こちらの「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」の翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
アブストラクト
我々は、我々の第一世代の推論モデルであるDeepSeek-R1-Zero とDeepSeek-R1をご紹介します。DeepSeek-R1-Zeroは準備ステップとして教師ありファインチューニング(SFT)なしに、大規模強化学習(RL)を通じてトレーニングされたモデルであり、特筆すべき推論能力を示しています。RLを通じて、DeepSeek-R1-Zeroは数多くのパワフルで興味深い推論の挙動を自然に導き出します。しかし、貧弱な可読性や言語の混在のような課題に直面しています。これらの問題に対応し、推論性能をさらに高めるために、RLの前にマルチステージのトレーニングとコールドスタートを取り入れたDeepSeek-R1をご紹介します。DeepSeek-R1は、推論タスクにおいてOpenAI-o1-1217に比類する性能を達成しています。研究コミュニティをサポートするために、我々はDeepSeek-R1-Zero、DeepSeek-R1と、QwenとLlamaをベースとしてDeepSeek-R1から蒸留した6つの密モデル(1.5B, 7B, 8B, 14B, 32B, 70B)をオープンソース化します。
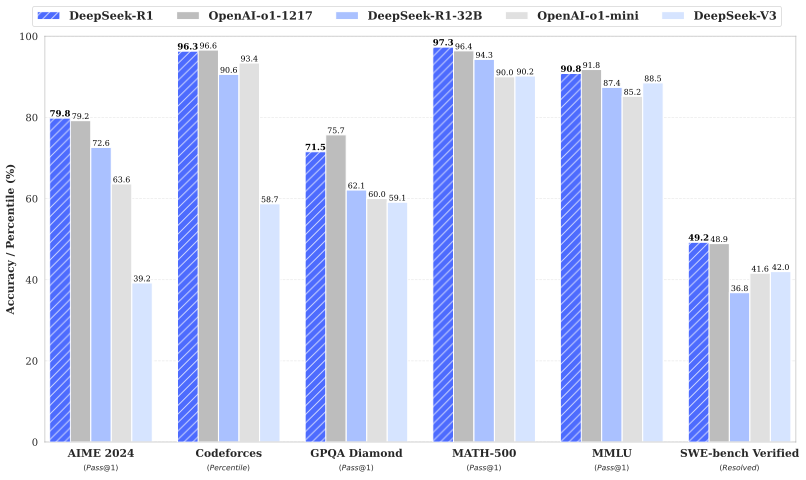
図1. DeepSeek-R1のベンチマーク
1. イントロダクション
近年において、大規模言語モデル(LLM)は迅速なイテレーションと進化(Anthropic, 2024; Google, 2024; OpenAI, 2024a)を体験しており、人工汎用インテリジェンス(AGI)へのギャップを徐々に縮めています。
最近、完全なトレーニングパイプラインの重要なコンポーネントとして、事後トレーニングが注目されています。論理的思考タスクにおける精度を改善し、社会的価値とアラインし、ユーザーの嗜好に適応しつつも、事前トレーニングに対して比較的最小と言える計算リソースしか必要としないということが示されています。論理的思考能力の文脈においては、OpenAIのo1(OpenAI, 2024b)シリーズモデルが、チェーンオブソートプロセスの長さを増加させることで推論時間のスケーリングを初めて導入しました。このアプローチによって、数学、コーディング、科学的論理思考のようなさまざまな論理的思考タスクにおいて劇的な改善を達成しました。しかし、効果的なテスト時間のスケーリングの課題は、いまだに研究コミュニティにおけるオープンな質問であり続けています。いくつかのこれまでの取り組みにおいては、プロセスベースの報奨モデル (Lightman et al., 2023; Uesato et al., 2022; Wang et al., 2023)、強化学習(Kumar et al., 2024)、Monte Carlo Tree SearchやBeam Searchのような検索アルゴリズム(Feng et al., 2024; Trinh et al., 2024; Xin et al., 2024)のようにさまざまなアプローチが探索されています。しかし、これらの手法のいずれも、OpenAIのo1シリーズモデルと同等の汎用的な論理的思考のパフォーマンスを達成できていません。
本論文では、純粋な強化学習(RL)を用いた言語モデルの論理的思考能力の改善に向けた第一歩を踏み出します。我々のゴールは、いかなる教示データを用いることなしに論理的思考能力を開発するためのLLMのポテンシャルを探索することであり、純粋なRLプロセスを通じたLLMの自己進化にフォーカスします。特に、ベースモデルとして我々はDeepSeek-V3-Baseを用い、論理的思考におけるモデルのパフォーマンスを改善するためのRLフレームワークとしてGRPO(Shao et al., 2024)を活用します。トレーニングの過程で、DeepSeek-V3-Baseは数多くのパワフルで興味深い論理的思考の挙動を自然に生み出しました。数千のRLステップののち、DeepSeek-R1-Zeroは論理的思考のベンチマークにおいて凄まじいパフォーマンスを示しています。例えば、AIME 2024のpass@1スコアは15.6%から71.0%に増加し、さらに多数決投票を用いることで、OpenAI-o1-0912のパフォーマンスとマッチする86.7%まで改善しました。
しかし、DeepSeek-R1-Zeroは、貧弱な可読性や言語の混在のような課題に直面しています。これらの問題に対応し、論理的思考のパフォーマンスをさらに改善するために、小規模なコールドスタートデータとマルチステージのトレーニングパイプラインを組み込んだDeepSeek-R1を導入しました。特に、我々はDeepSeek-V3-Baseモデルをファンチューンするために、数千のコールドスタートデータの収集からスタートしました。これに次いで、DeepSeek-R1-Zeroのように、論理的思考向けのRLを実施しました。RLプロセスにおける収束に近づくと、RLチェックポイントにおける却下サンプリングを通じて新たなSFTデータを作成し、記述、事実に基づくQA、自己認識のようなドメインにおけるDeepSeek-V3からの教師データと組み合わせ、DeepSeek-V3-Baseモデルを再トレーニングしました。新規データによるファインチューイニングののち、チェックポイントには更なるRLプロセスが適用され、すべてのシナリオのプロンプトを考慮するようにしました。これらのステップを経て、OpenAI-o1-1217と同等のパフォーマンスを達成するDeepSeek-R1と呼ばれるチェックポイントを獲得しました。
