本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Unity Catalogの新たなセキュリティとガバナンスの機能によって、より多くのワークロードをDatabricksの高度に効率的なマルチユーザークラスターで実行できるようになり、データチームは共有計算リソース上でSQL、Python、Scalaを開発、実行できるようになったことを発表できることを嬉しく思います。これによって、DatabricksはScala、Python、SQLのSparkワークロードのために、共有計算資源できめ細かいアクセスコントロールを提供する業界で唯一のプラットフォームとなります。
Databricksランタイム13.3 LTS以降では、共有クラスターで利用できる以下の機能によって、共有クラスターにシームレスにワークロードを移行することができます:
- クラスターライブラリとinitスクリプト: 誰が何をインストールできるのかを定義する強化セキュリティとガバナンスによって、クラスターライブラリをインストールし、起動時にinitスクリプトを実行することで、クラスターのセットアップを効率化します。
- Scala: 同時実行ユーザー間での完全なユーザーコード分離と、Unity Catalogの権限を強制することで、マルチユーザーによるScalaワークロード、Python、SQLワークロードをセキュアに実行します。
- PythonとPandas UDF: 同時実行ユーザー間における完全なコード分離によって、Pythonと(scalar)Pandas UDFをセキュアに実行します。
- シングルノードの機械学習: Sparkのドライバーノードとエンドツーエンドの機械学習ライフサイクルを管理するためにMLflowを用いて、scikit-learn、XGBoost、prophet、その他の人気のMLライブラリを実行します。
- 構造化ストリーミング: 構造化ストリーミングをリアルタイムデータ処理、分析ソリューションを開発します。
Unity Catalogにおける簡便なデータアクセス
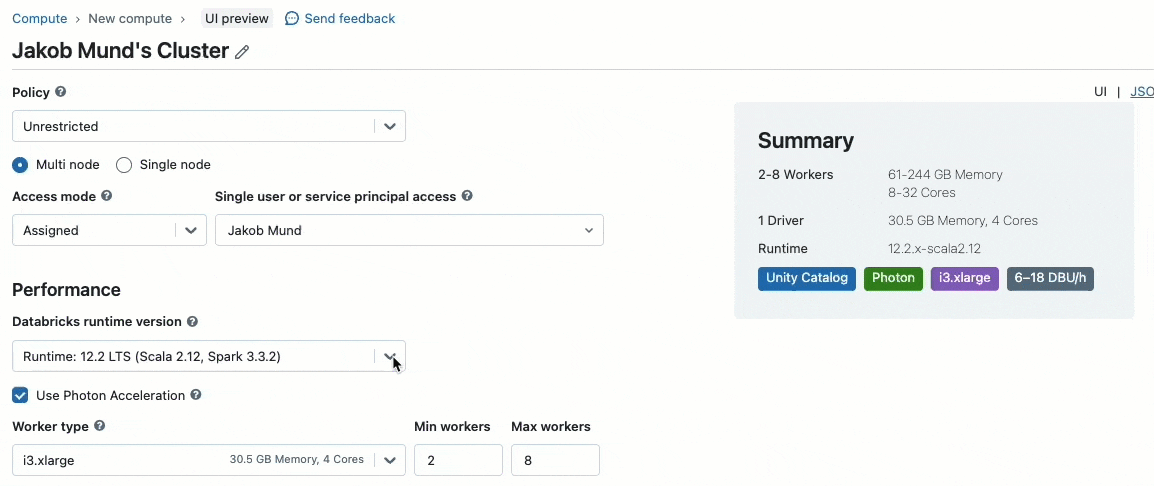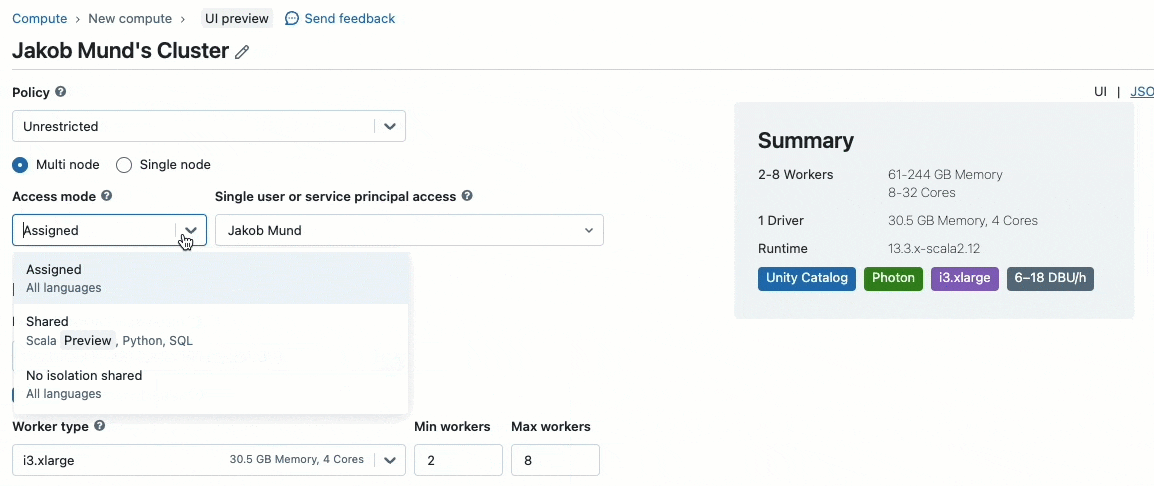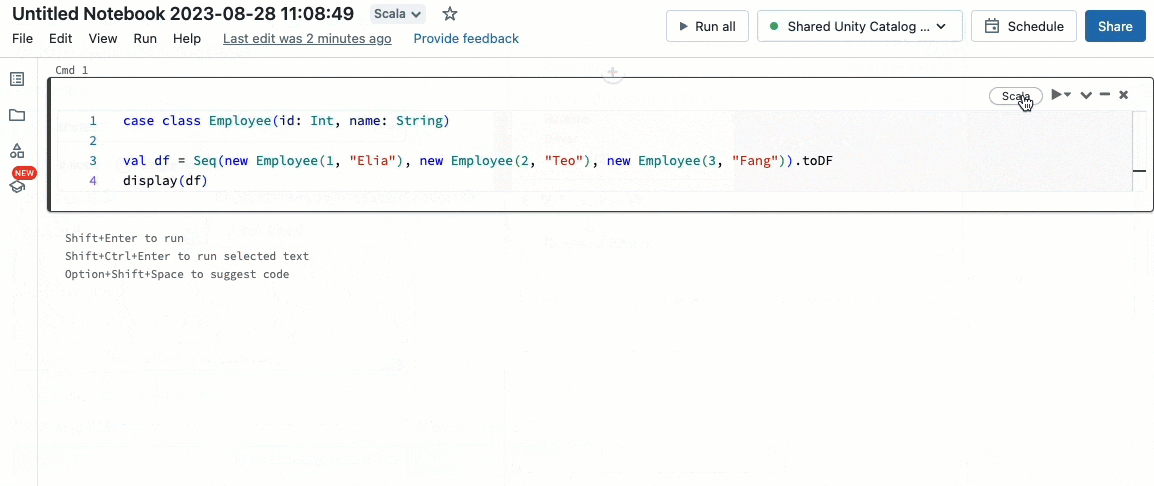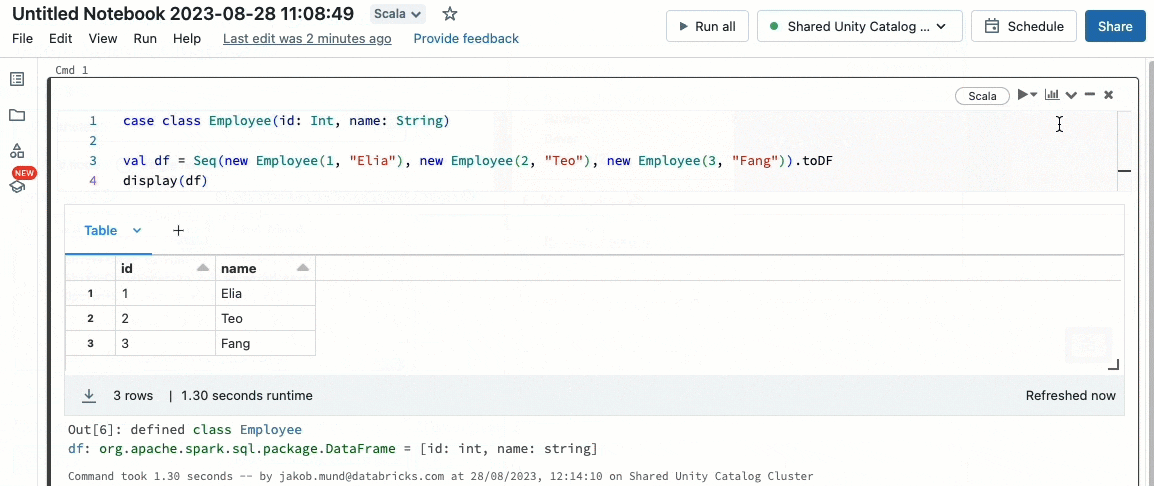
Unity Catalogで管理されるデータを取り扱うためのクラスターを作成する際、2つのアクセスモードを選択することができます:
