Top 5 Workflows Functionalities Announced at Data + AI Summit - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Data + AI Summitでは、Databricksレイクハウスプラットフォームに関して盛りだくさんのアナウンスがありました。これらのアナウンスの中には、Databricksレイクハウスプラットフォームと深くインテグレーションされた完全マネージドのオーケストレーションサービスであるDatabricksワークフローに関するいくつかのエキサイティングな機能強化も含まれていました。これらの新機能によって、データエンジニア、データサイエンティスト、アナリストは、複雑なインフラストラクチャを管理することなしに、任意のクラウド上で信頼性のあるデータ、分析、MLワークフローを構築できるようになります。
Gitサポートによる高信頼プロダクションデータパイプライン、MLパイプラインの構築
我々は全てのコードのバージョンを管理するためにGitを使っています。だとしたら、データパイプライン、MLパイプラインでGitを使わない理由はありませんよね?DatabricksワークフローにおけるGitサポートによって、Databricksワークフローを構成するタスクのソースとしてリモートのGitリファレンスを使用することができます。これによって、誤ってプロダクションコードを編集してしまう可能性を排除し、Databricksにおけるプロダクションコードのコピーを維持するためのオーバーヘッドを削減します。また、それぞれのジョブの実行はコミットのハッシュ値にリンクされるので、最新の状態を保つことができ再現性を改善することができます。ワークフローにおけるGitサポートはパブリックプレビューであり、GitHub、Gitlab、Bitbucket、Azure DevOps、AWS CodeCommitを含む幅広いGitプロバイダーと連携します。
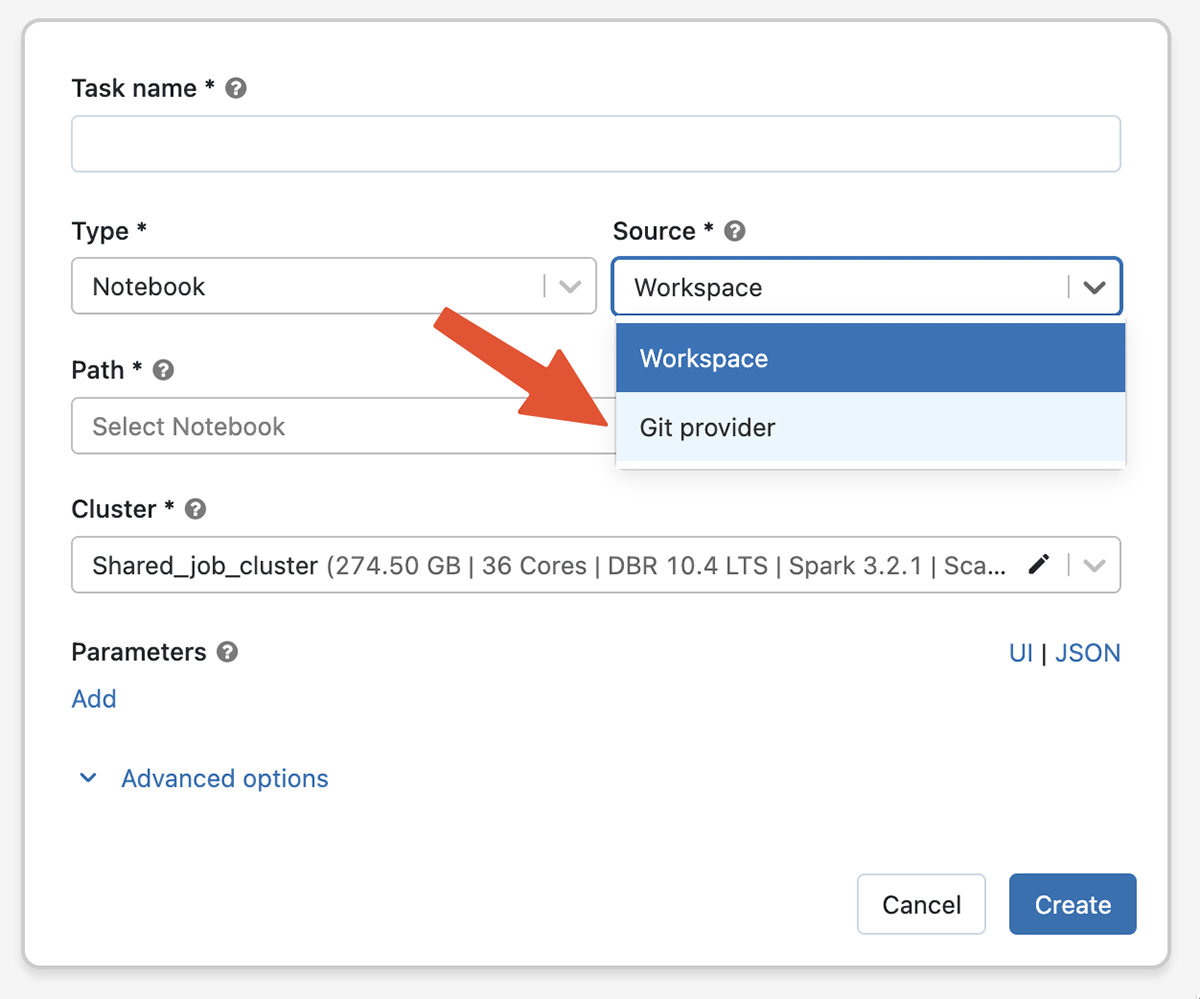
ワークフローにおけるGitサポート
詳細に関しては、こちらのブログ記事を参照ください。
プロダクションにおけるdbtプロジェクトの実行
