ユーザー部門の方からCSVファイルをアップロードしてもらって、それに対して処理を行い、結果を返すというユースケースは結構多いと思います。
こちらで紹介しているように、処理を行う機械学習モデルをMLflowモデルサービングで動作させ、UIの画面をStreamlitで構築するという構成を組むことは可能ですが、モデルとMLflowの連携やStreamlitへの処理の組み込みなど、それなりに敷居は高いです。
そこで、こちらではアップロードする人がDatabricksにアクセスできるという前提のもとで、簡単にファイルの授受を行えるアプリケーションをDatabricks上で構築する手順を説明します。
全体としては、ユーザー部門の方が以下の操作を行う流れとなります。
- Databricksノートブックの画面から、処理対象のCSVファイルをDatabricksファイルシステムにアップロード
- 処理を行うノートブックをジョブとして実行
- 処理結果のファイルをノートブックからダウンロード
注意
こちらで紹介しているアプリケーションは社内でのみ活用するプロトタイプと捉えてください。実際にプロダクションに移行するには、セキュリティ設計をしっかり行い、必要に応じてクラウドのネイティブサービスの活用も検討してください。
ファイルのアップロード(ユーザー部門)
ノートブックの画面からファイルをアップロードします。以下ではファイルアップロードおよび処理実行の手順を説明しています。
- アップロードするCSVファイルが以下の構造になっていることを確認してください。
| id | target |
|---|---|
| 1 | 10 |
- 画面上部にあるメニューからファイル > データをアップロードを選択します。
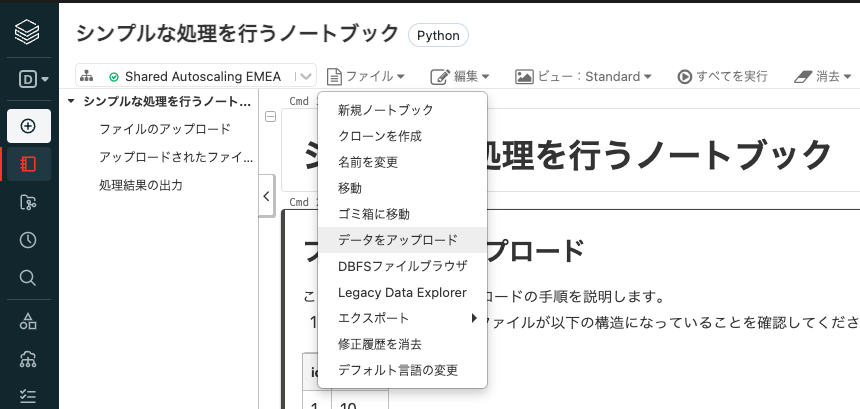
- 以下のダイアログのDBFSターゲットディレクトリで、下のCmd5で指定されている
upload_pathの場所を選択します。
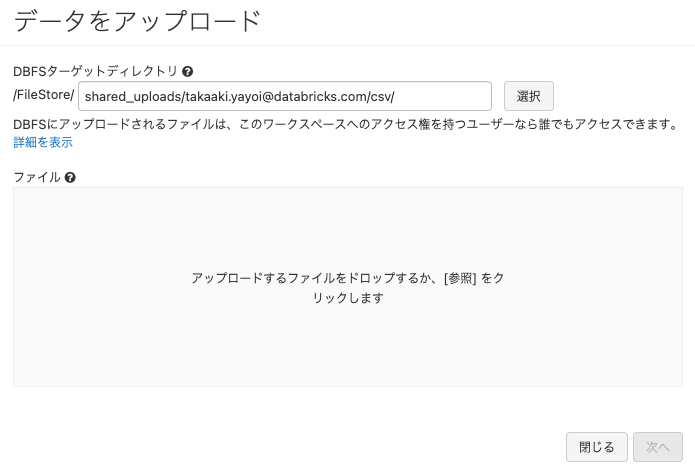
- アップロードするファイルをファイルにドラッグアンドドロップします。
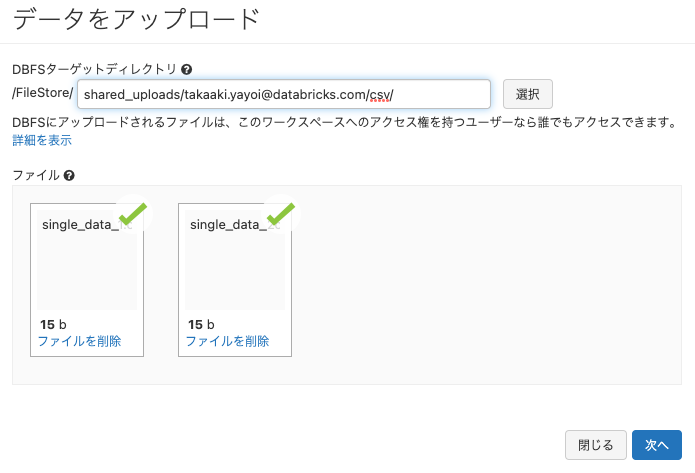
- 次へをクリックします。
- 完了をクリックします。
ノートブックの実装(開発者)
アップロードされたファイルの処理
以下の例ではpandasで処理を行います。もちろん、Sparkなど任意の処理を記述することができます。
Python
# CSVがアップロードされるDBFS上のパス
upload_path = "/FileStore/shared_uploads/takaaki.yayoi@databricks.com/csv"
