こちらの記事で触れた、オープンソース大規模言語モデルDollyを動かしてみます。モデルをダウンロードしてトレーニングを行うところまでカバーします。
前提
- Databricksワークスペース
- GPUインスタンスのクォータ(こちらに記載されている
p4d.24xlargeなどは大規模GPUクラスターなので、多くの場合クォータ解除の申請が必要になりますが、そもそも希少なので利用自体が難しいかもしれません)
手順
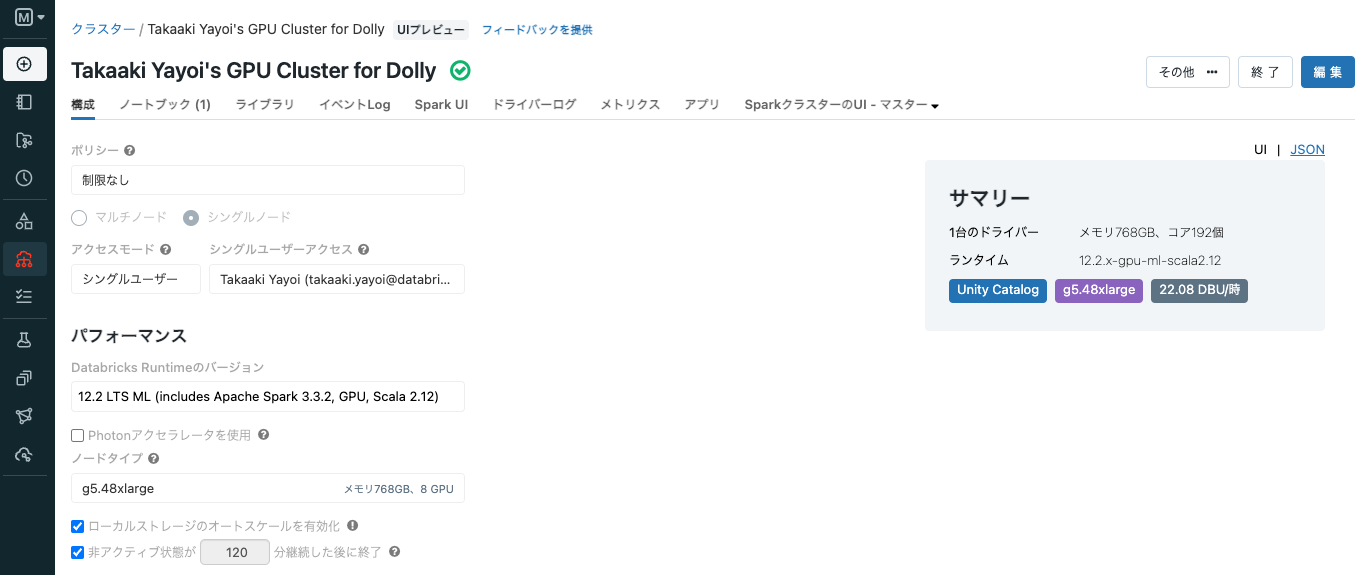
クラスターの作成
私が使用している環境でも上のインスタンスタイプは利用できなかったので、g5.48xlargeを使用しています。これでもメモリ768GB、8GPUです。
注意
