Lakehouse AI: A Data-Centric Approach to Building Generative AI Applications | Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
生成AIはすべてのビジネスに変革的なインパクトをもたらすことでしょう。Databricksは10年に渡りAIのイノベーションを開拓し続けてきており、AIソリューションを提供する数千のお客様とアクティブにコラボレーションし、月間11MダウンロードのMLflowのようなプロジェクトのオープンソースコミュニティと取り組みを進めています。レイクハウスAIとユニークなデータ中心アプローチによって、お客様がスピード、信頼性、完全なガバナンスを持ってAIモデルを開発、デプロイすることを支援します。本日、Data & AIサミットにおいて、皆様の生成AIのプロダクションジャーニーを加速する、最高のプラットフォームとしてレイクハウスAIを実現するいくつかの新機能を発表しました。これらのイノベーションには、ベクトル検索、レイクハウスモニタリング、LLMに最適化されたGPU搭載モデルサービング、MLflow 2.5などが含まれます。
生成AIソリューション開発における主要な課題
モデル品質の最適化: データはAIの心臓です。貧弱なデータは、バイアス、幻覚、有害なアウトプットにつながる恐れがあります。大規模言語モデル(LLM)には客観的な正解ラベルがほとんどないため、効果的に評価することが困難です。このため、お企業は多くの場合、監視なしに重要なユースケースでこのモデルをいつ信頼することができるのかを理解することをに苦戦しています。
エンタープライズデータを用いたトレーニングのコストと複雑性: 企業は、自分たちのデータを用いて自分たちのモデルをトレーニングし、コントロールしたいと考えています。MPT-7やFalcon-7Bのような指示によってチューニングされたモデルは、良いデータを用いて小規模のファインチューニングされたモデルは良いパフォーマンスを示すことをデモンストレーションしました。しかし、企業はベースモデルをスタートする際にどれだけのサンプルがあれば十分なのかを知ることや、モデルをトレーニング、ファインチューニングするために必要なインフラストラクチャの複雑性を管理することや、コストをどのように考えるべきかについて苦慮しています。
プロダクションにおけるモデルの信頼: 技術のランドスケープが急速に進化し、新たな機能が導入されることで、これらのモデルをプロダクションに持っていくことはより困難となっています。時には、これらの機能はベクトルデータベースのような新たなサービスのニーズの形でもたらされ、別の場合には、ディーププロンプトエンジニアリングのサポートや追跡のような新たなインタフェースであるかもしれません。プロダクションでモデルを信頼することは、堅牢でスケーラブルなインフラストラクチャ、モニタリングに完全に設られたスタックなしには困難です。
データのセキュリティとガバナンス: 企業はデータ漏えいを防ぐために、何のデータが送信され、サードパーティによって格納されるのかをコントロールし、レスポンスが規制に準拠していることを確実にしたいと考えています。我々は、あるチームが現在は規制されていないポリシーを用いて、セキュリテイぃやプライバシーを侵害したり、イノベーションのスピードを遅らせるような苦痛なプロセスを使用していたケースを目撃しています。
レイクハウスAI - 生成AIに最適化
上述の課題を解決するために、企業がデータのセキュリティやガバナンスを維持し、POCからプロダクションに至るジャーニーを加速する支援するいくつかのレイクハウスAIの機能を発表できることを嬉しく思っています。
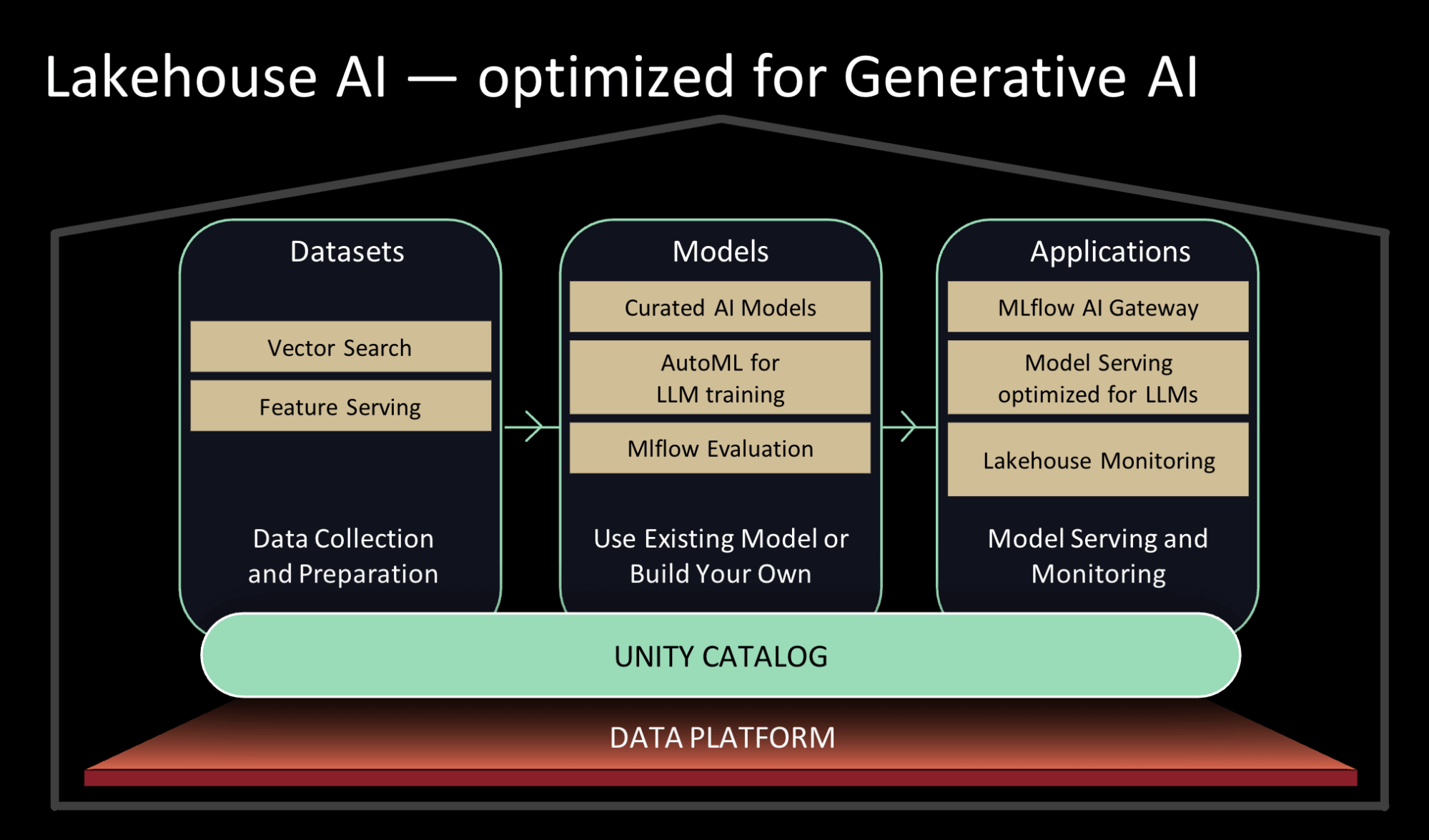
あなたのデータを用いて既存のモデルを活用、あるいはご自身のモデルをトレーニング
