Get started with Databricks as a data engineer | Databricks on AWS [2022/1/23時点]の翻訳です。
Databricksクイックスタートガイドのコンテンツです。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
データエンジニアのゴールは、生データを取り出して補強し、他の許可されたユーザー、特にデータサイエンティスト、データアナリストが利用できるようにすることです。このクイックスタートでは、容易に利用できるように、データの取り込み、変換、テーブルへの書き込みをウォークスルーします。
始める前に
ステップ1: DatabricksのData Science & Engineering UIに慣れる
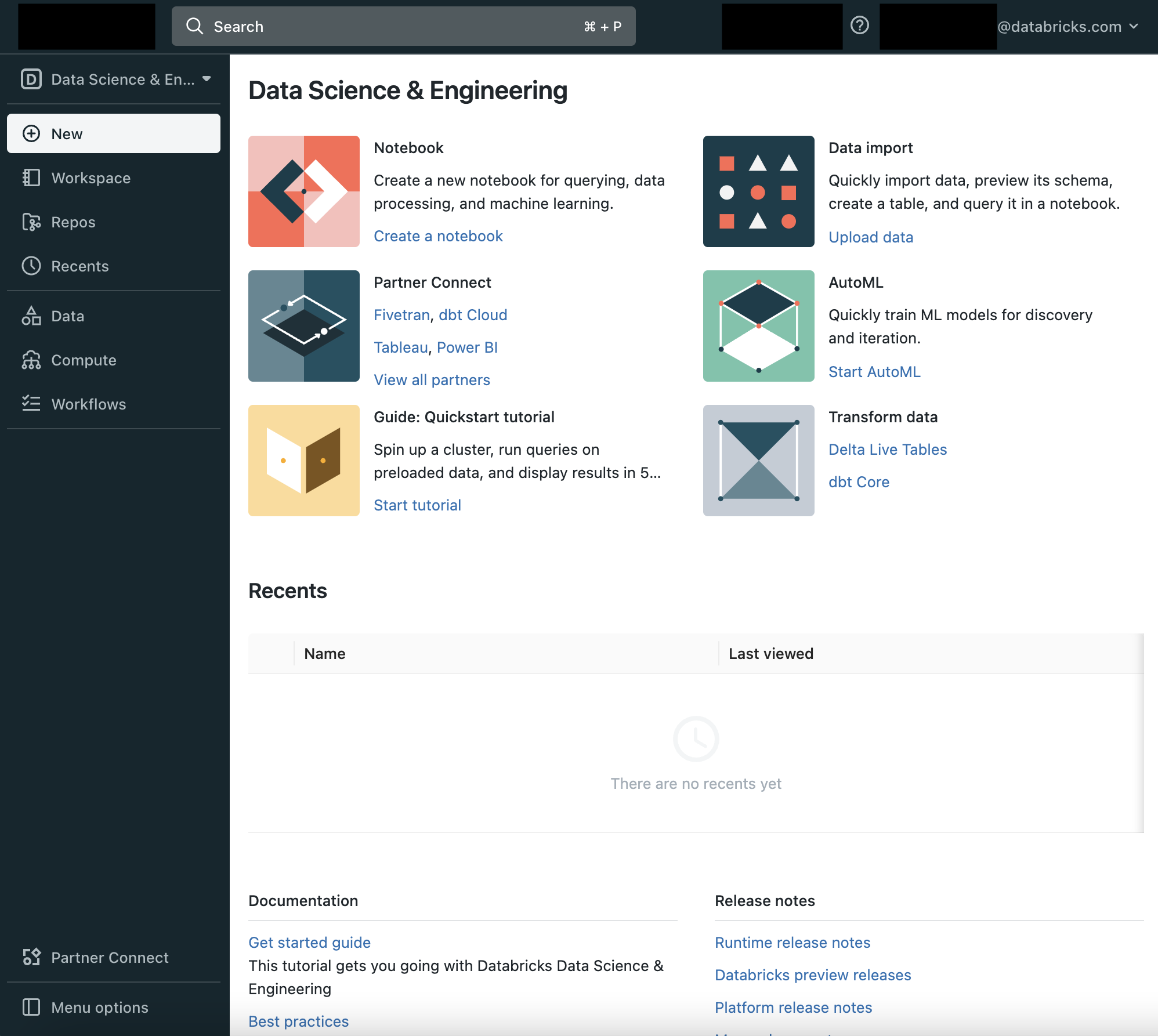
画面左のサイドバーとランディングページのCommon Tasksリストから、DatabricksのData Science & Engineeringの主要エンティティ: ワークスペース、クラスター、テーブル、ノートブック、ジョブ、ライブラリにアクセスすることができます。ワークスペースはノートブック、ライブラリ、インポートしたデータのようなDatabricksアセットを格納する特殊なルートフォルダーです。
サイドバーの利用
左のサイドバーからDatabricksの全てのアセットにアクセスできます。サイドバーのコンテンツは選択するペルソナ(Data Science & Engineering、Machine Learning、SQL)によって決まります。
-
デフォルトではサイドバーは畳み込まれた状態で表示され、アイコンのみが表示されます。サイドバー上にカーソルを移動すると全体を表示することができます。
-
ペルソナを変更するには、Databricksロゴ
 の直下にあるアイコンからペルソナを選択します。
の直下にあるアイコンからペルソナを選択します。

