こちらのノートブックのウォークスルーです。
このチュートリアルでは高階関数をウォークスルーします。こちらの詳細な記事では、配列の様な複雑なデータ型をSQLで取り扱うことが なぜ 重要であるのか、そして既存の実装がなぜ非効率的で手間のかかるものであるのかに関するモチベーション、正当性、コンセプトを説明していますが、このチュートリアルでは、IoTデバイスのイベントに含まれる構造化データと配列をSQLで処理する際に、 どのように 高階関数を使うのかを説明します。特に、あなたが関数型プログラミングに慣れているのであれば、これらを簡単かつ適切に活用することができ、これらの高階SQL関数の一部としてクイックかつ効率的にラムダ表現を記述することができます。
このチュートリアルでは、配列型を処理、変換する際に活用する4つの関数と、これらを様々なユースケースでどの様に活用するのかを探ります。
transform()filter()exists()aggregate()
この短いチュートリアルのテイクアウェイは、Spark SQLのユーティリティ関数を用いることで、ネストされたJSONの構造を切った張ったするための様々な手段が存在しているということです。これらの専用の高階関数は、主にSpark SQLでの配列の操作に適しており、配列あるいはネストされた配列を伴うテーブルの値を処理をより容易かつ簡潔なものにします。
少なくとも配列を持つ2つのカラム temp と c02_level を伴う属性と値からなるシンプルなJSONスキーマを作成しましょう。
from pyspark.sql.functions import *
from pyspark.sql.types import *
schema = StructType() \
.add("dc_id", StringType()) \
.add("source", MapType(StringType(), StructType() \
.add("description", StringType()) \
.add("ip", StringType()) \
.add("id", IntegerType()) \
.add("temp", ArrayType(IntegerType())) \
.add("c02_level", ArrayType(LongType())) \
.add("geo", StructType() \
.add("lat", DoubleType()) \
.add("long", DoubleType()))))
このヘルパーPython関数はJSON文字列をPythonデータフレームに変換します。
# Convenience function for turning JSON strings into DataFrames.
def jsonToDataFrame(json, schema=None):
# SparkSessions are available with Spark 2.0+
reader = spark.read
if schema:
reader.schema(schema)
return reader.json(sc.parallelize([json]))
上のスキーマを用いて、複雑なJSON構造を作成し、Pythonデータフレームに変換しましょう。データフレームを表示すると、埋め込まれたネスト構造を持つJSON文字列を持つキー(dc_id)とバリュー(source)の2つのカラムがあることがわかります。
dataDF = jsonToDataFrame( """{
"dc_id": "dc-101",
"source": {
"sensor-igauge": {
"id": 10,
"ip": "68.28.91.22",
"description": "Sensor attached to the container ceilings",
"temp":[35,35,35,36,35,35,32,35,30,35,32,35],
"c02_level": [1475,1476,1473],
"geo": {"lat":38.00, "long":97.00}
},
"sensor-ipad": {
"id": 13,
"ip": "67.185.72.1",
"description": "Sensor ipad attached to carbon cylinders",
"temp": [45,45,45,46,45,45,42,35,40,45,42,45],
"c02_level": [1370,1371,1372],
"geo": {"lat":47.41, "long":-122.00}
},
"sensor-inest": {
"id": 8,
"ip": "208.109.163.218",
"description": "Sensor attached to the factory ceilings",
"temp": [40,40,40,40,40,43,42,40,40,45,42,45],
"c02_level": [1346,1345, 1343],
"geo": {"lat":33.61, "long":-111.89}
},
"sensor-istick": {
"id": 5,
"ip": "204.116.105.67",
"description": "Sensor embedded in exhaust pipes in the ceilings",
"temp":[30,30,30,30,40,43,42,40,40,35,42,35],
"c02_level": [1574,1570, 1576],
"geo": {"lat":35.93, "long":-85.46}
}
}
}""", schema)
display(dataDF)

スキーマを確認すると、2つの要素がintegerの配列となっており、データフレームのスキーマが上で定義したスキーマを反映していることがわかるかと思います。
dataDF.printSchema()