我々はDeepSeek-R1をより小さなdenseモデルに蒸留することを探索しました。ベースモデルとしてQwen2.5-32B (Qwen, 2024b)を用いた、DeepSeek-R1からの直接の蒸留によって、RLを適用するよりも高い性能を示しました。これは、論理的思考能力を改善するには、より大きなベースモデルを用いることで発見される論理的思考パターンが重要であることを示しています。我々は蒸留したQwenとLlama (Dubey et al., 2024)シリーズをオープンソース化しました。特筆すべき点として、我々の蒸留した14Bモデルは非常に大きなマージンで最先端のオープンソースQwQ-32B-Preview (Qwen, 2024a)を上回り、蒸留した32Bと70Bモデルはdenseモデルにおける論理的思考ベンチマークにおいて新記録を達成しました。
1.1 貢献した要因
事後トレーニング: ベースモデルに対する大規模な強化学習
- 準備ステップとして、我々は教師ありファインチューニング(SFT)に頼ることなしに、ベースモデルに対して直接RLを適用しました。このアプローチによって、複雑な問題を解決するためにモデルはチェーンオブソート(CoT)を探索することができ、DeepSeek-R1-Zeroへとつながりました。DeepSeek-R1-Zeroは、事故検証、振り返り、長いCoTの生成のような能力を示し、研究コミュニティに大きなマイルストーンを示しました。特筆すべきこととして、SFTを必要とすることなしに純粋なRLを通じてLLMの倫理的思考能力の動機づけを行うことができるということを検証する初のオープンな研究であるということです。このブレイクスルーは、この領域における今後の前進に向けた道筋をつけたことになります。
- 我々はDeepSeek-R1を開発するためにパイプラインを導入しました。このパイプラインは、改善された論理的思考パターンを発見し、人間の嗜好との平仄をとることを狙いとした2つのRLステージと、モデルの論理的思考と論理的思考以外の能力のシードとして動作する2つのSFTステージを組み込んでいます。我々は、このパイプラインがより良いモデルを作ることで業界の利益になると信じています。
蒸留: 小規模なモデルもパワフルになることができる
- 我々は大規模なモデルの論理的思考のパターンを小規模なモデルに蒸留できることを示し、小規模なモデルにおけるRLを通じて発見される論理的思考のパラんーに比べて優れたパフォーマンスにつながることを示しました。オープンソースのDeepSeek-R1とそのAPIは、将来的により小さく、より優れたモデルを蒸留することで研究コミュニティの利益になることでしょう。
- DeepSeek-R1によって生成された倫理的思考のデータを用いることで、研究コミュニティで広く使用される幾つかのdenseモデルをファインチューンしました。評価結果では、蒸留された小規模なdensモデルはベンチマークにおいて非常に優れた動作をすることが示されています。DeepSeek-R1-Distill-Qwen-7Bは、AIME 2024においてQwQ-32B-Previewを上回る55.5%を達成しています。さらに、DeepSeek-R1-Distill-Qwen-32BはAIME 2024で72.6%、MATH-500で94.3%、LiveCodeBenchで57.2%のスコアを出しています。これらの結果は、以前のオープンソースモデルを大きく上回っており、o1-miniと同等のものとなっています。我々はQwen2.5とLlama3をベースとして蒸留した1.5B, 7B, 8B, 14B, 32B, 70Bのチェックポイントをコミュニティにオープンソース化しました。
1.2 評価結果のサマリー
- 論理的思考タスク: (1) AIME 2024においてDeepSeek-R1は79.8% Pass@1スコアを示しており、OpenAI-o1-1217を若干上回っています。MATH-500においては、印象的な97.3%のスコアを示しており、OpenAI-o1-1217と同等であり、その他のモデルを大きく上回っています。(2) コーディング関係のタスクにおいては、DeepSeek-R1はコードコンペのタスクにおいて専門家レベルを示しており、Codeforcesにおいては2,029 Eloレーティングを達成し、コンペの人間の参加者の96.3%を上回っています。エンジニアリング関係のタスクにおいては、DeepSeek-R1はDeepSeek-V3よりも若干優れた性能を示しており、現実世界のタスクにおいて開発者の助けとなることでしょう。
- 知識: MMLU、MMLU-Pro、GPQA Diamondのようなベンチマークにおいて、DeepSeek-R1は特筆すべき結果を示し、MMLUでは90.8%、MMLU-Proでは84.0%、GPQA Diamondでは71.5%となっており、DeepSeek-V3を大きく上回るスコアとなっています。このパフォーマンスはこれらのベンチマークにおいてOpenAI-o1-1217よりも若干低いものですが、DeepSeek-R1は他のクローズドソースモデルを上回っており、教育的なタスクにおける競争力を示しています。SimpleQAの事実に基づくベンチマークにおいては、DeepSeek-R1はDeepSeek-V3を上回っており、事実に基づく問い合わせへの対応能力を示しています。このベンチマークにおいてはOpenAI-o1が4oを上m割ったのと同じようなトレンドが観測されています。
- その他: また、DeepSeek-R1はクリエイティブなライティング、汎用的なQ&A、編集、要約などを含む幅広いタスクにも秀でています。AlpacaEval 2.0においては印象的な長さが制御された87.6%の勝率、ArenaHardでは92.3%の勝率を示しており、試験指向ではない問い合わせをインテリジェントに対応する強力な能力を示しています。さらに、DeepSeek-R1は長いコンテキストの理解を必要とするタスクで非常に優れたパフォーマンスを示しており、長コンテキストベンチマークにおいては、DeepSeek-V3を大きく上回っています。
2. アプローチ
2.1 概要
