How to Use PyTorch to Improve Image Recognition Modeling - The Databricks Blogの翻訳です。
この記事は、大規模機械学習データパイプラインを構築しているeコマース企業、Wehkampの機械学習エンジニア、データサイエンティストであるSimona Stolnicuによるゲスト記事です。
Wehkampはオランダ最大のeコマース企業であり、1日に50万人以上の人がウェブサイトを訪れます。Wehkampのサイトで提供される様々な商品は、お客様の数多くの要望に応えるためのものです。
eコマースウェブサイトを訪れるあらゆるお客様にとって重要な観点は、製品の定量的かつ正確な視覚体験です。大規模になると、ローカル環境のフォトスタジオで数千の商品画像を処理するのは簡単な作業ではありません。
素晴らしい顧客体験を生み出す観点として、一貫性があります。これらの画像背景は大きく異なるため、ウェブサイトを一貫性のある見た目にするために、ウェブサイトに掲載する前に画像背景を削除しています。これを手動でやるには、非常に大変で時間がかかる作業となります。数百万の画像となると、新たに到着する商品に対応し続けるために、手動で背景画像の除去をおこなうための時間とリソースは膨大なものとなってしまいます。
この記事では、画像処理時間を削減し、画像品質を高めるために機械学習(ML)を用いたエンドツーエンドの自動パイプラインを説明します。これを実現するために、画像処理にはPyTorch、分散トレーニングにはDatabricks上でHorovodを活用しました。
画像処理パイプラインの概要
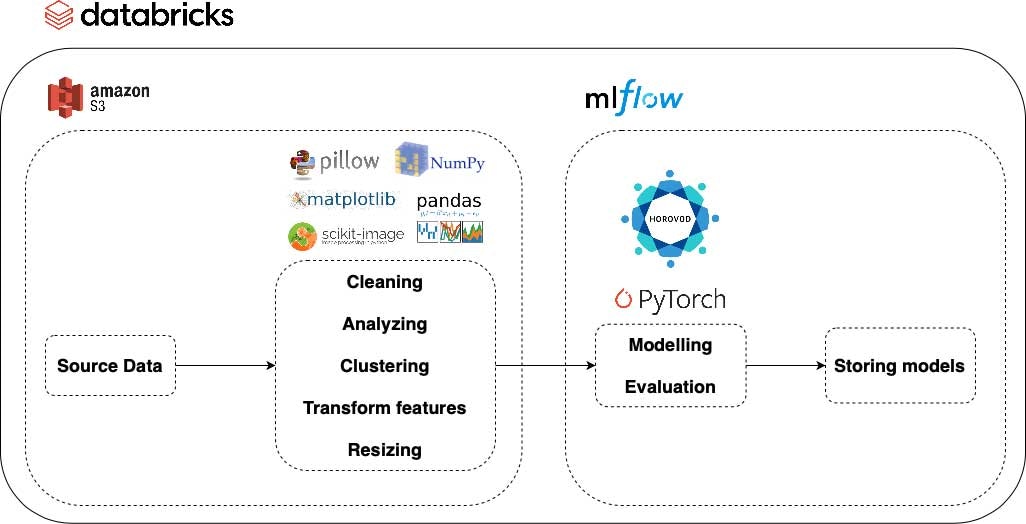
以下の図から、データの取得から処理済みデータに対してトレーニング、評価されたモデルの格納に至る我々のパイプラインの基本的なコンポーネントを確認することができます。さらに、画像処理パイプラインのそれぞれのステップで用いられるサービスとライブラリを確認することができます。概要としては、生データ、処理済み画像データの両方をロード、保存するためにAmazon S3を使いました。モデルのトレーニングと評価においては、パラメーターと結果を格納するためにMLflowのエクスペリメントを使用しました。また、モデルのバー助管理を行うためにMLflowモデルレジストリを活用し、ここからモデルを実運用環境に移行することができます。
ファッション画像データセットの処理
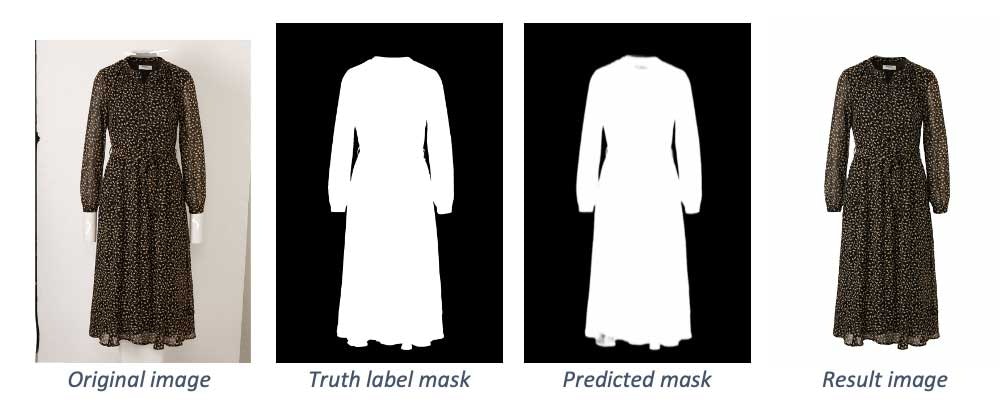
