こちらで紹介されているノートブックをウォークスルーした内容となっています。
ノートブックの日本語訳はこちらです。
このノートブックの目的は、Databricksの分散処理能力を活用することで、効率的な方法で店舗レベルの大量のきめ細かい予測をどのように行うのかを説明することです。これは、Spark 2.x向けに以前開発されたノートブックのSpark 3.xのアップデート版です。
ノートブックのアップデートマークには、Spark 3.xあるいはDatabricksプラットフォームの新機能を利用するためにコードに変更がされたことを意味します。
注意
このエクササイズではCPUを大量に必要とします。シングルノードクラスターの場合、予測結果の永続化などで処理に5分以上かかる場合があります。処理を高速化するためには16コア4ノードなど並列性が高くなる構成を選択してください。
ライブラリのインストール
このエクササイズでは、需要予測で人気を高めているライブラリであるFBProphetを用い、Databricksランタイム7.1以降のクラスターに関連づけられているノートブックセッションにロードします。
![]()
アップデート
Databricks 7.1では、%pipマジックコマンドを用いてノートブックスコープライブラリとしてインストールすることができます。
%pip install pystan==2.19.1.1 # 参考 https://github.com/facebook/prophet/commit/82f3399409b7646c49280688f59e5a3d2c936d39#comments
%pip install fbprophet==0.6
Step 1: データの検証
使用するトレーニングデータセットとして、10店舗における50商品5年分の店舗・商品のユニット売り上げデータを使用します。このデータセットは過去のKaggleのコンペティションの一部として公開されており、こちらからダウンロードすることができます。
ダンロードしたあとは、train.csv.zipファイルを解凍し、こちらで説明されているファイルのインポートステップに従って、解凍したCSVを /FileStore/demand_forecast/train/ にアップロードします。
これでDatabricksからデータセットにアクセスできるようになったので、モデルを準備するためにデータを探索します。
from pyspark.sql.types import *
# トレーニングデータセットの構造
train_schema = StructType([
StructField('date', DateType()),
StructField('store', IntegerType()),
StructField('item', IntegerType()),
StructField('sales', IntegerType())
])
# トレーニングファイルをデータフレームに読み込み
train = spark.read.csv(
'dbfs:/FileStore/demand_forecast/train/train.csv',
header=True,
schema=train_schema
)