# 処理結果を格納するDBFS上のパス
output_path = "/FileStore/shared_uploads/takaaki.yayoi@databricks.com/output"
Python
# アップロードパスのクリーンアップ
# アップロード先をクリアする際には以下のコメントを解除して実行してください。
#dbutils.fs.rm(upload_path, True)
# 出力パスのクリーンアップ
# 出力先をクリアする際には以下のコメントを解除して実行してください。
#dbutils.fs.rm(output_path, True)
Python
# 上のパスで指定されているディレクトリが存在しない場合には作成します
dbutils.fs.mkdirs(upload_path)
dbutils.fs.mkdirs(output_path)
# ローカルファイルAPIであるpandasからアクセスするので、パスの先頭に/dbfsをつけます
pandas_upload_path = f"/dbfs{upload_path}"
pandas_output_path = f"/dbfs{output_path}"
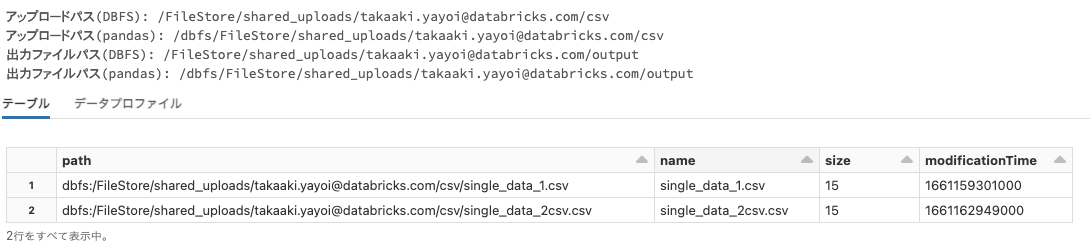