機械学習モデルが画像の背景と前景を区別できるように、モデルはオリジナル画像と、どのピクセルが背景、前景どちらに属するのかを示すバイナリーマスクのペアを処理する必要があります。
このプロジェクトで用いられたデータセットには30,000ペア画像が含まれています。モデルの予測アウトプットはバイナリーマスクであり、最終的な画像はオリジナル画像からバイナリーマスクでマークされた背景画像を除去することで取得できます。
テスト用データセットのいくつかの例を以下で確認できますが、特にオリジナル画像とラベル(トレーニングデータセットの場合、これがネットワークの入力を表現します)、予測されたマスクと背景画像が除去された最終画像が続きます。



処理すべきデータに対して何を期待するのかを正確に知らない限り、画像処理の一般的なステップバイステップのパイプラインを構築することは困難です。データにおける未知のばらつきは、データに対して必要となるオペレーションを予測することが困難となります。我々の場合、クレンジングや、さらなる分析を必要とする正確な画像の領域を特定するために、いくつかのトレーニングを試行しました。
データセットのクレンジングは、プロセスの最初で行う、ミスマッチのペア画像の除外と画像のリサイズから構成されています。これは、処理の効率化と、我々のネットワークアーキテクチャの入力サイズにマッチさせるようにするために行われます。
我々のケースに適した別のステップは、画像データを以下の6つの製品タイプのクラスターに分割することです。
- ロングパンツ
- ショートパンツ
- 半袖のトップス、ドレス
- 長袖のトップス、ドレス
- 水着/スポーツウェア/アクセサリー
- ライトカラー(淡彩色)の製品
データにおいて製品タイプの不均衡があり、トレーニングデータで少数派の製品タイプにおいてモデルの性能が劣化したため、この分割が必要でした。我々のデータセットの背景色がライトカラーであり、製品と背景が同じ色である場合の製品の検知が困難であったため、ライトカラー製品から構成されるクラスターを作成しました。これらのケースに該当するものは少量であったので、モデルは同様のケースを取り扱う大量のサンプルを得ることはできませんでした。
このクラスタリングのプロセスは、主にオリジナル画像から計算された特徴量に対するk-meansアルゴリズムをベースとしています。このプロセスの結果は完全に正確なものとは言えないため、ある程度の手作業が必要となりました。
