Continued Best Practices for Using Structured Streaming in Production - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
「プロダクションにおけるストリーミング: ベストプラクティスコレクション」と題した2パートからなるブログシリーズにおいて、これが2番目の記事となります。ここで我々は構造化ストリーミングパイプラインにおける「デプロイメント後」の検討事項を議論します。この記事で提案している内容の大部分は、構造化ストリーミングのジョブとDelta Live Tables(バッチとストリーミングパイプラインの両方をサポートする我々のフラッグシップかつ完全マネージドのETL製品)の両方に適用できます。
以前の「デプロイメント前」の問題は、プロダクションにおけるSparkストリーミング: ベストプラクティスコレクションPart 1でカバーしていますので、まだお読みで無い場合には最初にお読みいただくことをお勧めします。
ストリーミングパイプラインやストリーミングアプリケーションをプロダクションに移行し始める前に、全てのセクションを読んでいただき、開発からQA、最終的なプロダクションにプロモーションする際に再度読むことをお勧めします。
デプロイメント後
お使いのストリーミングアプリケーションをデプロイした後は、通常以下の3点を知りたいと考えるでしょう:
- 私のアプリケーションはどのように稼働している?
- リソースは効果的に活用されているのか?
- 発生する問題にどのように対応すべきか?
これらのトピックのイントロダクションからスタートし、このブログシリーズの後半でディープダイブします。
モニタリングと計測(私のアプリケーションはどのように稼働している?)
ストリーミングのワークロードはプロダクションにデプロイしたら、非常に手離れの良いものであるべきです。しかし、時々気になるのは「私のアプリケーションはどのように稼働している?」ということです。アプリケーションのモニタリングは以下の点に応じて異なるレベルで実行されることになります:
- お使いのアプリケーションで収集されるメトリクス(バッチの処理時間/レーテンシー/スループットなど)
- どこからアプリケーションをモニタリングしたいのか
最もシンプルなレベルでは、様々なシチュエーションで活用できるSpark UIに直接ビルトインされているストリーミングダッシュボード(新しい構造化ストリーミングUI)があります。ストリーミングワークロードを実行するジョブの失敗時にアラートを発生させることもできます。より詳細なメトリクスが必要、あるいは、お使いのコードベースの一部としてこれらのメトリクスに基づくカスタムアクションを作成したい場合には、StreamingQueryListenerがあなたが探しているものに適しています。(ドライバーやワーカーのマシンレベルのトレースを含む)Sparkのメトリクスをレポートさせたいのであれば、プラットフォームのメトリクスシンクを使うべきです。
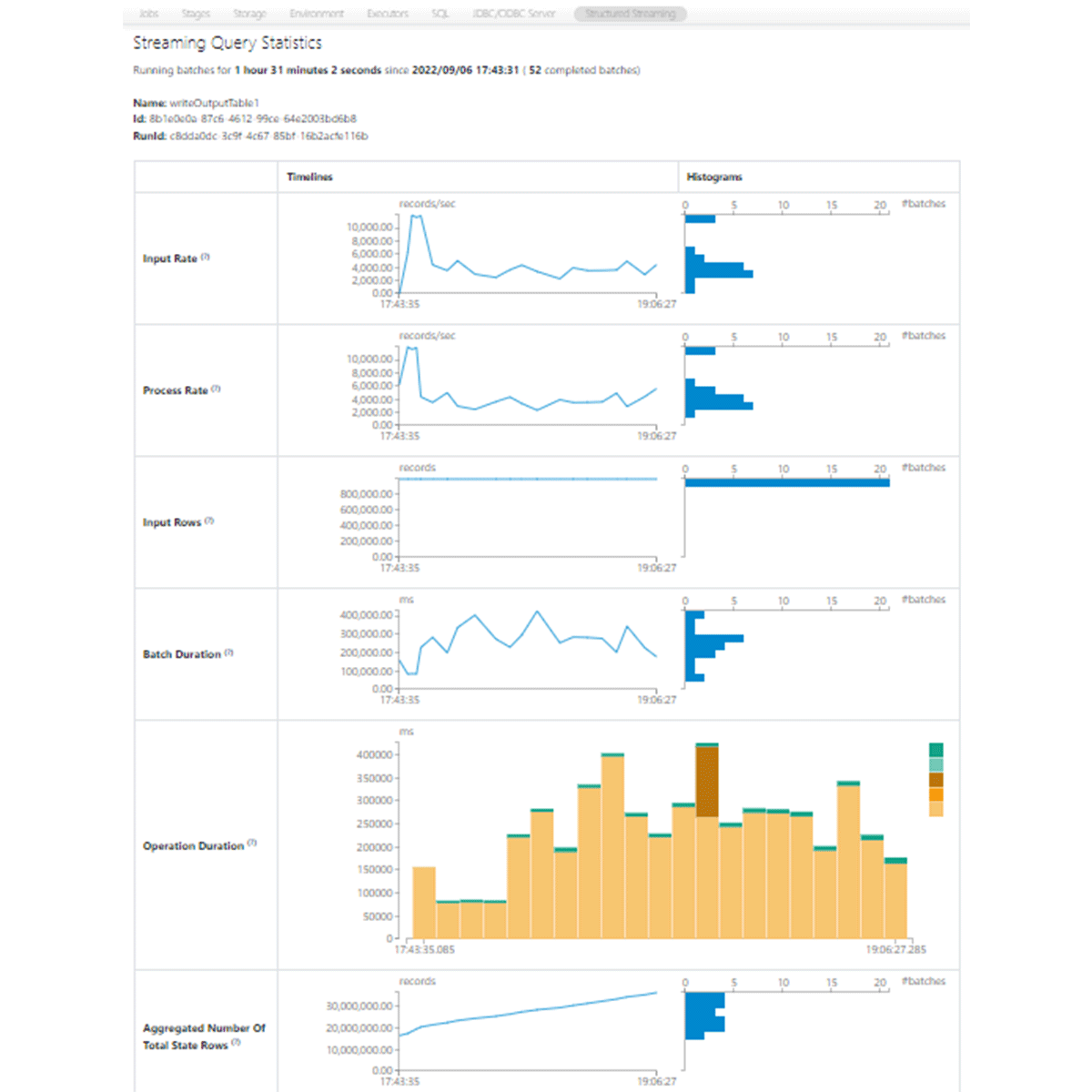
Apache Sparkの構造化ストリーミングUI
検討すべきもう一つの事柄は、観測のためにこれらのメトリクスをどこに表示させたいのかということです。クラスターレベルでのGangliaダッシュボード、ストリーミングワークロードのモニタリングのためのDatadogのようなパートナーアプリケーションのインテグレーション、PrometheusやGrafanaのようなツールを用いたよりオープンソースなオプションがあります。それぞれには、コスト、パフォーマンス、メンテナンス要件に関する利点、欠点があります。