-
次回ログイン時に表示されるペルソナを固定するには、ペルソナの隣にあるをクリックします。再度クリックするとピンを削除することができます。
-
サイドバーの一番下にあるMenu optionsで、サイドバーの表示モードを切り替えることができます。Auto(デフォルト)、Expand(展開)、Collapse(畳み込み)から選択できます。
-
機械学習に関連するページを開く際には、ペルソナは自動的にMachine Learningに切り替わります。
ヘルプの利用
ヘルプにアクセスするためには、右上のアイコン![]() をクリックします。
をクリックします。
ステップ2: クラスターを作成する
クラスターはDatabricksの計算リソースの集合体です。クラスターを作成するには:
-
Databricksにログインすると、Data Science & Engineeringワークスペースに移動します。
-
サイドバーの
 Computeボタンをクリックします。
Computeボタンをクリックします。 -
クラスターページで、Create Clusterをクリックします。

-
クラスター作成ページで、クラスター名Quickstartを指定して、Databricksランタイムバージョンドロップダウンから**7.3 LTS (Scala 2.12, Spark 3.0.1)**を選択します。
-
Create Clusterをクリックします。
ステップ3: データを取り込む
Databricksにデータを取り込む最も簡単な方法はCreate Table Wizardを使用することです。サイドバーで![]() DataをクリックしてCreate Tableボタンをクリックします。
DataをクリックしてCreate Tableボタンをクリックします。

Create New Tableダイアログで、お使いのコンピュータからFilesセクションにCSVファイルをドラッグアンドドロップします。テストするサンプルファイルを必要があるのであれば、ダイアモンドデータセットをローカルコンピュータをダウンロードし、アップロードするためにドラッグアンドドロップします。

- Create Table with UIボタンをクリックします。
- ステップ2で作成したQuickstartクラスターを選択します。
- Preview Tableボタンをクリックします。
- Specify Table Attributesセクションまでスクロールダウンしてデータをプレビューします。
- First row is headerオプションを選択します。
- Infer Schemaオプションを選択します。
- Create Tableをクリックします。
これで、クエリーをするためのDelta Lakeテーブルを作成しました。
それ以外のデータ取り込みの選択肢
あるいは、テーブルを作成するノートブックのコードを調査し、編集するためにCreate Table in Notebookボタンをクリックすることができます。Other Data Sourcesセレクターをクリックすることで、Redshift、Kinesis、JDBCのような他のデータソースからデータを取り込むためのコードを生成するためのこの方法を取ることができます。
Salesforceのようにデータを取り込む他のデータソースがある場合、サイドバーのPartner ConnectをクリックすることでDatabricksのパートナーを容易に活用することができます。Partner Connectからパートナーを選択すると、パートナーのアプリケーションをDatabricksに接続することができ、パートナーの製品、サービスにユーザー登録していない場合でも、フリートライアルをスタートすることも可能です、詳細はDatabricks Partner Connectガイドをご覧ください。
ステップ4: データをクエリーする
ノートブックはApache Sparkクラスターでの処理を実行するセルの集合体です。ワークスペースでノートブックを作成するには:
-
サイドバーで
 Workspaceボタンをクリックします。
Workspaceボタンをクリックします。 -
ワークスペースのフォルダーで
 をクリックし、Create > Notebookを選択します。
をクリックし、Create > Notebookを選択します。

