Announcing Ray support on Databricks and Apache Spark Clusters - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
RayはスケーラブルなAI、Pythonワークロードを実行するための有名な計算フレームワークであり、さまざまな分散機械学習ツール、大規模ハイパーパラメーターチューニング能力、強化学習アルゴリズム、モデルサービングなどを提供しています。同様にApache Spark™は、Spark MLlibを通じたさまざまな分散機械学習のための高パフォーマンスアルゴリズムと、Spark MLlib、TensorFlow、PyTorchを含む機械学習フレームワークとの密なインテグレーションを提供しています。ベストモデルを構築するために、機械学習の実践者は多くの場合、複数のアルゴリズムを探索する必要があり、RayとSparkを含む複数のプラットフォームを活用する必要が出てきます。本日、Rayバージョン2.3.0のリリースによって、RayのワークロードがDatabricksとSparkスタンドアローンクラスターでサポートされ、両方のプラットフォームでのモデル開発を劇的にシンプルにできることを発表できて嬉しく思っています。
Databricks、SparkにおけるRayクラスターの作成
DatabricksあるいはSparkクラスターでRayをスタートするには、シンプルに最新バージョンのRayをインストールし、ray.util.spark.setup_ray_cluster()関数を呼び出し、Rayワーカーの数と計算リソース割り当てを指定します。Databricks Runtimeバージョン12.0以降のDatabricksクラスター、バージョン3.3以降のSparkクラスターであればサポートされています。例えば、以下のコードはDatabricksノートブックでRayをインストールし、2つのワーカーノードでRayクラスターを初期化します。
# Install Ray with the ‘default’, ‘rllib’, and 'tune' extensions for
# Ray dashboard, reinforcement learning, and tuning support
%pip install ray[default,rllib,tune]>=2.3.0
from ray.util.spark import setup_ray_cluster
setup_ray_cluster(num_worker_nodes=2)
たった数行のコードでRayクラスターを作成し、モデルのトレーニングを開始することができます。
Ray TrainとRay RLlibによるモデルのトレーニング
Rayクラスターを起動したら、モデルを構築するために分散機械学習のパワーを活用できるようになります。すべてのRayアプリケーションとRayとインテグレーションされた機械学習アルゴリズムは、変更なしにDatabricksクラスターやSparkクラスターでサポートされます。例えば、XGBoostのモデルトレーニングを容易に分散させるために、DatabricksノートブックでRay Train APIを活用することができ、トレーニングの時間を削減し、モデル精度を改善することができます。
# Install xgboost-ray for distributed XGBoost training on Ray
%pip install xgboost-ray
import pandas as pd
import ray.data
from ray.air.config import ScalingConfig
from ray.train.xgboost import XGBoostTrainer
from sklearn.datasets import fetch_california_housing
housing_dataset = fetch_california_housing(as_frame=True)
housing_df = pd.concat(
[housing_dataset.data, housing_dataset.target], axis=1
)
trainer = XGBoostTrainer(
scaling_config=ScalingConfig(num_workers=2),
label_column="MedHouseVal",
num_boost_round=20,
params={
"objective": "reg:squarederror",
"eval_metric": ["logloss", "error"],
},
datasets={"train": ray.data.from_pandas(housing_df)}
)
training_result = trainer.fit()
また、Rayは強化学習をネイティブでサポートしています。例えば、Taxi Gymnasium environmentでPPO強化学習アルゴリズムをトレーニングするために、Databricksノートブックで以下のRay RLlibコードを実行することができます。
from ray.rllib.algorithms.ppo import PPOConfig
config = ( # 1. Configure the algorithm,
PPOConfig()
.environment("Taxi-v3")
.rollouts(num_rollout_workers=2)
.framework("tf2")
.training(model={"fcnet_hiddens": [64, 64]})
.evaluation(evaluation_num_workers=1)
)
algo = config.build() # 2. build the algorithm,
for _ in range(3):
print(algo.train()) # 3. train it,
algo.evaluate() # 4. and evaluate it.