# データフレームにクエリーを実行できるように一時ビューを作成
train.createOrReplaceTempView('train')
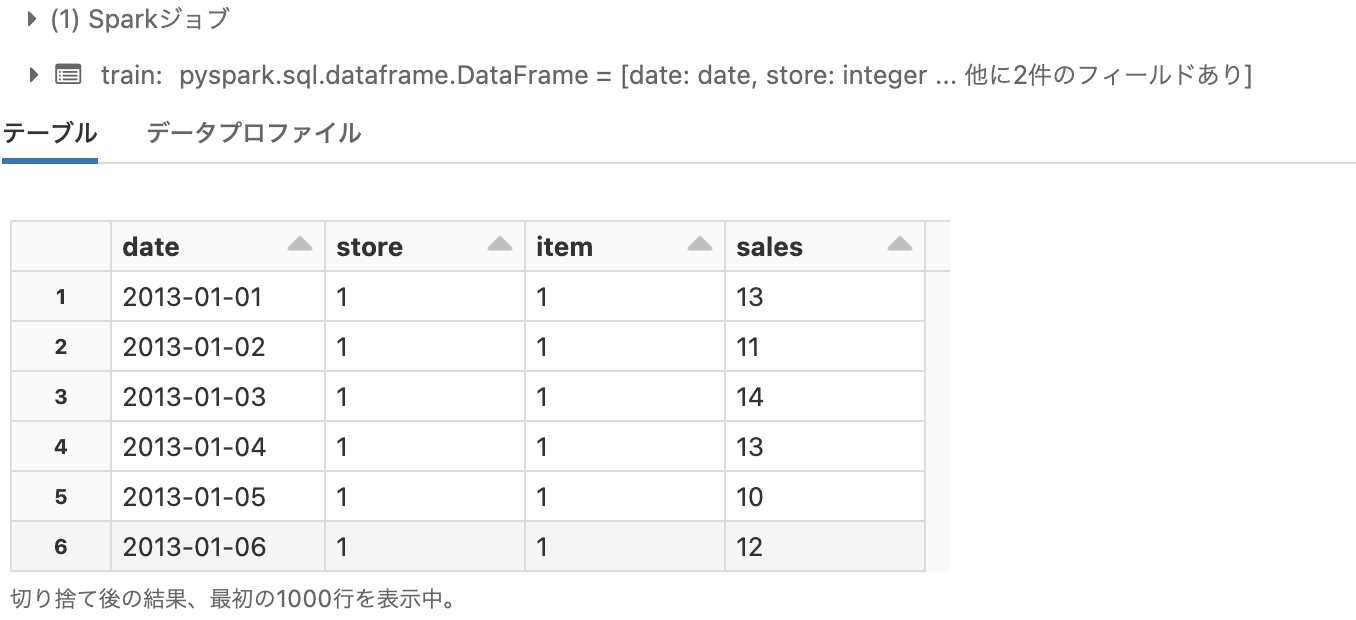
# データの表示
display(train)
年ごとのトレンドの参照
需要予測を行う際、多くのケースにおいて我々は一般的なトレンドや季節性に着目します。ユニットの売上における年次のトレンドを見るところから探索をスタートしましょう。
%sql
SELECT
year(date) as year,
sum(sales) as sales
FROM train
GROUP BY year(date)
ORDER BY year;
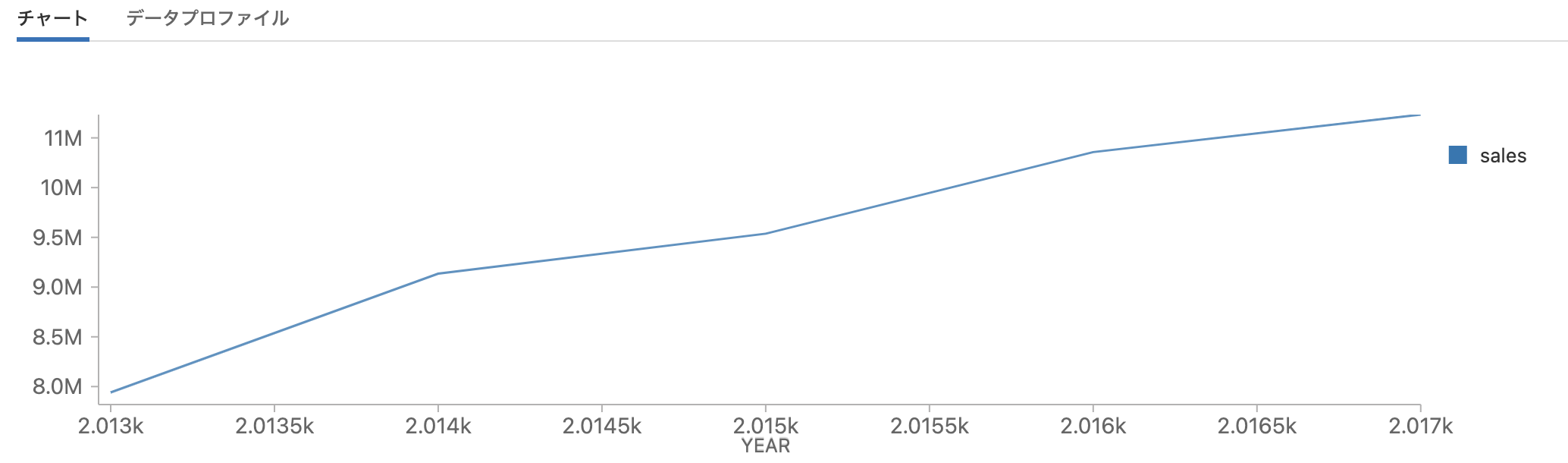
店舗に関わらず、トータルユニットセールスにおいては共通した上昇志向のトレンドがありことが明確となっています。これらの店舗に関連する市場に対して、より多くの知識があれば、予測期間を通じてアプローチするに値する最大の成長キャパシティがあるのかを判断したいと考えるかもしれません。しかし、そのような知識がなくても、このデータセットをクイックに確認することで、我々のゴールが数日先、数ヶ月先、あるいは数年先の予測なのであれば、問題はないと安心でき、このタイムスパンでは線形の成長が継続することを期待できます。
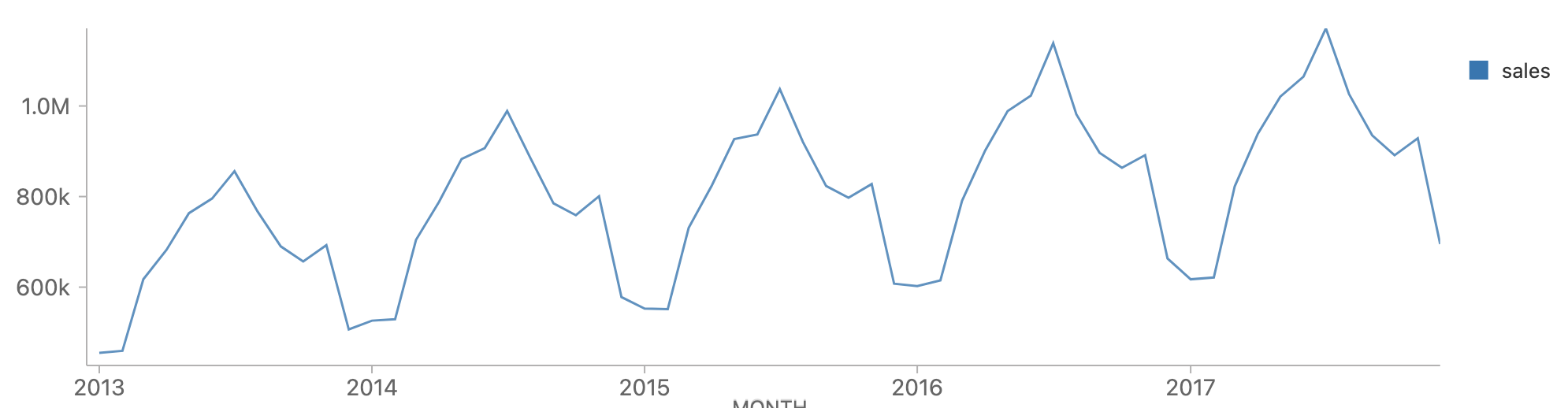
月ごとのトレンドの表示
次に季節性を検証しましょう。各年の月ごとのデータを集計すると、全体的なセールスの増加傾向とともに年間の季節的なパターンを確認することができます。
%sql
SELECT
TRUNC(date, 'MM') as month,
SUM(sales) as sales
FROM train
GROUP BY TRUNC(date, 'MM')
ORDER BY month;
曜日ごとのトレンドの表示
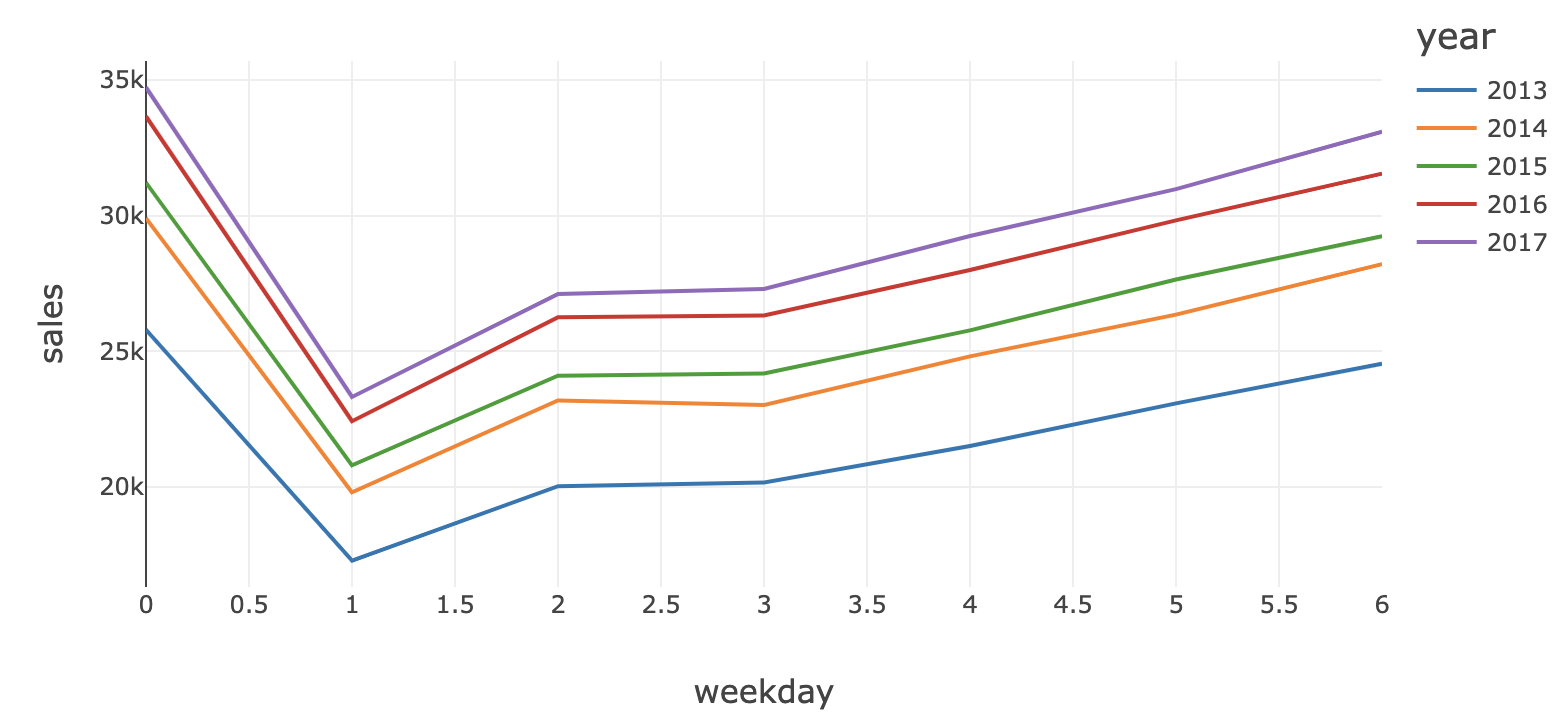
曜日レベルでデータを集計すると、日曜日にピークがあって月曜日に減少し、日曜日に向けて一定の割合で増加していく傾向を確認することができます。このパターンは、五年間を通じて非常に安定したパターンであるように見えます。
アップデート
Spark 3の一部はProleptic Gregorian calendarに移行したので、CAST(DATE_FORMAT(date, 'u')における'u'オプションは削除されました。 同様のアウトプットを得るためにEを使用します。
%sql
SELECT
YEAR(date) as year,
(
CASE
WHEN DATE_FORMAT(date, 'E') = 'Sun' THEN 0
WHEN DATE_FORMAT(date, 'E') = 'Mon' THEN 1
WHEN DATE_FORMAT(date, 'E') = 'Tue' THEN 2
WHEN DATE_FORMAT(date, 'E') = 'Wed' THEN 3
WHEN DATE_FORMAT(date, 'E') = 'Thu' THEN 4
WHEN DATE_FORMAT(date, 'E') = 'Fri' THEN 5