この作業は大規模データに対するものでしたが、このモデルが使用される全てのユースケースをカバーしていませんでした。このため、データに対して拡張技術を適用しましたが、重要なもののいくつかは以下の通りです。
- クロッピング
- 背景画像の変更
- 画像の合成
以下では、それぞれの変換処理が上記画像に対して、どのように働くのかを示しています。

画像を取り扱う際に注意すべきことの一つには、トレーニングデータの取得が困難であると言うことです。トレーニングデータを作成する手動のプロセスは、制度を担保するために多大な時間と労力を必要とします。
画像処理のモデルアーキテクチャ
背景から前景の分離は、特徴の検知問題と考えることができます。これは、画像において最も明白な領域を検知し、ピクセルが背景あるいは前景に属する確率を予測することで構成されます。
この領域における最新技術は、N2-Netの論文(U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection)であり、特徴的物体の検知、特徴検知にディープニューラルネットワークアーキテクチャを導入しました。このアーキテクチャには、2段階にネストされたUネットワークシェイプがあり、少ないメモリと限定された計算コストで実行することができます。
これの主な強みは、このアーキテクチャにおいて大規模なディープレイヤーを用いて特徴量を検知できると言うものです。このようにして、追加の計算時間なしに文脈情報を理解することができます。
我々のモデルは、上述の論文にインスパイヤされたアーキテクチャ上に構築されており、Mask-RCNNのような他のコンボリューショナルニューラルネットワークアーキテクチャ(CNN)と比較して、結果が劇的に改善されました。これは、Mask-RCNNのバックボーンも画像分類タスクに特化したものですが、この特定のユースケースにおいてはネットワークが複雑になってしまうためです。
分散モデルトレーニングおよび評価
大規模データに対するトレーニングは、トライアンドエラーを含む大変時間のかかるプロセスです。我々のネットワークは、グラフィカルプロセッシングユニット(GPU)搭載のワーカーを用いたDatabricks環境でトレーニングされました。PyTorchを用いた分散トレーニングプロセスをセットアップするために、Horovodが役立ちました。
それぞれのエポックでは、異なるバッチが複数のワーカーでトレーニングされ、ワーカー間でパラメーターの平均を計算することで結果がマージされました。それぞれのエポックにおいて、データセットはワーカーの数だけ分割されます。それぞれのワーカーはそのデータをbatch_sizeに分割し、トレーニングのパラメーターとして設定されます。これにより、batch_sizeはワーカーの数だけ倍増させられるので、大規模なバッチサイズでもトレーニングが可能となります。
