本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
個人向けバンキングにおけるデジタルトランスフォーメーションを加速させるプラットフォームとしての金融サービス向けレイクハウス
まさに、NetflixやTeslaがメディア、自動車業界を破壊したように、多くのフィンテック企業は、パーソナライズされたサービス、よりセキュリティに優れた数えきれないクレジットカード、シームレスなオムニチャネル体験を通じて、デジタルネイティブの人々の心を掴み取ることで、金融業界を変革しています。8年目のスタートアップが南アメリカで最も価値のある銀行になったというNuBankのサクセスストーリーは特別なものではありません。280以上の他のフィンテックユニコーンもまた、ペイメント業界全体を破壊しようとしています。Financial Conduct Authority (FCA)の研究では、 「イノベーション、デジタル化、顧客行動の変容を通じて、大銀行の歴史的な優位性が失われつつある」 といったことが述べられています。破壊するか、破壊されるかの選択に直面し、JP Morgan Chaseのような多くの従来型の金融サービス機関(FSI)は、データ、人工知能(AI)を用いてフィンテック企業と彼ら自身の土俵であるクラウドで戦うための戦略的投資を発表しました。
最新のパーソナライゼーションを行うのに必要となるデータ量、実験段階(POC)から企業規模のデータパイプラインにおけるAIのオペレーションの複雑性、クラウドインフラストラクチャ上での顧客データ取り扱いにおける厳密なデータ、プライバシー規制から、多くの破壊者、スタートアップがデジタルトランスフォーメーションを加速し、数百万の顧客にパーソナライズされた洞察と、強化された銀行体験を提供するための戦略的プラットフォームとして金融サービス向けレイクハウスが急速に活用されるようになりました(HSBCがどのようにAIを用いてモバイルバンキングを再発明したのかをご覧ください)。