WHEN DATE_FORMAT(date, 'E') = 'Sat' THEN 6
END
) % 7 as weekday,
AVG(sales) as sales
FROM (
SELECT
date,
SUM(sales) as sales
FROM train
GROUP BY date
) x
GROUP BY year, weekday
ORDER BY year, weekday;
これで、データに対する基本的なパターンに慣れ親しんだので、どのように予測モデルを構築するのかを探索していきましょう。
Step 2: 単一の予測モデルの構築
店舗と商品の個々の組み合わせの予測を生成しようとする前に、FBProphetの使い方に慣れるという目的のみにおいても、単一の予測モデルを構築することは有益と言えるでしょう。
単一の商品-店舗の組み合わせのデータの取得
最初のステップは、モデルをトレーニングする履歴データを構成することとなります。
# データをdate(ds)レベルに集計するクエリー
sql_statement = '''
SELECT
CAST(date as date) as ds,
sales as y
FROM train
WHERE store=1 AND item=1
ORDER BY ds
'''
# Pandasデータフレームとしてデータセットを構成
history_pd = spark.sql(sql_statement).toPandas()
# 欠損値のあるレコードの削除
history_pd = history_pd.dropna()
Prophetライブラリのインポート
次にfbprophetライブラリをインポートします。使用する際に多くの情報が出力されるのでログの出力を抑制しますが、実際の環境においいてはログの設定をチューニングする必要があります。
from fbprophet import Prophet
import logging
# fbprophetのインフォーメーションメッセージを無効化
logging.getLogger('py4j').setLevel(logging.ERROR)
Prophetモデルのトレーニング
データを確認した結果に基いて、全体的な成長パターンをlinearに設定し、週と年の季節性パターンを有効化すべきです。また、季節性のパターンがセールスにおける全体的な成長に合わせて成長するように見えるので、季節性モードをmultiplicative(増加)に設定しても構いません。
# モデルパラメーターの設定
model = Prophet(
interval_width=0.95,
growth='linear',
daily_seasonality=False,
weekly_seasonality=True,
yearly_seasonality=True,
seasonality_mode='multiplicative'
)
# 履歴データに対してモデルをフィッティング
model.fit(history_pd)
予測の実施
これでモデルをトレーニングできたので、90日の予測にモデルを使用しましょう。
# 履歴データと最新の日付以降90日の両方を含むデータセットを定義
future_pd = model.make_future_dataframe(
