New Visualizations for Understanding Apache Spark Streaming Applications - The Databricks Blogの翻訳です。
本記事はSpark 1.4.0を前提としており、最新バージョンのSpark UIとは構成が異なる部分があります。
前回は、Sparkアプリケーションの動作を理解するために、Apache Spark 1.4.0で導入された新たな可視化機能をご紹介しました。同じテーマのもと、この記事では特にSparkストリーミングのアプリケーションを理解できるように導入された新たな可視化機能をハイライトします。我々はSpark UIのストリーミングタブを以下のようにアップデートしました。
- イベントの速度、スケジューリングの遅れ、過去のバッチの処理時間のタイムライン、統計情報
- それぞれのバッチの全てのSparkジョブの詳細
さらに、ストリーミングのオペレーションの文脈におけるジョブ実行を理解するために、実行DAGの可視化が、ストリーミングの情報で拡張されています。
ストリーミングアプリケーションを分析するエンドツーエンドのサンプルを用いて、より詳細に見ていきましょう。
処理のトレンドに対するタイムライン、ヒストグラム
Sparkストリーミングアプリケーションをデバッグする際、ユーザーは多くの場合、データを受け取る速度と、それぞれのバッチの処理時間に興味を持ちます。ストリーミングタブの新たなUIでは、現在のメトリクスと過去の1,000個のバッチにおけるトレンドを容易に確認することができます。ストリーミングアプリケーションを実行している間、Spark UIのストリーミングタブを開くと、以下の図1のような画面が表示されることでしょう。(赤字の[A]は注釈で、UIの一部ではありません)
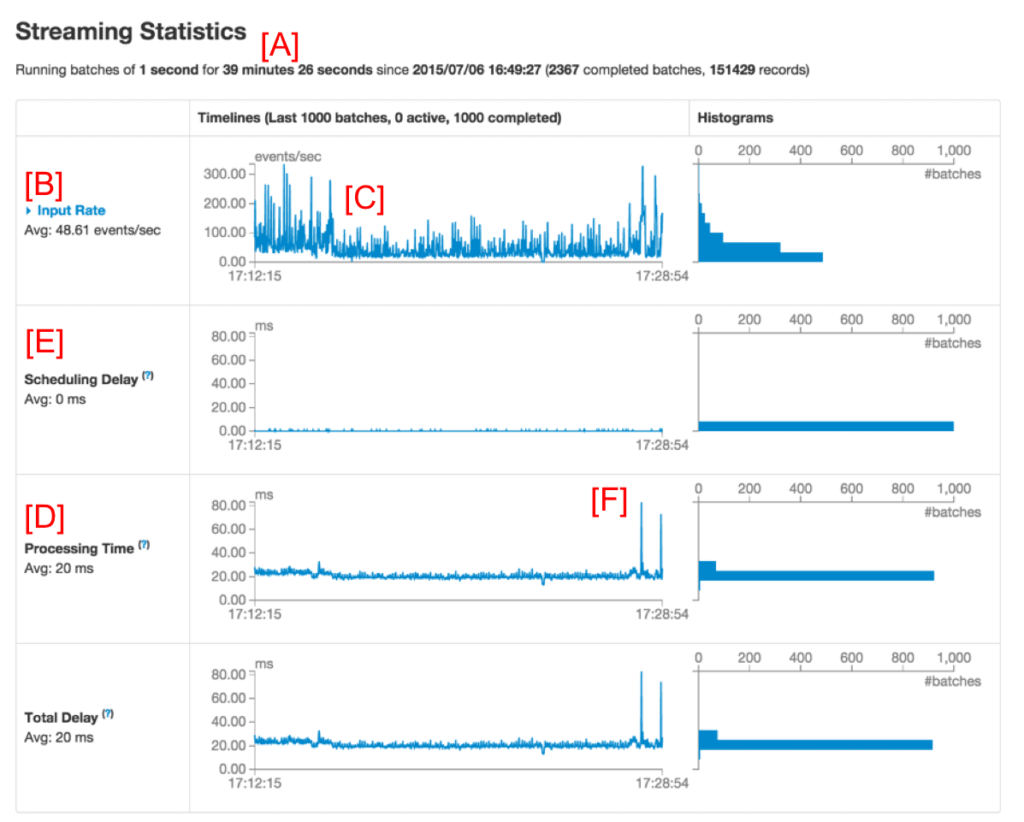
図1: Spark UIのストリーミングタブ