カラムsourceを個別のカラムにexplodeするにはexplode()を使用します。
explodedDF = dataDF.select("dc_id", explode("source"))
display(explodedDF)
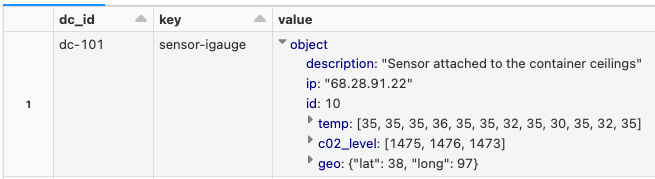
これで、個々のフィールドをフィールド名を用いて抽出するために、structであるvalueカラムを操作できる様になります。
#
# use col.getItem(key) to get individual values within our Map
#
devicesDataDF = explodedDF.select("dc_id", "key", \
"value.ip", \
col("value.id").alias("device_id"), \
col("value.c02_level").alias("c02_levels"), \
"value.temp")
display(devicesDataDF)
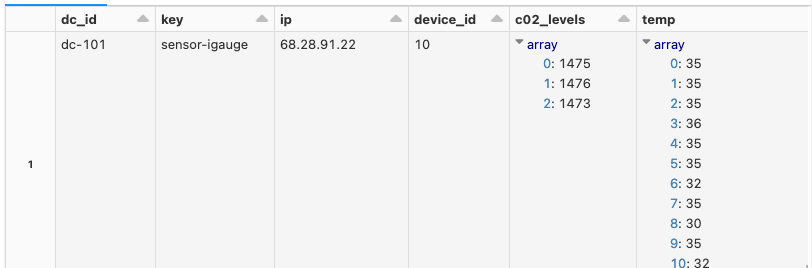
サニティチェックのために、explodeと個々のデータを抽出する過程を経て、データフレームとして何が保存されたのか、上述のスキーマに準拠しているのかを確認しましょう。
devicesDataDF.printSchema()

このチュートリアルではデータフレームAPIよりもSQLの高階関数と匿名関数にフォーカスを当てているので、一時テーブルかビューを作成し、上述した高階SQL関数を使い始めましょう。
devicesDataDF.createOrReplaceTempView("data_center_iot_devices")
データフレームのカラムと同じ様にテーブルが作成され、これはスキーマを反映したものとなります。
%sql select * from data_center_iot_devices

%sql describe data_center_iot_devices

SQLの高階関数とラムダエクスプレッション
transform()の使い方
この関数のシグネチャ transform(values, value -> lambda expression) には2つのコンポーネントがあります:
-
transform(values..)は高階関数です。これは、入力として配列と匿名関数を受け取ります。内部ではtransformは、新たな配列をセットアップし、それぞれの要素に匿名関数を適用し、出力の配列に結果を割り当てます。 -
value -> expressionは匿名関数です。この関数はさらに->シンボルで2つのコンポーネントに分割されます。
-
引数のリスト: この場合では引数は value 1つのみです。
(x, y) -> x + yのように、括弧で囲んだカンマ区切りの引数リストを作成することで、複数の引数を指定することができます。 - 本体: これは、新たな値を計算するために引数と外部の変数を使用するSQLのエクスプレッションです。
まとめると、transform()のプログラム的なシグネチャは以下の様になります。
transform(array<T>, function<T, U>): array<U>
入力であるarray<T>のそれぞれの要素にfunction<T, U>を適用することでarray<U>を変換します。
これは機能的にはmapと同じものであることに注意してください。(キーバリューエクスプレッションからmapを作成する)mapエクスプレッションとの混乱を避けるためにtransformと名付けられています。
transform(...)の基本的なこのスキームは、この後で実際に見ていきますが、他の高階関数と同じ様に動作します。
以下のクエリーは、それぞれの要素の気温の値を摂氏から華氏に変換することで配列の値を変換します。
すべての摂氏の値を華氏に変換しましょう。(変換式 ((C * 9) / 5) + 32 を使います。)ここでのラムダ表現はC->Fに変換を行う数式となります。
そして、tempと((t * 9) div 5) + 32が高階関数transform()の引数となります。匿名関数は、配列tempのそれぞれの要素に対してイテレーションを行い、関数を適用して値を変換し、出力配列に値を割り当てます。結果として変換された値を持つ新たなカラムfahrenheit_tempが得られます。
%sql select key, ip, device_id, temp,
transform (temp, t -> ((t * 9) div 5) + 32 ) as fahrenheit_temp
from data_center_iot_devices
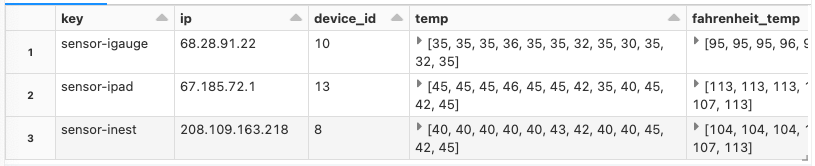
上のサンプルは変換された値を生成しましたが、以下の例ではラムダ関数としてtrueかfalseを返すt->t > 1300のブール値の表現を用い、値ではなくブール値の配列を生成します。
%sql select dc_id, key, ip, device_id, c02_levels, temp,
transform (c02_levels, t -> t > 1300) as high_c02_levels
from data_center_iot_devices