periods=90,
freq='d',
include_history=True
)
# データセットに対して予測を実施
forecast_pd = model.predict(future_pd)
display(forecast_pd)
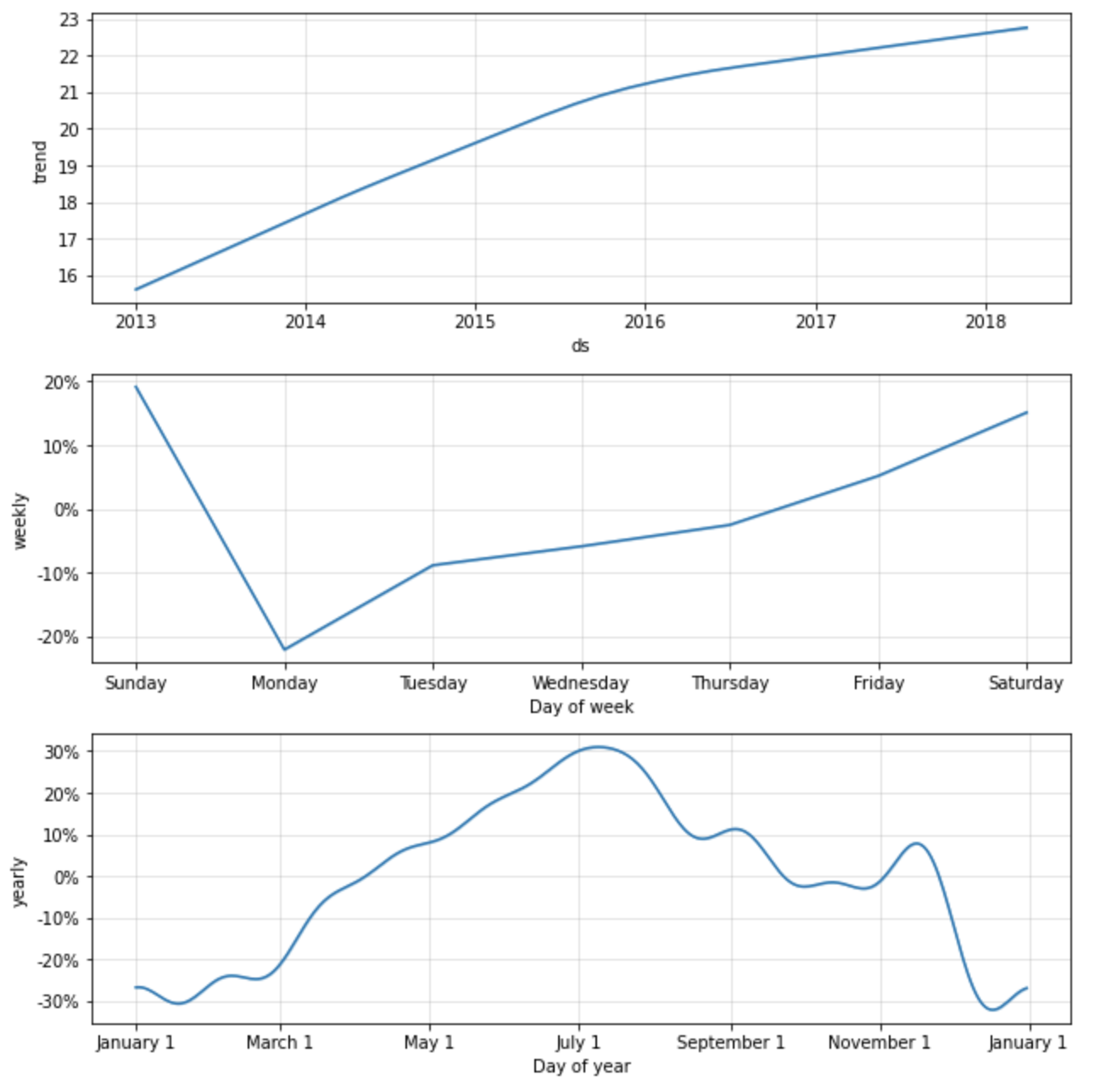
予測コンポーネントの検証
モデルはどのような性能なのでしょうか?作成したモデルにおける一般的なトレンド、季節性のトレンドをグラフとして確認することができます。
trends_fig = model.plot_components(forecast_pd)
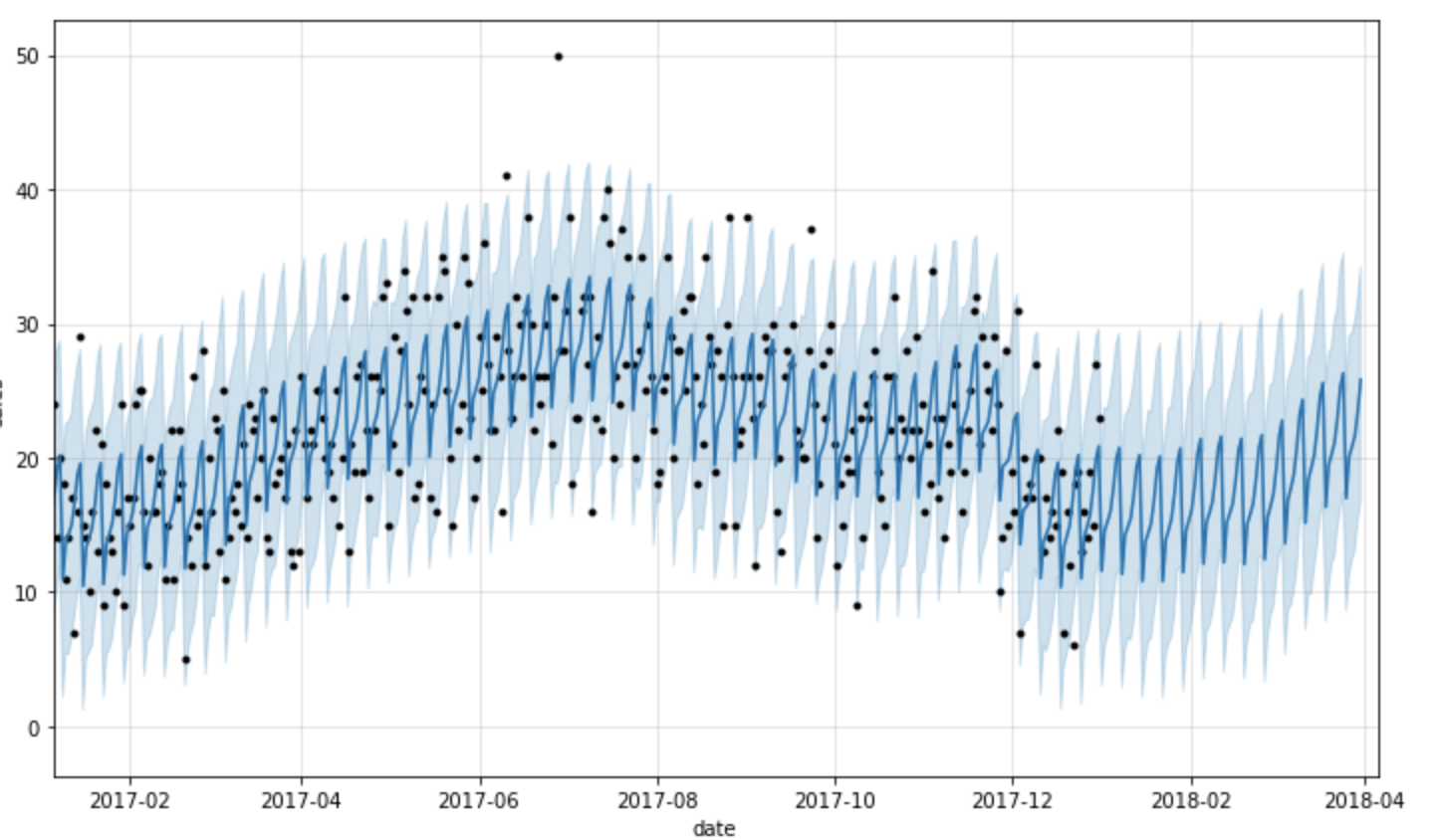
履歴データ vs. 予測の参照
そして、ここでは実際のデータと将来の予測値を含む予測データを確認することができますが、読みやすいように過去一年の履歴データに限定してグラフに表示しています。
predict_fig = model.plot( forecast_pd, xlabel='date', ylabel='sales')
# 過去1年分 + 90日の予測を表示するように図を調整
xlim = predict_fig.axes[0].get_xlim()
new_xlim = ( xlim[1]-(180.0+365.0), xlim[1]-90.0)
predict_fig.axes[0].set_xlim(new_xlim)
注意
このビジュアライゼーションは若干ビジーです。Bartosz Mikulskiがこれをブレークダウンした素晴らしい説明を公開しており、チェックする価値があるものです。簡単に言うと、黒い点が実際の値を表現しており、暗い青の線は予測値、明るい青の帯は95%の信頼区間を表現しています。
評価メトリクスの計算
視覚による調査は有用ですが、予測を評価するより良い方法はMean Absolute Errorを計算するというものです。我々の環境では、実際の値に対する予測値のMean Absolute ErrorやRoot Mean Squared Errorを計算します。
アップデート
pandasの機能変更によって、日付文字列を適切なデータ型に変換するためにpd.to_datetimeを使用する必要があります。
import pandas as pd
from sklearn.metrics import mean_squared_error, mean_absolute_error
from math import sqrt
from datetime import date
# 比較のために過去の実績値と予測値を取得
actuals_pd = history_pd[ history_pd['ds'] < date(2018, 1, 1) ]['y']
predicted_pd = forecast_pd[ forecast_pd['ds'] < pd.to_datetime('2018-01-01') ]['yhat']
# 評価メトリクスの計算
mae = mean_absolute_error(actuals_pd, predicted_pd)
mse = mean_squared_error(actuals_pd, predicted_pd)