print("アップロードパス(DBFS):", upload_path)
print("アップロードパス(pandas):", pandas_upload_path)
print("出力ファイルパス(DBFS):", output_path)
print("出力ファイルパス(pandas):", pandas_output_path)
# Databricks Utilityを使ってファイルを確認します
display(dbutils.fs.ls(upload_path))
Python
import pandas as pd
import glob
import os
# 対象ディレクトリ配下のCSVファイルを対象とします
all_files = glob.glob(os.path.join(pandas_upload_path , "*.csv"))
# 上記ディレクトリ配下にあるすべてのCSVを読み込んで結合します。
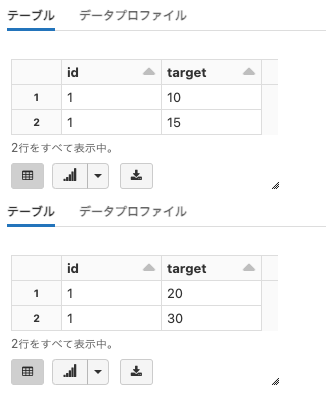
df = pd.concat((pd.read_csv(f) for f in all_files), ignore_index=True)
# 読み込んだデータの確認
display(df)
# データ処理
# こちらではtargetの値を2倍にしています
df['target'] = df['target'] * 2