これまでの取り組みは、モデルのパフォーマンスを強化するために大量の教師データに過度に依存していました。この研究では、コールドスターとして教師ありファインチューニング(SFT)すらを用いることなしに、大規模な強化学習(RL)を通じて論理的思考能力を大幅に改善できるということを示します。さらに、小規模のコールドスタートデータを含めることで、パフォーマンスをさらに改善することができます。以下のセクションでは、以下を示します: (1) SFTデータを用いずにベースモデルに直接RLを適用するDeepSeek-R1-Zero、(2) 数千の長いチェーンオブソート(CoT)の例でファインチューンしたチェックポイントからスタートしてRLを適用したDeepSeek-R1、(3) DeepSeek-R1から小規模なdenseモデルへの論理的思考能力の蒸留。
2.2 DeepSeek-R1-Zero: ベースモデルに対する強化学習
我々の以前の取り組み(Shao et al., 2024; Wang et al., 2023)による成果が示すように、論理的思考タスクにおいて強化学習は非常に優れた有効性を示しました。しかし、これらの取り組みは収集に時間を要する教師データに過度に依存していました。このセクションでは、いかなる教師データを用いずに論理的思考能力を開発するためにのLLMのポテンシャルを探索し、純粋な強化学習プロセスを通じたLLMの自己進化にフォーカスします。RLアルゴリズムの簡単な説明からスタートし、いくつかの素晴らしい結果を示すことで、価値のある洞察をコミュニティに提供できればと考えています。
2.2.1 強化学習アルゴリズム
グループ相対ポリシー最適化 RLのコストを節約するために、我々はポリシーモデルと通常は同じサイズである批判モデルが先んじ、グループスコアからベースラインを推定するGroup Relative Policy Optimization (GRPO) (Shao et al., 2024)を導入しました。特に、それぞれの質問qに対して、GRPOは過去のポリシー𝜋𝜃𝑜𝑙𝑑からのアウトプットのグループ{𝑜1, 𝑜2,··· , 𝑜𝐺}をサンプリングし、以下の目標を最大化することでポリシーモデル𝜋𝜃を最適化します。
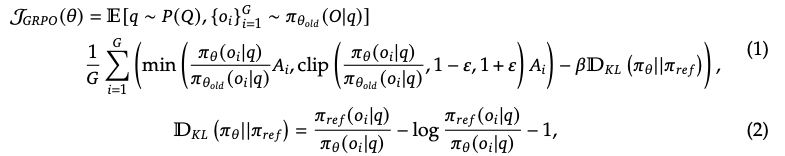
ここでは、𝜀と𝛽はハイパーパラメータであり𝐴𝑖はアドバンテージであり、それぞれのグループにおけるアウトプットに対応する報奨のグループ{𝑟1, 𝑟2, ..., 𝑟𝐺}を用いて計算されます。
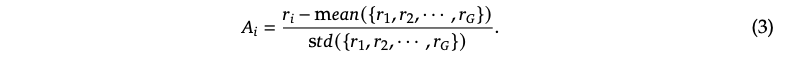

表1: DeepSeek-R1-Zeroのテンプレート。トレーニングの過程では特定の論理的思考に関する質問でpromptが置き換えられます。
2.2.2 報奨モデリング
報奨はRLの最適化の方向を決定するトレーニングシグナルのソースです。DeepSeek-R1-Zeroをトレーニングするために、主に二つのタイプの報奨から構成されるルールベースの法相システムを導入しました:
- 精度の報奨: 精度報奨モデルはレスポンスが正しいかどうかを評価します。例えば、決定論的な結果を伴う数学の問題では、モデルは指定されたフォーマットで最終回答を提供することが求められるので、信頼性のあるルールベースの正しさの検証が可能となります。同様に、LeetCode問題においては、事前定義されたテーストケースに基づいたフィードバックを生成するためにコンパイラを使うことができます。
-
フォーマットの報奨: 精度報奨モデルに加え、
<think>と</think>タグの間に思考プロセスを埋め込むことをモデルに強制するフォーマット報奨モデルを採用しています。
ニューラル報奨モデルは大規模な強化学習プロセスにおいて、報奨のハッキングに苦しむことがあることを発見し、報奨モデルの再トレーニングには追加のトレーニングリソースを必要とし、全体的なトレーニングパイプラインを複雑にするため、DeepSeek-R1-Zeroの開発ではニューラル報奨モデルの成果を活用したり処理したりはしていません。
2.2.3 トレーニングテンプレート
DeepSeek-R1-Zeroをトレーニングするために、ベースモデルが我々が指定した指示に準拠するようにするためのガイドとなる分かりやすいテンプレートの設計からスタートしました。表1に示しているようにこのテンプレートでは、最初に論理的思考プロセスを生成し、その後に最終回答を生成することをDeepSeek-R1-Zeroに求めています。RLプロセスの過程でモデルの自然な前進を正確に観測できるように、思慮深い指向の強制や特定の問題解決戦略のプロモーションのようなコンテンツ固有のバイアスを避けるために、我々は意図的にこの構造的なフォーマットに対する我々の制約を制限しています。
2.2.4 DeepSeek-R1-Zeroのパフォーマンス、自己進化プロセスとAhaモーメント
DeepSeek-R1-Zeroのパフォーマンス
図2ではRLトレーニングプロセスを通じたAIME 2024におけるDeepSeek-R1-Zeroのパフォーマンスの軌跡を示しています。示されているように、DeepSeek-R1-ZeroはRLトレーニングが進むと安定して一貫性のある改善を示しています。特筆すべき点として、AIME 2024における平均pass@1スコアは大きく改善しており、最初の15.6%から71.0%へとジャンプしており、OpenAI-o1-0912と同等のパフォーマンスレベルに到達しています。この大きな改善は、モデルのパフォーマンスの最適化における我々のRLアルゴリズムの効率性をハイライトしています。
表2では、さまざまな論理的思考関係のベンチマークにおけるDeepSeek-R1-ZeroとOpenAIのo1-0912の間の比較分析結果を示しています。
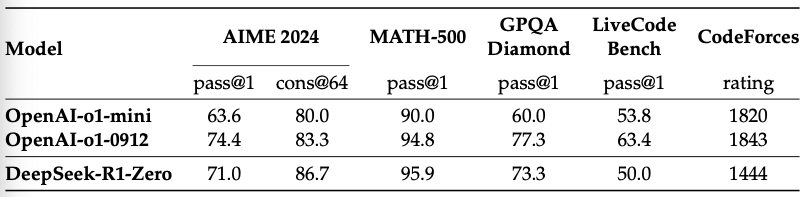
表2: 論理的思考関係のベンチマークにおけるDeepSeek-R1-ZeroとOpenAIのo1モデルの比較
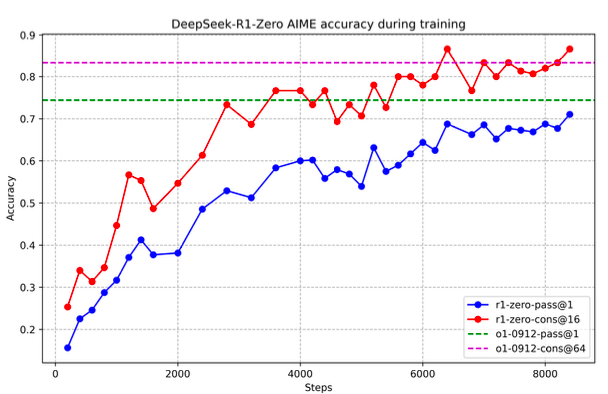
図2: トレーニング過程におけるDeepSeek-R1-ZeroのAIMEの精度。安定した評価を確実にするために、それぞれの質問において16のレスポンスをサンプリングし、全体平均精度を計算しました。
