How to Use Databricks to Encrypt and Protect PII Data - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
2020年時点の記事です。
そっとPIIを保護するために、Fernet暗号化ライブラリ、UDF、Databricksシークレットの活用
この記事は、Northwestern Mutualのlead software engineerであるKeyuri Shahとsoftware engineerであるFred Kimballのゲスト投稿です。
日々のデータ流出や機微情報レコードの漏洩は増加の一途を辿っており、PII(個人情報)の保護は非常に重要となっています。次の犠牲者になるのを避け、ID盗難や不正からユーザーを守るために、データや情報セキュリティの複数レイヤーを組み込む必要があります。
我々はDatabricksプラットフォームを活用しており、適切な権限が付与されたユーザーのみが機微な情報にアクセスできるようにする必要があります。Fernet暗号化ライブラリ、ユーザー定義関数(UDF)、Databricksシークレットを組み合わせることで、Northwestern MutualではPII情報の暗号化プロセスを開発し、データ読み取り者に追加のステップを求めることなしに、ビジネスニーズがある人のみに復号化を許可しています。
PII保護の必要性
近年のいかなる量の顧客データの管理においては間違いなくPIIの保護が求められます。これは、シンプルな設定ミスによって数百万の機微な顧客レコードが盗まれることになったCapital Oneのデータ漏洩のようにいかなる規模の企業にとって大きなリスクです。ストレージデバイスの暗号化やテーブルレベルのカラムマスキングは効果的なセキュリティ対策ですが、この機微なデータに対する内部の許可されないアクセスは、依然として大きな脅威となります。このため、Databricksにおいて通常のユーザーがテーブルやファイルから機微情報を取得することを制限するソリューションを必要としました。
しかし、機微情報を読み込むビジネスニーズを持つ人たちが読み込めるようにする必要もありました。我々は、それぞれのユーザーのテーブルの読み込み方法に違いを生じさせたくはありませんでした。データ分析やレポート作成におけるクエリーの作成をシンプルにするために、通常の読み込みと復号化された読み込みの両方は、同じDelta Lakeオブジェクトに対して行われる必要がありました。
カラムレベル暗号化を強制するためのプロセスの構築
これらのセキュリティ要件を受けて、セキュアでさりげなく、そして管理が容易なプロセスの作成を探索しました。以下の図では、このプロセスに必要なコンポーネントのハイレベルの概要を示しています。
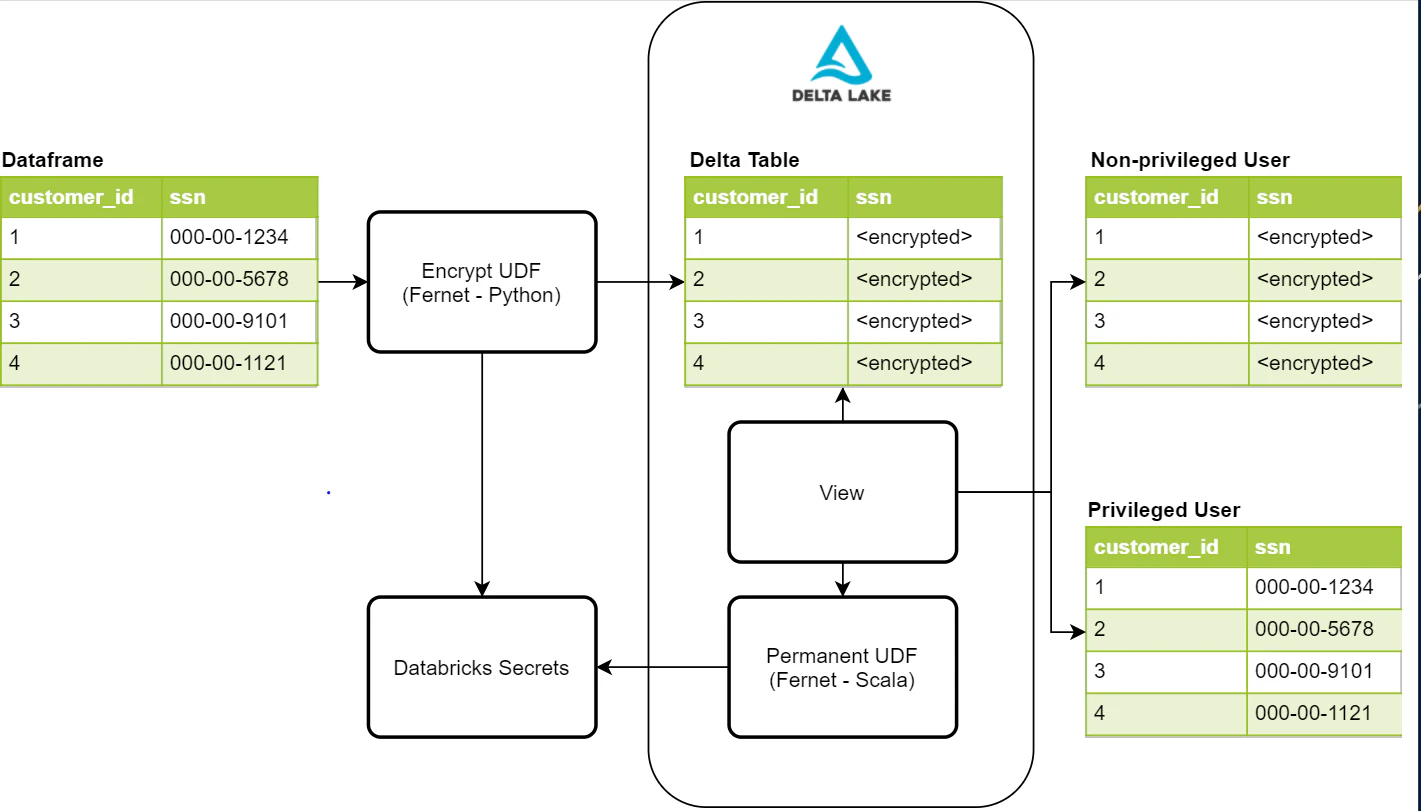
Fernetによって保護されたPIIの書き込み
このプロセスの最初のステップは、暗号化によってでデータを保護することです。可能性のあるソリューションの一つがFernet Pythonライブラリです。Fernetは、いくつかの標準的な暗号化プリミティブを用いて構築されている対称性の暗号化を使用します。このライブラリは、データフレームの任意のカラムを暗号化できるようにする暗号化UDFで使用されます。暗号化キーを格納するために、我々のデータ取り込みプロセスのみがアクセスできるようにする設定がなされたDatabricksシークレットを使用します。データがDelta Lakeテーブルに格納されると、社会セキュリティ番号、電話番号、クレジットカード番号、その他のIDのような値を保持するPIIカラムは許可されないユーザーによる読み込みができなくなります。