filter()の使い方
transformと同じ様に、filterはtransformと同様のシグネチャ filter(array<T>, function<T, Boolean>): array<T> を持っています。
ブール値のエクスプレッションを用いたtransform()と違い、これは述語function<T, Boolean>に合致する要素 のみ を入力配列から出力配列に追加します。
例えば、c02_levelsが危険なレベルを超える(cO2_level > 1300)ものだけを含めたいとしましょう。繰り返しになりますが、関数のシグネチャはtransform()と違いません。しかし、同じラムダ表現を用いた transform() と比較して、filter()がどのように配列を生成するのかに注意してください。
%sql select dc_id, key, ip, device_id, c02_levels, temp,
filter (c02_levels, t -> t > 1300) as high_c02_levels
from data_center_iot_devices

ラムダの述語を逆にした場合には、結果の配列が空になることに注意してください。これは、transform()のように値をtrueかfalseに評価しないためです。
%sql select dc_id, key, ip, device_id, c02_levels, temp,
filter (c02_levels, t -> t < 1300 ) as high_c02_levels
from data_center_iot_devices

exists()の使い方
上の2つの関数とは若干異なる関数のシグネチャを持ちますが、考え方はシンプルで同じものです。
exists(array<T>, function<T, V, Boolean>): Boolean
入力配列の中に述語function<T, Boolean>を満たすものがあるかどうかを返します。
この場合、配列tempに対してイテレーションを行い、配列の中に特定の値があるかどうかを確認します。お手元の配列に摂氏45度が含まれるのか、c02のレベルで1570に等しいものがあるのかを確認してみましょう。
%sql select dc_id, key, ip, device_id, c02_levels, temp,
exists (temp, t -> t = 45 ) as value_exists
from data_center_iot_devices

%sql select dc_id, key, ip, device_id, c02_levels, temp,
exists (c02_levels, t -> t = 1570 ) as high_c02_levels
from data_center_iot_devices