dbtはシンプルなSQLを用いてデータパイプラインを構築できる人気のあるオープンソースツールです。全てのものはプレーンテキストとしてディレクトリの中に整理され、バージョン管理、デプロイメント、テスト可能性をシンプルにします。昨年、我々はDatabricksユーザーにシンプルなセットアップとPhoton高速化SQLを提供する、新たなdbt-databricksアダプターを発表しました。dbtユーザーは、ジョブの新たなdbtタスクタイプを用いることでDatabricks上でプロダクションのプロジェクトを実行することができ、プロダクションワークロードのための素晴らしいAPIとセマンティクスを提供する信頼性の高いオーケストレータのメリットを享受することができます。
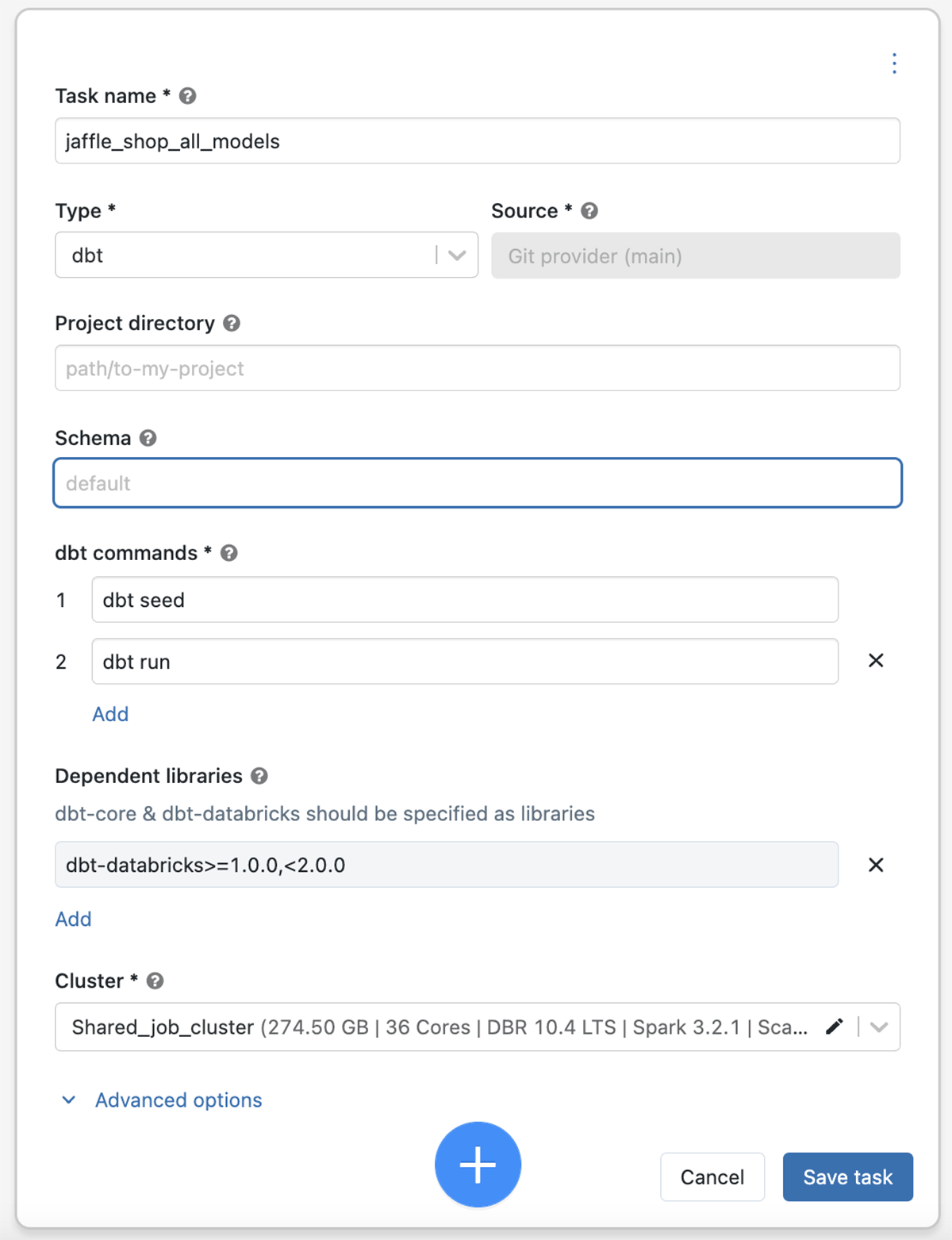
ジョブにおけるdbtタスクタイプ
この機能のプライベートプレビューに参加するには、Databricks担当者にコンタクトしてください。
SQLタスクによる更なるレイクハウスのオーケストレーション
リアルワールドのデータとMLパイプラインでは、数多くの異なるタイプのタスクが共に連携します。ジョブにSQLタスクタイプを追加することで、レイクハウスでさらに多くのものをオーケストレーションできるようになります。