# 処理結果を確認
display(df)
処理結果の出力
Python
import datetime
# ファイル名にタイムスタンプを埋め込みます
# デフォルトのタイムゾーンはUTCなのでJSTを指定します
dt_now_jst = datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9)))
output_file_name = dt_now_jst.strftime('%Y%m%d_%H%M%S') + '.csv'
output_file_path = os.path.join(pandas_output_path , output_file_name)
print("出力ファイル:", output_file_path)
df.to_csv(output_file_path)

# Databricks Utilityを使ってファイルを確認します
display(dbutils.fs.ls(output_path))

ダウンロードリンクの生成
Python
import re
# FileStoreをfilesに置き換えます
download_url_path = re.sub("FileStore", "files", output_file_path)
# 先頭の/dbfsを除外します
download_url_path = re.sub("^/dbfs", "", download_url_path)
print(download_url_path)

Python
displayHTML (f"""
以下のリンクから処理結果ファイルをダウンロードしてください。<br>
<a href='{download_url_path}'>{output_file_name}</a>
""")
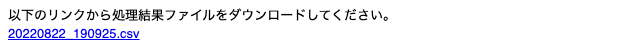
ノートブックをジョブとして登録(開発者)
ノートブック作成者以外の方でも実行できるようにジョブとして登録します。ここでは、エンドユーザーの方にはあまりプログラミングの経験がないことを想定して、可能な限りノートブックの処理を表に出さないようにしています。
- 画面右上のスケジュールをクリックします。
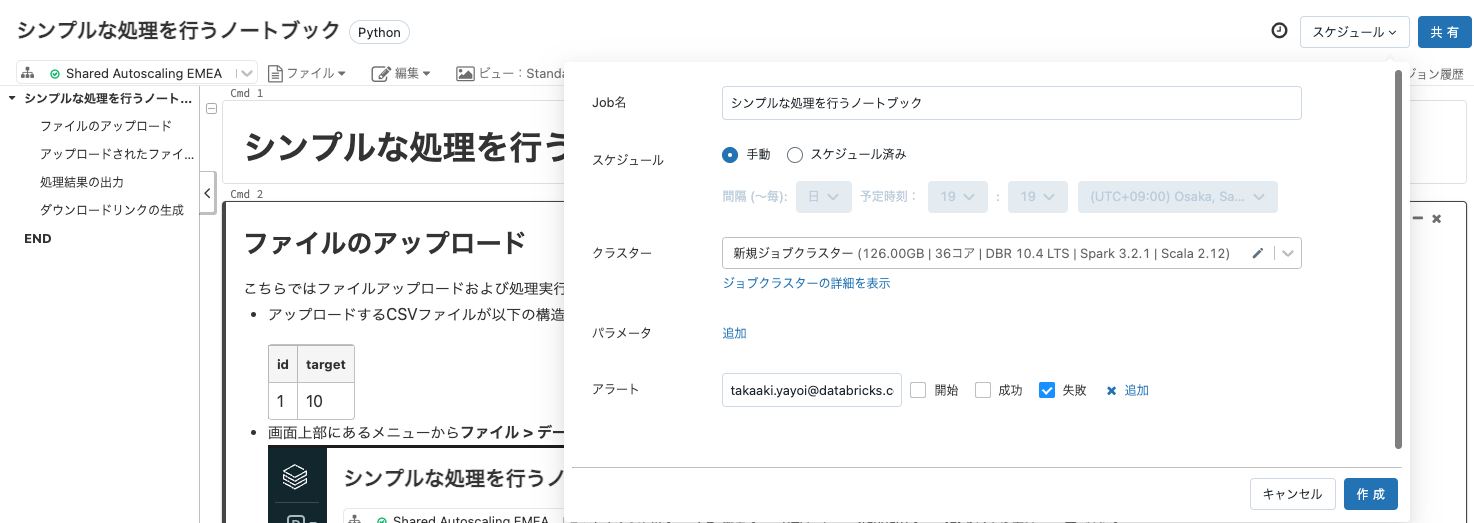
- 手動を選択して作成をクリックします。
- もう一度右上のスケジュールをクリックします。
- ジョブに表示をクリックすると別タブでジョブ画面が開きます。この際、ブラウザで表示されるURLをメモしておきます。
注意