- 共有アクセスモードのクラスター - あるいは単に共有クラスター - はほとんどのワークロードにおいて推奨の計算資源の選択肢となります。共有クラスターによって、いかなる人数のユーザーが同じ計算リソースアタッチし、同時にワークロードを実行することができ、劇的にコストを削減し、クラスター管理を簡素化し、きめ細かいアクセスコントロールを含む全体的なデータガバナンスを実現します。これは、低レベルのリソースへのアクセスを持たない完全に分離された環境下で、いかなるSQL、Python、Scalaのユーザーコードを実行するUnity Catalogのユーザーワークロードの分離によって実現されます。
- シングルユーザーアクセスモードのクラスターは、権限を伴うマシンアクセスや、RDD APIの活用、分散ML、GPU、DatabricksコンテナサービスやRを必要とするワークロードでの推奨となります。
シングルユーザークラスターは、ユーザーコードが背後のマシンへのアクセス権を持ってSpark上で実行される従来のSparkアーキテクチャに従いますが、共有クラスターはそのコードの分離を保証します。以下の図では、共有クラスター固有のアーキテクチャと分離の原則を示しています。すべてのクライアントサイドのユーザーコード(Python、Scala)は完全に分離されて実行され、Sparkエグゼキューターで実行されるUDFは、分離された環境で実行されます。このアーキテクチャによって、同じ計算し現場で複数のワークロードをセキュアに実行することができ、コラボレーティブでコスト効率が高くセキュアなソリューションを同時に提供することができます。