-
ノートブック作成ダイアログで、名前を入力し、言語ドロップダウンではPythonを選択します。これによりノートブックのデフォルト言語を決定します。
-
Createをクリックします。先頭のセルが空白のノートブックが開きます。
-
最初のセルに以下のコードを入力し、SHIFT+ENTERをクリックしてコードを実行します。
Python
df = table("diamonds_csv")
display(df)
ノートブックはダイヤモンドの色と平均価格のテーブルを表示します。

1. 別のセルを作成し、今回はSQLクエリーを入力するために`%sql`マジックコマンドを使用します。
```sql:SQL
%sql
select * from diamonds_csv
ノートブックのデフォルト言語を上書きするために、セルの最初に%sql、%r、%python、%scalaマジックコマンドを使用することができます。
- コマンドを実行するためにSHIFT+ENTERをクリックします。
ステップ5: データを可視化する
色ごとのダイアモンドの平均価格のチャートを表示します。
-
棒グラフアイコン
 をクリックします。
をクリックします。 -
Plot Optionsをクリックします。
- colorをKeysボックスにドラッグします。
- priceをValuesボックスにドラッグします。
- AggregationドロップダウンでAVGを選択します。

-
棒グラフを表示するためにApplyをクリックします。

ステップ6: データを変換する
高信頼かつスケーラブルなデータパイプラインを作成するベストな方法はDelta Live Tablesを使うことです。
効果的なパイプラインの構築、エンドツーエンドの実行方法についてはDelta Live Tablesクイックスタートを参照ください。
ステップ7: データガバナンスをセットアップする
Databricksのテーブルへのアクセスをコントロールするには以下の手順を踏みます。
-
サイドバーのペルソナスイッチャーを使用してDatabriks SQL環境に切り替えます。
Databricksロゴ
の下のアイコンをクリックしてSQLを選択します。 -
サイドバーの
 Dataをクリックします。
Dataをクリックします。右上のドロップダウンリストでStarter EndpointのようなSQLエンドポイントを選択します。
-
ステップ2で作成した
diamonds_csvテーブルを検索します。
defaultデータベースを選択し、下のテキストボックスにdiaと入力してフィルタリングを行い、diamonds_csvを選択します。

- PermissionsタブでGrantボタンをクリックします。
-
All Usersに対してテーブルのSELECT、READ_METADATAを許可します。

- OKをクリックします。
これで作成したテーブルを全てのユーザーが参照できるようになりました。
ステップ8: ジョブをスケジュールする
Databricksクラスターのスケーラブルなリソースを用いて、データ処理タスクを事項するジョブをスケジューリングすることができます。シングルタスクのジョブ、あるいは大規模かつ複雑な依存関係を持つマルチタスクアプリケーションのジョブを構成することができます。
サンプルデータセットを読み込み処理を行うタスクをオーケストレートするジョブの作成方法については、Jobs quickstartをご覧ください。
次のステップ
Databricksにおけるデータエンジニアリングタスクの実行を支援する他のツールについて学習することができます。
- Connect your favorite IDE using Databricks Connect
- Use Azure Data Factory or Apache Airflow to manage dependencies in data pipelines
- Use dbt with Databricks
- Develop a CI/CD pipeline for Databricks
- Learn about the Databricks Command Line Interface (CLI)
- Learn about the Databricks Terraform Provider