CPUクラスターに比べて、GPUクラスターは高価なので使用する際にはコストに注意してください。AWSのコストに加えて、こちらで試算できるようにg5.48xlargeの場合、Databricksのコストも一時間あたり14ドル程度かかります。
ノートブックのクローン
もとのソースはGitHubで公開されているので、Databricks Reposのリポジトリにクローンします。
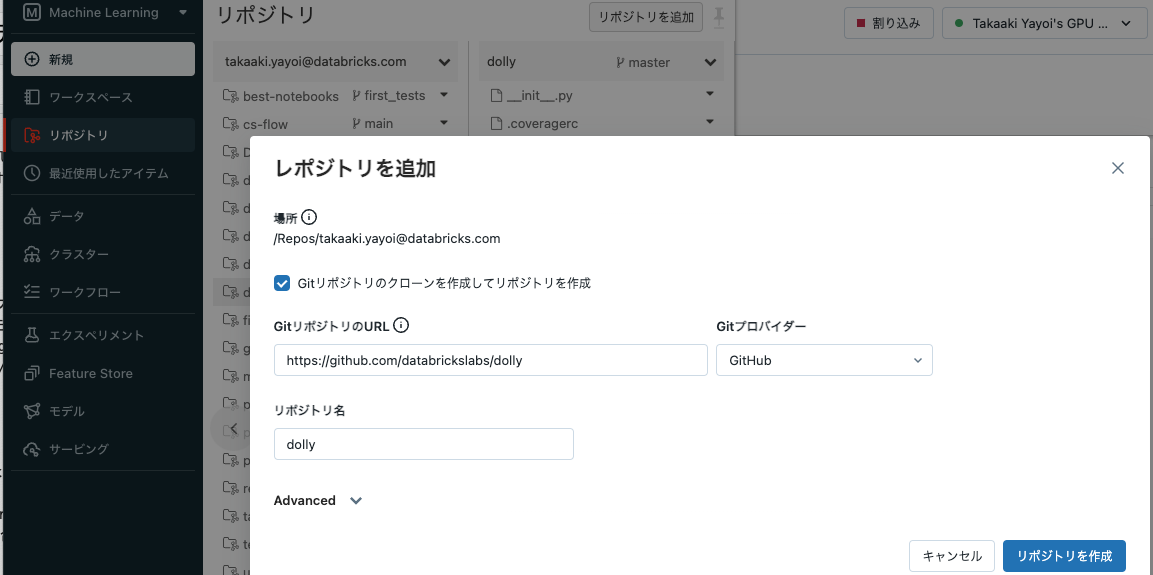
設定の変更
ノートブックtrain_dollyを開き、上で作成したクラスターにアタッチします。
実際、g5.48xlargeでトレーニングを完了させるにはいくつか設定の変更を行いました。さらなるチューニングは必要だと思いますが、まずはトレーニング完遂を目指します。こちらではトレーニングに成功した設定を共有しています。