reduce()の使い方
この関数とメソッドは他のものよりも高度なものとなります。次のセクションで見る様に集計を行うこともできます。このシグネチャを用いることで、関数の引数として最後に来て擁するラムダ表現に加えて、追加の処理を行うことができます。
reduce(array<T>, B, function<B, T, B>, function<B, R>): R
function<B, T, B>を用いて、要素をバッファーBにマージし、最終的なバッファーに最後のfunction<B, R>を適用することで、array<T>の要素を単一の値Rにまとめます。Bの初期値はzeroエクスプレッションによって決定されます。
最後の関数はオプションです。最終化の関数を指定しない場合、何も変化させない関数(id -> id)が使用されます。これは、2つのラムダ関数を使う唯一の高階関数です。
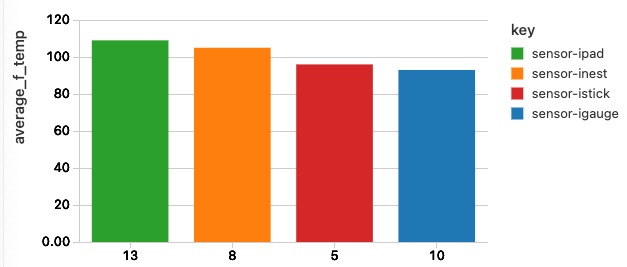
例えば、気温の平均を計算したい場合、ラムダ表現を使用します: 最初のものは、内部的かつ一時的なバッファにすべての結果を集約し、二つ目のものは最終的に集約されたバッファに適用されます。上述したシグネチャに関しては、Bは0、function<B,T,B>はt + acc、function<B,R>はacc div size(temp)となります。さらに、最終化のラムダ表現では、平均気温を華氏に変換しています。
%sql select key, ip, device_id, temp,
reduce(temp, 0, (t, acc) -> t + acc, acc-> (acc div size(temp) * 9 div 5) + 32 ) as average_f_temp
from data_center_iot_devices
sort by average_f_temp desc
同じ様に、ここではc02_levelsの平均を得るためにreduce()を使用します。
%sql select key, ip, device_id, c02_levels,
reduce(c02_levels, 0L, (t, acc) -> t + acc, acc-> acc div size(c02_levels)) as average_c02_levels
from data_center_iot_devices
sort by average_c02_levels desc
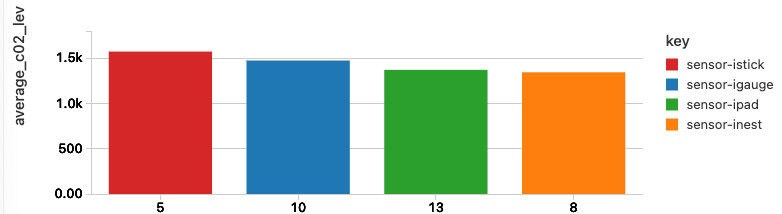
aggregate()の使い方
Aggregateはreduceの別名です。同じ入力を持ち、同じ結果を生成します。
c02のレベルのgeomeanを計算し、降順でソートしましょう。上述した関数のシグネチャを持つ複雑なラムダ表現に注意してください。
%sql select key, ip, device_id, c02_levels,
aggregate(c02_levels,
(1L as product, 0 as N),
(buffer, c02) -> (c02 * buffer.product, buffer.N + 1),
buffer -> Round(Power(buffer.product, 1.0 / buffer.N))) as c02_geomean
from data_center_iot_devices
sort by c02_geomean desc