UIによるインタラクションで十分な低ボリュームのストリーミングワークロードを使用していようが、より堅牢なモニタリングプラットフォームに投資することを決断しようが、皆様のプロダクションストリーミングワークロードの観測方法を理解する必要があります。このシリーズで今後ポストされる「モニタリングとアラート」では、より詳細な議論が含まれることになります。特に、ストリーミングアプリケーションをモニタリングするための様々な計測方法や観測性を活用するためのいくつかのツールを詳細に見ていきます。
アプリケーションの最適化(リソースは効果的に活用されているのか?「コスト」を考えましょう)
プロダクションへのデプロイ後に生じる次の懸念事項は「自分のアプリケーションはリソースを効果的に活用しているのか?」ということです。開発者として、我々は作業中のコードと適切に記述されたコードの違いを理解しています(あるいはすぐに学びます)。コードの実行形態を改善することは非常に楽しいものですが、最終的に問題になるのは全体的な実行コストです。構造化ストリーミングアプリケーションにおけるコストの検討は、他のSparkアプリケーションと概ね同じようなものとなります。特筆すべき違いは、これらのワークロードは多くの場合「常時稼働」のアプリケーションなので、プロダクションワークロードの最適化に失敗すると、非常に高コストになり、無駄な出費がすぐに累積していくという点です。コスト最適化の支援は頻繁にリクエストされるので、これに関する別の記事をポストする予定です。フォーカスするキーポイントは使用の効率性とサイジングです。
クラスターサイズを適切に設定することは、ストリーミングアプリケーションにおいて効率性と無駄の違いを生み出す最も重要な違いとなります。時にはプロダクションにおけるアプリケーションの完全な負荷条件をデプロイする前に推定することが困難であるため、これは特にトリッキーになります。別のケースでは、日、週、月を通じて取り扱われるボリュームの変動性によって困難となる場合があります。最初にデプロイする際は、パフォーマンスのボトルネックを避けるために追加の費用を投じて若干サイズを大きめにすることをお勧めします。適切なクラスター使用率を確認するために数週間クラスターが稼働した後に、お使いのモニタリングを活用してください。例えば、負荷のピークの際にCPUやメモリーの使用率は高いレベルにあるのか、あるいは、定常的に負荷が低くてクラスターのサイズを引き下げて良いのか?これに対する定期的なモニタリングを継続し、データボリュームの時系列変化を注視します。いずれかが発生している場合、コスト効率の高いオペレーションを維持するためにクラスターのサイズ変更が必要になるかもしれません。
一般的なガイドラインとして、過度なシャッフルオペレーションやjoin、極端なウォーターマークの閾値(ご自身の要件を超えないでください)はアプリケーションを実行するために必要なリソースを増加させるので、これらを避けるべきです。大きなウォーターマークの閾値は、構造化ストリーミングにバッチ間の状態ストアに多くのデータを保持させることになり、クラスターのメモリー要件を引き上げることになります。また、設定するVMのタイプにも注意してください - メモリーを大量に必要とするストリームにメモリー最適化VMを使っていますか?計算が膨大に発生するストリームに計算最適化VMを使っていますか?そうで無い場合には、それぞれの使用率を確認し、より適したマシンタイプを試すことを検討してください。クラウドプロバイダーから提供される新たなサーバーファミリーでは、より最適化されたCPUが搭載されており、多くの場合において処理実行の高速化につながり、これはSLAを達成するために少ない台数で済むことを意味します。
トラブルシューティング(発生する問題にどのように対応すべきか?)