前回のソリューションアクセラレータでは、クレジットカードのトランザクションからブランド、マーチャントをどのように特定するのかをお見せしました。我々の新たなソリューションアクセラレータでは、顧客な完全な像を捕捉し、従来のデモグラフィック情報、収入、製品・サービス(あなたが誰なのか)の先に行き、トランザクションの挙動や購買の嗜好(どのように銀行を利用するのか)にまで拡張する、モダンかつ高度なパーソナライゼーションデータアセット戦略を実現するためにこの成果を活用しました。データアセットとしては同じものが、オンラインバンキングアプリケーションにおけるロイヤリティプログラム、コアの銀行プラットフォームにおける不正検知、「後払い(BNPL)」におけるクレジットリスクのような多くの下流のユースケースでも適用することができます。
トランザクションの文脈
あらゆるセグメンテーションのユースケースに対する一般的なアプローチは、シンプルなクラスタリングモデルですが、すぐに使える技術は多くありません。あるいは、オリジナルアーキタイプからデータを変換することで、より広範囲の技術を活用できますが、多くの場合予期しない結果をもたらします。このソリューションアクセラレータでは、元のクレジットカードトランザクションデータをグラフパラダイムに変換し、元々は自然言語処理(NLP)向けにデザインされた技術を活用します。
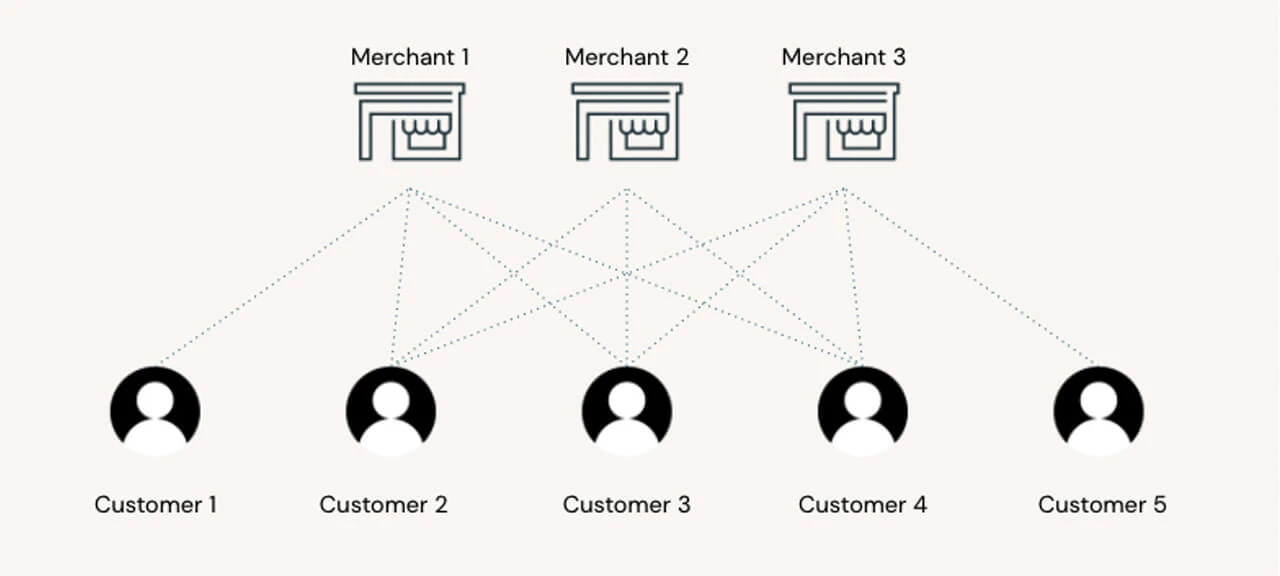
単語の意味が周辺の文脈で定義されるNLP技術と同様に、マーチャントの顧客ベースと、顧客がサポートする他のブランドからマーチャントのカテゴリーを学習することができます。この文脈を構築するために、顧客があるお店から他のお店に訪れる様子をグラフ構造を上下させることでシミュレーションすることで「買い物の移動」を生成します。ここでの狙いは、我々のネットワーク上の顧客が伝達する文脈情報の数学表現である「エンベディング」を学習することです。この例では、近しい2つのマーチャントが、数学的に近しい大きなベクトルに埋め込まれます。さらにこれを拡張し、同様の購買行動を示す2人の顧客は数学的に近しいものとなり、より進んだ顧客セグメンテーション戦略への道を拓きます。
マーチャントのエンベディング
