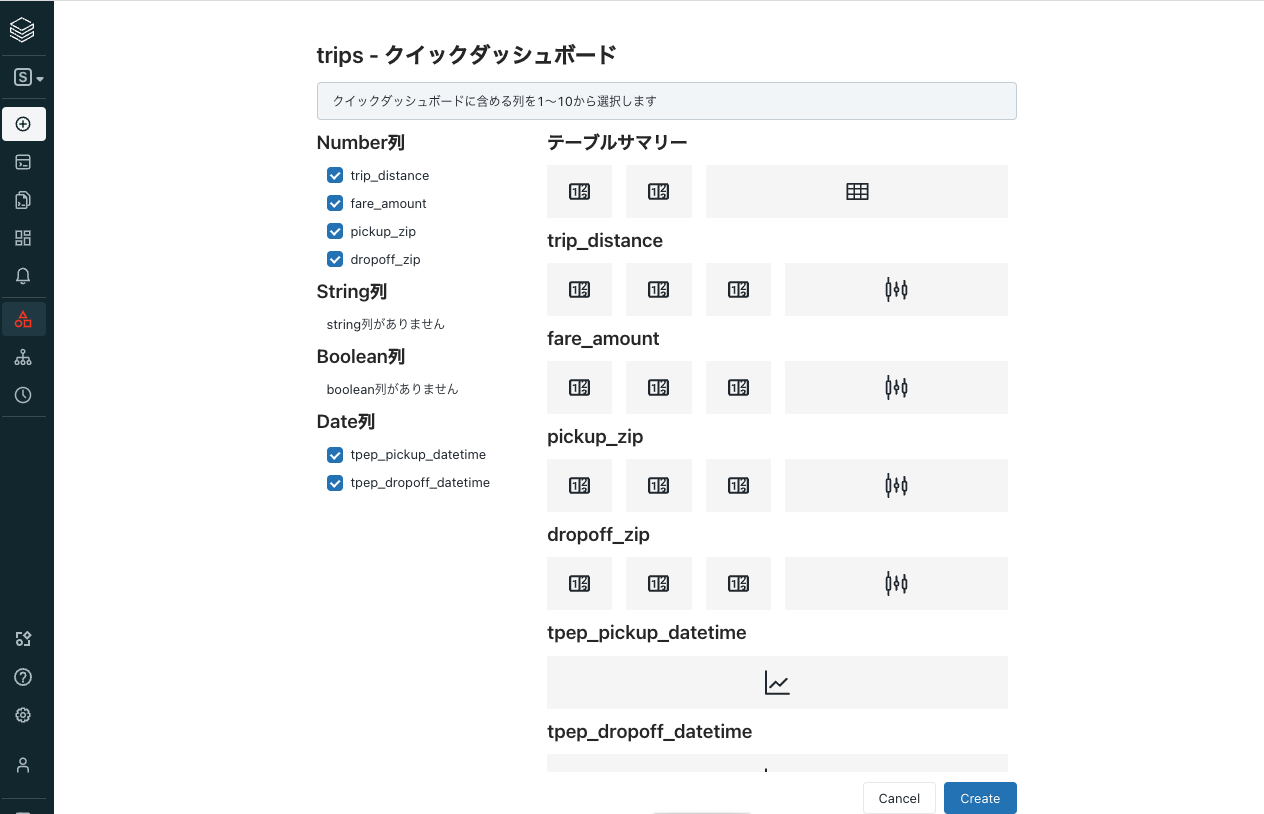
ダッシュボードの完成
これだけで、選択した列のデータ方に応じたビジュアライゼーションが追加されたダッシュボードが表示されます。カスタマイズしたい場合には、Databricks SQLのダッシュボードを参考に編集を行ってください。編集を完了をクリックすればダッシュボードの完成です。ここまでの操作はすべてマウスのクリックによるものです。