例えば、データを取り込むためにノートブックを起動し、データを変換するためにDelta Live Tablesのパイプラインを実行し、そして、クエリーの実行とダッシュボードの更新をするためにSQLタスクタイプを使用することができます。
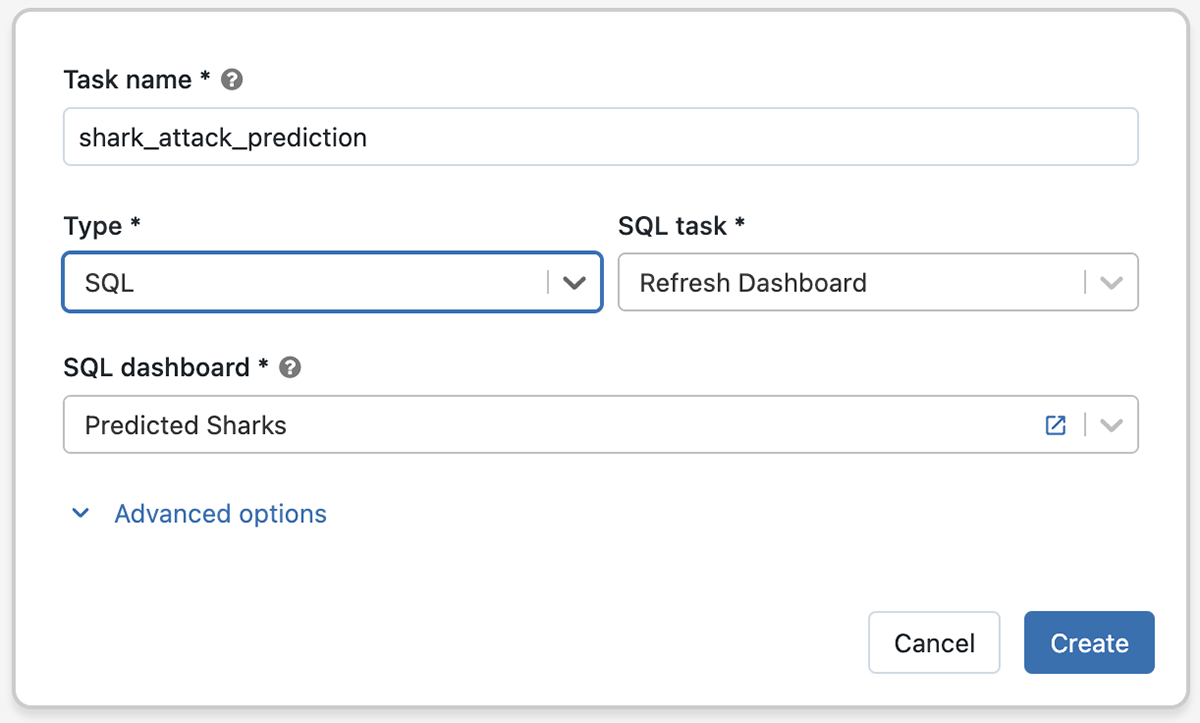
ジョブにおけるSQLタスクタイプ
この機能のプライベートプレビューに参加するには、Databricks担当者にコンタクトしてください。
「リペアおよびリラン」によるデータワークフロー、MLワークフローの時間と費用の節約
リアルワールドのデータ、機械学習ユースケースをサポートするためには、企業はデータの取り込み、ETLからMLモデルのトレーニング、サービングに至る数多くのタスクや依存関係を持つ洗練されたワークフローを作成しなくてはなりません。これのタスクのそれぞれは、適切な順序で完了しなくてはなりません。しかし、ワークフローの重要なタスクが失敗した場合、後段のすべてのタスクに影響を与えます。ジョブの新たな「リペアおよびリラン」機能は、失敗したタスクのみを実行できるようにすることでこの問題に対応し、時間と費用を節約します。