この発見は、RLはDeepSeek-R1-Zeroがいかなるファインチューニングデータを必要とすることなしに、堅牢な論理的思考能力を獲得する助けとなっていることを明らかにしました。これは、RL単体を通じて効果的に学習、汎化するモデルの能力を強調している特筆すべき成果です。さらに、多数決を適用することで、DeepSeek-R1-Zeroのパフォーマンスをさらに拡張することができます。例えば、AIMEベンチマークで多数決を採用すると、DeepSeek-R1-Zeroのパフォーマンスは71.0%から86.7%へと向上し、OpenAI-o1-0912のパフォーマンスを上回りました。多数決の有無に関係なく、このように競争力のあるパフォーマンスを達成するためのDeepSeek-R1-Zeroの能力は、論理的思考タスクにおける強力な基礎能力と更なる進歩をハイライトしています。
DeepSeek-R1-Zeroの自己進化プロセス DeepSeek-R1-Zeroの自己進化プロセスは、モデルが自律的に論理的思考能力を改善するために、RLがどのようにモデルをドライブするのかに関する素晴らしいデモンストレーションとなっています。ベースモデルから直接RLを起動することで、教師ありファインチューニングステージの影響を受けることなしにモデルの進化を近くで監視することができます。このアプローチは、モデルが時間と共にどのように進化するのか、特に複雑な論理的思考タスクに対応する能力に関して、クリアなビューを提供します。
図3に示すように、トレーニングプロセスを通じてDeepSeek-R1-Zeroの思考時間は一定の改善を示しています。
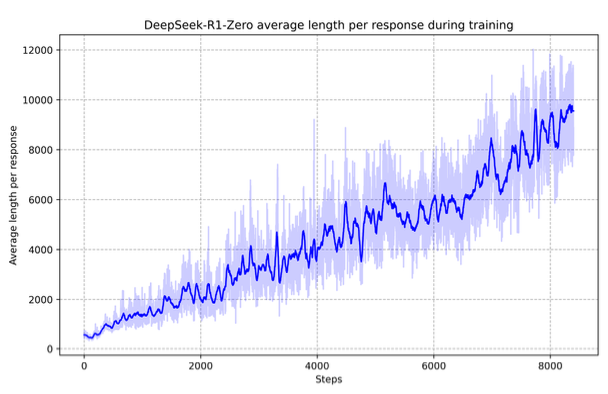
図3: RLプロセスにおけるトレーニングセットに対するDeepSeek-R1-Zeroの平均レスポンス長。DeepSeek-R1-Zeroはより長い思考時間によって、論理的思考タスクを解決するために自然に学習を行います。
この改善は外部での調整ではなく、モデル内における本来備わっている発展による結果です。DeepSeek-R1-Zeroは、拡張されたテスト時の計算処理を活用することで、より複雑な論理的思考タスクを解決するための能力を自然に獲得しています。この計算処理は、数百から数千の論理的思考のトークンの生成にわたるものであり、モデルがより深く思考プロセスを探索、洗練できるようにしています。
この自己進化の最も特筆すべき側面の一つは、テスト時の計算処理が増加するとより洗練された挙動が現れるということです。モデルが事前のステップを再訪、再評価する振り返り、問題解決のための別のアプローチの探索のような挙動は自発的に発生します。これらの挙動は、明示的にプログラムされておらず、強化学習環境でのモデルのインタラクションの結果として出現します。この自発的な発展は、DeepSeek-R1-Zeroの論理的思考応力を大きく強化し、より優れた効率性と精度によってより困難なタスクに取り組めるようになります。
DeepSeek-R1-ZeroのAhaモーメント DeepSeek-R1-Zeroのトレーニングの際に観測された特に興味深い減少は「Ahaモーメント」の発生です。このモーメントは、表3に示しているようにモデルの中間バージョンで発生します。このフェーズを通じて、DeepSeek-R1-Zeroは最初のアプローチを再評価することで、問題に対してより多くの思考時間を割り当てることを学習します。この挙動はモデルの論理的思考能力を成長させる照明だけではなく、どのようにして強化学習が予期しない洗練された成果につながりうるのかを示す魅力的な例となっています。
このモーメントはモデルの「Ahaモーメント」であるだけでなく、挙動を観測している研究者にとってのものでもあります。これは、強化学習の力と美しさを強調しています: 問題をdのように解くのかをモデルに明示的に教えるのではなく、シンプルに適切なインセンティブを提供するとモデルは自律的に高度な問題解決戦略を生み出します。この「Ahaモーメント」は、人工システムにおける新たなレベルの知性を解放するRLのポテンシャルのパワフルなリマインダーとして動作し、未来のより自律的で適応的なモデルへの道ならしをします。

表3: DeepSeek-R1-Zeroの中間バージョンの興味深い「Ahaモーメント」。モデルは人間のようなトーンを用いて再考することを学習します。また、これは我々にとってもAhaモーメントであり、強化学習の力と美しさを目撃させてくれます。
DeepSeek-R1-Zeroの欠点 DeepSeek-R1-Zeroは強力な論理的思考能力を示し、予期しないパワフルな論理的思考の挙動を発展させますが、いくつかの問題に直面しています。例えば、DeepSeek-R1-Zeroは貧弱な可読性や言語の混合のような課題に苦戦しています。論理的思考プロセスをより可読性のあるものにし、オープンコミュニティと共有するために、DeepSeek-R1、RLと人間に優しいコールドスタートデータを活用する手法を探索します。
2.3 DeepSeek-R1: コールドスタートを用いた強化学習
DeepSeek-R1-Zeroの期待できる成果にインスパイアされ、自然に2つの疑問が起きました: 1) コールドスタートとして少量の高品質データを組み込むことで、論理的思考のパフォーマンスをさらに改善したり、収束を加速することができないか? 2) 明確で一貫性のあるチェーンオブソート(CoT)を生成するだけはなく、強力な汎用能力を示すユーザーフレンドリーなモデルをどのようにトレーニングできるのか?これらの疑問に取り組むため、我々はDeepSeek-R1をトレーニングするためのパイプラインを設計しました。以下で説明するように、このパイプラインは4つのステージから構成されます。
2.3.1 コールドスタート
RLトレーニングの初期の不安定なコールドスタートフェーズをベースモデルから取り除いたDeepSeek-R1-Zeroとは違い、DeepSeek-R1では初期のRLアクターとしてモデルをファインチューンするために、少量の長いCoTデータを構成、収集しました。このようなデータを収集するために、我々はいくつかのアプローチを探索しました: 例としての長いCoTを用いたfew-shotプロンプティングの活用、振り返りや検証を伴う詳細な回答を生成するためにモデルへの直接のプロンプト、可読性のあるフォーマットでのDeepSeek-R1-Zeroのアウトプットの収集、人間のアノテーターによる後処理を通じた結果の洗練などです。