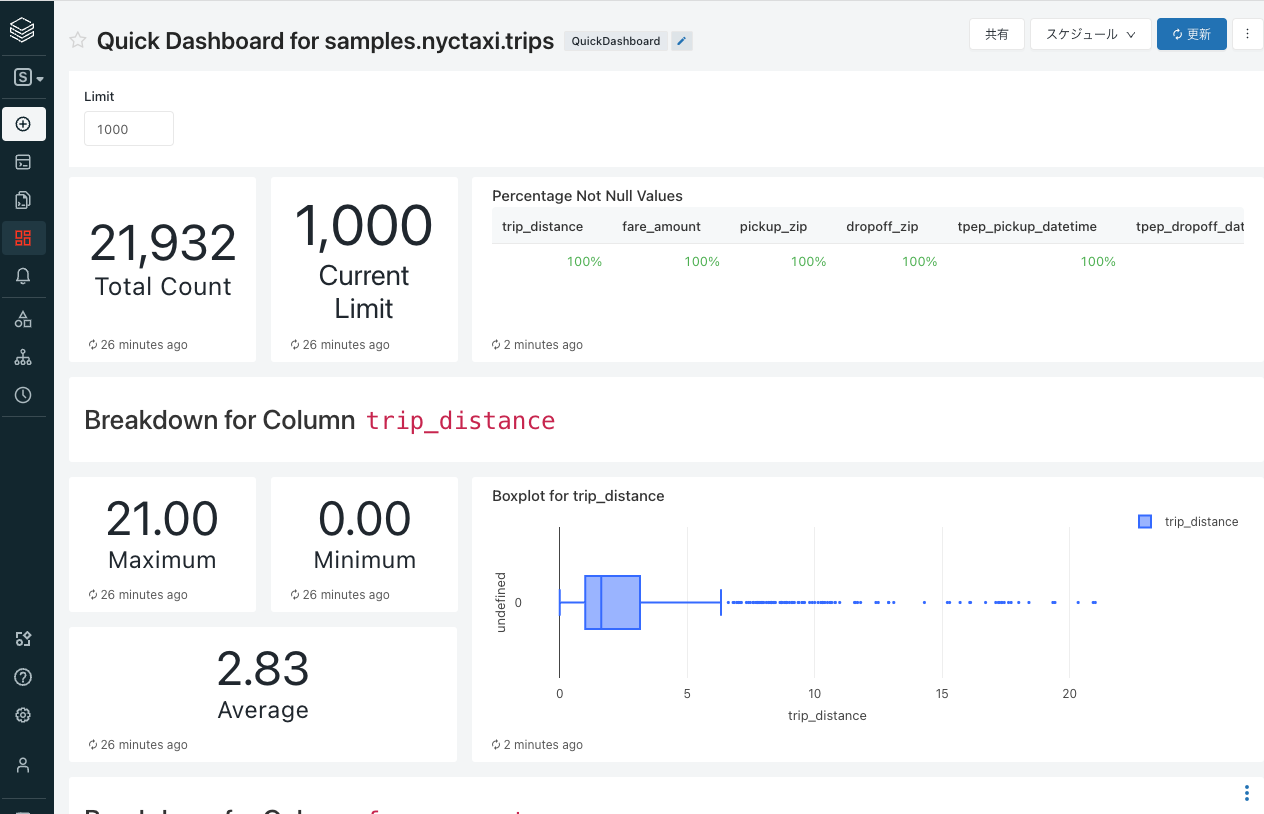
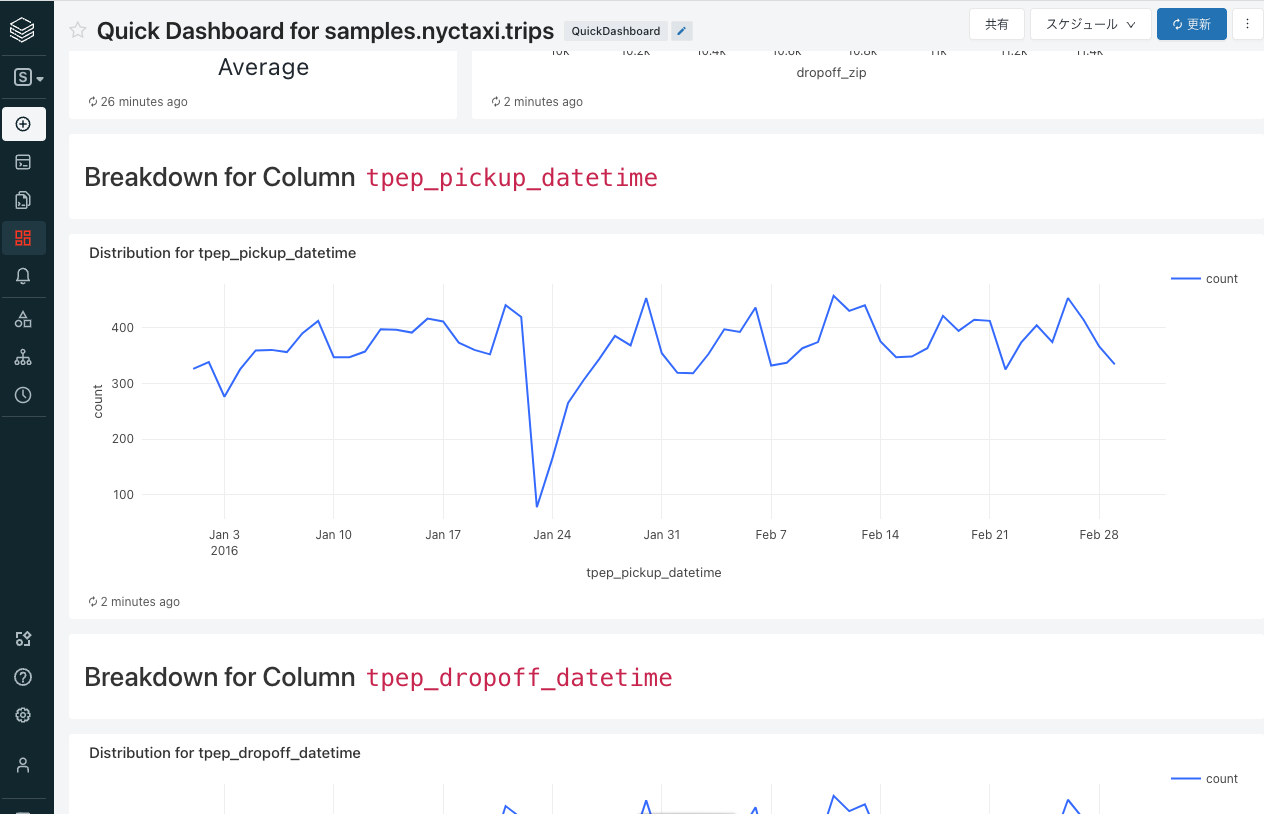
Databricks SQLを活用することで、シンプルなダッシュボードであればクリックのみの操作で作成することができます。
より機能的なダッシュボードを作成したい場合には、ローコードでDatabricks SQLダッシュボードを作成するをご覧ください。