Word2Vecは、エンべディングのニューラルネットワークのトレーニングをより効率的にするためにGoogleのTomas Mikolovらによって開発され、それ以来、事前学習済み単語エンべディングアルゴリズムの開発におけるデファクトスタンダードとなっています。我々のソリューションにおいては、事前に定義した「買い物の移動」をトレーニングするために、Apache Spark™ ML APIに含まれているデフォルトのwordVecモデルを使用します。
from pyspark.ml.feature import Word2Vec
with mlflow.start_run(run_name='shopping_trips') as run:
word2Vec_model = Word2Vec() \
.setVectorSize(255) \
.setWindowSize(3) \
.setMinCount(5) \
.setInputCol('walks') \
.setOutputCol(vectors) \
.fit(shopping_trips)
mlflow.spark.log_model(word2Vec_model, "model")
我々のアプローチをクイックに検証するための最も分かりやすい方法は、結果を見てドメイン知識を当てはめるというものです。“Paul Smith”のようなブランドの例では、我々のモデルはPaul Smithに近い競合他社である“Hugo Boss”、“Ralph Lauren”、“Tommy Hilfiger”などを見つけ出しています。
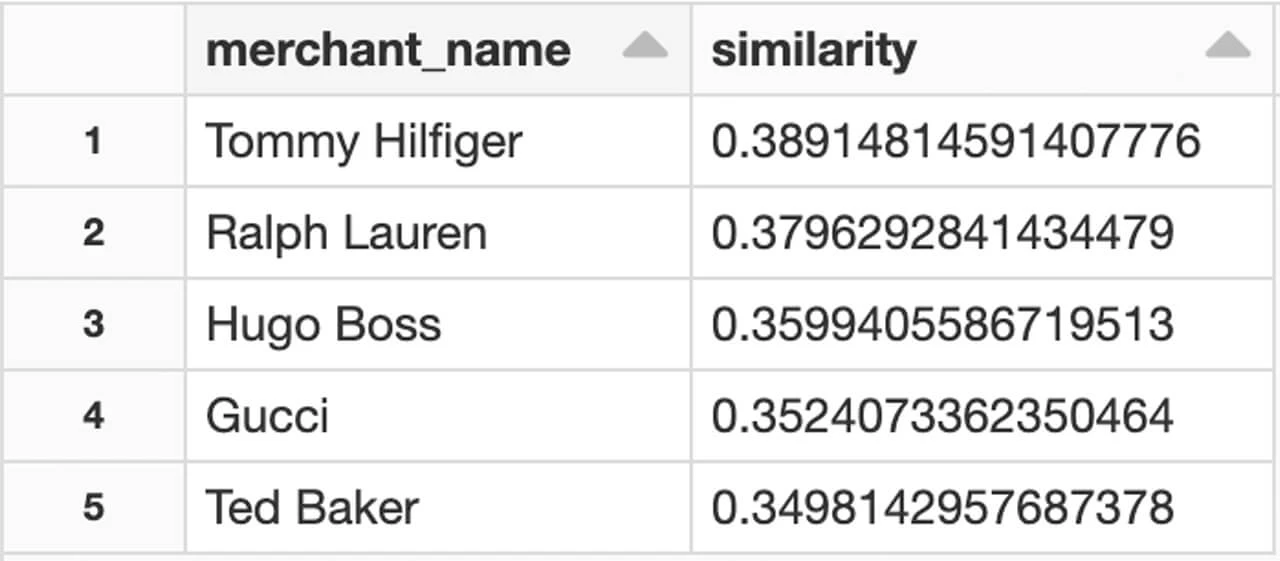
我々は単に同じカテゴリーのブランド(ファッション業界)を検知しただけではなく、同じ価格帯のブランドを検知しています。顧客の購買行動を用いることで、異なるラインオブビジネスを分類できるだけではなく、購入される商品の品質に基づいて、顧客セグメンテーションを行うことが可能となります。
マーチャントのクラスタリング
