インクリメンタル(incremental)なデータの取り込みとは、データの増分のみを取り込むことを意味します。
その際にはAuto Loaderがおすすめです。オブジェクトストレージに新規データが到着すると、その新規データのみに対する処理を実行することができます。
ここでは、ダミーデータを使ってAuto Loaderを用いて増分のみを処理する様子をデモします。
データの保存
想定シナリオとしては、7/6から7/8にかけてデータが日次でS3に書き込まれるものとします。まずは、ダミーデータを準備します。
data_07_06 = [{"Date": "2023/07/06", "Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Date": "2023/07/06", "Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Date": "2023/07/06", "Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Date": "2023/07/06", "Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
df_07_06 = spark.createDataFrame(data_07_06)
display(df_07_06)
data_07_07 = [{"Date": "2023/07/07", "Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Date": "2023/07/07", "Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Date": "2023/07/07", "Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Date": "2023/07/07", "Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
df_07_07 = spark.createDataFrame(data_07_07)
display(df_07_07)
data_07_08 = [{"Date": "2023/07/08", "Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Date": "2023/07/08", "Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Date": "2023/07/08", "Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Date": "2023/07/08", "Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
df_07_08 = spark.createDataFrame(data_07_08)
display(df_07_08)

そして、これらのデータはS3に年/月/日というふうに切られたパスに格納されるものとします。7/7時点という想定で、最初の2つのデータのみを書き込みます。
save_path = "s3://taka-external-location-bucket/landing-zone/load_test/2023/07/06/"
df_07_06.write.format("parquet").option("header", "true").mode("overwrite").save(save_path)
save_path = "s3://taka-external-location-bucket/landing-zone/load_test/2023/07/07/"
df_07_07.write.format("parquet").option("header", "true").mode("overwrite").save(save_path)
SQLコマンドのLISTを使うとクイックにパスを確認できます。
%sql
LIST "s3://taka-external-location-bucket/landing-zone/load_test/2023/07/"

データの取り込み
ここでいくつか注意点を:
- Auto Loaderは
cloudFilesという構造化ストリーミングソースを提供します。これは、後段の処理がストリーミング処理でなくてはならないことを意味します。 - ストリーミング処理では、連続的に到着するデータを処理し続けるので、障害時に復旧する目的などで、どこまで処理をしたのかを記録しておく必要があります。この役目を担うのがチェックポイントです。チェックポイントに処理の進捗が書き込まれます。
- ストリーミング処理と言いましたが、これらの機能をバッチ処理で使用することができます。これによって、処理の進捗を自動で管理してくれるので、バッチ処理自体もシンプルになります。この仕組みを活用するには
Trigger.AvailableNowを使用します。詳細はこちらをご覧ください。
既存データのロード
-
cloudFilesを用いて、インクリメンタルにデータをロードするのでreadStreamを用いてストリーム処理を行います。 -
recursiveFileLookupオプションを指定して、ディレクトリを再帰的にスキャンします。
# 関数のインポート
from pyspark.sql.functions import input_file_name, current_timestamp
# チェックポイントのパス
checkpoint_path = f"/tmp/takaaki.yayoi@databricks.com/_checkpoint/etl_quickstart"
# ソースパス
all_data_path = "s3://taka-external-location-bucket/landing-zone/load_test/"
# 書き込み先テーブル
table_name = "main.default.incremental_load"
(spark.readStream # ストリーミング読み込み
.format("cloudFiles") # Auto Loader
.option("cloudFiles.format", "parquet") # Parquetの読み込み
.option("cloudFiles.schemaLocation", checkpoint_path) # チェックポイントのパスにスキーマも保存
.load(all_data_path) # 読み込みソースの指定
.select("*", current_timestamp().alias("processing_time")) # 処理時刻の列を追加
.writeStream # ストリーミング書き込み
.option("checkpointLocation", checkpoint_path) # チェックポイントのパス
.trigger(availableNow=True) # AvailableNowトリガー
.toTable(table_name)) # テーブルへの書き込み
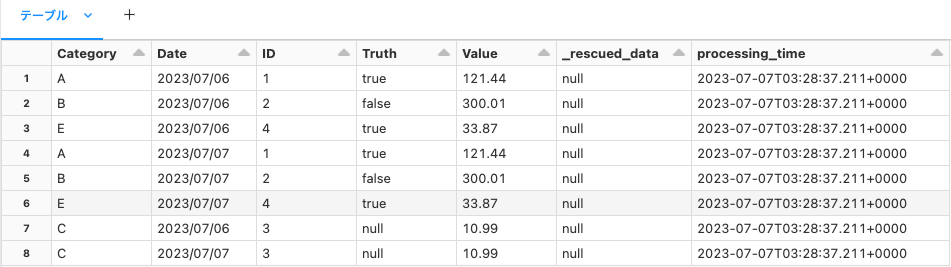
テーブルを確認すると、2日分のデータが書き込まれていることが分かります。
%sql
SELECT * FROM main.default.incremental_load;
新規データの追加
7/8のデータが到着したものとします。
save_path = "s3://taka-external-location-bucket/landing-zone/load_test/2023/07/08/"
df_07_08.write.format("parquet").option("header", "true").mode("overwrite").save(save_path)
%sql
LIST "s3://taka-external-location-bucket/landing-zone/load_test/2023/07/"