リポジトリからクローンしたdolly/config/ds_z3_bf16_config.jsonを変更します。"zero_optimization"の下に"offload_optimizer"のブロックを追加しています。
{
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
ノートブックの最後のセルは以下の様になっています。
!deepspeed {num_gpus_flag} \
--module training.trainer \
--deepspeed {deepspeed_config} \
--epochs 1 \
--local-output-dir {local_output_dir} \
--dbfs-output-dir {dbfs_output_dir} \
--per-device-train-batch-size 8 \
--per-device-eval-batch-size 8 \
--lr 1e-5
今回はバッチサイズと学習率を大きくしています。
!deepspeed {num_gpus_flag} \
--module training.trainer \
--deepspeed {deepspeed_config} \
--epochs 1 \
--local-output-dir {local_output_dir} \
--dbfs-output-dir {dbfs_output_dir} \
--per-device-train-batch-size 16 \
--per-device-eval-batch-size 16 \
--lr 1e-2
ノートブックの実行
Cmd4を実行すると、画面左上にあるnum_gpusはDatabricksのウィジェットであり、ノートブックにパラメーターを引き渡すことができます。ここではクラスターのGPU数である8を入力しておきます。
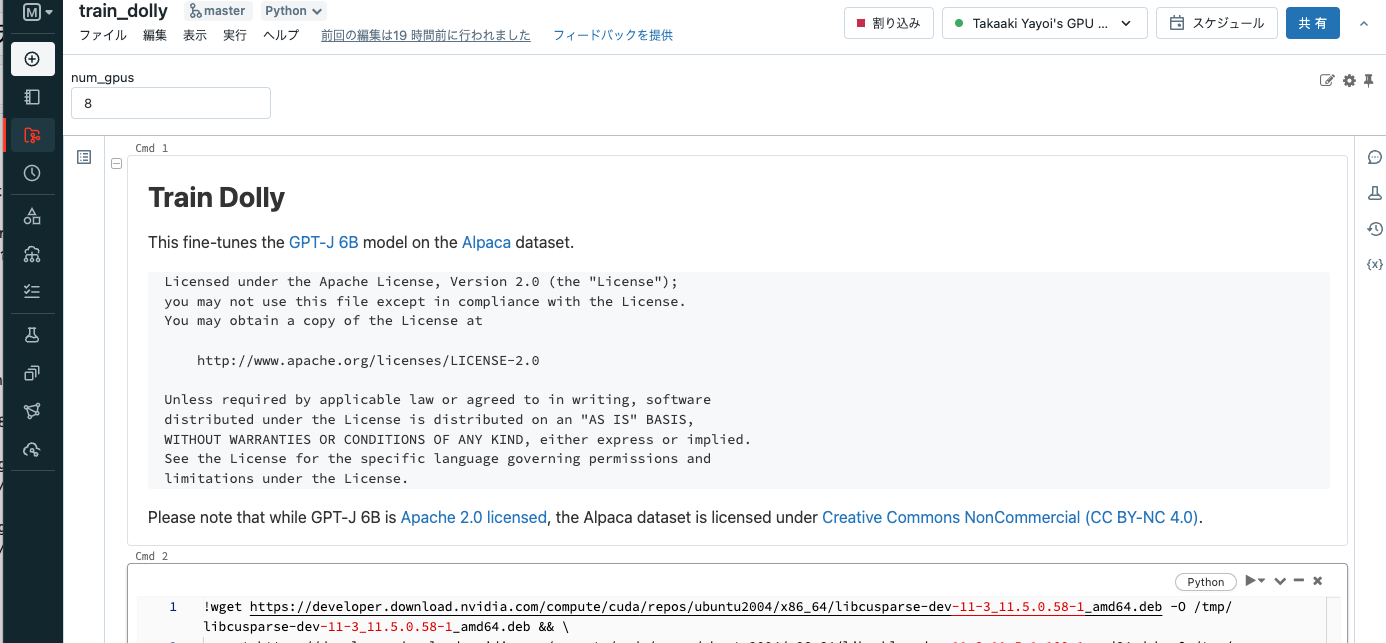
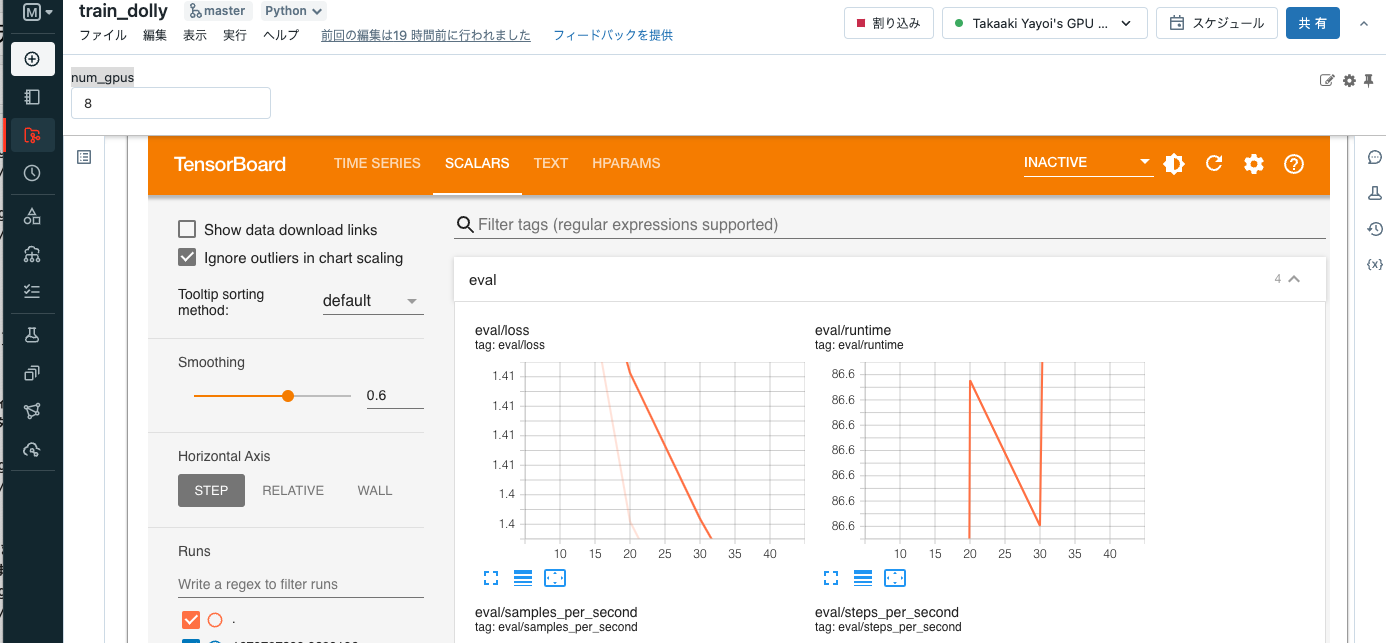
Cmd9を実行すると、tensorboardが表示されるのでトレーニングの進捗を確認することができます。
トレーニングの完了
上のスペックのインスタンスでは約4時間かかりました。
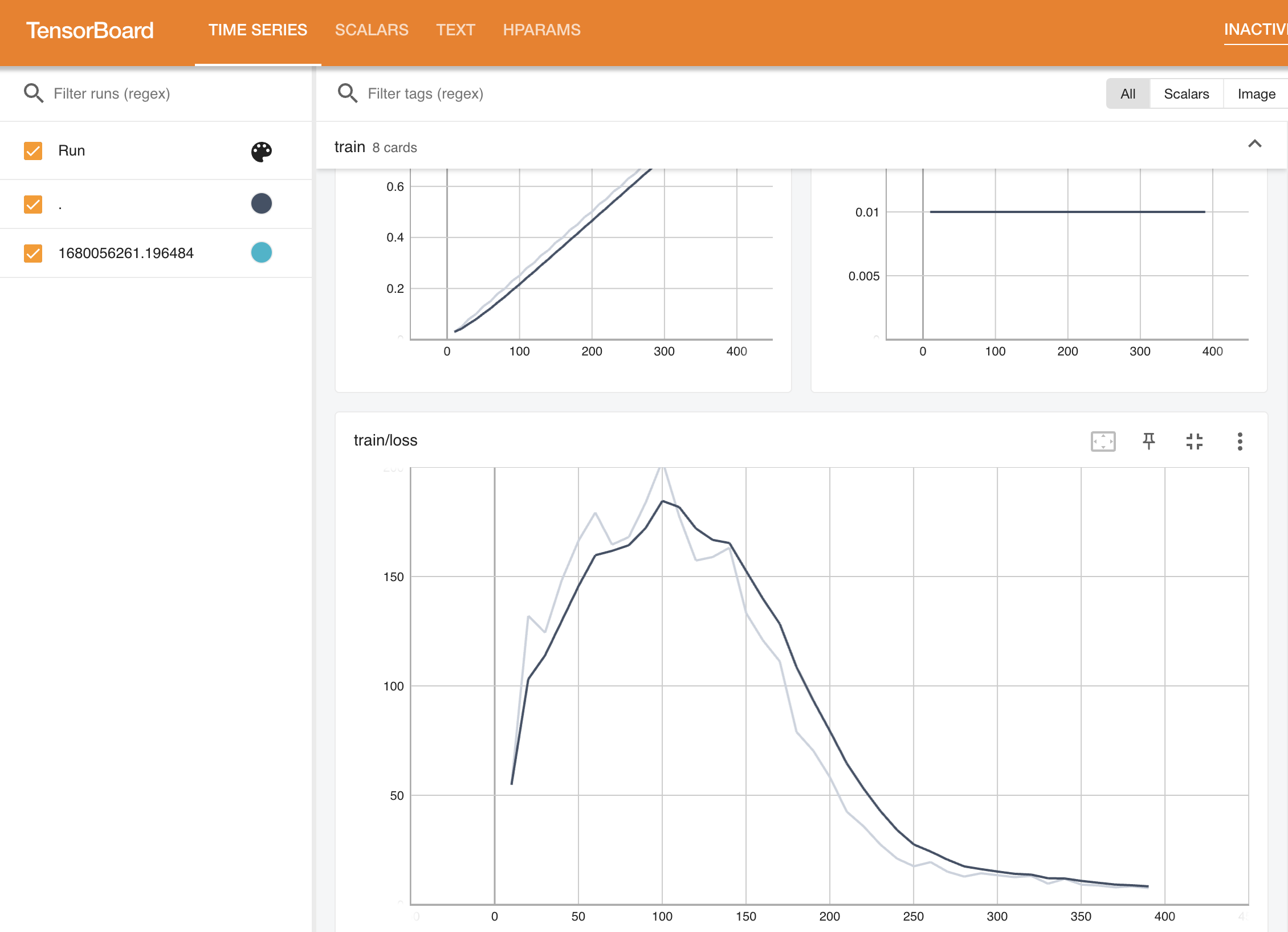
Tensorboardの結果。
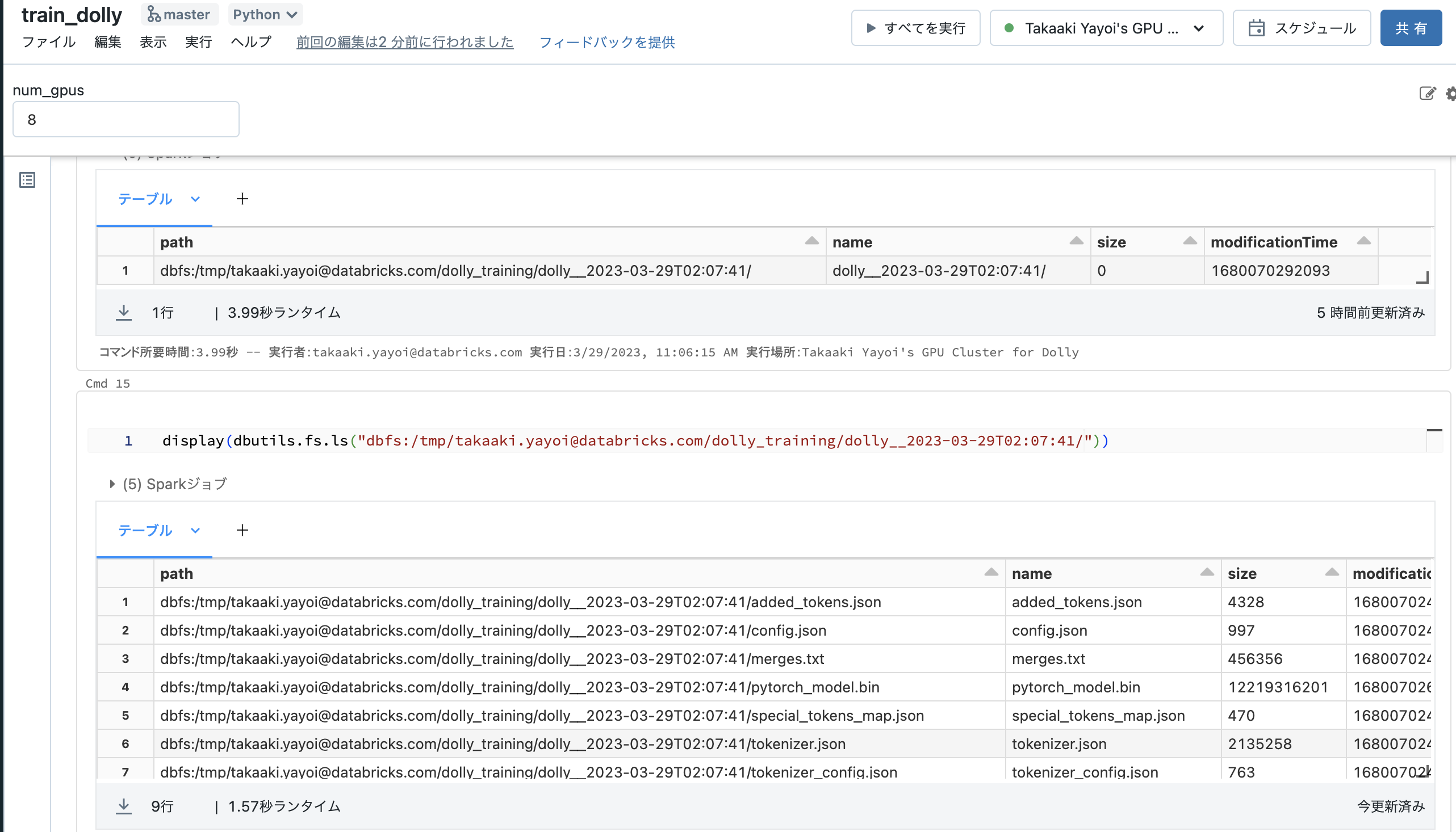
出力ディレクトリにモデルが永続化されています。
次はこのモデルをどう使うかを調査します。