最初のライン(**[A]のマーク)にはストリーミングアプリケーションの現在の状態が表示されます。この例では、アプリケーションは、1秒のバッチ間隔でおおよそ40分稼働しています。その下の、Input Rate([B]のマーク)には、ストリーミングアプリケーションが、ソースから49イベント/秒のスピードでデータを受け取っていることが表示されています。この例では、タイムラインは中央([C]でマーク)で平均速度が少々減少しており、タイムラインの終端に向けて回復傾向が認められます。より詳細を知りたい場合には、Input Rate([B]**の近く)の側のドロップダウンをクリックして、以下の図2のように、それぞれのソースから構成されるタイムラインを表示することができます。
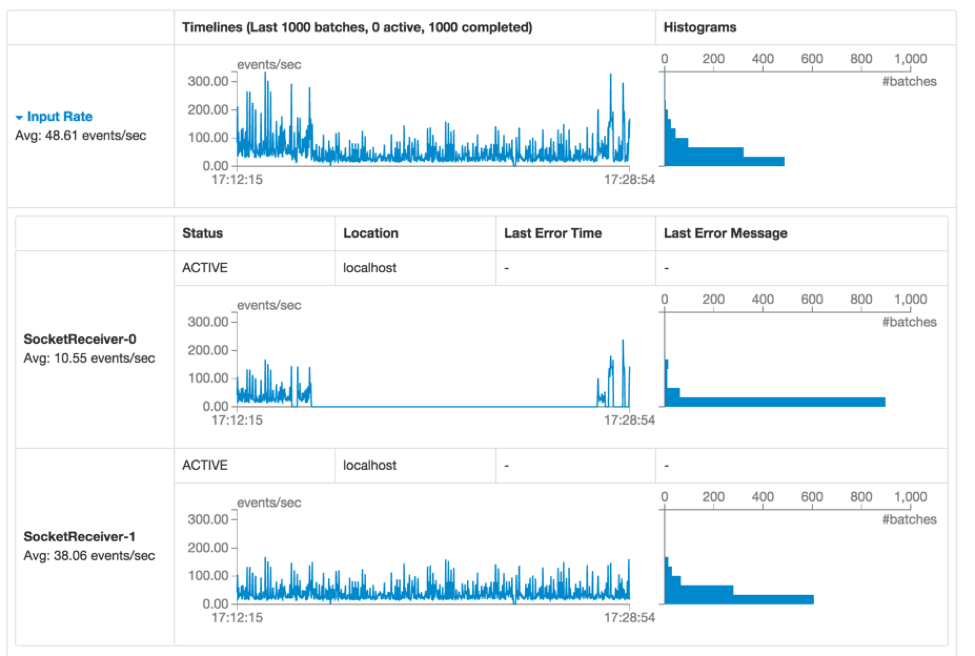
図2
図2では、アプリケーションには二つのソース(SocketReceiver-0とSocketReceiver-1)が存在し、そのうちの一つが短い期間データの受信をストップしたため、全体的な受信速度を引き下げたことがわかります。
このページの下(図1の**[D])をさらに見ていくと、Processing Timeには、平均20msでバッチが処理されていることが表示されています。バッチ間隔(この例では1秒)よりも短い処理時間は、バッチは作成されるとすぐに処理されており、(図1で[E]**で示されており、前回のバッチが完了するまでのバッチの待ち時間として定義される)Scheduling Delayがほぼゼロであることを意味しています。Scheduling delayはお使いのストリーミングアプリケーションが安定しているか否かを示す重要なインジケーターであり、このUIによって容易にモニタリングすることができます。
バッチの詳細
もう一度図1を見てみると、なぜか右側に行くに従って、いくつかのバッチが完了するのに長い時間を要している(図1の**[F]**)ことを不思議に思うかもしれません。このUIを用いることで容易に分析することができます。まず初めに、タイムラインのグラフでバッチ処理時間が高い値を示している部分をクリックします。これによって、ページ内の完了バッチ一覧に移動することができます。
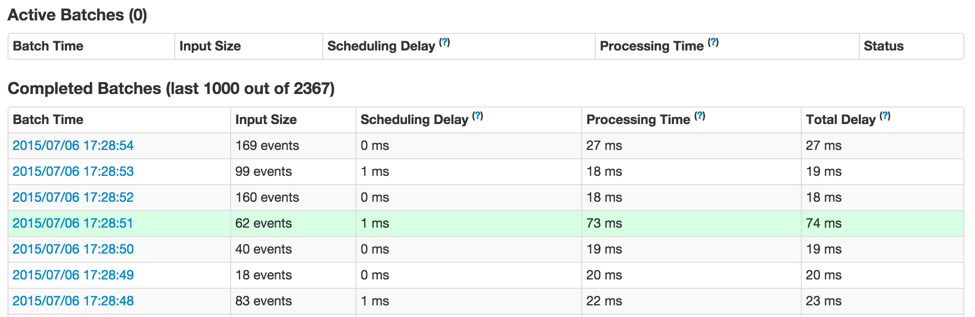
図3