- この時点でジョブの設定を変更することができます。Computeではジョブの実行に使用するクラスターを設定することができますが、デフォルトでは新規にジョブクラスターを作成して実行するのでジョブの起動に数分の時間を要します。常時稼働のクラスターがある場合にはそれを指定することで、ジョブの実行時間を短縮することができます。
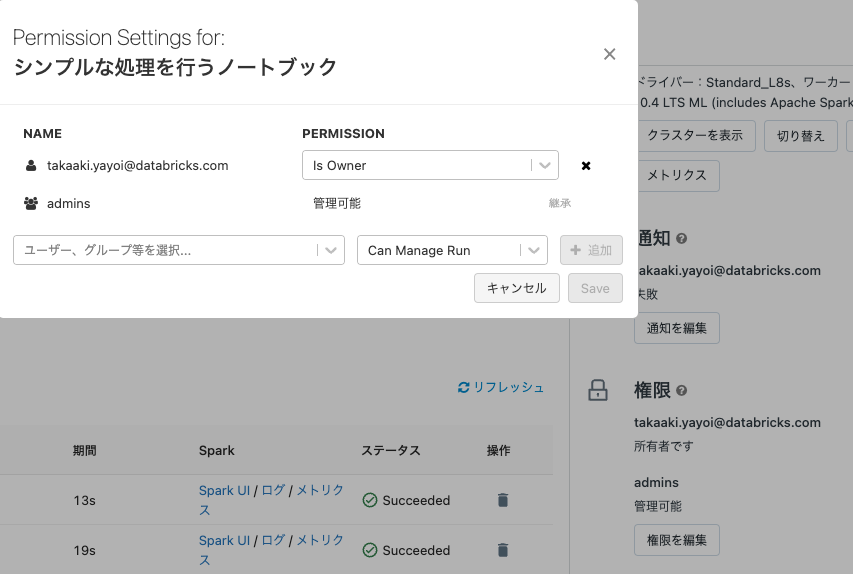
- ジョブを実行させたいユーザーに対して実行権限
Can Manage Runを与えてください。
- ノートブックのコードを非表示にしたい場合には、セルの右上の下向き矢印をクリックして、メニューからコードを非表示を選択します。
ジョブ実行手順を説明(開発者)
以下のようなドキュメントをユーザー部門の方に共有します。
Markdown
- `<a href="<上記ジョブのURL>" target="_blank">こちらのリンク</a>`をクリックし、ジョブを開いてください。
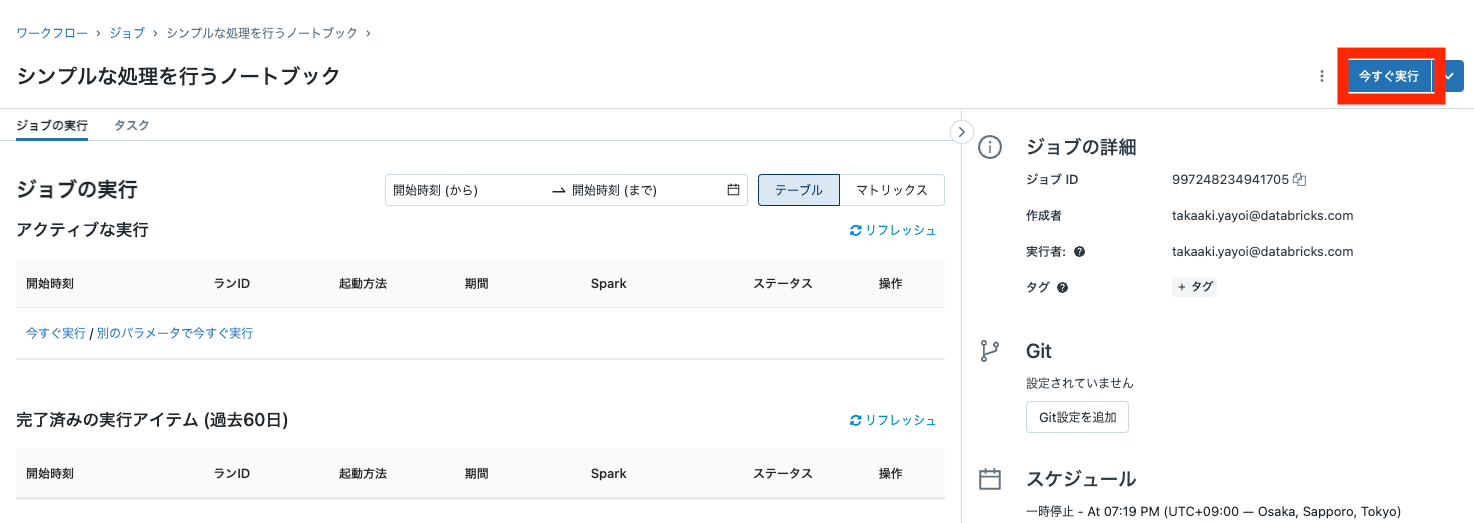
- **今すぐ実行**をクリックしてください。
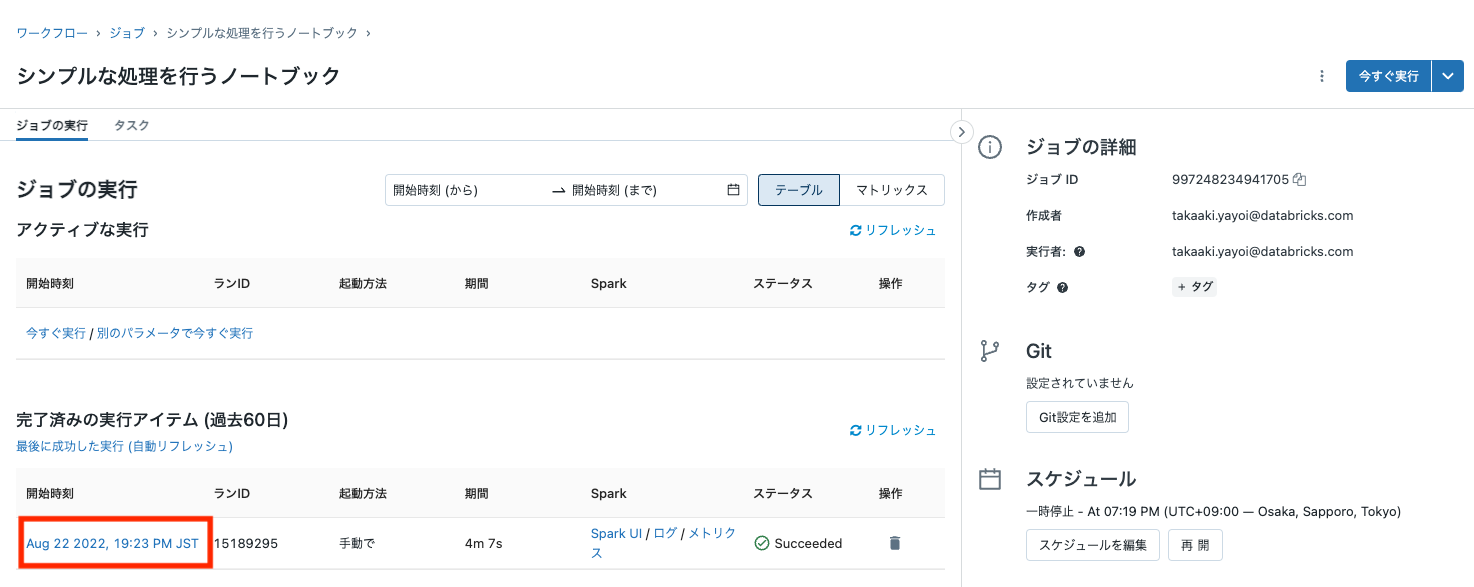
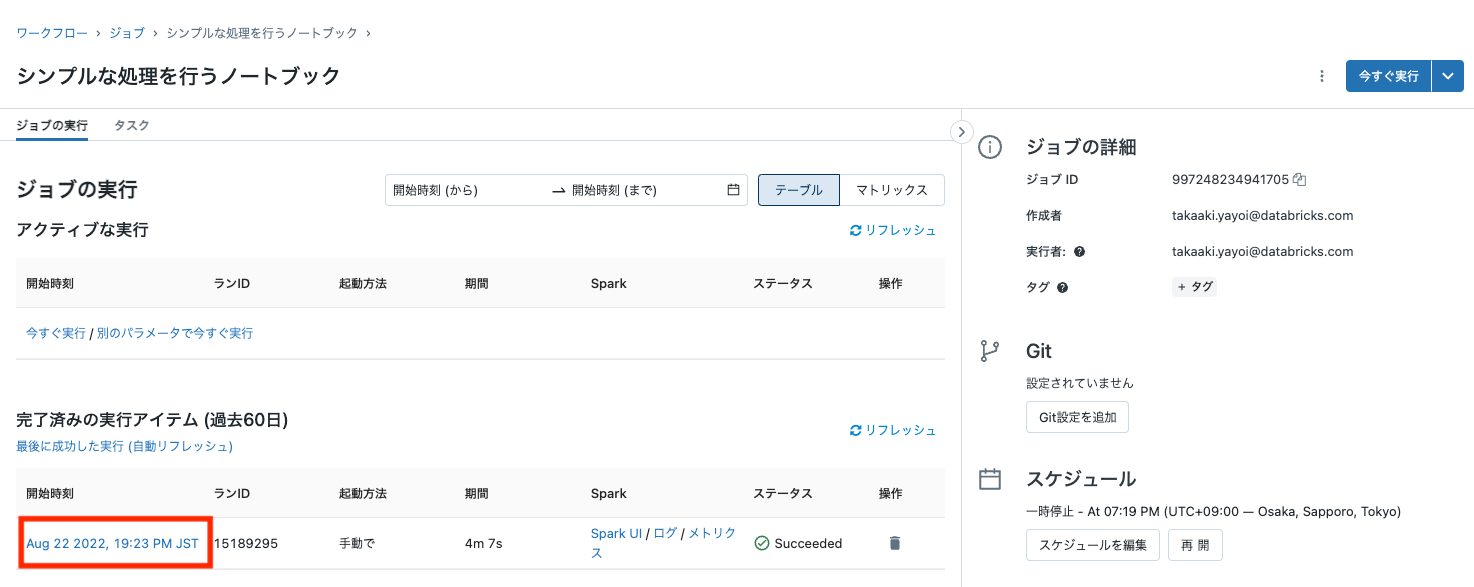