rmse = sqrt(mse)
# メトリクスの表示
print( '\n'.join(['MAE: {0}', 'MSE: {1}', 'RMSE: {2}']).format(mae, mse, rmse) )

FBProphetでは、あなたの予測結果が時間の経過を通じてどれだけ良い結果を出しているのかを評価するための別の方法を提供しています。予測モデルを構築する際にこれらの活用を検討することを強くお勧めしますが、ここではスケーリングの課題にフォーカスしているので、説明はスキップします。
Step 3: 予測処理をスケール
我々の保持するメカニズムを活用して、個々の店舗と商品の組み合わせに対する大量の高精細モデルと予測を行うという元々の目標に取り組みましょう。セールスデータを店舗・商品・日付の粒度に構成するところからスタートします。
注意
このデータセットのデータはすでにこのレベルの粒度に集計されていますが、ここではデータが期待している構造になっていることを確実するために、明示的に集計を行います。
すべての店舗・商品の組み合わせに対応するデータの取得
sql_statement = '''
SELECT
store,
item,
CAST(date as date) as ds,
SUM(sales) as y
FROM train
GROUP BY store, item, ds
ORDER BY store, item, ds
'''
store_item_history = (
spark
.sql( sql_statement )
.repartition(sc.defaultParallelism, ['store', 'item'])
).cache()
予測アウトプットのスキーマを定義
店舗・商品・日付レベルにデータを集計したら、データをどのようにFBProphetに渡すのかを検討する必要があります。我々のゴールが、それぞれの店舗と商品の組み合わせに対応するモデルの構築であれば、構成した店舗・商品のサブセットを引渡し、そのサブセットでモデルをトレーニングし、店舗・商品レベルの予測結果を受け取る必要があります。予測を実行した店舗と商品のIDを維持できるように、予測結果がこのような構造のデータセットで返却されてほしいので、Prophetモデルによって生成されるフィールドから適切なものに出力を限定します。
from pyspark.sql.types import *
result_schema =StructType([
StructField('ds',DateType()),
StructField('store',IntegerType()),
StructField('item',IntegerType()),
StructField('y',FloatType()),
StructField('yhat',FloatType()),
StructField('yhat_upper',FloatType()),
StructField('yhat_lower',FloatType())
])
モデルをトレーニングし予測を行う関数の定義
モデルをトレーニングし予測行うために、Pandasの関数を活用します。店舗と商品の組み合わせに対応するデータのサブセットを受け取るために、この関数を活用します。上のセルで定義したフォーマットで予測結果が返却されます。