IoT JSONデータを持つネスト構造を用いた別の例
以下のスキーマを持つデータフレームを作成し、問題がないかをチェックしましょう。
schema2 = StructType() \
.add("device_id", IntegerType()) \
.add("battery_level", ArrayType(IntegerType())) \
.add("c02_level", ArrayType(IntegerType())) \
.add("signal", ArrayType(IntegerType())) \
.add("temp", ArrayType(IntegerType())) \
.add("cca3", ArrayType(StringType())) \
.add("device_type", StringType()) \
.add("ip", StringType()) \
.add("timestamp", TimestampType())
dataDF2 = jsonToDataFrame("""[
{"device_id": 0, "device_type": "sensor-ipad", "ip": "68.161.225.1", "cca3": ["USA", "United States"], "temp": [25,26, 27], "signal": [23,22,24], "battery_level": [8,9,7], "c02_level": [917, 921, 925], "timestamp" :1475600496 },
{"device_id": 1, "device_type": "sensor-igauge", "ip": "213.161.254.1", "cca3": ["NOR", "Norway"], "temp": [30, 32,35], "signal": [18,18,19], "battery_level": [6, 6, 5], "c02_level": [1413, 1416, 1417], "timestamp" :1475600498 },
{"device_id": 3, "device_type": "sensor-inest", "ip": "66.39.173.154", "cca3": ["USA", "United States"], "temp":[47, 47, 48], "signal": [12,12,13], "battery_level": [1, 1, 0], "c02_level": [1447,1446, 1448], "timestamp" :1475600502 },
{"device_id": 4, "device_type": "sensor-ipad", "ip": "203.82.41.9", "cca3":["PHL", "Philippines"], "temp":[29, 29, 28], "signal":[11, 11, 11], "battery_level":[0, 0, 0], "c02_level": [983, 990, 982], "timestamp" :1475600504 },
{"device_id": 5, "device_type": "sensor-istick", "ip": "204.116.105.67", "cca3": ["USA", "United States"], "temp":[50,51,50], "signal": [16,16,17], "battery_level": [8,8, 8], "c02_level": [1574,1575,1576], "timestamp" :1475600506 },
{"device_id": 6, "device_type": "sensor-ipad", "ip": "220.173.179.1", "cca3": ["CHN", "China"], "temp": [21,21,22], "signal": [18,18,19], "battery_level": [9,9,9], "c02_level": [1249,1249,1250], "timestamp" :1475600508 },
{"device_id": 7, "device_type": "sensor-ipad", "ip": "118.23.68.227", "cca3": ["JPN", "Japan"], "temp":[27,27,28], "signal": [15,15,29], "battery_level":[0,0,0], "c02_level": [1531,1532,1531], "timestamp" :1475600512 },
{"device_id": 8, "device_type": "sensor-inest", "ip": "208.109.163.218", "cca3": ["USA", "United States"], "temp":[40,40,41], "signal": [16,16,17], "battery_level":[ 9, 9, 10], "c02_level": [1208,1209,1208], "timestamp" :1475600514},
{"device_id": 9, "device_type": "sensor-ipad", "ip": "88.213.191.34", "cca3": ["ITA", "Italy"], "temp": [19,28,5], "signal": [11, 5, 24], "battery_level": [0,-1,0], "c02_level": [1171, 1240, 1400], "timestamp" :1475600516 },
{"device_id": 10, "device_type": "sensor-igauge", "ip": "68.28.91.22", "cca3": ["USA", "United States"], "temp": [32,33,32], "signal": [26,26,25], "battery_level": [7,7,8], "c02_level": [886,886,887], "timestamp" :1475600518 },
{"device_id": 11, "device_type": "sensor-ipad", "ip": "59.144.114.250", "cca3": ["IND", "India"], "temp": [46,45,44], "signal": [25,25,24], "battery_level": [4,5,5], "c02_level": [863,862,864], "timestamp" :1475600520 },
{"device_id": 12, "device_type": "sensor-igauge", "ip": "193.156.90.200", "cca3": ["NOR", "Norway"], "temp": [18,17,18], "signal": [26,25,26], "battery_level": [8,9,8], "c02_level": [1220,1221,1220], "timestamp" :1475600522 },
{"device_id": 13, "device_type": "sensor-ipad", "ip": "67.185.72.1", "cca3": ["USA", "United States"], "temp": [34,35,34], "signal": [20,21,20], "battery_level": [8,8,8], "c02_level": [1504,1504,1503], "timestamp" :1475600524 },
{"device_id": 14, "device_type": "sensor-inest", "ip": "68.85.85.106", "cca3": ["USA", "United States"], "temp": [39,40,38], "signal": [17, 17, 18], "battery_level": [8,8,7], "c02_level": [831,832,831], "timestamp" :1475600526 },
{"device_id": 15, "device_type": "sensor-ipad", "ip": "161.188.212.254", "cca3": ["USA", "United States"], "temp": [27,27,28], "signal": [26,26,25], "battery_level": [5,5,5], "c02_level": [1378,1376,1378], "timestamp" :1475600528 },
{"device_id": 16, "device_type": "sensor-igauge", "ip": "221.3.128.242", "cca3": ["CHN", "China"], "temp": [10,10,11], "signal": [24,24,23], "battery_level": [6,5,6], "c02_level": [1423, 1423, 1423], "timestamp" :1475600530 },
{"device_id": 17, "device_type": "sensor-ipad", "ip": "64.124.180.215", "cca3": ["USA", "United States"], "temp": [38,38,39], "signal": [17,17,17], "battery_level": [9,9,9], "c02_level": [1304,1304,1304], "timestamp" :1475600532 },
{"device_id": 18, "device_type": "sensor-igauge", "ip": "66.153.162.66", "cca3": ["USA", "United States"], "temp": [26, 0, 99], "signal": [10, 1, 5], "battery_level": [0, 0, 0], "c02_level": [902,902, 1300], "timestamp" :1475600534 },
{"device_id": 19, "device_type": "sensor-ipad", "ip": "193.200.142.254", "cca3": ["AUT", "Austria"], "temp": [32,32,33], "signal": [27,27,28], "battery_level": [5,5,5], "c02_level": [1282, 1282, 1281], "timestamp" :1475600536 }
]""", schema2)
display(dataDF2)