- ジョブの結果が**Succeeded**になったことを確認したら**開始時刻**のリンクをクリックして結果にアクセスしてください。
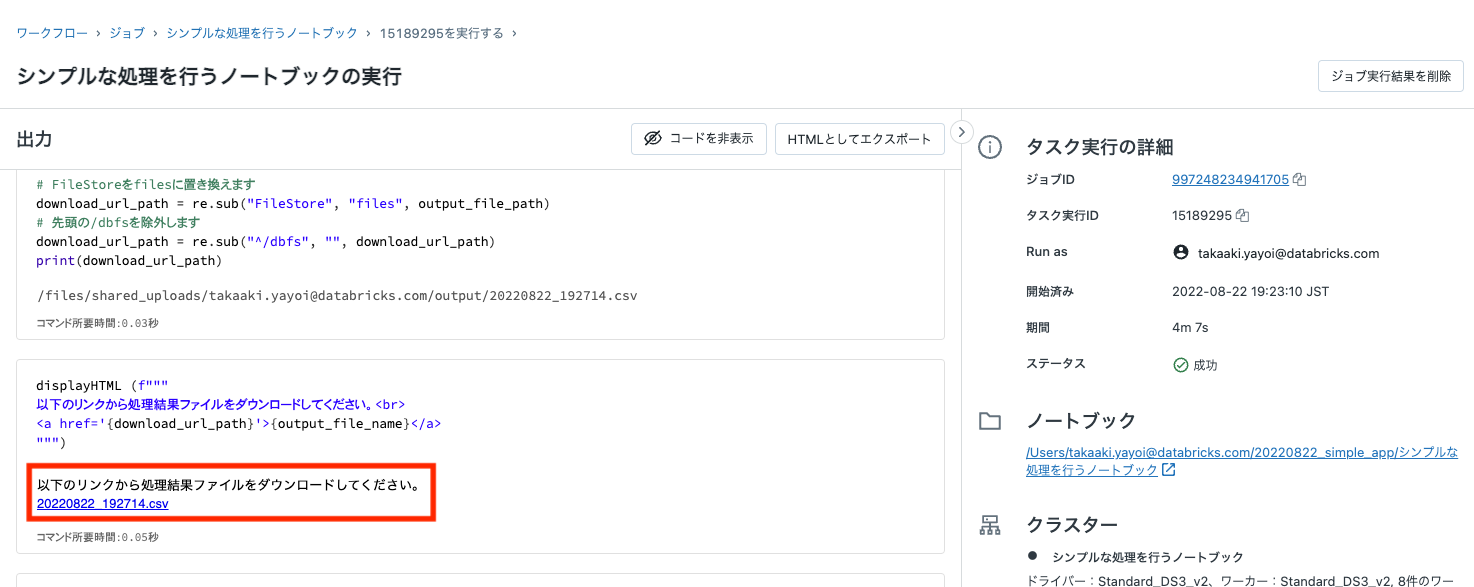
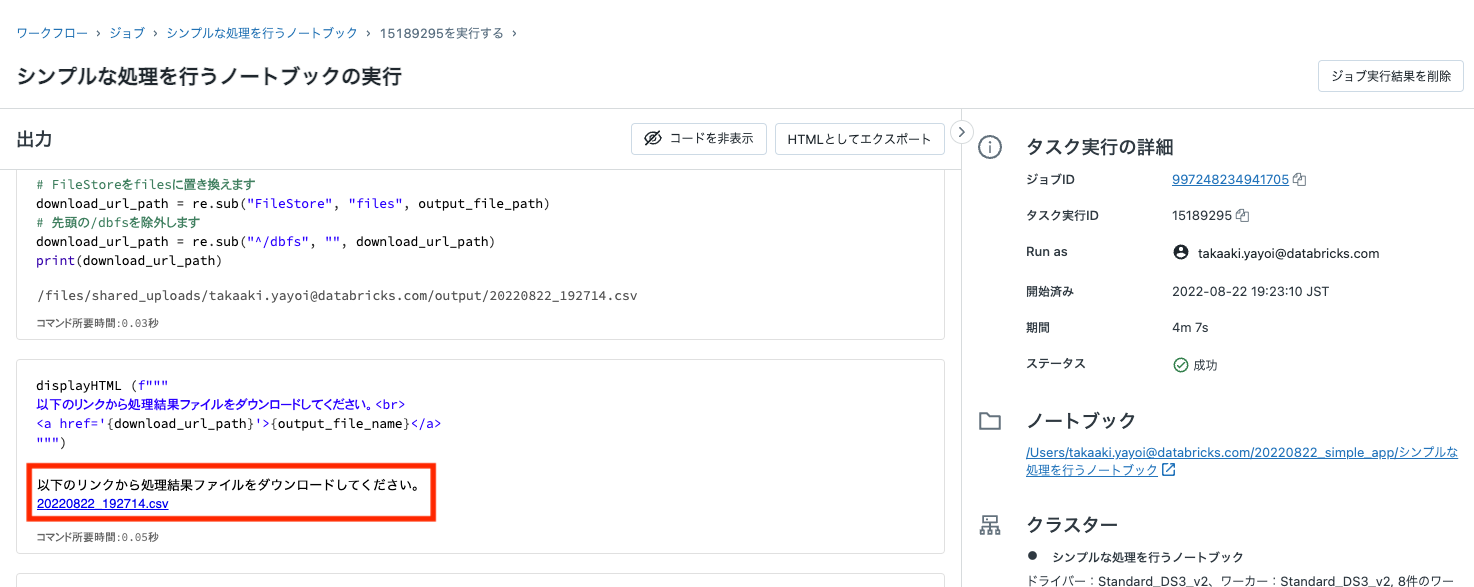
- ノートブックの末尾に表示されているリンクをクリックしてCSVファイルをダウンロードしてください。
レンダリングすると以下のようになります。以下のリンクはダミーです。URLを適宜変更してください。
- こちらのリンクをクリックし、ジョブを開いてください。
-
今すぐ実行をクリックしてください。
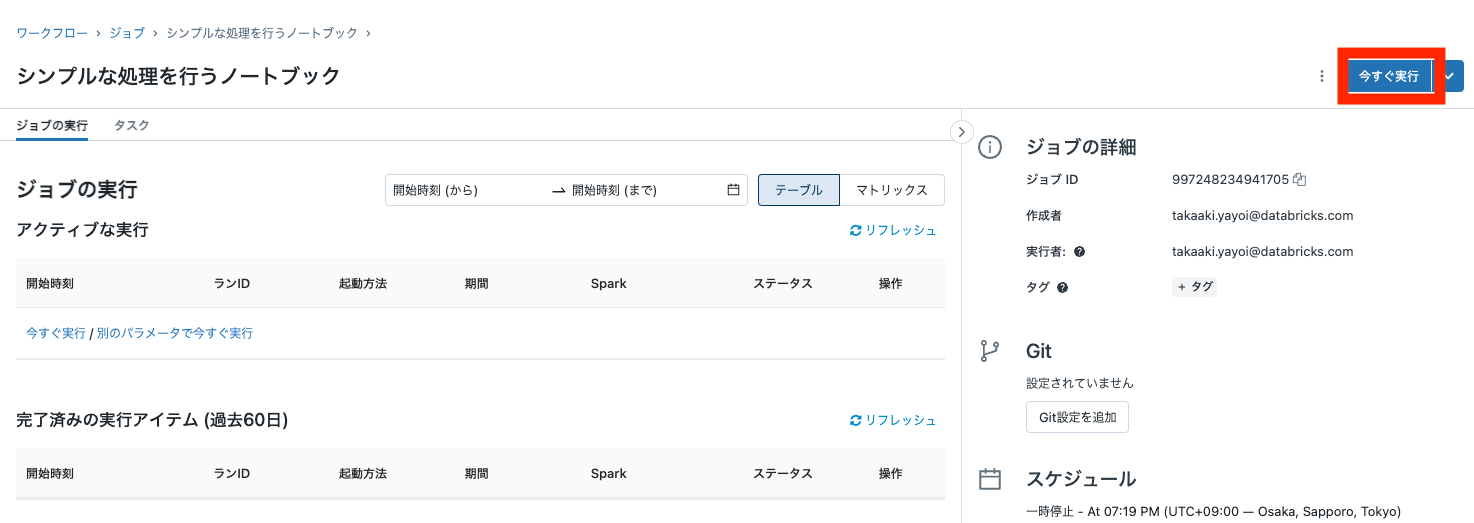
- ジョブの結果がSucceededになったことを確認したら開始時刻のリンクをクリックして結果にアクセスしてください。
- ノートブックの末尾に表示されているリンクをクリックしてCSVファイルをダウンロードしてください。
ジョブの実行(ユーザー部門)
- 上の手順に沿ってジョブを実行します。
- ノートブック末尾に表示されるリンクをクリックしてCSVファイルをダウンロードします。
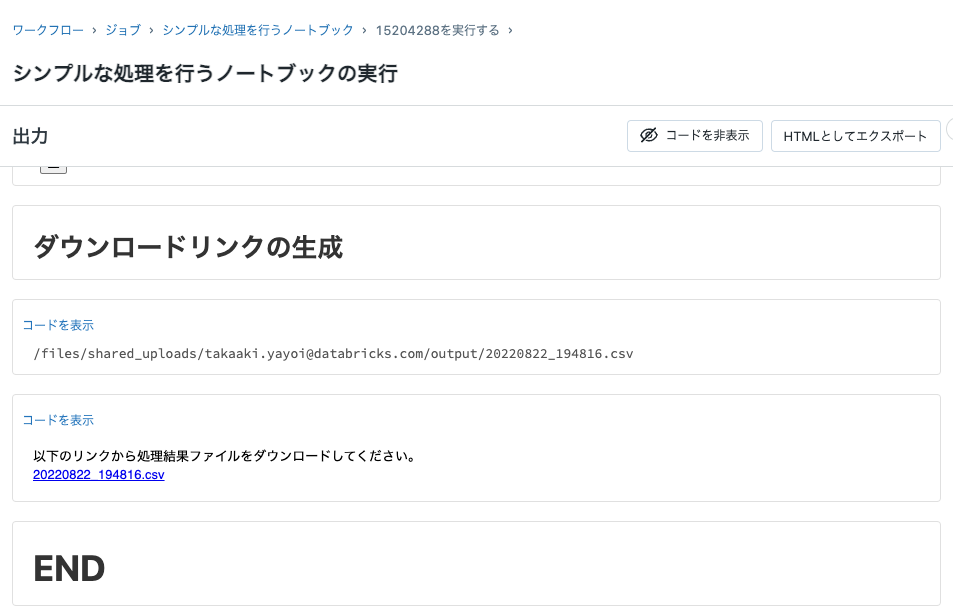
- CSVを開くと処理が行われていることを確認できます。