アップデート
Spark 3.0では、このpandas UDFの機能をpandas functionsで置き換えました。非推奨となったpandas UDFの文法はまだサポートされていますが、将来的にはサポートされなくなります。新たに整理されたpandas functions APIに関しては、ドキュメントを参照してください。
def forecast_store_item( history_pd: pd.DataFrame ) -> pd.DataFrame:
# 以前と同様にモデルをトレーニング
# --------------------------------------
# 欠損値の除外 (日付・店舗・商品レベルでは発生頻度が高まります)
history_pd = history_pd.dropna()
# モデルの設定
model = Prophet(
interval_width=0.95,
growth='linear',
daily_seasonality=False,
weekly_seasonality=True,
yearly_seasonality=True,
seasonality_mode='multiplicative'
)
# モデルのトレーニング
model.fit( history_pd )
# --------------------------------------
# 以前と同様に予測を実施
# --------------------------------------
# 予測の実施
future_pd = model.make_future_dataframe(
periods=90,
freq='d',
include_history=True
)
forecast_pd = model.predict( future_pd )
# --------------------------------------
# 期待する結果セットの構成
# --------------------------------------
# 予測結果から適切なフィールドを取得
f_pd = forecast_pd[ ['ds','yhat', 'yhat_upper', 'yhat_lower'] ].set_index('ds')
# 履歴から適切なフィールドを取得
h_pd = history_pd[['ds','store','item','y']].set_index('ds')
# 履歴と予測をjoin
results_pd = f_pd.join( h_pd, how='left' )
results_pd.reset_index(level=0, inplace=True)
# 入力データセットから店舗と商品を取得
results_pd['store'] = history_pd['store'].iloc[0]
results_pd['item'] = history_pd['item'].iloc[0]
# --------------------------------------
# 期待されるデータセットを返却
return results_pd[ ['ds', 'store', 'item', 'y', 'yhat', 'yhat_upper', 'yhat_lower'] ]