- インデックスのためのベクトル検索: ベクトルのエンべディングを用いることで、あなたの組織の知識コーパス全体を用いたカスタマーサポートbotからお客様の意図を理解する検索、レコメンデーション体験に至る様々なユースケースにおける生成AIとLLMのパワーを活用することができます。我々のベクトルデータベースによって、チームがエンべディングベクトルとして企業のデータをクイックにインデックスし、リアルタイムのデプロイメントで低レーテンシーのベクトル類似度検索を実施する助けとなります。ベクトル検索は、ガバナンスのためのUnity Catalogや、データやクエリーをベクトルに変換するプロセスを自動で管理するためのモデルサービングを含むレイクハウスと密接にインテグレーションされます。こちらからプレビューにサインアップしてください。
- 高パフォーマンスの最適化モデルサービングに支えられ整理されたモデル: あなたのユースケースに最適なオープンソースの生成AIモデルを調査することに時間を費やすのではなく、共通的なユースケース向けにDatabricksのエキスパートが整理したモデルを頼ることができます。我々のチームは継続的にモデルのランドスケープを監視しており、品質やスピードのような数多くのファクターに関して新たなモデルをテストしています。Databricksマーケットプレイスで最高の基盤モデルを利用できるようにし、デフォルトのUnity Catalogでタスク固有のLLMを利用できるようにします。お使いのUnity Catalogにモデルが取り込まれると、直接活用したり、皆様のデータを用いてファインチューニングすることができます。これらのモデルのそれぞれに対して、レイクハウスAIのコンポーネントを最適化しています。例えば、モデルサービングのレーテンシーを最大10倍削減しています。こちらからプレビューにサインアップしてください。
- AutoMLのLLMサポート: 我々はAutoMLを、皆様のデータを用いたテキスト分類の生成AIモデルのファインチューニング、ベースのエンべディングモデルのファインチューニングに拡張しました。AutoMLによって、非技術者のユーザーは企業のデータを用いてポイントアンドクリックの操作でモデルをファインチューニングできるように意なり、同じことを行う技術者ユーザーの効率性を高めます。こちらからプレビューにサインアップしてください。
あなたのモデルとプロンプトのパフォーマンスをモニタリング、評価、記録
- レイクハウスモニタリング: 皆様のデータとAI資産の両方の品質を同時に追跡できるようにする、データとAIを統合した初のモニタリングサービスです。このサービスでは皆様の資産のプロファイルとドリフトのメトリクスを保持し、プロアクティブなアラートや、可視化し、企業で共有するための自動生成品質ダッシュボードを設定でき、リネージグラフにおけるデータ品質アラートを関係づけることで根本原因分析を促進します。Unity Catalog上に構築されたレイクハウスモニタリングは、ユーザーが高い品質、精度、信頼性を維持できるように、皆様のデータとAI資産に対する深い洞察を提供します。こちらからプレビューにサインアップしてください。
- 推論テーブル: データ中心パラダイムの一部として、サービングエンドポイントに送信されるリクエストや返信されるレスポンスは、お使いのUnity CatalogのDeltaテーブルに記録されます。このペイロードの自動キロkうによって、チームはニアリアルタイムで自分たちのモデルを監視することができ、このテーブルは、ご自身のエンべディングや他のLLMをファインチューニングするための次回のデータセットとして再度ラベルづけする必要があるソースデータポイントとして簡単に活用することができます。
- LLMOpsのためのMLflow(MLflow 2.4とMlflow 2.5): 皆様のLLMユースケースにおけるベストな候補モデルを容易に特定できるように、我々はMLflowのevaluation APIをLLMのパラメーターとモデルを追跡するように拡張しました。皆様のユースケースでベストなプロンプトテンプレートの特定の助けになるように、プロンプトエンジニアリングツールを開発しました。評価されるそれぞれのプロンプトテンプレートは、検証や再利用のためにMLflowによって記録されます。