この取り組みにおいて、RLのスタート地点としてDeepSeek-V3-Baseをファインチューニングするための数千のコールドスタートデータを収集しました。DeepSeek-R1-Zeroと比べて、コールドスタートデータの利点には以下のようなものがあります:
- 可読性: DeepSeek-R1-Zeroの主な制限は、コンテントが多くの場合において読むことに適していないということでした。レスポンスには複数の言語が混在したり、ユーザーへの回答をハイライトするためのマークダウンフォーマットが欠如していました。対照的に、DeepSeek-R1のためにコールドスタートデータを作成する際に、それぞれのレスポンスの最後に要約を含め、読み手に優しくないレスポンスを除外する可読性のあるパターンを設計しました。ここでは、出力フォーマットを
|special_token|<reasoning_process>|special_token|<summary>として設計し、ここでは、論理的思考プロセスはクエリーに対するCoTであり、論理的思考の結果を要約するためにsummaryが使用されます。 - ポテンシャル: 人間の手によるコールドスタートデータに対するパターンを注意深く設計することで、DeepSeek-R1-Zeroよりも優れたパフォーマンスを観測しました。我々は、論理的思考モデルにおいては繰り返しのトレーニングがより良い方法であると信じています。
2.3.2 論理的思考重視の強化学習
コールドスタートデータでDeepSeek-V3-Baseをファインチューニングしたら、DeepSeek-R1-Zeroで採用されたのと同じ大規模強化学習トレーニングプロセスを適用します。このフェーズでは、特にコーディング、数学、科学、明確な回答がある適切に定義された問題を含む論理的な思考のように論理的思考が高度に求められるタスクにおけるモデルの論理的思考能力の強化にフォーカスしています。このトレーニングプロセスの過程で、多くの場合、特にRLのプロンプトに複数の言語が含まれている場合にCoTに言語の混合が起きることを観察しました。言語混合の問題を軽減するために、CoTにおけるターゲットの言語の比率として計算される言語一貫性報奨を導入しました。切除実験ではこのような調整はモデルのパフォーマンスに若干の劣化を引き起こしましたが、この報奨は人間の嗜好に適合しており、可読性を改善しました。最後に、最終的な報奨を形成するために、論理的思考タスクの精度と言語一貫性の報奨を直接足し合わせることで組み合わせました。そして、論理的思考タスクが収束するまで、ファインチューニングしたモデルに対してRLトレーニングを適用しました。
2.3.3 棄却サンプリングと教師ありファインチューニング
論理的思考重視のRLが収束すると、我々は以降のラウンドのためのSFT(教師ありファインチューニング)データを収集するために、結果として得られたチェックポイントを活用しました。論理的思考に主にフォーカスしている初期のコールドスタートデータと異なり、このステージではライティング、ロールプレイ、そのほかの汎用タスクにおけるモデルの能力を強化するために、ほかのドメインのデータを組み込みます。特に、我々は以下で説明しているように、データを生成し、モデルをファインチューニングしました。
論理的思考データ 上述のRLトレーニングのチェックポイントからの棄却サンプリングを実施することで、論理的思考のプロンプトをキュレーションし、論理的思考の軌跡を生成しました。以前のステージでは、ルールベースの報奨を用いて検証できるデータのみを含めました。しかし、このステージでは追加データを組み込むことでデータセットを拡張します。これらのデータのいくつかは、審判としてDeepSeek-V3に正解データとモデルの推論結果を与えることで生成される法相を用いています。さらに、モデルの出力は時にはカオスで読みにくいため、言語が混在しているチェーンオブソート、段落が長い、コードブロックを除外しました。それぞれのプロンプトにおいて、複数のレスポンスをサンプリングし、正しいもののみを保持しました。結果として、600kの論理的思考に関係するトレーニングサンプルを収集しました。
論理的思考以外のデータ ライティング、事実に基づくQ&A、自己認識、翻訳のような論理的思考以外のデータに関しては、DeepSeek-V3のパイプラインを導入し、DeepSeek-V3のSFTデータセットのポーションを再利用しました。特定の論理的思考以外のタスクにおいては、プロンプティングで質問に回答する前に可能性のあるチェーンオブソートを生成するために、DeepSeek-V3を呼び出しました。しかし、「hello」のようなよりシンプルなクエリーに対しては、レスポンスでCoTを提供しませんでした。結果として、論理的思考と関係のない約200kのトレーニングサンプルを収集しました。
約800kのサンプルを持つキュレーションされたデータセットを用いて、2エポックでDeepSeek-V3-Baseをファインチューンしました。
2.3.4 すべてのシナリオのための強化学習
モデルをさらに人間の嗜好に合わせるために、我々はモデルの有用性と無害性を改善するのと同時に論理的思考能力を洗練することを狙いとした二次強化学習ステージを実装しました。特に、報奨シグナルとさまざまなプロンプトのバリエーションの組み合わせを用いてモデルをトレーニングしました。論理的思考データにおいては、数学、コーディング、論理的思考両領域における学習プロセスをガイドするためにルールベースの報奨を活用したDeepSeek-R1-Zeroで説明した方法論に準拠しました。一般的なデータにおいては、複雑で微妙なシナリオにおける人間の嗜好を捕捉するようにモデルに報奨を与えることに落ち着きました。DeepSeek-V3のパイプラインをベースに構築を行い、同様の分布を持つ嗜好のペアとトレーニングプロンプトを導入しました。有用性に関しては、最終的なサマリーに特別にフォーカスし、評価においてユーザーに対するレスポンスの有用性と適切性が強調されるようにしつつも、背後の論理的思考プロセスへの干渉を最小化するようにしました。無害性に関しては、生成プロセスにおいて生じうるいかなる潜在的なリスク、バイアス、有害なコンテンツを特定、軽減するために、論理的思考プロセスとサマリーの両方を含むモデルのレスポンス全体を評価しました。最終的には、報奨シグナルとさまざまなデータのインテグレーションによって、論理的思考に秀でているだけではなく、有用性と無害性に優先度を置いたモデルをトレーニングすることができました。
