5 Steps to Get Started With Databricks on Google Cloud - The Databricks Blogの翻訳です。
今年初めにGoogle CloudのDatabricksをローンチしてから、我々はこのジョイントソリューションが世界中のデータチームに価値をもたらしたストーリーを見て興奮し続けています。我々のお気に入りの引用は、J.B.HuntのバイスプレジデントアナリティクスのDouglas Mettenburgによるものです。「最終的には、Google CloudのDatabricksは今や、J.B.Huntの信頼できる情報源となっています。我々がビジネスにインパクトをもたらすAIソリューションを構築すればするほど、企業全体にもたらすデータの真の価値を示しています。」
Douglasが述べているように、Google CloudのDatabricksは、全ての分析、AIワークロードを統合するシンプルかつオープンなレイクハウスプラットフォーム上で全てのデータを格納するように設計されています。クラウドベースのレイクハウスアーキテクチャを用いてデータエンジニアリング、データサイエンス、アナリティクス間でのコラボレーションを改善することで、企業におけるデータドリブンによる意思決定を加速します。そして、アクセスを容易にするために、このソリューションは他のインフラストラクチャと同じように、Google Cloudコンソールからアクセスすることができます。
Google CloudでDatabricksを始める最初の一歩は簡単です。ステップバイステップの指示を説明している以下のガイドに従うだけです。デモ動画でこれらのステップを参照することもできます。
1. GCPマーケットプレースからDatabricksをサブスクライブする
Google Cloud Platformにログインするところからスタートします。新規ユーザーである場合には、Databricksをサブスクライブする前にアカウントを作成する必要があります。コンソールに移動したら、既存のGoogle Cloudプロジェクトを選択するか、新規プロジェクトを作成し、お使いのGoogle Cloudコンソールで定義されているGoogle Cloudアイデンティティオーガニゼーションオブジェクトを確認します。このステップでは、Google請求アカウントをセットアップするか、Databricksで使用する既存のアカウントを選択するために、請求管理者による許可が必要となります。これはGCPコンソールの左のナビゲーションバーの請求から行うことができます。
パートナーソリューションの中にあるDatabricksを探すか、シンプルにマーケットプレースで検索します。これでサブスクライブする準備ができました。
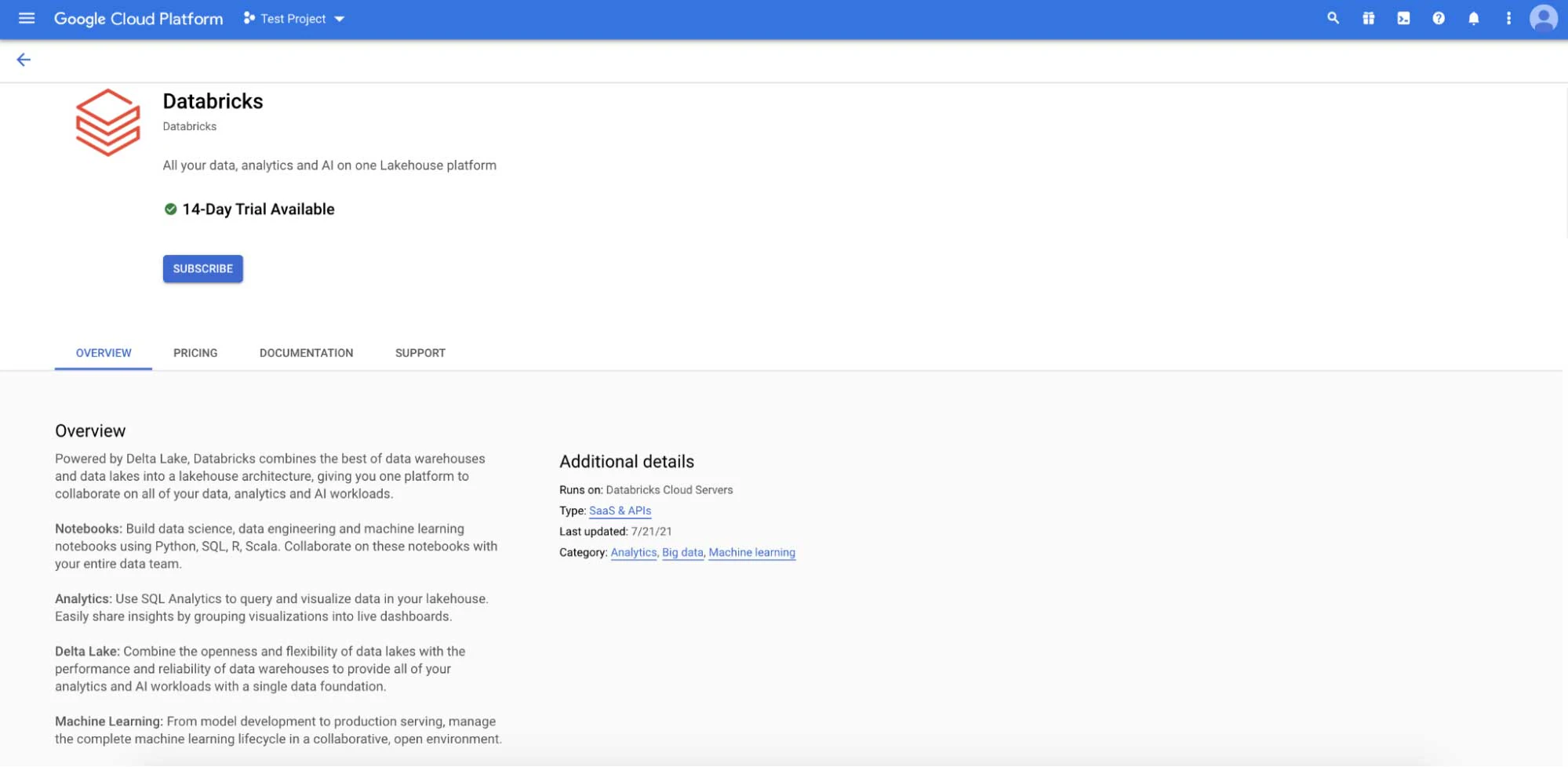