カスタムUDFを持つビューから保護データの読み込み
センシティブなデータが書き込まれ、保護されると、権限のあるユーザーがセンシティブなデータを読み込める方法が必要となります。最初に行う必要があるのは、Databricksで稼働しているHiveインスタンスに追加するUDFを作成することです。UDFを永続化するには、UDFはScalaで記述される必要があります。幸運なことに、Fernetには復号化読み込みで活用できるScala実装があります。また、このUDFは復号化を実行するために、暗号化書き込みに用いられたのと同じシークレットにアクセスし、このケースでは、クラスターのSpark設定に追加されます。これによって、権限のあるユーザー、権限のないユーザーにこのキーに対するアクセスをコントロールための、クラスターのアクセスコントロールが必要となります。UDFが作成されると、権限のあるユーザーが復号化されたデータを参照するために、ビュー定義でUDFを使えるようになります。
現在、単一のデータセットに対して2つのビューオブジェクトを作成しており、それぞれが権限のあるユーザー、権限のないユーザー向けのものとなっています。権限のないユーザー向けのビューにはUDFがないので、暗号化された値としてPIIの値を参照します。権限のあるユーザー向けのもう一方のビューにはUDFがあるので、彼らは自身のビジネスニーズのために復号化された値を参照することができます。また、これらのビューに対するアクセスはDatabricksによって提供されるテーブルアクセスコントロールによって制御されます。
近い将来、動的ビュー機能とよばれる新たなDatabricksの機能を活用したいと考えています。動的ビュー機能によって、ユーザーが登録されているDatabricksグループに基づいて、暗号化された値あるいは復号化された値を容易に返却、参照できるようになります。これによって、我々のDelta Lakeで作成するオブジェクトの数を削減し、テーブルアクセスコントロールのルールをシンプルにすることができます。
いずれの実装でも、ユーザーはビューから読み込まれた値を複合化する必要があるかどうかを悩むことなしに自分たちの開発や分析を行うことができ、ビジネスニーズを持つ人たちだけが復号化された値を読み込むことができます。
このカラムレベル暗号化手法の利点
まとめると、このプロセスを用いることの利点は:
- 既存のPython、Scalaライブラリを用いて暗号化を実行できます
- センシティブなPIIデータがDelta Lakeに格納される際に追加のセキュリティレイヤーが設けられます
- 同じDelta Lakeオブジェクトが、当該オブジェクトに対してさまざまなレベルの権限を持つユーザーによって使用されます
- アナリストはPIIの読み込み権限を持っているのかどうかに妨げられません
これらがどのように見えるのかのサンプルについては、以下のノートブックがガイドとなることでしょう。
追加のリソース
Fernetライブラリ
永続化UDFの作成
動的ビューの機能
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。