2.4 蒸留: 論理的思考能力で小規模モデルを強化
DeepSeek-R1のような論理的思考能力を持つより効率的で小さいモデルで装備を固めるために、§2.3.3で詳細を説明しているように、DeepSeek-R1でキュレーションした800kのサンプルを用いてQwen (Qwen, 2024b)やLlama (AI@Meta, 2024)のようなオープンソースのモデルを直接ファインチューンしました。このわかりやすい蒸留手法は小規模なモデルの論理的思考能力を劇的に改善することがわかりました。ここで用いたベースモデルは、Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B、Llama-3.3-70B-Instructです。Llama-3.3はLlama-3.1よりも論理的思考能力が若干優れていたのでこちらを選択しました。
蒸留されたモデルにおいては、SFTのみを適用し、RLはモデルのパフォーマンスを劇的に改善し得ますがRLを含めていません。我々の主要なゴールは、蒸留テクニックの効果を示すことであり、RLステージの探索はより広範な研究コミュニティに委ねます。
3. 実験
ベンチマーク MMLU (Hendrycks et al., 2020)、MMLU-Redux (Gema et al., 2024)、MMLU-Pro (Wang et al., 2024)、C-Eval (Huang et al., 2023)、CMMLU (Li et al., 2023)、IFEval (Zhou et al., 2023)、FRAMES (Krishna et al., 2024)、GPQA Diamond (Rein et al., 2023), SimpleQA (OpenAI, 2024c), C-SimpleQA (He et al., 2024)、SWE-Bench Verified (OpenAI, 2024d)、Aider、LiveCodeBench (Jain et al., 2024) (2024-08 – 2025-01)、Codeforces、Chinese National High School Mathematics Olympiad (CNMO 2024)、American Invitational Mathematics Examination 2024 (AIME 2024) (MAA, 2024)でモデルを評価しました。標準的なベンチマークに加え、LLMs as judgesを用いたオープンエンドの生成タスクでもモデルを評価しました。特に、ペアごとの比較のために審判としてGPT-4-Turbo-1106を活用したAlpacaEval 2.0 (Dubois et al., 2024) and Arena-Hard (Li et al., 2024)のオリジナルの設定に準拠しました。ここでは、長さのバイアスを避けるために、最終的なサマリーのみを評価に与えています。蒸留したモデルにおいては、AIME 2024、MATH-500、GPQA Diamond、Codeforces、LiveCodeBenchの代表的な結果を報告します。
評価プロンプト DeepSeek-V3の環境に従い、simple-
evals frameworkのプロンプトを用いて、MMLU、DROP、GPQA Diamond、SimpleQAのような標準的なベンチマークを評価しました。MMLU-Reduxにおいては、zero-shotの環境でZero-Eval prompt format (Lin, 2024)を導入しました。MMLU-Pro、C-Eval、CLUE-WSCにおいては、オリジナルのプロンプトがfew-shotであるため、zero-shotの環境になるようにプロンプトを若干修正しました。few-shotでのCoTはDeepSeek-R1のパフォーマンスを損なう場合があります。そのほかのデータセットはクリエーターによって提供されたデフォルトのプロンプトによるオリジナルの評価プロトコルに従います。コードと数学のベンチマークにおいては、HumanEval-Mulデータセットが8つの主流のプログラミング言語(Python、Java、C++、C#、JavaScript、TypeScript、PHP、Bash)をカバーしています。LiveCodeBenchにおけるモデルのパフォーマンスは、2024/8と2025/1の間に収集されたデータとCoTフォーマットを用いて評価されました。Codeforcesデータセットは、10のDiv.2コンテストの問題と、専門家が作成したテストケースを用いて評価され、後ほど期待されるレーティングと競争相手のパーセンテージが計算されました。SWE-Benchの検証結果は、エージェントレスフレームワーク(Xia et al., 2024)経由で取得されました。AIDER関連のベンチマークは"diff"フォーマットを用いて計測されました。それぞれのベンチマークにおいては、DeepSeek-R1の出力は最大32,768トークンとしました。
ベースライン DeepSeek-V3、Claude-Sonnet-3.5-1022、GPT-4o-0513、OpenAI-o1-mini、OpenAI-o1-1217を含むいくつかの強力なベースラインに対して包括的な評価を実施しました。中国本土ではOpenAI-o1-1217 APIへのアクセスが困難なため、公式レポートに基づいたパフォーマンスを報告します。蒸留モデルに関しては、オープンソースのQwQ-32B-Preview (Qwen, 2024a)とも比較しました。