リアルタイムでモデル、特徴量、関数をセキュアにサーブ
-
GPU搭載、LLMに最適化されたモデルサービング: GPUモデルサービングを提供するだけではなく、トップのオープンソースLLMのGPUサービングに最適化しています。我々の最適化によって最高クラスのパフォーマンスを提供し、Databricksにデプロイした際に桁違いに高速にLLMを実行することが可能となります。これらのパフォーマンス改善によって、チームは推論時間のコストを削減することができ、トラフィックに対応できるようにクイックにスケールアップ/ダウンできます。こちらからプレビューにサインアップしてください。
「Databricksのモデルサービングに移行することで推論のレーテンシーを10倍削減し、我々のお客様に適切で正確な予測結果をより迅速に提供できるようになりました。データが存在し、我々がモデルをトレーニングするのと同じ場所でモデルサービングを行うことで、デプロイメントを加速し、メンテナンス工数を削減することができました。」— Daniel Edsgärd, Head of Data Science, Electrolux
-
特徴量と関数のサービング: 企業は特徴量と関数の両方をサービングすることで、オンラインとオフラインの偏りを避けることができます。特徴量と関数のサービングは、機械学習モデルをサーブしたり、LLMアプリケーションを強化するためのREST APIエンドポイントの背後で低レーテンシーでオンデマンドの計算処理を実行します。Databricksのモデルサービングと組み合わせて活用することで、特徴量は送信されるリクエスト自動で結合されるので、お客様はシンプルなデータパイプラインを構築することができます。こちらからプレビューにサインアップしてください。
-
AI Functions: 今ではデータアナリストやデータエンジニアは、インタラクティブなSQLクエリーや、SQL/SparkのETLパイプラインでLLMやそのほかの機械学習モデルを活用することができます。AI Functionsを用いることで、Unity CatalogやAIゲートウェイでの権限が許可されていれば、アナリストは感情分析やドキュメントの要約を行うことができます。同様に、データエンジニアはコールセンターのすべての通話を書き起こし、これらの通話から重要なビジネス洞察を抽出するために、LLMを用いて更なる分析を実行するパイプラインを構築することができます。
データとガバナンスの管理
- データとAIのガバナンスの統合: 我々はUnity Catalogを単一の統合体験でデータとAI資産の両方のリネージ追跡と包括的なガバナンスを提供するようにエンハンスしました。これは、モデルレジストリと特徴量ストアがUnity Catalogに統合されたことを意味し、チームは自分たちのデータの隣にAIを管理し、ワークスペース横断でこれらの資産を共有できるようになります。
- MLflow AIゲートウェイ: 企業が自分たちの従業員にOpenAIや他のLLMプロバイダーを活用させようとした際、レート制限や資格情報の管理、コスト急増、外部に送信されたデータの追跡、問題に直面します。MLflow 2.5の一部としてMLflow AIゲートウェイは、企業がコストや使用量を管理するために、様々なレート制限、キャッシュ、コスト属性などを設定できるルートを作成、共有できるようになるワークスペースレベルAPIです。
- MLOpsのためのDatabricks CLI: このDatabricks CLIの進化によって、データチームはインテグレーションされたCI/CDツールを用いて、infra-as-codeを用いてプロジェクトをセットアップし、プロダクションへの移行を高速にすることができます。企業は、Databricksワークフローを用いてAIライフサイクルコンポーネントを自動化するために「バンドル」を作成することができます。
この生成AIの新時代において、リリースしたこれらすべてのイノベーションに興奮しており、これらで皆様が構築するものを楽しみにしています!