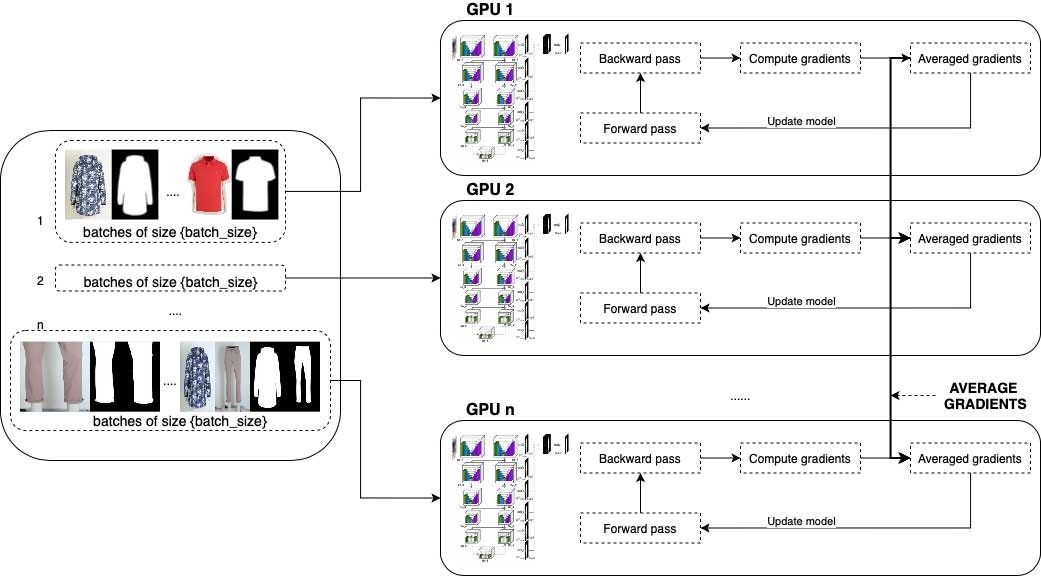
Horovodは、それぞれのエポッックの後でワーカーのパラメータを平均し、ルートノードにまとめることができます。そして、新たな値をワーカーに再分配し、次のエポックに進みます。このセットアップは、特にPyTorch環境においては非常に簡単なものとなります。
それぞれのエポックの後に検証ステップを設定したり、トレーニング中に異なる、あるいは追加のメトリクスが必要になったとします。この場合、どうすればいいのでしょうか?Horovod関数のデフォルト実装では、追加のメトリクスを考慮できないため、どのようにワーカーのパラメーターがマージされるべきかを明示的に設定する必要があります。ソリューションは、Horovodがメトリクスの平均値を計算するのと同じ関数を使うと言うものです。このことをHorovodのドキュメントで発見するのは少し難しいですが、これで解決することができます。

特筆すべき、トレーニング、検証の特徴には以下のようなものがあります。
- トレーニングパラメーターの設定(Adam optimizer, dynamic learning rate, batch_size=10*nr_gpus, epochs=~30)
- トレーニング・検証時間: シングルGPUの20ワーカーのクラスターを用いて9時間
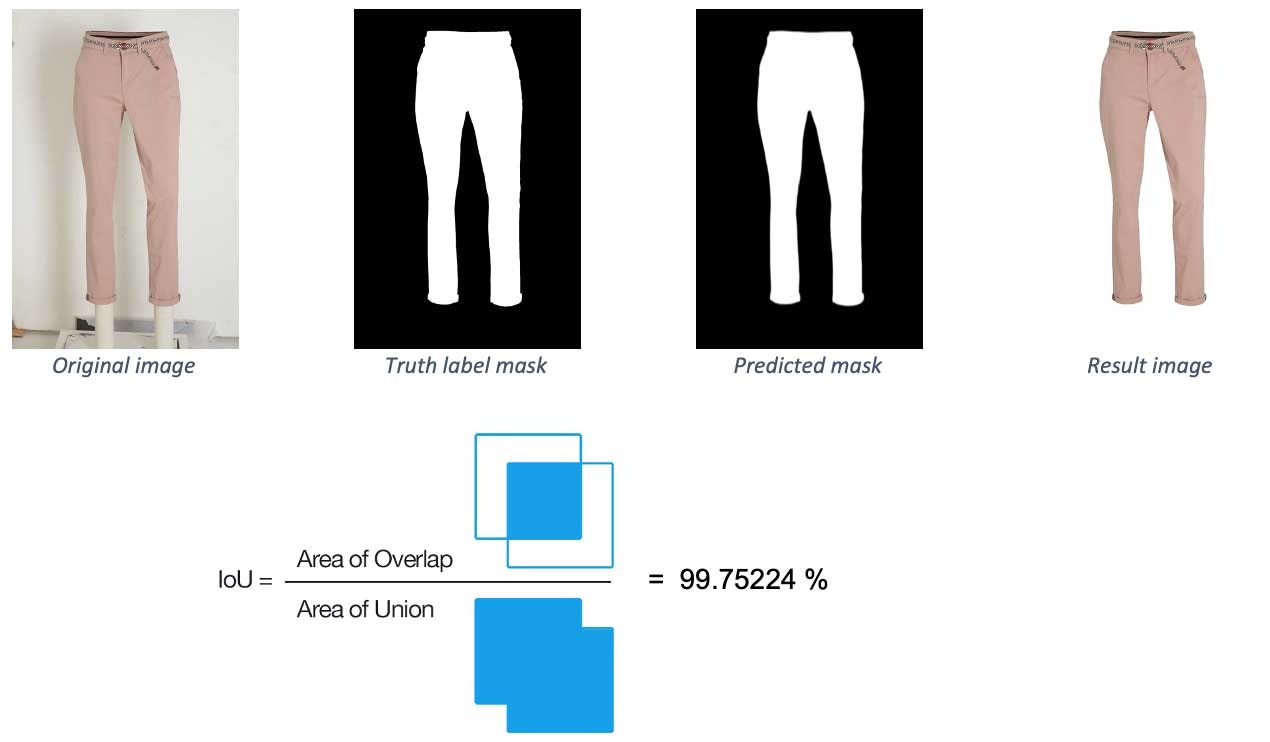
- 評価方法: Intersection over Union (IoU)メトリック
- TensorBoardメトリクス: 検証用データセットに対するlosses, learning rate, IoU metric/epoch
Intersection over Union (IoU)は、実際のマスクと比較することで予測したマスクの精度をチェックするために使用される評価メトリクスです。以下では、二つのサンプル画像におけるメトリクスの値を確認することができます。最初の例は、ほぼ100%となっており、予測したラベルはほとんど本当のラベルと同じであることを意味しています。2つ目の例では少々問題があり、低いスコアとなっています。
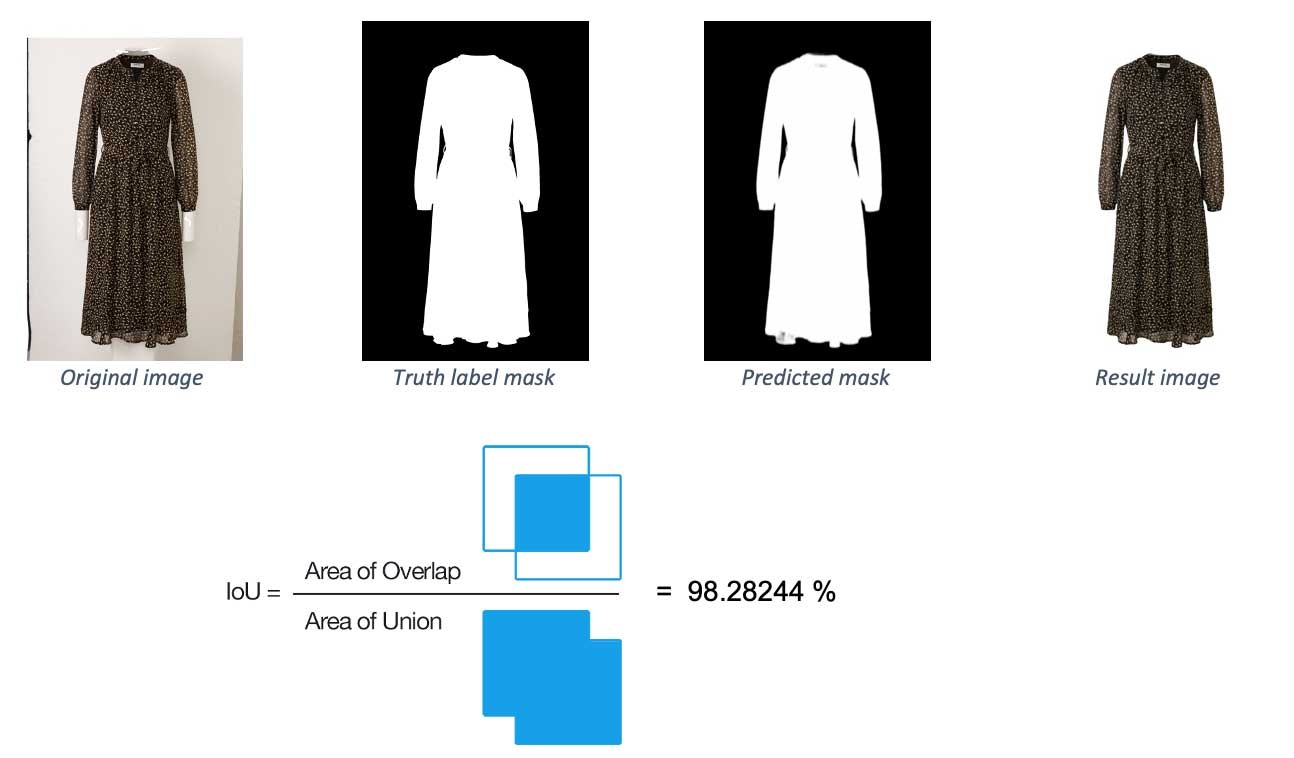
PyTorchモデルパフォーマンスおよび評価メトリクス