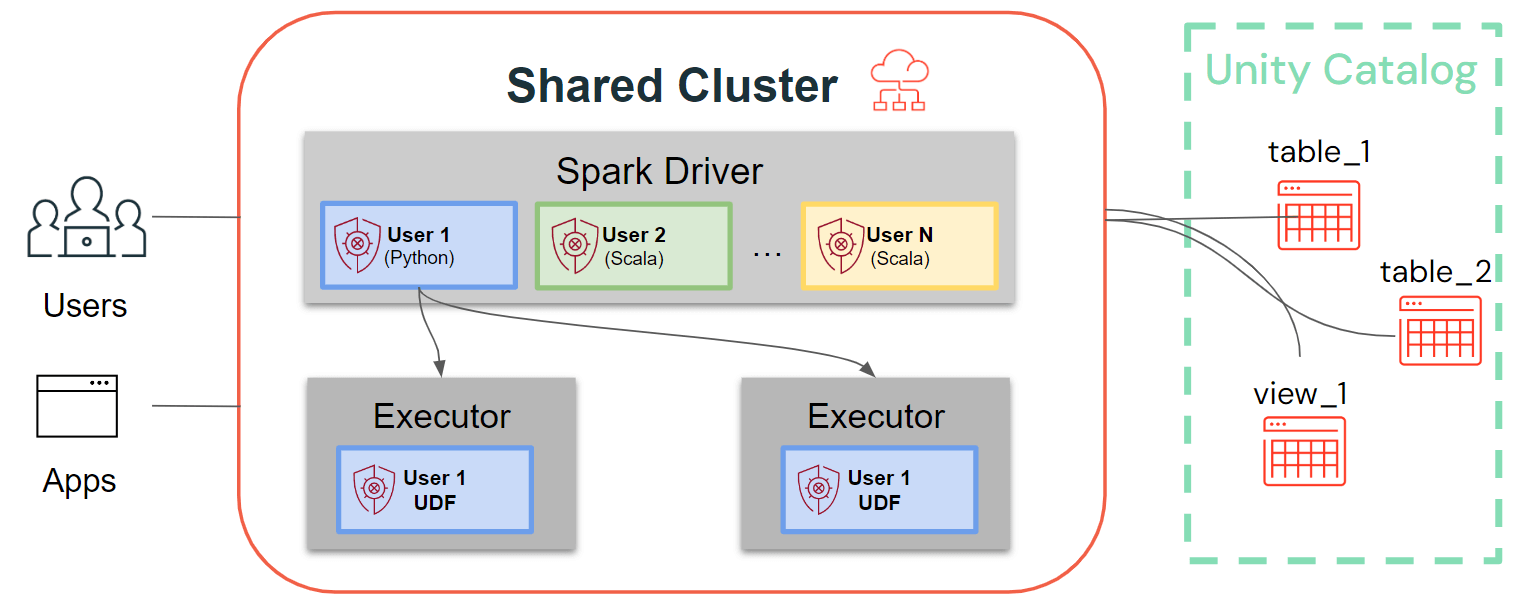
共有クラスターの最新の機能強化: クラスターライブラリ、initスクリプト、Python UDF、Scala、ML、ストリーミングのサポート
クラスターライブラリやinitスクリプトを用いた共有クラスターの設定
クラスターライブラリによって、単体のクラスターあるいは複数のクラスターであっても、ライブラリをシームレスに共有、管理することができ、バージョンの一貫性を保証し、繰り返しのインストールの必要性を削減します。機械学習フレームワーク、データベースコネクター、その他の重要なコンポーネントをクラスターに取り込む場合でも、クラスターライブラリは、共有クラスターに集中管理され労力を要しないソリューションを提供します。
既存のクラスターUI、APIを用いて、Unity Catalogのボリューム(AWS, Azure, GCP)、ワークスペースファイル(AWS, Azure, GCP)、PyPI/Maven、クラウドストレージロケーションからライブラリをインストールすることができます。