条項を確認したら、馴染みのある青いGoogle SSOを用いてサインインすることができます。Google IAMとの密連携によって、GoogleのOAuth 2.0実装を通じて、お使いのGoogle Cloudアイデンティティを用いて、Databricksのワークスペースに対してシンプルに認証することができます。すなわち、Databricksはあなたのログイン情報にアクセスする必要がなく、Databricksに認証情報を格納したり、防御したりすることに関するリスクを排除することができます。
2. GCPにおけるDatabricksセットアップの前提条件
最初のDatabricksワークスペースを作成する準備はほぼできていますが、以下の前提条件を確認しましょう。
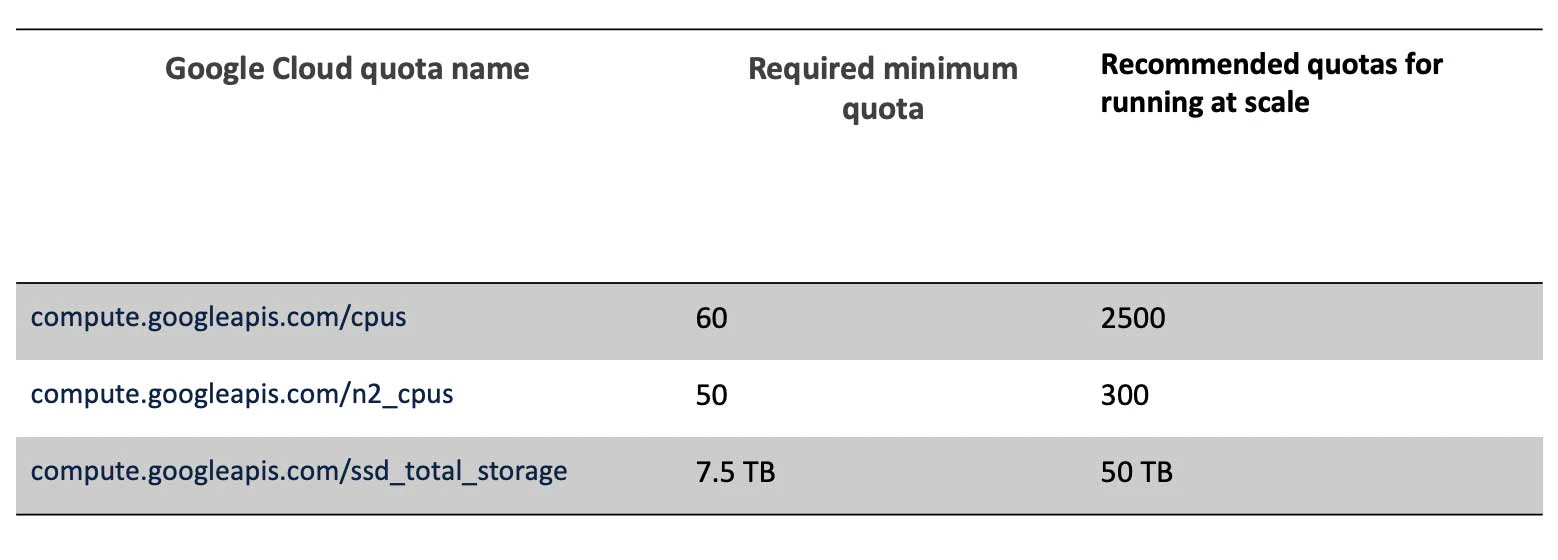
適切なリソースクォータを確認
Databricksクラスターが実行することになるターゲットのGoogle Cloudリージョンで、必要な最低限のクォータを割り当てる必要があります。お使いのプロジェクトがGCPのデフォルト値よりも少ない場合には、ドキュメントに記載されているクォータの完全なリストを確認することをお勧めします。
ネットワークのサイズの設定
次に、Databricksワークスペースで使用するGKEサブネットを設定します。最初のワークスペースを作成する前にのみ必要であり、ワークスペースにおいてDatabricksのジョブがうまく動作するために十分なIPスペースが必要となりますので、重要な作業となります。これを簡単に行えるように、Databricksでは、皆様の要件に応えるサブネットのデフォルトのIPレンジの決定をサポートする計算機を提供しています。