初期の結果は色々と問題があるものでしたが、多かれ少なかれ他よりも近しいマーチャントのグループが生成されました。これらのグループに対して更なる調査を行うことも可能です。これらの重要なマーチャント、ブランドのグループを見つけ出す最も簡単な方法は、埋め込まれたベクトル空間を3Dのプロットにするものです。このために、埋め込みベクトルを3次元に削減するために主成分分析(PCA)のような機械学習技術を適用します。
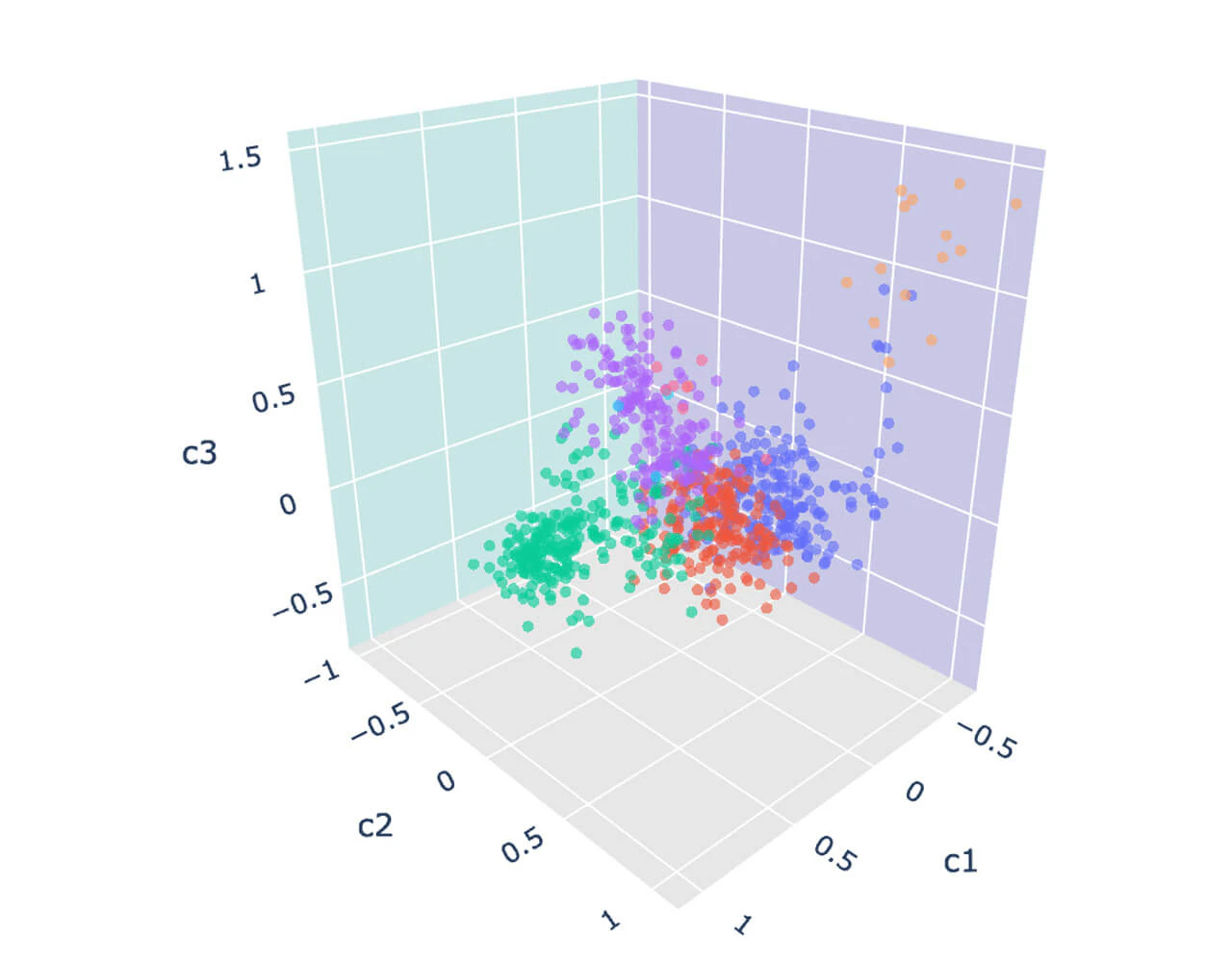
シンプルなプロットを用いることで、異なるマーチャントのグループを特定することができます。これらのマーチャントはことなるラインオブビジネスかもしれませんし、一見しただけでは違うように見えるかもしれませんが、これらはすべて共通するものがあります:似た顧客ベースを惹きつけているということです。クラスタリングモデル(KMeans)を通じてこの仮説をより確認することができます。
トランザクションのフィンガープリント
word2vecモデルの風変わりな特徴の一つに、高い予測値を保ちながらも大規模なベクトルを集約できるというものがあります。言い換えると、構成する単語のベクトルを平均化することで、ドキュメントの重要度を学習できるということです(Mikolovらによるホワイトペーパーをご覧ください)。同様に、顧客に好まれるブランドのそれぞれのベクトルを集計することで、顧客の購買嗜好を学習することができます。高級ブランド、ハイエンドの車、優良なお酒に対して同じような好みを持つ2人の顧客は理論上は近しいものとなり、同じセグメントに属することになります。
customer_merchants = transactions \
.groupBy('customer_id') \
.agg(F.collect_list('merchant_name').alias('walks'))
customer_embeddings = word2Vec_model.transform(customer_merchants)
このような集約ビューは、顧客それぞれに固有のトランザクションフィンガープリントを生成することを述べることには意義があります。2つのフィンガープリントは類似した特性(同じ購買嗜好)を示すかもしれませんが、時間経過に伴う個々の顧客固有の振る舞いを追跡するために、これらの固有のシグネチャを活用することができます。