評価環境 我々はモデルに最大生成長を32,768トークンに設定しました。出力の長い論理的思考モデルを評価するために貪欲にデコードを用いると、繰り返し率が高まり、異なるチェックポイントにおいて大きな変動を引き起こすることを知りました。このため、pass@𝑘 評価(Chen et al., 2021)をデフォルトとし、非ゼロの温度を用いたpass@1を報告します。特に、我々はそれぞれの質問に対してk個のレスポンス(テストセットのサイズによるが通常は4から64の間)を生成するために、0.6のサンプリング温度と0.95のtop-pを用いました。そして、pass@1は以下のように計算されます。
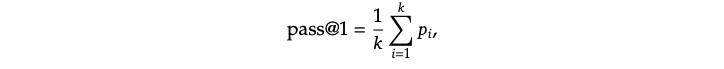
ここで𝑝𝑖はi番目のレスポンスの正しさを示します。この手法によって、より信頼できるパフォーマンスの推定が可能となります。AIME 2024においては、cons@64と表現される64のサンプルを用いたコンセンサス(多数決)による結果(Wang et al., 2022)も報告します。
3.1 DeepSeek-R1の評価
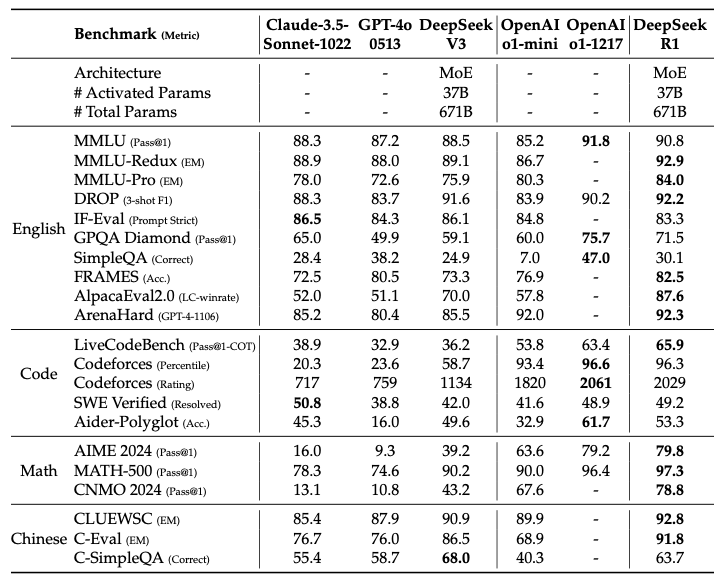
表4: DeepSeek-R1とその他の代表的なモデルとの比較
MMLU、MMLU-Pro、GPQA Diamondのように教育中心のベンチマークにおいては、DeepSeek-V3と比較してDeepSeek-R1は非常に優れたパフォーマンスを示しています。この改善は、主に大規模強化学習を通じて達成された大きなゲインが得られているSTEMに関係する質問における高い精度によるものです。さらに、長いコンテキストに依存するQAタスクであるFRAMESにおいてもDeepSeek-R1は優れており、強力な文書分析能力を示しています。これは、AIドリブンの検索やデータ分析タスクにおける論理的思考モデルのポテンシャルをハイライトしています。事実ベースのベンチマークであるSimpleQAでは、DeepSeek-R1はDeepSeek-V3を上回っており、事実に基づくクエリーの取り扱いにおける能力を示しています。このベンチマークにおいてはOpenAI-o1がGPT-4oを上回るという同様のトレンドが観測されています。しかし、中国語のSimpleQAベンチマークにおいては主に安全性RLの後に特定のクエリーへの回答を拒否する傾向のため、DeepSeek-R1はDeepSeek-V3よりも悪い性能になっています。安全性RL無しの場合、DeepSeek-R1は70%以上の精度を達成することができます。
また、DeepSeek-R1はフォーマット指示に追従するモデルの能力を評価するために設計されたベンチマークであるIF-Evalにおいて、印象的な結果をもたらしています。これらの改善は、教師ありファインチューニング(SFT)とRLトレーニングの最終ステージにおける指示追従データの追加とリンクしている場合があります。さらに、AlpacaEval2.0とArenaHardにおいては特筆すべきパフォーマンスが示されており、ラインティングのタスクとオープンなドメインでのQ&AにおけるDeepSeek-R1の強さを示しています。このDeepSeek-V3を大きく上回るパフォーマンスは、論理的思考能力を改善するだけではなく、さまざまなドメインにおけるパフォーマンスを改善する大規模RLの汎化能力によるメリットを強調しています。さらに、DeepSeek-R1によって生成されるサマリーの長さは、ArenaHardでは平均689トークン、AlpacaEval 2.0では平均2,218トークンと簡潔なものとなっています。これは、DeepSeek-R1はGPTベースの評価において長いバイアスを回避し、さまざまなタスクにおける頑健性をさらに確固たるものとしています。
数学タスクにおいては、DeepSeek-R1はOpenAI-o1-1217と同等のパフォーマンスを示し、ほかのモデルとは大きな開きを持って上回っています、論理的思考にフォーカスしたモデルがベンチマークの大勢を占めるLiveCodeBenchやCodeforcesのようなコーディングアルゴリズムタスクにおいては類似の傾向が観測されています。エンジニアリングを重視するコーディングタスクにおいては、AiderではOpenAI-o1-1217はDeepSeek-R1を上回っていますが、SWE Verifiedでは同等のパフォーマンスとなっています。このようなDeepSeek-R1のエンジニアリングのパフォーマンスは、現時点では関連するRLトレーニングデータの量が非常に限定的なものであり、次のバージョンでは改善されると我々は信じています。
3.2 蒸留モデルの評価
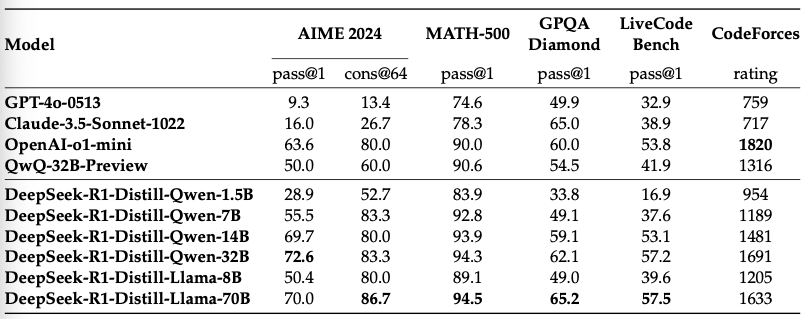
表5: 論理的思考に関連するベンチマークにおけるDeepSeek-R1蒸留モデルとそのほかのモデルとの比較
表5に示すように、DeepSeek-R1の出力をシンプルに上流することで、ボードにあるGPT-4o-0513のような非論理的思考モデルを上回る効率的なDeepSeek-R1-7B(DeepSeek-R1-Distill-Qwen-7B、以下では同じように略しています)を実現します。すべての評価メトリクスにおいてDeepSeek-R1-14BはQwQ-32B-Previewを上回っていますが、DeepSeek-R1-32BとDeepSeek-R1-70Bはほとんどのベンチマークでo1-miniを上回っています。これらの結果は、蒸留の強力なポテンシャルを示しています。さらに、これらの蒸留モデルにRLを適用することで、さらなるゲインを達成できることを発見しました。これは、ここではシンプルなSFTで蒸留したモデルの結果のみを示しているので、さらなる探索の価値があると信じています。
4. 議論
4.1 蒸留 対 強化学習
セクション3.2では、DeepSeek-R1を蒸留することで、小規模なモデルが印象的な結果をもたらすことを確認できました。しかし、依然として1つの質問が残っています: 蒸留無しにこの論文で議論されている大規模RLトレーニングを通じてモデルは同等のパフォーマンスを達成できるのでしょうか?
