以下の記事で説明しているipywidgetsをDatabricksノートブック上で使ってみます。
サンプルノートブックの日本語訳はこちらです。
このノートブックでは、データサイエンティストがどのように新たなデータセットをブラウズするのかをウォークスルーします。
クラスターの作成
Databricksランタイム11.0以降が稼働するクラウスターを作成して起動します。
ノートブックの実行
上述のノートブックをインポートして実行してきます。
データのロード
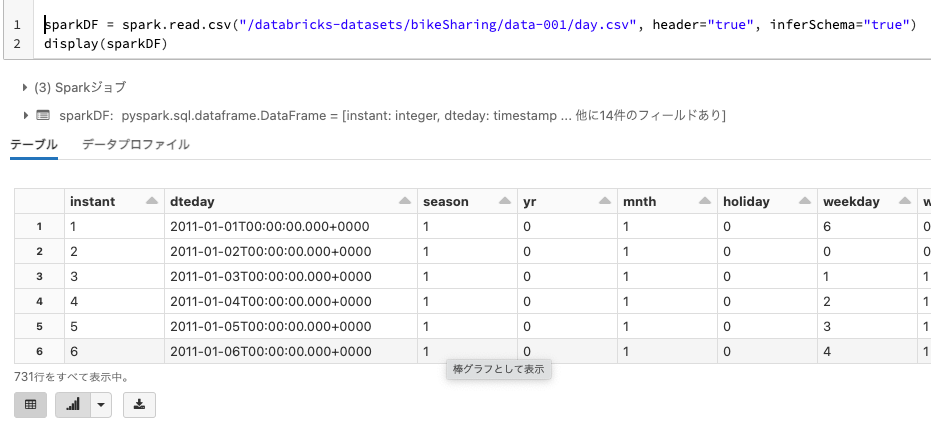
ここで使用するbike-sharingデータセットには、日付、気候、登録ユーザーによって、あるいはカジュアルにレンタルされた自転車の数を含む日毎のデータ2年分が含まれています。
sparkDF = spark.read.csv("/databricks-datasets/bikeSharing/data-001/day.csv", header="true", inferSchema="true")
display(sparkDF)
データの探索
データセットを探索する一般的な方法は、関係性を見出すために変数をプロットすることです。次のセルでは、日毎にレンタルされた自転車の総数と、その日に記録された気温の散布図を作成します。
pdf = sparkDF.toPandas()
pdf.plot.scatter(x='temp', y='cnt')

異なる説明変数と目的変数を簡単に参照できるようにするために、関数を作成することもできます。
def f(x ='temp', y = 'cnt'):
pdf.plot.scatter(x=x, y=y)
これで、関係性をプロットするために任意の2つのカラム名を指定することができます。

ipywidgetsの活用
ipywidgetsを用いることで、ご自身のプロットにインタラクティブなコントローラを追加することができます。@interactデコレーターを用いることで、1行のコードでインタラクティブなウィジェットを定義することができます。
以下のセルを実行した後、y軸にcnt、x軸にデフォルト値であるtempを持つプロットが表示されます。fit=Trueのデフォルト値のため、プロットには回帰曲線が含まれます。
x軸に異なる値を選択するために、上のプロットのwidgetセレクターを使用したり、回帰曲線の表示のオンオフを行うことができます。ウィジェット用いて選択を行うと、即座にプロットに反映されます。
異なるタイプのipywidgetsに関しては、ipywidgetsのドキュメントをご覧ください。
import ipywidgets as widgets
import seaborn as sns
from ipywidgets import interact
# このコードでは、リスト ['temp', 'atemp', 'hum', 'windspeed'] によってドロップダウンメニューウィジェットが作成されます。
# 変数にTrue/Falseを設定すると (`fit=True`) チェックボックスウィジェットが作成されます。
@interact(column=['temp', 'atemp', 'hum', 'windspeed'], fit=True)
def f(column='temp', fit=True):
sns.lmplot(x=column, y='cnt', data=pdf, fit_reg=fit)
インタラクティブに操作できるグラフが表示されます。

ドロップダウンからカラムを選択すると、即座にグラフが描画されます。
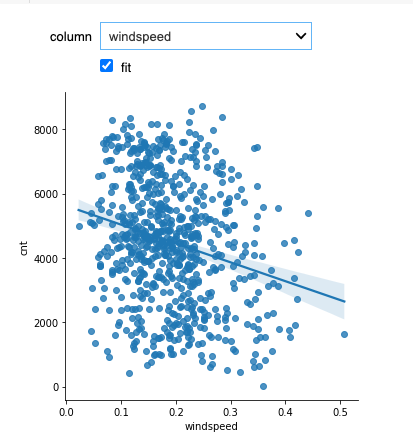
チェックボックスで回帰曲線のオンオフを切り替えることができます。

次のコマンドでは、ドロップダウンメニューを用いることで、ヒストグラムに任意の気候変数をプロットすることができます。また、ヒストグラムのビンの数を指定するためにスライダーを使うことができます。
# このコードでは、 `(bins=(2, 20, 2)` が2から20の間で2ごとの値を指定できる整数値スライダーウイジェットを定義します。
@interact(bins=(2, 20, 2), value=['temp', 'atemp', 'hum', 'windspeed'])
def plot_histogram(bins, value):
pdf = sparkDF.toPandas()
pdf.hist(column=value, bins=bins)

スライダーを操作することでヒストグラムの解像度を変更することができます。