デプロイメント後に持つ最後の質問は「発生する問題にどのように対応すべきか?」ということです。コスト最適化と同じように、Sparkにおけるストリーミングアプリケーションのトラブルシュートは内部の機構はほとんど変わらないので、他のSparkアプリケーションと多く変わりません。ストリーミングアプリケーションにおいては、問題は通常、障害シナリオとレーテンシーシナリオという2つのカテゴリーに属することになります。
障害シナリオ
障害シナリオには通常、エラーによるストリームの停止、エグゼキューターの障害、クラスター全体を停止されるドライバー障害が含まれます。これらの共通する原因は:
- 同じクラスターで大量のストリームを実行し、ドライバーのリソースを枯渇させる。Databricksにおいては、クラスターが停止する前にドライバーのオーバーロード状態をGangliaでこの状況を確認することができます。
- クラスターのワーカー数が少ない、あるいはコア数、メモリーに関するワーカーサイズが小さく、アウトオブメモリーエラーを引き起こしてエグゼキューターが停止する。これも、エグゼキューターが停止する前に、GangliaあるいはエグゼキュータータブのSpark UIでこの状況を確認することができます。
-
collectを用いて大量のデータをドライバーに送信し、アウトオブメモリーエラーで停止。
レーテンシーシナリオ
レーテンシーシナリオでは、ストリームが期待するほどに高速に処理を行わないことになります。レーテンシーの問題は断続的あるいは継続的なものとなり得ます。大量のストリームや小さすぎるクラスターも原因となり得ます。その他の一般的な原因は:
- データの偏り - いくつかのタスクが他のタスクよりも大量のデータを持つことになった際に発生します。偏りのあるデータによって、これらのタスクは他のタスクよりも処理に時間をようすることになり、ディスクへの溢れを引き起こします。ストリーム全体の処理速度は最も遅いタスクの速度となります。
- ウォーターマークを定義しない、あるいは非常に長いウォーターマークでステートフルなクエリーを実行し、ステートが非常に大きくなり、時間と共にストリームは遅くなり、場合によっては障害を引き起こします。
- 最適化が不十分なシンク。例えば、ストリームの一部としてパーティショニングしすぎたDeltaテーブルへのマージの実行。
- 安定しているが高いレーテンシー(バッチ実行時間)。原因によっては、Sparkで同時に利用できるコア数を増やすために、ワーカーを追加することで解決できる場合があります。入力パーティションの数の増加や、バッチサイズ設定によるコアあたりの負荷を削減することでレーテンシーを削減することができます。
バッチジョブのトラブルシュートと同様、クラスターの使用率をチェックするためにGangliaや、パフォーマンスボトルネックを特定するためにSpak UIを活用します。ストリーミングアプリケーションをモニタリング、トラブルシュートするために開発されたSpark UIの構造化ストリーミングタブがあります。このタブでは実行中のストリームが一覧され、ストリームに名前をつけているのであればその名前、そうで無い場合には<no name>が表示されます。また、Spark UIのJobsタブではストリームIDを確認できるので、特定ストリームの複数ジョブ(Jobs)がどれかを確認することができます。