この他のモデルトレーニングに関する情報やサンプルについては、Ray Train documentationやRay RLlib documentationをチェックしてみてください。
Ray Tuneによる最適モデルの発見
モデルの品質を改善するために、大規模かつ並列で数千のモデルパラメーター設定を探索するためにRay Tuneを活用することもできます。例えば、以下のコードではscikit-learnの分類モデルを最適化するためにRay Tuneを活用しています。
# Install the scikit-learn integration for Ray Tune
%pip install tune-sklearn
from sklearn.datasets import load_iris
from sklearn.linear_model import SGDClassifier
from ray.tune.sklearn import TuneGridSearchCV
X, y = load_iris(return_X_y=True)
parameter_grid = {"alpha": [1e-4, 1e-1, 1], "epsilon": [0.01, 0.1]}
tune_search = TuneGridSearchCV(
SGDClassifier(), parameter_grid, max_iters=10
)
tune_search.fit(X, y)
best_model = tune_search.best_estimator
Ray with MLflowの使用法を含む、Rayにおけるモデルチューニングの情報とサンプルについては、Ray Tune documentationを参照ください。
Rayダッシュボードの参照
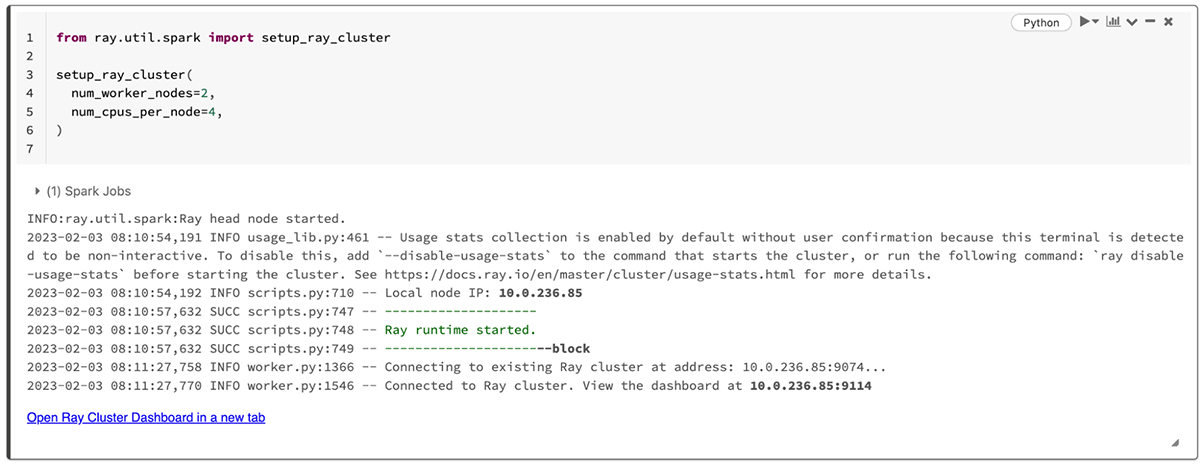
DatabricksクラスターでRayを起動すると、Rayダッシュボードへのリンクが表示されます。
モデル開発を通じて、Ray dashboardを用いることで、Rayの機械学習タスクの進捗とRayノードの健康状態をモニタリングすることができます。Rayクラスターを作成すると、ray.util.spark.setup_ray_cluster()はRayダッシュボードへのリンクを表示します。

Rayダッシュボードはクラスターのノード、アクター、ログなどの詳細情報を提供します。
Rayダッシュボードは、Rayクラスターのノード、アクター、メトリクス、イベントログの包括的なビューを提供します。個々のノードのリソース利用メトリクスやすべてのノードの集計メトリクスを容易に参照することができます。Rayダッシュボードの詳細については、Ray dashboard documentationを参照ください。
Databricks、SparkでRayを使い始める
Ray 2.3.0によって、DatabricksクラスターやSparkクラスターでRayアプリケーションを実行できるようになりました。Databricksを利用されているのであれば、シンプルにバージョン12.0以降のDatabricks RuntimeのDatabricksクラスターを作成し、スタートするためにDatabricksにおけるRayの活用をご覧ください。最後に、スタンドアローンSparkクラスターでRayを起動する手順に関しては、Ray on Spark documentationをチェックしてください。また、Rayにおける機械学習の詳細についてはhttps://docs.ray.io/en/latest/をご覧ください。
我々は分散機械学習の相互運用可能性を前進させることができて非常に興奮していますし、されにApache Spark™とDatabricksにおけるRayアプリケーションを強化することを楽しみにしています!