前回観測した時からシグネチャが劇的に異なる場合(例:突然ギャンブル関連企業に興味を持った)、不正行為のサインかもしれません。時間経過に伴いシグネチャがドリフトする場合、ライフイベント(子供が産まれた)を示しているのかもしれません。このアプローチは、リテールバンキングにおけるハイパーパーソナライゼーションのキーとなるものです。リアルタイムデータに対して顧客の嗜好を追跡できる能力は、ポジティブなものであれネガティブなものであれ様々なライフイベントに対して、銀行がプッシュ通知などのパーソナライズされたマーケティング、オファリングを行うのに役立ちます。

顧客セグメンテーション
顧客行動分析に対して素晴らしい予測値を提供するいくつかのシグナルを生成することができましたが、まだ実際のセグメンテーション問題に取り組んでいません。セグメンテーション、解約防止、顧客生涯価値を含むカスタマー360ユースケースでは多くのケースで先進的な小売業から考え方を拝借し、小売向けレイクハウスの別のソリューションアクセラレータを使用して、最高クラスの小売企業で使用されている別のセグメンテーション技術をウォークスルーします。
小売業界のベストプラクティスに従い、異なる購買特性を示す異なる5つのグループに対して、顧客ベース全体をセグメント分けすることができました。
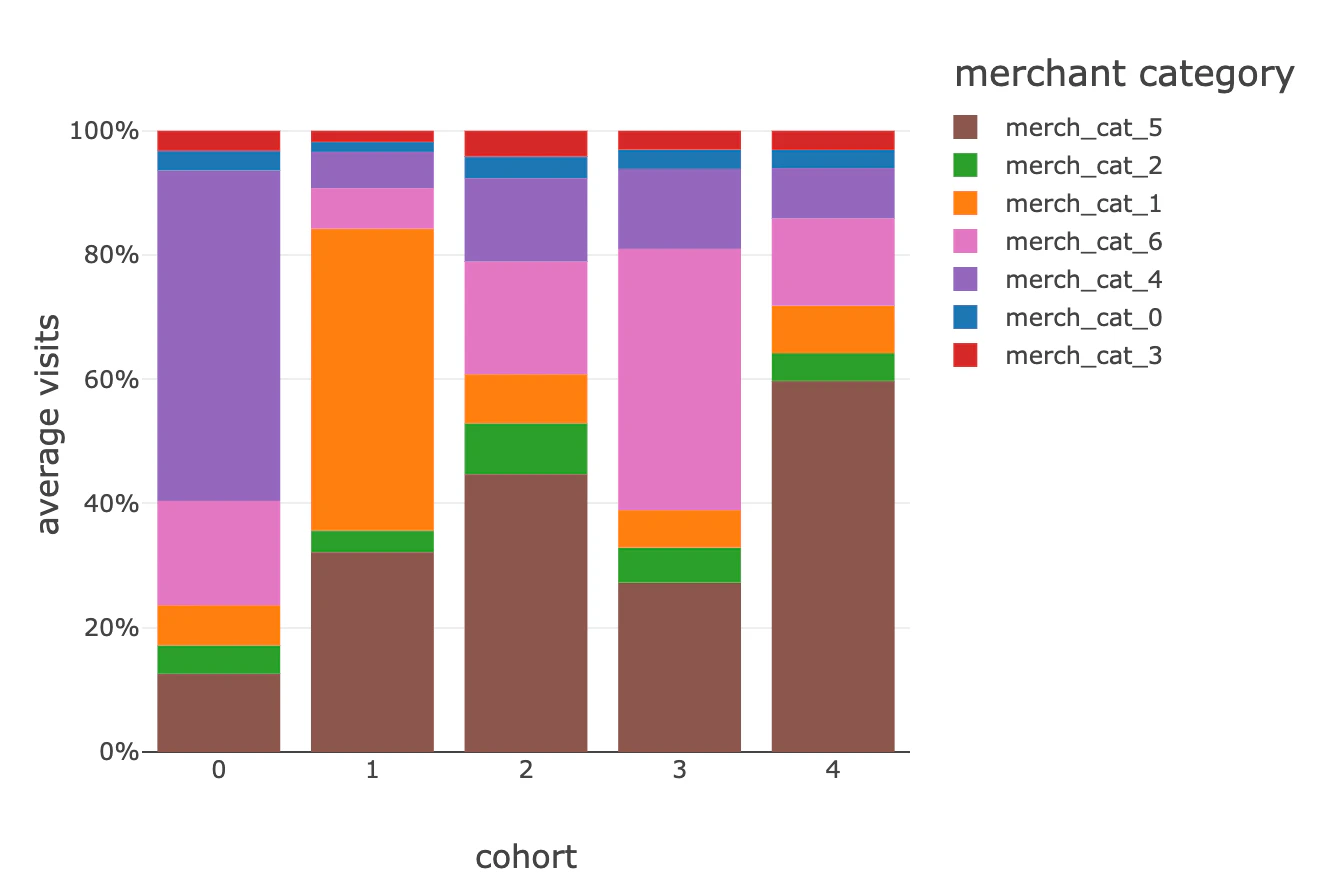
#0はギャンブルに対するバイアス(上のグラフにおけるmerchant category 4)が認められますが、他のグループはオンラインビジネスやサブスクリプションベースのサービス(merchant category 6)により集中しており、おそらく若年層の顧客を示しているのだと思います。読者の皆様に対しては、これらの行動ドリブンセグメント、そして、クレジットの意思決定、ネクストベストアクション、パーソナライズされたサービス、顧客満足、貸金回収、市場分析のインパクトをより理解するために、皆様がお客さまについて既に知っている追加のデータポイント(本来のセグメント、製品・サービス、平均収入、デモグラフィックなど)を用いて、このビューに対する補足をすることをお勧めします。