セッション長の制限の確認
もし、あなたの会社のIT管理者が、ユーザーログインにおけるセッション長のグローバル制限を設定している場合には、Databricksは適切に動作しません。この場合、Googleワークスペースにおける信頼済みアプリケーションリストにDatabricksを追加するよう管理者に依頼してください。詳細はこちらを参照ください。
3. 最初のワークスペースの作成
これで、Databricksワークスペースを作成する準備が整いました。前提条件を設定したら、Databricksアカウントコンソール上で、名前、リージョン、Google CloudのプロジェクトIDを指定して最初のワークスペースを作成します。


4. ワークスペースにユーザーを追加
Databricks管理者はadmin consoleでユーザーアカウントを管理することができます。管理者として以下のことを行えます。
- さらなるユーザーの招待、ユーザーの削除
- クラスター作成権限を付与することができるように、他のユーザーを管理者に任命
ロールベースのアクセスコントロール(RBAC)のためにグループを作成することで、異なるユーザーグループが異なる権限を持つことができます。繰り返しになりますが、ネイティブのIAMインテグレーションによって、ユーザー認証は非常にシンプルなものになります。
5. 最初のDatabricksジョブの実行
これからお楽しみです!お使いのDatabricksワークスペースで、クエリーやジョブを実行するコンピュートエンジンインスタンスを利用できるように、新規クラスターを作成します。最初に新規クラスターを作成した際、DatabricksはGKEクラスターを起動しますが、これは約20分かかります。それ以降のDatabricksクラスターの起動は数分で済みます。
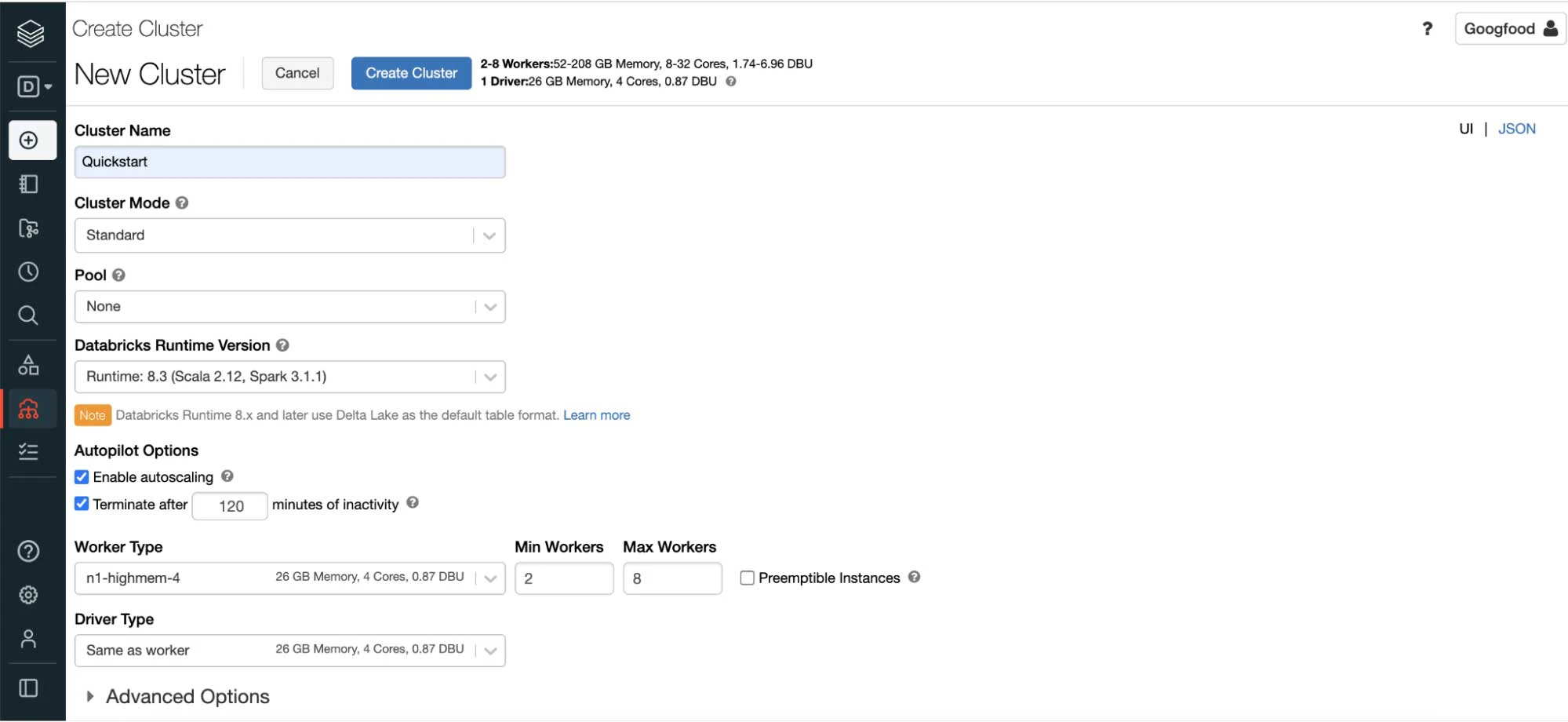
どのように操作するのかに関しては、クイックスタートのチュートリアルノートブックを探索してみましょう。ノートブックはDatabrikcsクラスターで計算を実行するセルの集合体です。ノートブックをクラスターにアタッチしたら、Python、SQL、R、Scalaのようなサポート言語を用いてクエリーを実行することができますし、同じノートブックで言語を切り替えることもできます。
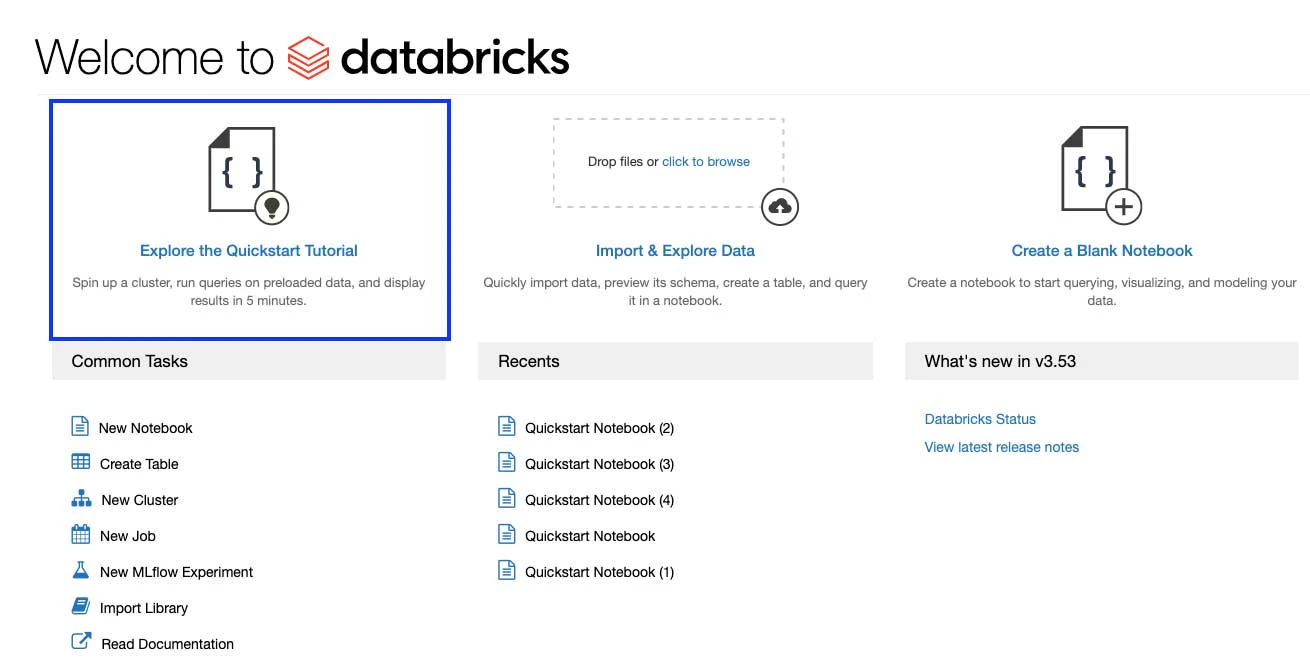
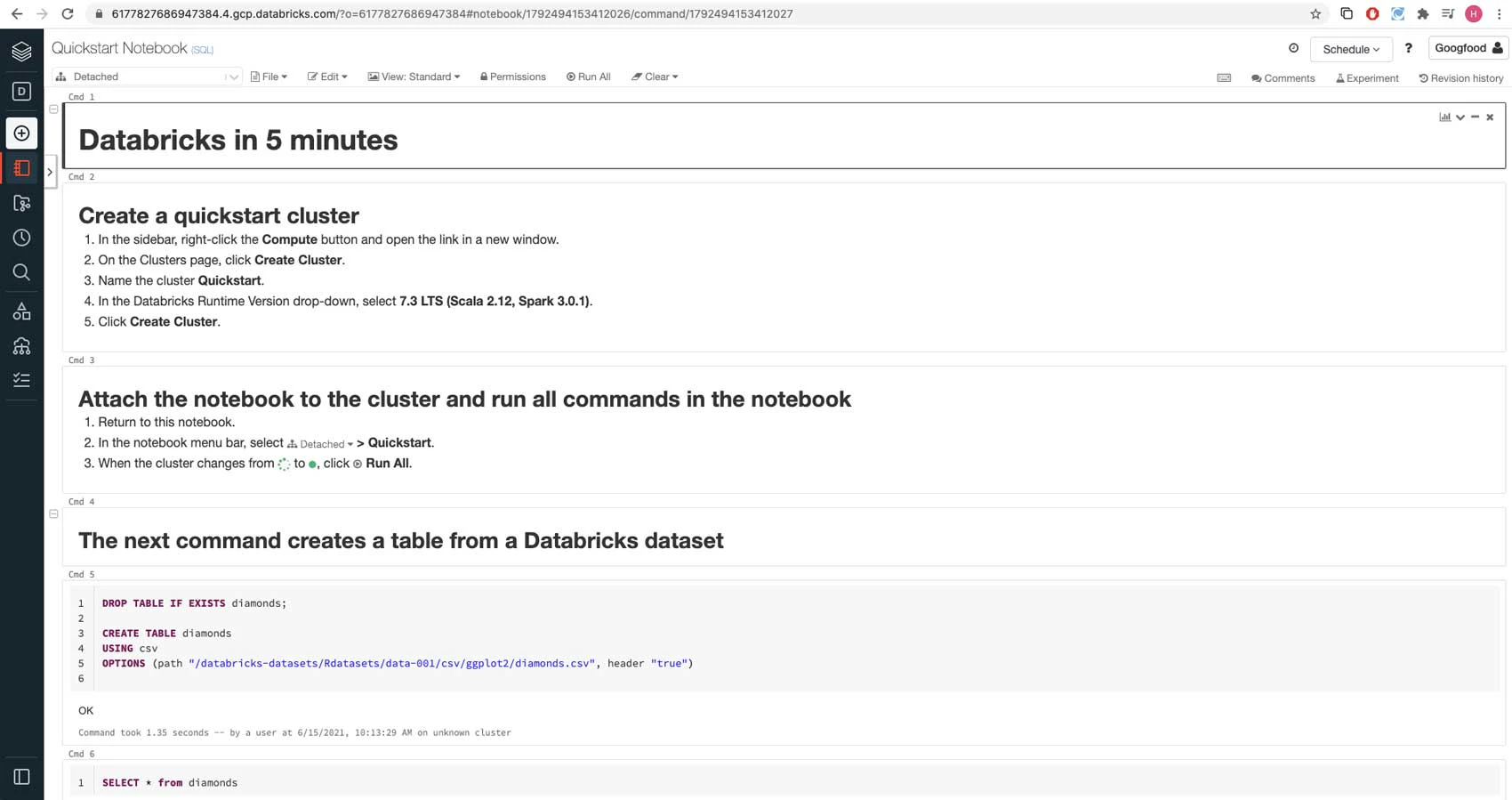
ここでは、Databricksクラスターにインストールされる分散ファイルシステムであるDatabricksファイルシステム(DBFS)にマウントされるデータセットのコレクション、Databricksデータセットで利用できるサンプルCSVデータファイルのデータを用いてテーブルを作成しています。