我々の関数の中にはいろいろな物が含まれていますが、このコードでモデルをトレーニングし、予測結果を生成する最初の2つのブロックと、このノートブックの前半のセルとを比較すると、非常に類似していることがわかります。コードに追加されているのは、必要な結果セットを構成する部分のみであり、これは標準的なPandasデータフレームの操作によって構成されています。
それぞれの店舗・商品の組み合わせに対して予測関数を適用
予測を行うために上で構築したpandas関数を呼び出しましょう。このために、履歴データセットを店舗と商品でグルーピングします。そして、それぞれのグループに上の関数を適用し、データ管理のために本日の日付を training_date として追加します。
アップデート
上のアップデートの記述の通り、pandas関数を呼び出すためにpandas UDFではなくapplyInPandas()を使用します。
from pyspark.sql.functions import current_date
results = (
store_item_history
.groupBy('store', 'item')
.applyInPandas(forecast_store_item, schema=result_schema)
.withColumn('training_date', current_date() )
)
results.createOrReplaceTempView('new_forecasts')
display(results)
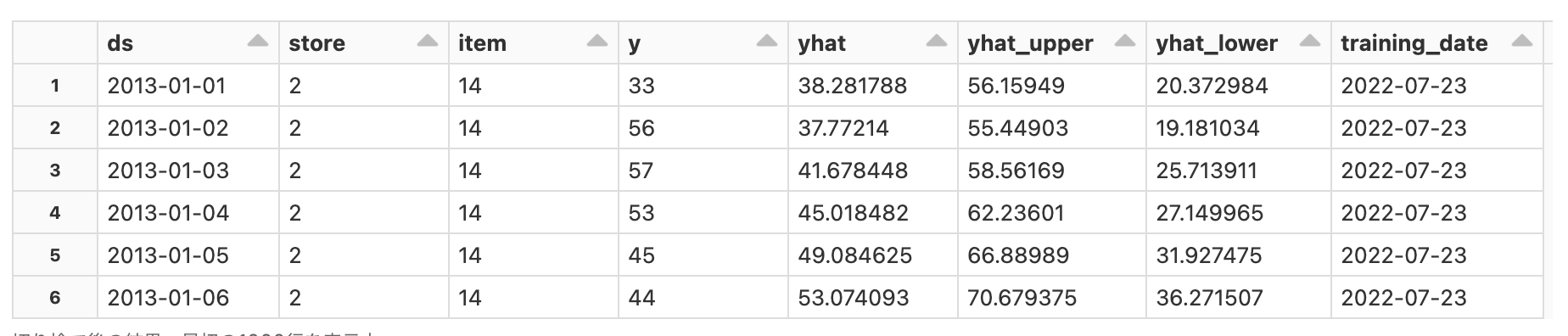
予測結果の永続化
多くの場合、予測結果をレポートで活用したいと考えるので、クエリー可能なテーブル構造として保存します。以下では、他のユーザーとデータベースが競合しないようにユーザー名を埋め込んだデータベースを作成しています。
import re
from pyspark.sql.types import *
# Username を取得
username_raw = dbutils.notebook.entry_point.getDbutils().notebook().getContext().tags().apply('user')
# Username の英数字以外を除去し、全て小文字化
username = re.sub('[^A-Za-z0-9]+', '', username_raw).lower()
# ユーザー固有のデータベース名を生成します
db_name = f"databricks_handson_{username}"
# データベースの準備
spark.sql(f"DROP DATABASE IF EXISTS {db_name} CASCADE")
spark.sql(f"CREATE DATABASE IF NOT EXISTS {db_name}")
spark.sql(f"USE {db_name}")
# データベースを表示
print(f"database_name: {db_name}")
%sql
-- 予測テーブルの作成
create table if not exists forecasts (