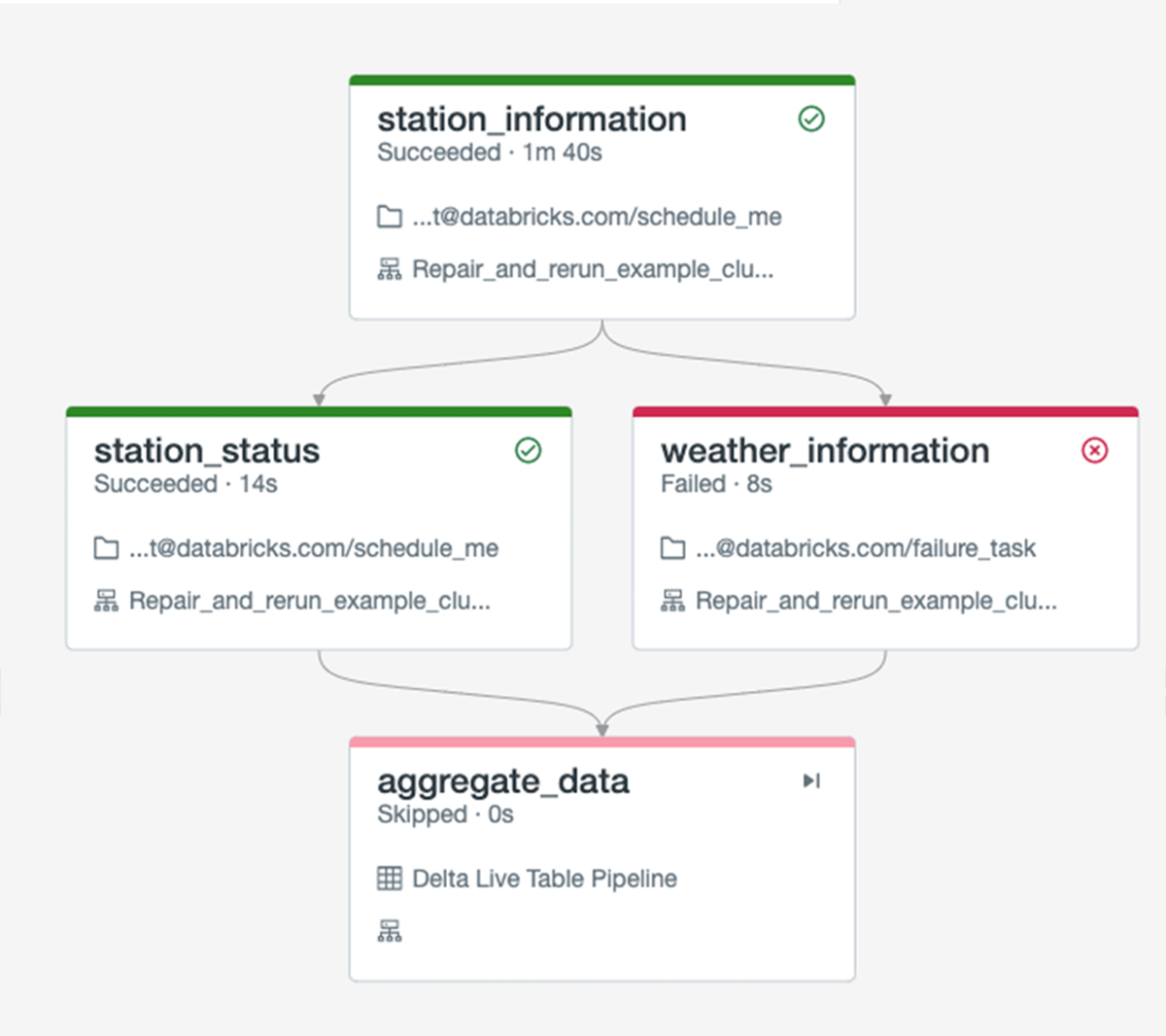
ジョブのリペア、リラン
容易にタスク間の文脈を共有
あるタスクが、上流のタスクの結果に依存するケースがあります。例えば、あるモデルの統計情報(F1スコアなど)が、事前に定義された閾値を下回った場合、モデルを再トレーニングしたいと考えるかもしれません。これまでは、上流のタスクからのデータにアクセスするためには、Deltaテーブルのようにジョブの文脈外のどこかの場所に格納する必要がありました。
今では、Task Values APIを用いることで、後段のタスクから取得できる値をタスクに設定することができます。デバッグを容易にするために、ジョブのUIはタスクに指定された値を表示します。
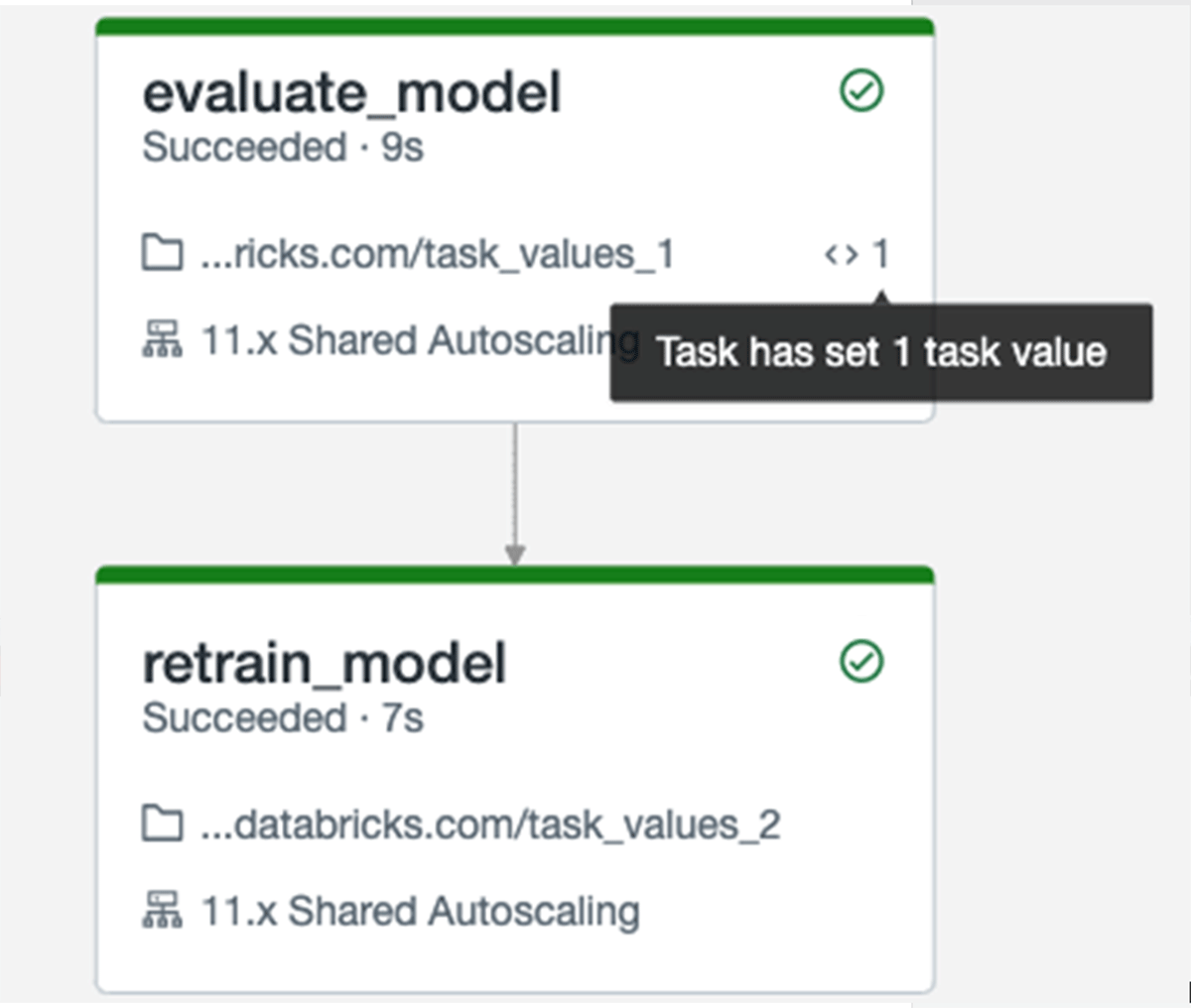
タスクバリュー
より詳細は
ワークフローのデモ
Data + AI Summit 2022での発表やアップデートに関して、データに熱中している人たちが会話しているDatabricks Communityに参加してみてください。学び、ネットワークを作り、祝いましょう。