この質問に答えるために、数学、コーディング、STEMデータを用いてQwen-32B-Baseに対する大規模RLトレーニングを実施、10Kステップ以上のトレーニングを行い、DeepSeek-R1-Zero-Qwen-32Bを獲得しました。表6に示す実験結果では、RLトレーニング後に32BのベースモデルはQwQ-32B-Previewと同等のパフォーマンスを達成しています。しかし、DeepSeek-R1から蒸留したDeepSeek-R1-Distill-Qwen-32Bは、すべてのベンチマークにおいてDeepSeek-R1-Zero-Qwen-32Bよりもはるかに優れたパフォーマンスとなっています。

表6: 論理的思考に関係するベンチマークにおける蒸留モデルとRLモデルの比較
これによって、我々は2つの結論を導き出すことができます: 第一に、よりパワフルなモデルを小規模なモデルに上流することで素晴らしい結果を達成しますが、本論文で説明している大規模RLに依存した小規模なモデルは膨大な計算パワーを必要とし、蒸留のパフォーマンスを達成することすらできません。第二に、蒸留の戦略は経済的かつ効果的であり、知性の境界をさらに前進させるには、さらにパワフルなベースモデルとより大きな規模の強化学習を必要とするかもしれません。
4.2 成功しなかった試み
DeepSeek-R1の開発の初期ステージにおいて、途中での失敗ややり直しにも遭遇しました。洞察を提供するために、ここでは我々の失敗体験を共有しますが、これらのアプローチが効果的な論理的思考モデルの開発の能力に欠けていることを示唆するわけではありません。
プロセス報奨モデル(PRM) RPMは論理的思考タスクを解決するためにモデルをより良いアプローチにガイドする合理的な手法です(Lightman et al., 2023; Uesato et al., 2022; Wang et al., 2023)。しかし、実際にはPRMには究極的な成功の妨げとなる場合のある3つの主要な制限があります。第一に、汎用的な論理的思考におけるきめ細かいステップを明示的に定義することが困難です。第二に、現在の中間ステップが正しいかどうかを特定することが困難なタスクとなります。モデルを用いた自動アノテーションが満足する結果とならない場合があり、手動でのアノテーションをスケールアップさせることは現実的ではありません。第三に、モデルベースのPRMが導入されると、報奨ハッキング(Gao et al., 2022)は不可避となり、報奨モデルの再トレーニングにはさらなる計算リソースを必要とし、全体的なトレーニングパイプラインを複雑なものにします。まとめると、PRMはモデルによって生成されたトップNのリランクを行ったり、ガイドされた検索(Snell et al., 2024)での助けとなる優れた能力を示しますが、その利点は我々の実験における大規模強化学習において導入される追加の計算オーバーヘッドと比べると限定的なものとなります。
モンテカルロツリーサーチ(MCTS) AlphaGo (Silver et al., 2017b)とAlphaZero (Silver et al., 2017a)にインスパイアされ、テスト時の計算のスケーラビリティを改善するためにモンテカルロツリーサーチ(MCTS)の活用を探索しました。このアプローチには、モデルがソリューション空間をシステマティックに探索できるようにするための、回答の小規模パーツへの分割が含まれます。これを促進するために、検索に必要な特定の論理的思考ステップに対応する複数のタグを生成するようにモデルにプロンプトを与えました。トレーニングにおいて、我々は最初に事前トレーニングしたバリューモデルでガイドされるMCTSを通じて回答を特定するために収集されたプロンプトを用いました。結果として、アクターモデルとバリューモデルの両方をトレーニングするために結果として得られた質問・回答ペアを用い、プロセスを繰り返し改善しました。
しかし、このアプローチはトレーニングをスケールアップする際に幾つかの課題に直面しました。第一に、探索空間が比較的適切に定義されるチェスとは異なり、トークン生成はとてつもなく大きな探索空間となります。これに対応するために、それぞれのノードにおける最大拡張制限を設定しましたが、これはモデルが局所最適解に陥ることになりました。第二に、バリューモデルが探索プロセスのそれぞれのステップをガイドするので、バリューモデルが生成の品質に直接の影響を与えました。きめ細かいバリューモデルのトレーニングは本質的に困難であり、モデルの繰り返しの改善を困難なものとしました。AlphaGoのコアの成功はそのパフォーマンスを前進的に強化するバリューモデルのとrー絵ニングに依存しており、トークン生成の複雑性のため、我々の環境でこの原則を複製することは困難であることが示されました。
まとめると、MCTSは事前トレーニングしたバリューモデルと組み合わせた際には、推論のパフォーマンスを改善できますが、自己探索を通じたモデルパフォーマンスのブーストは依然として大きな課題となっています。
5. まとめ、制限、今後の取り組み
この取り組みにおいて、我々は強化学習を通じた論理的思考能力の強化における我々のジャーニーを共有しました。DeepSeek-R1-Zeroはコールドスタートデータに依存することなしに、純粋なRLアプローチを表現し、さまざまなタスクにおいて強力なパフォーマンスを達成しました。DeepSeek-R1ではコールドスタートデータと繰り返しのRLファインチューニングを活用し、さらにパワフルなものとなりました。最終的にはDeepSeek-R1は、さまざまなタスクでOpenAI-o1-1217同等のパフォーマンスを達成しました。
さらに、我々は小規模のdenseモデルへの論理的思考能力の蒸留を探索しました。800Kのトレーニングサンプルを生成するために教師モデルとしてDeepSeek-R1を用い、幾つかの小規模なdenseモデルをファインチューニングしました。結果は有望なものでした: DeepSeek-R1-Distill-Qwen-1.5BはAIMEで28.9%、MATHで83.9%という数学ベンチマークにおいて、GPT-4oとClaude-3.5-Sonnetを上回りました。また、他のdenseモデルも印象的な結果を達成しており、同じ背後のチェックポイントをベースとした他の指示チューニングモデルを大きく上回りました。
将来的には、DeepSeek-R1における以下の方向性における研究に投資することを計画しています。
- 一般的な能力: 現時点では、関数呼び出し、マルチターン、複雑なロールプレイング、JSON出力のようなタスクにおいて、DeepSeek-R1はDeepSeek-V3を下回っています。先に巣埋めるために、これらの領域におけるタスクを強化するためにどれだけ長いCoTを活用できるのかを探索する予定です。
- 言語の混合: 現在、DeepSeek-R1は中国語と英語に最適化されており、他の言語でのクエリーの取り扱いに言語が混在する問題に繋がっている可能性があります。例えば、DeepSeek-R1はクエリーが英語や中国語以外だった場合でも、論理的思考とレスポンスで英語を使う場合があります。将来的なアップデートでこの制限に取り組むつもりです。
- プロンプトエンジニアリング: DeepSeek-R1を評価する際、我々はプロンプトに敏感であることを発見しました。Few-shotのプロンプトは定常的にパフォーマンスを悪化させました。このため、最適化結果を得るためにはzero-shotの設定を用いて、問題を直接説明して出力フォーマットを指定することをユーザーに推奨しています。
- ソフトウェアエンジニアリングタスク: RLプロセスの効率性に影響を及ぼす長い評価時間のため、ソフトウェアエンジニアリングタスクには積極的にRLを適用していません。このため、DeepSeek-R1はソフトウェアエンジニアリングタスクにおいて、DeepSeek-V3よりもはるかに優れた改善を示していません。将来的なバージョンでは、効率性を改善するために、ソフトウェアエンジニアリングデータに対する棄却サンプリングを実装し、RLプロセスに非同期評価を組み込むことでこれに対応する予定です。
リファレンス
原書をご覧ください。