新規データのみを処理
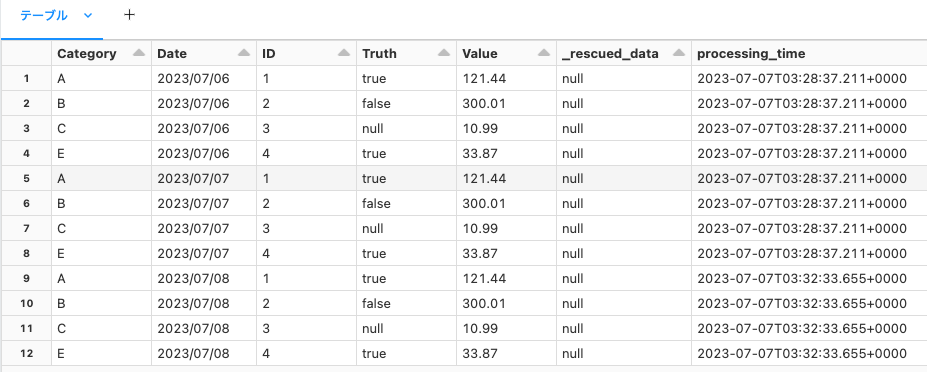
チェックポイントに処理の進捗は格納されているので、再度処理を実行しても新規データのみが処理され、データの重複は起きません。
# 関数のインポート
from pyspark.sql.functions import input_file_name, current_timestamp
# チェックポイントのパス
checkpoint_path = f"/tmp/takaaki.yayoi@databricks.com/_checkpoint/etl_quickstart"
# ソースパス
all_data_path = "s3://taka-external-location-bucket/landing-zone/load_test/"
# 書き込み先テーブル
table_name = "main.default.incremental_load"
(spark.readStream # ストリーミング読み込み
.format("cloudFiles") # Auto Loader
.option("cloudFiles.format", "parquet") # Parquetの読み込み
.option("cloudFiles.schemaLocation", checkpoint_path) # チェックポイントのパスにスキーマも保存
.load(all_data_path) # 読み込みソースの指定
.select("*", current_timestamp().alias("processing_time")) # 処理時刻の列を追加
.writeStream # ストリーミング書き込み
.option("checkpointLocation", checkpoint_path) # チェックポイントのパス
.trigger(availableNow=True) # AvailableNowトリガー
.toTable(table_name)) # テーブルへの書き込み
%sql
SELECT * FROM main.default.incremental_load ORDER BY Date ASC, Category ASC;
今回はTrigger.AvailableNowを用いて、バッチ的に処理をしましたが、純然たる連続処理のストリーミング処理として実行することも可能です。そもそも、デフォルトの挙動は連続実行です。こちらにあるように、一定周期で処理を行うようにすることで、ストレージに新規データが書き込まれるや否や後段の処理が実行され、増分のみがテーブルに書き込まれ続けるデータパイプラインを構築、実行することができます。
外部システムから定期的にデータが到着して、それらを処理して取り込むというのは一般的なユースケースだと思います。上述した仕組みを使うことで、外部システムとの連携も疎結合にできますし、受け取った後の処理は自動で行われ、さらには、Sparkの柔軟かつ高パフォーマンスなデータ処理能力を活用できるこのパターンは、合理性があるものだと私は思います。是非お試しください!