上で、特定ストリームに対するJobsと述べたことに気づいたかもしれません。Spark UIでストリーミングアプリケーションを参照した際、継続的に1つのジョブがJobsタブに表示されると考えることはよくある誤解です。そうではなく、お使いのコードに応じてマイクロバッチごとに複数のジョブがスタート、完了することを目の当たりにすることになります。それぞれのジョブには構造化ストリーミングタブで確認できるストリームIDがあり、説明にはマイクロバッチの番号が含まれるので、どのジョブがどのストリームで実行されているのかを確認することができます。最も処理に時間を要しているステージやタスク、ディスク溢れを起こしているタスクを特定するためにこれらのジョブをクリックすることができ、最も遅いクエリーを特定し、実行計画をチェックするためにSQLタブでジョブIDを用いて検索を行うことができます。
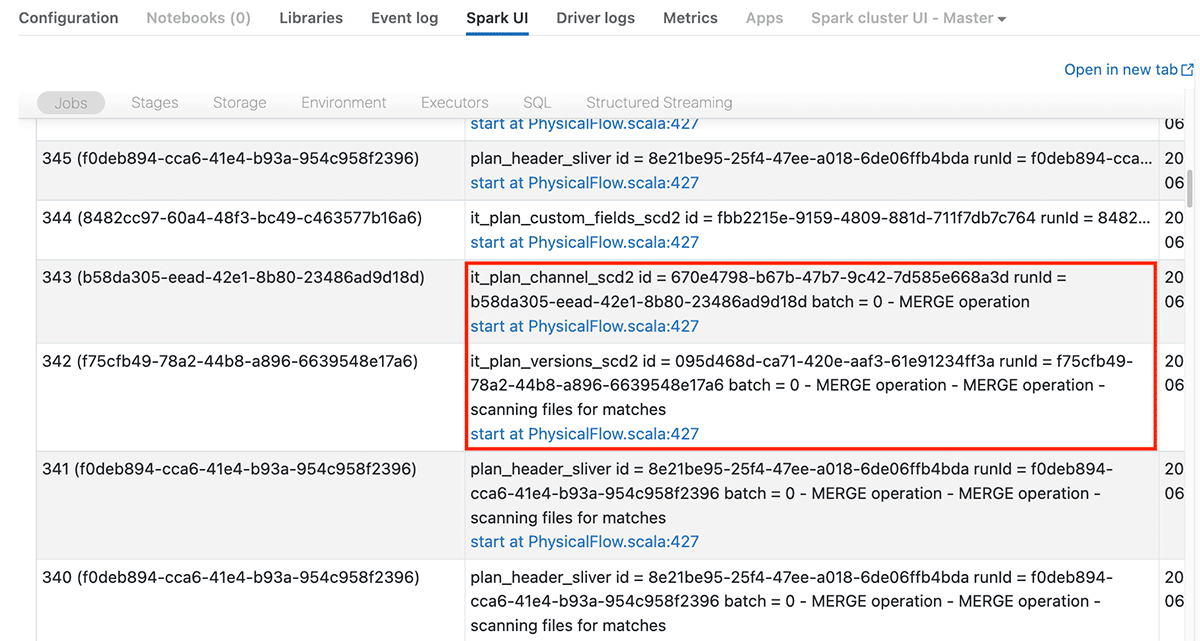
Apache Spark UIにおけるJobsタブ
構造化ストリーミングタブでストリームをクリックすると、バッチの追加、クエリーの計画、コミットのようなマイクロバッチごとに実行されている異なるストリーミングオペレーションでどれだけ時間を要しているのかを確認することができます(上のApache Spark構造化ストリーミングUIのスクリーンショットをご覧ください)。また、何行が処理されたのか、ステートフルストリームにおける状態ストアのサイズを確認することができます。これによって、潜在的なレーテンシーの問題がどこにあるのかに関する洞察を得ることができます。
このブログシリーズの後半ではトラブルシューティングによりディープダイブし、ここでは上で概要を説明した障害シナリオとレーテンシーの両方の原因の対策のいくつかを見ていきます。
まとめ
ここでカバーされたトピックの多くが、他のプロダクションSparkアプリケーションをデプロイする際の方法と類似していることに気づいたかもしれません。ワークロードがストリーミングアプリケーションであろうがバッチ処理であろうが、同じ原則の大部分を適用することができます。ストリーミングアプリケーションを構築する際に特に重要になることにフォーカスしましたが、すでに皆様も気づいているように、ここで議論したトピックは、ほとんどのプロダクションデプロイメントに含まれるものです。
現在の世界中の大部分の業界において、これまで以上に最新の情報が必要とされていますが、これはあなたにとって問題とはなりません。Sparkの構造化ストリーミングを用いることで、大規模なプロダクション環境でこれを実現することができます。この記事でカバーしたトピックのディープダイブを楽しみにしていてください。そして当面はストリーミングし続けてください!
Production considerations for Structured Streamingを読む。