まとめ
このソリューションアクセラレータにおいては、我々はリテールバンキングおける顧客セグメンテーションに対して、うまくNLPの世界のコンセプトをカードのトランザクションに適用することができました。また、グラフ分析、行列計算、NLP、クラスタリング技術全てが、セキュアかつスケーラブルな一つのプラットフォームで組み合わせられる必要があるこの課題に取り組む際には、金融向けレイクハウスが適していることを示しました。SQLの世界を通じて容易に活用できる従来型のセグメンテーションと比較して、この破壊的かつ未来のセグメンテーションは、より完全な顧客の全体像を構築し、データ+AIを用いることでのみ大規模かつリアルタイムに実現することができます。
我々は、すぐに利用できるデータとモデルを用いて実現できることのほんの一部に触れたにすぎませんが、顧客の購買パターンが、でもグラフィックよりもより効果的にハイパーパーソナライゼーションを実現できることを証明し、クロスセル/アップセル、値付け/ターゲティング活動から顧客ロイヤリティ、不正検知戦略に至る新たな様々な機会への扉を開きました。
最も重要なことですが、この技術を用いることで、他の人からの情報を活用することで、クレジット履歴を知ることなしに、新規顧客や少数派の顧客を学習することができます。World Economic Forumによれば、世界中には銀行口座を持たない成人は17億人おり、Federal Reserveによれば、アメリカだけでも5500万人の人が銀行以外の金融サービスを利用しており、このようなアプローチを用いることで、リテールバンキングにとってより顧客中心かつインクルーシブな未来への道筋を立てることが可能となります。
すぐに皆様のカスタマー360のデータアセット戦略をテストするために、アクセラレータのノートブックを試してみてください。そして、同様のユースケースのお客様を我々がどのように支援してきたのかを知りたいのであれば、ぜひご連絡ください。