date date,
store integer,
item integer,
sales float,
sales_predicted float,
sales_predicted_upper float,
sales_predicted_lower float,
training_date date
)
using delta
partitioned by (training_date);
-- データのロード
insert into forecasts
select
ds as date,
store,
item,
y as sales,
yhat as sales_predicted,
yhat_upper as sales_predicted_upper,
yhat_lower as sales_predicted_lower,
training_date
from new_forecasts;
評価メトリクスの永続化
この場合も、予測ごとのメトリクスをレポートしたいと考えるので、これらをクエリー可能なテーブルに永続化します。
%sql
create table if not exists forecast_evals (
store integer,
item integer,
mae float,
mse float,
rmse float,
training_date date
)
using delta
partitioned by (training_date);
insert into forecast_evals
select
store,
item,
mae,
mse,
rmse,
training_date
from new_forecast_evals;
予測結果の可視化
ここまでで、それぞれの店舗・商品の組み合わせに対する予測結果を生成し、それぞれの基本的な評価メトリクスを計算しました。この予測データを確認するために、シンプルなクエリー(ここでは店舗1から店舗3における商品1に限定しています)を実行することができます。
%sql
SELECT
store,
date,
sales_predicted,
sales_predicted_upper,
sales_predicted_lower
FROM forecasts a
WHERE item = 1 AND
store IN (1, 2, 3) AND
date >= '2018-01-01' AND
training_date=current_date()
ORDER BY store
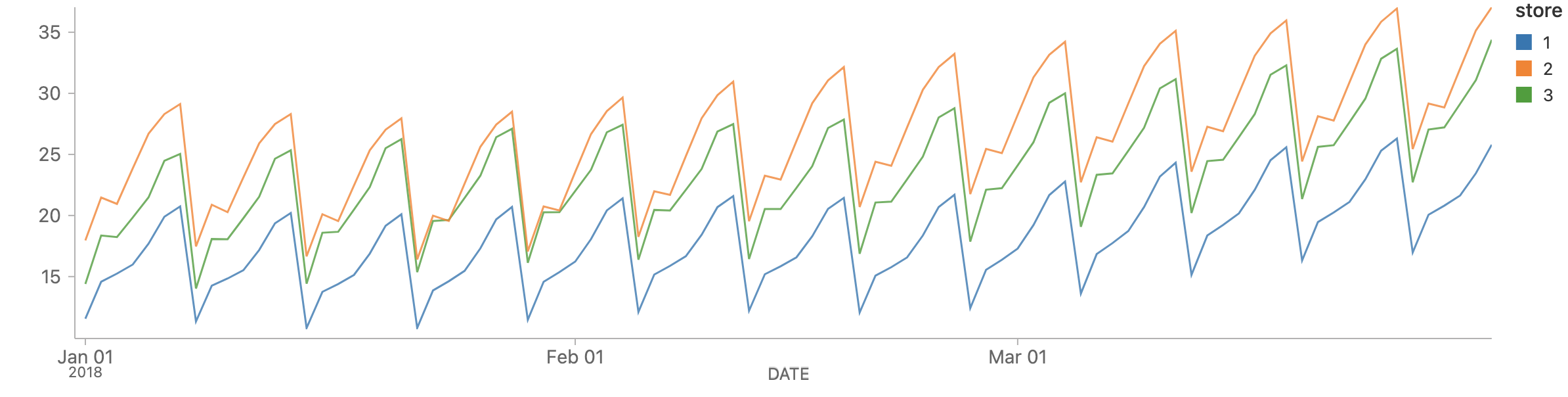
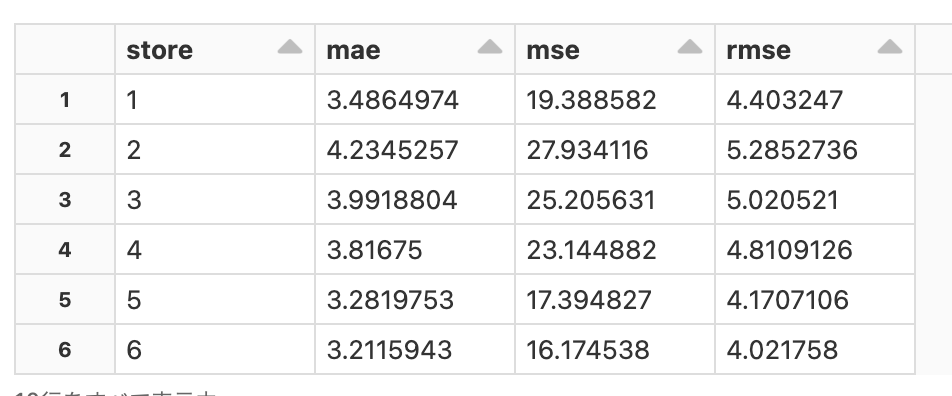
評価メトリクスの取得
そして、これらのそれぞれに対して、予測の信頼性評価の助けとなる指標を取得します。
%sql
SELECT
store,
mae,
mse,
rmse
FROM forecast_evals a
WHERE item = 1 AND
training_date=current_date()
ORDER BY store
このように、大規模な需要予測を行う場合においても、Sparkの並列性を活用することで処理を高速に行うことができます。