我々のベストモデルの平均パフォーマンスは99.435%です。特定のスコアを達成した画像の数に関しては、二つの観点から考えることができます。
まず初めに、精度で分類を行います。
- 99.3%以上の画像が95%の精度
- 98.7%以上の画像が97%の精度
- 93.1%以上の画像が99%の精度
モデルの結果を確認する別の方法は、特定の画像タイプクラスターにおけるパフォーマンスを見ると言うものです。このように見ることで、我々のモデルの強み・弱みを明確にすることができます。例えば、画像タイプで分類した際の結果は以下のようになります。
- ロングパンツ: 99.428%の精度
- ショートパンツ: 99.617%の精度
- 半袖のトップス、ドレス: 99.502%の精度
- 長袖のトップス、ドレス: 99.588%の精度
- 水着/スポーツウェア/アクセサリー: 98.815%の精度
- ライトカラー(淡彩色)の製品: 98.868%の精度
教訓
あらゆるトレーニング、実験においては、何かしらのエラーに遭遇することは避けられません。開発中に遭遇したエラーのいくつかは、アウトオブメモリー(OOM)や、ある場合には、ワーカーノードがデタッチされたことによる障害でした。最初のケースでは、エラーを起こさない最大のバッチサイズを見つけるまで、異なる値をトライしました。2つ目に関しては、クラスターにおいてスポットインスタンスではなく、オンデマンドインスタンスのみが使用されるかを常に確認することがソリューションとなりました。これは、Databrciksの機械学習ランタイムクラスターを作成する際に容易に選択することができます。
次のステップ
まとめると、eコマースのファッションのように、アイテムが定期的に変化し続けるような動的な環境でMLを使う際には、モデルのパフォーマンスがこれらの変更に追従できているかを確認することが重要となります。このプロジェクトは、実運用環境のモデルの出力結果を用いて再トレーニングを行うためのパイプラインを構築に移行することを狙いとしました。
出力画像の品質をチェックするために、設定された閾値によって、修正を行うためのインタフェースに画像を転送するかどうか、再トレーニングパイプラインのためのデータストレージに直接移動するかどうかを決定します。これを実現することで、作業の品質、お客様に提供する体験を継続的に改善すると言う新たな課題に取りめるようになりました。
詳細が気になりますか?Data + AI Summit 2021に登録し、Automated Background Removal Using PyTorchセッションに参加してください。