CSVデータをDelta Lakeフォーマットで保存し、Deltaテーブルを作成します。Delta Lakeは、お使いのデータレイクに信頼性、セキュリティ、パフォーマンスをもたらすオープンテーブルフォーマットです。Delta LakeフォーマットはParquetファイルとトランザクションログから構成されており、テーブルに対して今後行うオペレーションでベストな性能を得るためにDelta Lakeを活用します。
次に、CSVデータをデータフレームに読み込み、Delta Lakeフォーマットで書き出します。このコマンドでは、Python言語マジックコマンドを使用しており、ノートブックのデフォルト言語(SQL)に加え別の言語を組み合わせることを可能にしています。
これで、格納場所にDeltaテーブルを作成し、色ごとのダイアンモンドの平均価格をテーブルに問い合わせるSQL文を実行する準備が整いました。色ごとのダイアモンドの平均価格のグラフを表示するために、棒グラフアイコンをクリックします。
これで全てです!これが、Google Cloudアカウント上でDatabricksをセットアップし、ユーザーとしてワークスペース、クラスター、ノートブックを作成し、SQLコマンドを実行し、結果を表示するのかの手順となります。
質問がありますか?
あなたの疑問に対する答えが欲しい、あるいは、Google CloudでDatabricksをスタートする方法を学びたいのであれば、ライブのインストラクター付きのハンズオンワークショップに登録下さい。複数の日程がございます。ぜひ登録ください!