これはここのバッチの詳細を表示します(図3で緑でハイライトされています)。こちらからわかるように、このバッチは他のバッチよりも長い処理時間を要しています。次に来る疑問は、どのようなSparkジョブが、このバッチの処理時間を長いものにしたのかというものです。これを調査するためには、バッチ処理時間(最初の列のブルーのリンク)をクリックします。これによって、対応するバッチの詳細情報、出力オペレーションとSparkジョブを表示します。(図4)
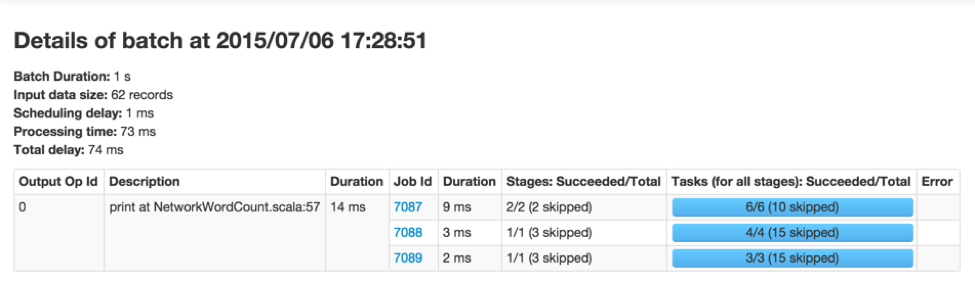
図4
上の図4からは、3つのSparkジョブを生成する出力オペレーションがあったことがわかります。さらに分析を進めるために、ジョブIDをクリックしてステージやタスクを調べることができます。
ストリーミングRDDの実行DAG
バッチジョブのタスク、ステージの分析を始めると、実行グラフに対する深い理解が役立つことになります。前回の記事で説明したように、Spark 1.4.0では、RDDの依存関係および、一連の依存関係のあるステージを用いて、どのようにRDDが処理されるのかを表現するために、実行DAG(有効非巡回グラフ)の可視化が追加されました。これらのRDDがストリーミングアプリケーションのDStreamsで生成された場合には、この可視化にストリーミングのセマンティクスが追加されます。それぞれのバッチで受け取る単語をカウントする、シンプルなストリーミングのワードカウントプログラムからスタートします。NetworkWordCountのサンプルをご覧ください。ここでは、ワードカウントを計算するためにDStreamのオペレーションのflatMap, map, reduceByKeyを使用します。Sparkジョブの実行DAGは以下の図5のようになります。

図5
黒のドットは、16:06:50のバッチのDStreamによって生成されたRDDを表現しています。青で塗られたボックスはRDDを変換するために使われたDStreamオペレーションを参照しており、ピンクのボックスはこれらの変換が行われるステージを表現しています。これは全体的に以下のことを示しています。
- 16:06:50のバッチにおける単一のsocket text streamからデータを受け取っている。
- データからワードカウントを行うために、flatMap, map, reduceByKeyの変換を用いる2つのステージから構成されたジョブ。