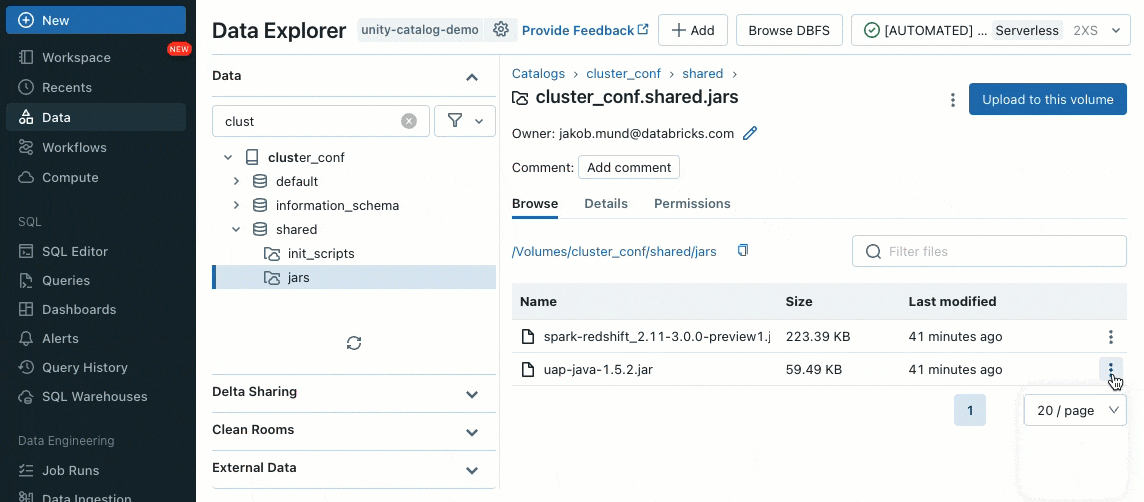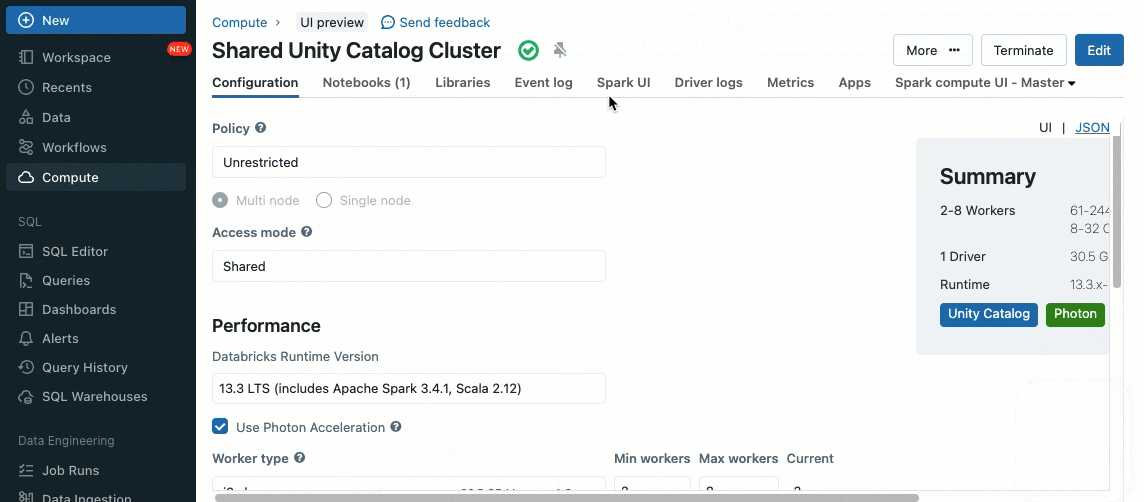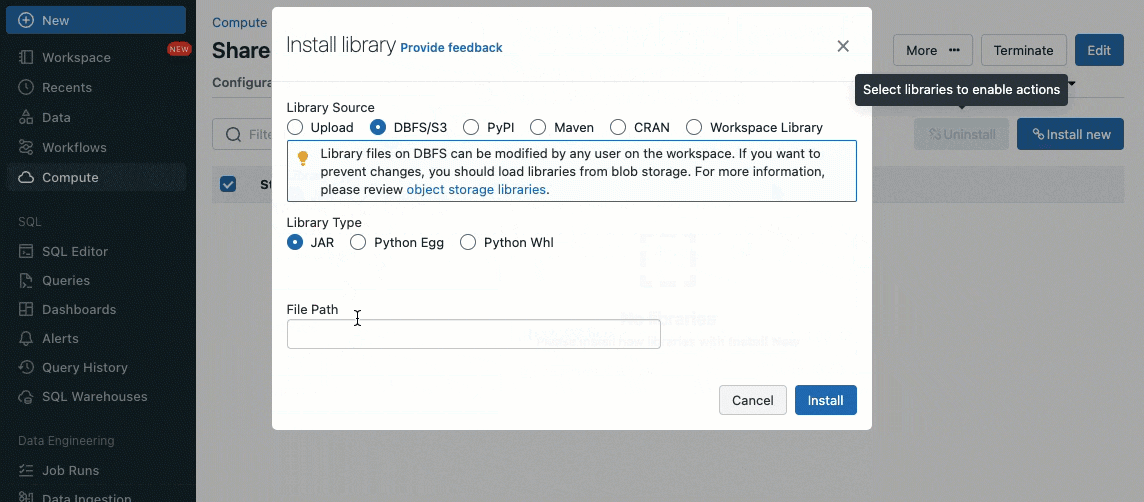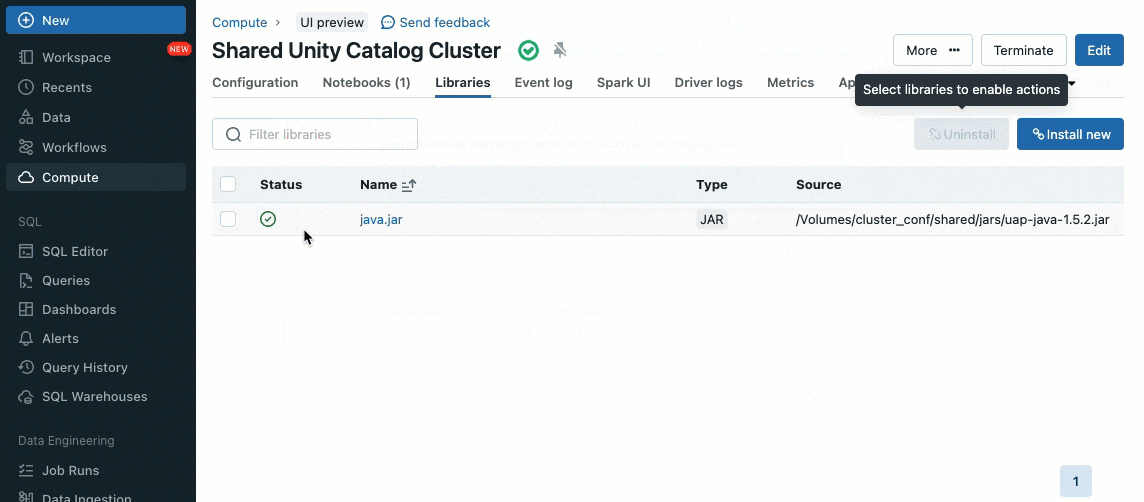
initスクリプトを用いて、クラスター管理者として認証機構、ネットワーク設定、データソースの初期化のセットアップのようなタスクを自動化するために、クラスター作成プロセスの過程でカスタムのスクリプトを実行することができます。
initスクリプトは、クラスター作成時に直接共有クラスターにインストール、あるいはクラスターポリシー(AWS, Azure, GCP)を用いてクラスターのフリートにインストールすることができます。柔軟性を最大にするために、Unity Catalogのボリューム(AWS, Azure, GCP)あるいはクラウドストレージからinitスクリプトを使用することを選択することができます。

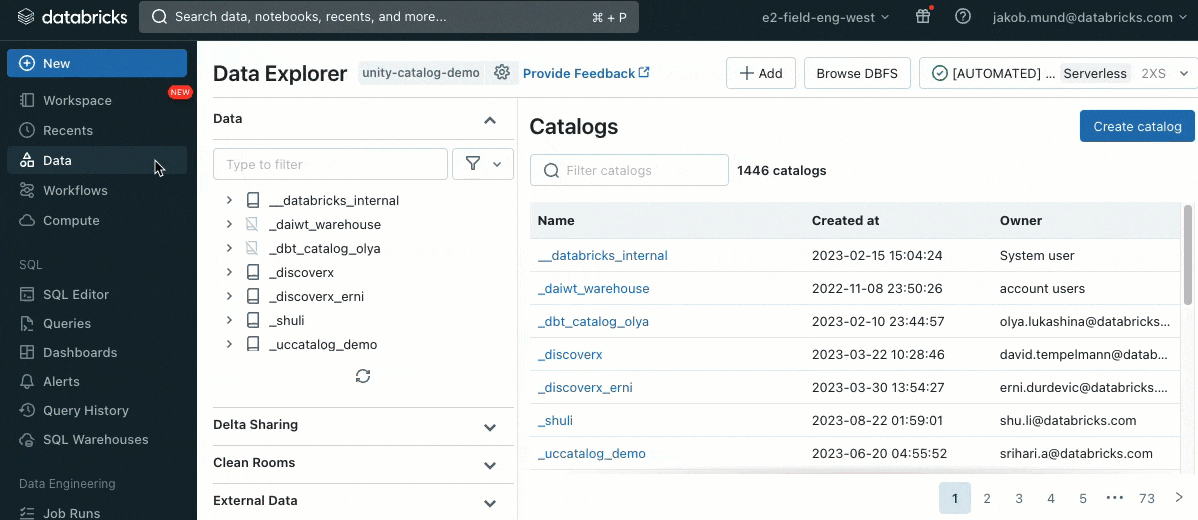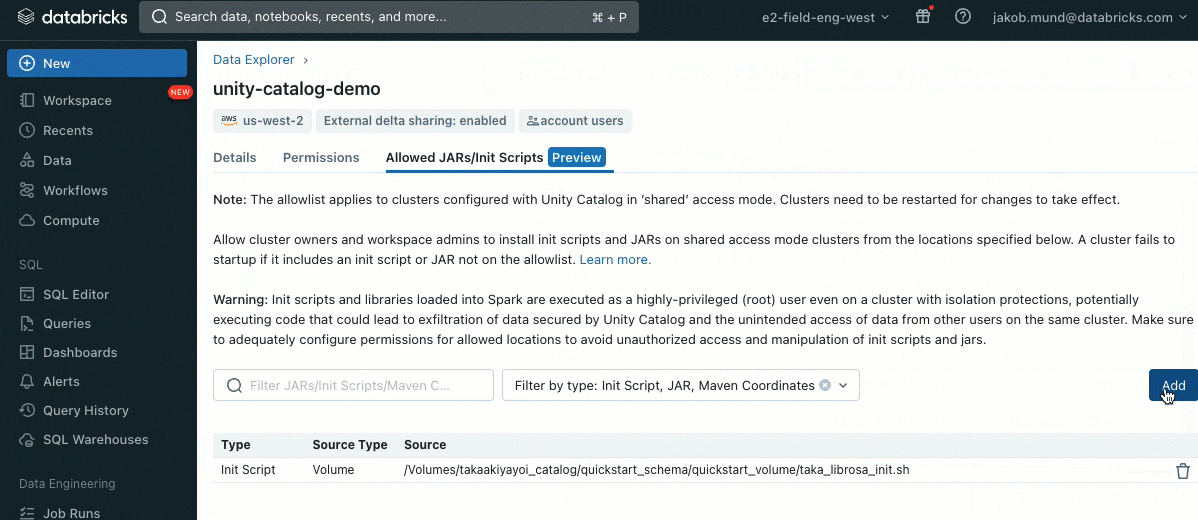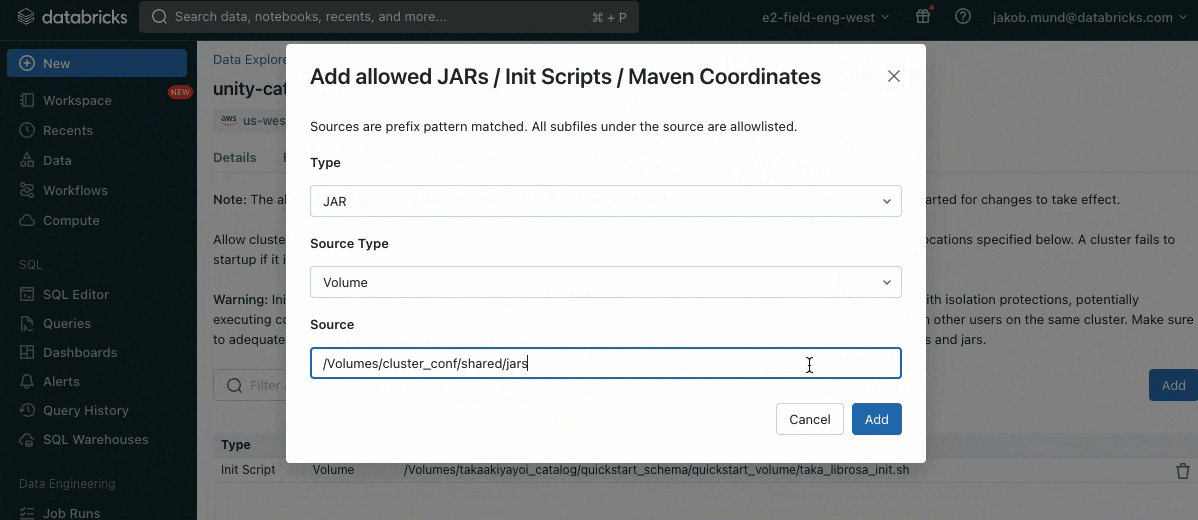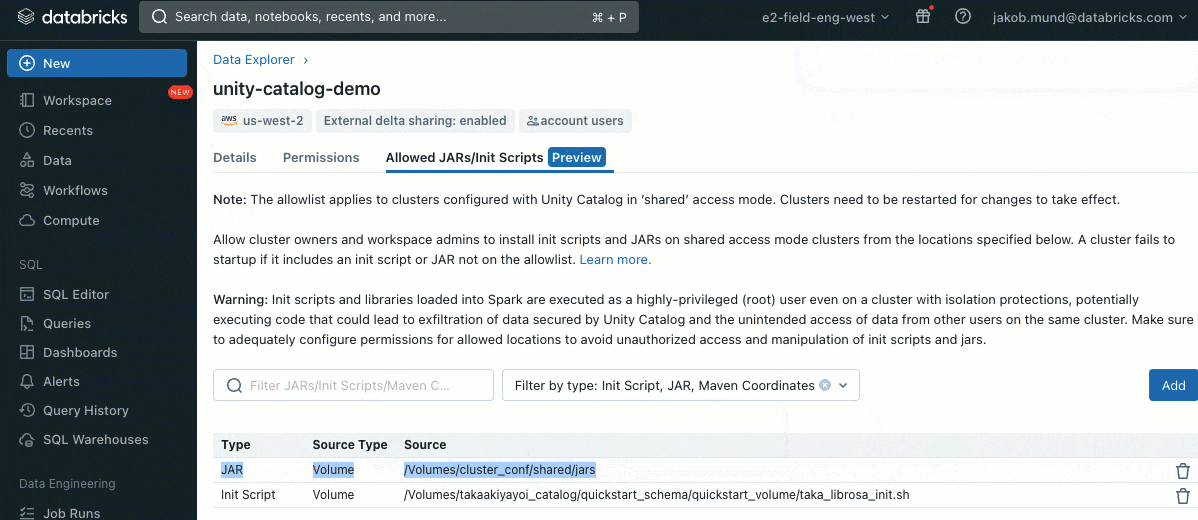