dataDF2.printSchema()

上で行った様に、SQLクエリーを実行できる一時ビューを作成し、高階関数を用いた処理をいくつか行いましょう。
dataDF2.createOrReplaceTempView("iot_nested_data")
transform()の使い方
バッテリーレベルをチェックするためにtransformを使います。
%sql select cca3, device_type, battery_level,
transform (battery_level, bl -> bl > 0) as boolean_battery_level
from iot_nested_data
単体のtransform()関数にのみ制限されないことに注意してください。実際のところ、以下のコードが国名の大文字・小文字に変換している様に、複数の変換処理をチェーンすることができます。
%sql select cca3,
transform (cca3, c -> lcase(c)) as lower_cca3,
transform (cca3, c -> ucase(c)) as upper_cca3
from iot_nested_data

filter()の使い方
バッテリーレベルが5より低いデバイスをフィルタリングします。
%sql select cca3, device_type, battery_level,
filter (battery_level, bl -> bl < 5) as low_levels
from iot_nested_data
reduce()の使い方
%sql select cca3, device_type, battery_level,
reduce(battery_level, 0, (t, acc) -> t + acc, acc -> acc div size(battery_level) ) as average_battery_level
from iot_nested_data
sort by average_battery_level desc

%sql select cca3, device_type, temp,
reduce(temp, 0, (t, acc) -> t + acc, acc -> acc div size(temp) ) as average_temp
from iot_nested_data
sort by average_temp desc

%sql select cca3, device_type, c02_level,
reduce(c02_level, 0, (t, acc) -> t + acc, acc -> acc div size(c02_level) ) as average_c02_level
from iot_nested_data
sort by average_c02_level desc
以下のコードの様に、複数のreduce()関数を組み合わせたりチェーンすることができます。
%sql select cca3, device_type, signal, temp, c02_level,
reduce(signal, 0, (s, sacc) -> s + sacc, sacc -> sacc div size(signal) ) as average_signal,
reduce(temp, 0, (t, tacc) -> t + tacc, tacc -> tacc div size(temp) ) as average_temp,
reduce(c02_level, 0, (c, cacc) -> c + cacc, cacc -> cacc div size(c02_level) ) as average_c02_level
from iot_nested_data
sort by average_signal desc

サマリー
この短いチュートリアルでは、SQLにおける高階関数とラムダ表現の使いやすさをデモンストレーションし、ネストされた構造や配列のJSON属性を操作しました。データフレームやデータセットに希望する値をパースし、SQLのビューやテーブルとして保存することで、データフレームAPI、データセットAPIを用いるのと同じ様に、SQLで高階関数を用いることで容易にお手元の配列を操作、変換することができます。
最後になりますが、PythonやScalaでUDFを記述するよりも高階関数を活用する方が簡単です。なぜに関しては、ブログ記事SQL higher-order functionsをご覧ください。