これはシンプルなグラフですが、より多くの入力ストリームや、windowやupdateStateByKeyオペレーションのような高度なDStream変換が必要になってくるとグラフはさらに複雑になります。例えば、2つのsocket text streamからのデータを用いて、3つのバッチの移動ウィンドウに対してカウントを行う際には、バッチジョブの一つの実行DAGは以下の図6のようになるでしょう。
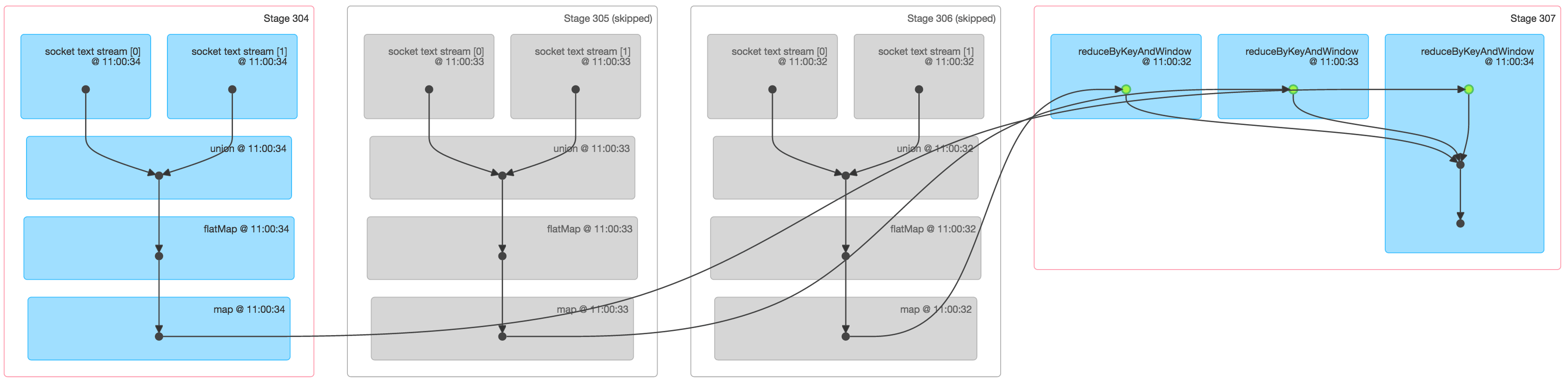
図6
図6は、3つのバッチからのデータに対するワードカウントを行うSparkジョブに関して多くの情報を提供します。
- 最初の3つのステージは、ウィンドウ内の3つのバッチのそぞれでワードカウントを行います。これは、mapとflatMapオペレーションを用いた上述のシンプルなNetworkWordCountの最初のステージと同じようなものです。しかし、以下の相違点には注意してください。
- 2つのsocket text streamのそれぞれから得られる2つの入力RDDが存在します。これら2つのRDDは単一のRDDにunionされ、さらにバッチごとの中間カウントに変換されます。
- これらのステージの2つはグレーになっていますが、これは古い2つのバッチはすでにメモリーにキャッシュされており、再計算を必要としないためです。最新のバッチのみが最初からの計算を必要とします。
- 右の最後のステージは、バッチごとのワードカウントを「ウィンドウ内の」ワードカウントに結合するためにreduceByKeyAndWindowを使用しています。
これらの可視化によって、開発者はストリーミングアプリケーションのステータスと傾向をモニタリングできるようになり、内部のSparkジョブと実行計画の関係を理解することができます。
今後の方向性
Spark 1.5.0で予定されている大きな改善点は、それぞれのバッチの入力データに関してより情報を提供するというものです(JIRA, PR)。例えば、Kafkaを使っている場合、バッチの詳細ページにはトピック、パーティション、バッチで処理されたオフセットが表示されることになるでしょう。こちらはプレビューです。
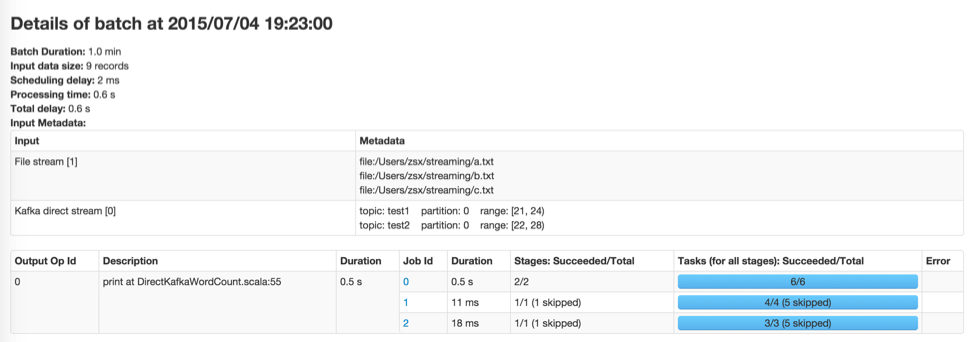
図7