更なるセキュリティレイヤーとして、クラスターライブラリ(jar)やinitスクリプトのインストールを制御する許可リスト(AWS, Azure, GCP)を導入します。これによって、管理者は共有クラスターに対するこれらの制御を行うことができます。それぞれのメタストアにおいて、メタストア管理者はライブラリ(jar)やinitスクリプトをインストールできるボリュームあるいはクラウドストレージロケーションを設定することができ、信頼されたリソースのリポジトリの集中管理を実現し、許可されないインストールを防ぐことができます。これによって、クラスター設定に対するきめ細かい制御を実現し、組織のデータワークフローにおける一貫性を維持する助けとなります。
Scalaワークロードを持ち込みましょう
Unity Catalogで制御される共有クラスターでScalaがサポートされました。データエンジニアは、同じクラスター上でコラボレーションしながら、いかなるタイプのビッグデータの課題に対応するために、Scalaの柔軟性とパフォーマンスを活用することができ、Unity Catalogのガバナンスモデルを活用することができまうs。
既存のDatabricksワークフローにScalaをインテグレーションすることは非常に簡単です。共有クラスターを作成する際にシンプルにDatabricksランタイム13.3 LTS以降を選択すると、他のサポートされている言語と同じようにScaalを記述、実行することができます。
ユーザー定義関数(UDF)、機械学習、構造化ストリーミングの活用
これで全てではありません!共有クラスターにおいてよりゲームチェンジャーとなる進歩を共有できることを嬉しく思っています。
PythonとPandasのユーザー定義関数(UDF)のサポート: 共有クラスターでPythonと(scalar)Pandas UDFの両方のパワーを活用することができます。シームレスに共有クラスターにあなたのワークロードを持ち込むだけです。コードを適用させる必要はありません。サンドボックス化された環境で、SparkエグゼキューターにおけるUDFユーザーコードの実行を分離するjことで、共有クラスターは許可されないアクセスや漏洩の可能性を防ぎ、皆様のデータに対する追加の保護レイヤーを提供します。
SparkドライバーノードとMLflowを用いたすべてのMLライブラリのサポート: Scikit-learn、XGBoost、prophet、その他の人気のMLライブラリをと扱っているのであれば、共有クラスター上で直接シームレスに機械学習モデルを構築、トレーニング、デプロイすることができます。すべてのユーザー向けにMLライブラリをインストールするために、新たなクラスターライブラリを活用することができます。MLflow(2.2.0以降)のサポートが導入されたことで、エンドツーエンドの機械学習ライフサイクルの管理がこれまで以上に簡単なものとなります。
訳者注
上記サポートは Databricks機械学習ランタイムのサポートではありません。 あくまで、共有クラスターのドライバーノードに機械学習ランタイムをインストールでき、MLflowで管理できるということです。
構造化ストリーミングがUnity Catalogで制御される共有クラスターで利用できるようになりました。この変革的な機能追加によって、リアルタイムのデータ処理や分析を可能とし、皆様のデータチームがどのようにコラボレーションを通じてストリーミングワークロードを取り扱うのかに関して変革をもたらします。
今日始めましょう、さらに良いものがやってきます
シンプルにDatabricksランタイム13.3 LTS以降を活用することで、共有クラスターにおけるScala、クラスターライブラリ、Python UDF、シングノードのML、ストリーミングのパワーを発見しましょう。詳細を学び、データエクセレンスに向けた皆様のジャーニーをスタートするにはクイックスタートガイド(AWS, Azure, GCP)をご覧ください。
向こう数週間、数ヶ月では、Unity Catalogのコンピュートアーキテクチャの統合を継続していき、Unity Catalogを用いた作業をさらにシンプルなものとしていきます!