Run MLflow Projects on Databricks | Databricks on AWS [2021/10/14時点]の翻訳です。
注意
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
MLflow Projectは、データサイエンスのコードを再利用可能かつ再現可能な方法でパッケージするためのフォーマットです。MLflow Projectsのコンポーネントには、プロジェクトを実行するためのAPI、コマンドラインツールが含まれており、再現性確保のために、パラメーターとソースコードのgitコミットを記録するためのトラッキングコンポーネントと連携します。
本書では、MLflowプロジェクトのフォーマットを説明し、お使いのデータサイエンスコードを容易に垂直スケールできるように、MLflowのCLIを用いてDatabricksクラスターでMLflowプロジェクトをリモートで実行する方法を説明します。
MLflowプロジェクトの実行はDatabricksコミュニティエディションではサポートされていません。
MLflowプロジェクトのフォーマット
任意のローカルディレクトリ、GitリポジトリをMLflowプロジェクトとして取り扱うことができます。以下のルールに基づいてプロジェクトを定義します。
- プロジェクト名はディレクトリ名となります。
- Conda環境は
conda.yamlが存在すればconda.yamlによって定義されます。conda.yamlが存在しない場合には、MLflowはプロジェクトを実行する際にはPython(特にCondaで利用できる最新のPython)のみを含むConda環境を使用します。 - プロジェクトにおける任意の
.py、.shファイルを、明示的にパラメーターを宣言することなしに、エントリーポイントにすることができます。一連のパラメーターを指定してこのようなコマンドを実行する際には、MLflowはコマンドのそれぞれのパラメーターを--key <value>文法を使用して引き渡します。
YAML文法のテキストファイルであるMLプロジェクトファイルを指定することで、更なるオプションを指定することができます。MLプロジェクトファイルのサンプルは以下のようになります。
name: My Project
conda_env: my_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
MLflowプロジェクトを実行する
デフォルトワークスペースのDatabricksクラスターでMLflowプロジェクトを実行するには、以下のコマンドを使用します。
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
<uri>がGitリポジトリのURI、MLflowプロジェクトを含むフォルダー、<json-new-cluster-spec>がnew_cluster structureを含むJSONドキュメントとなります。GitのURIはhttps://github.com/<repo>#<project-folder>の形式に従う必要があります。
クラスター設定のサンプルは以下の通りとなります。
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "i3.xlarge"
}
ワーカーノードにライブラリをインストールする必要がある場合には、“cluster specification”フォーマットを使用してください。wheelをDBFSにアップロードし、pypi依存関係として指定する必要があります。例を以下に示します。
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "i3.xlarge"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
重要!
- MLflowプロジェクトでは
.egg、.jarの依存関係はサポートされていません。
- Docker環境でのMLflowプロジェクトの実行はサポートされていません。
- DatabricksにおけるMLflowプロジェクトを実行する際には、新規クラスター設定を使用する必要があります。既存クラスターでのプロジェクト実行はサポートされていません。
SparkRの使用
MLflowプロジェクトの実行においてSparkRを使用するには、以下のようにお使いのプロジェクトコードの最初にSparkRをインストール、インポートを行う必要があります。
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
お使いのプロジェクトはSparkRセッションを初期化し、通常通りSparkRを使用します。
sparkR.session()
...
サンプル
このサンプルでは、エクスペリメントの作成、DatabricksクラスターでのMLflowチュートリアルプロジェクトの実行、ジョブ実行のアウトプットの参照、エクスペリメントのランの参照方法を説明します。
前提条件
-
pip install mlflowを用いてMLflowをインストールします。 - Databricks CLIをインストール、設定します。Databricksクラスターでジョブを実行するためにDatabricks CLIの認証機構が必要となります。
ステップ1: エクスペリメントの作成
- ワークスペースでCreate > MLflow Experimentを選択します。
- Nameフィールドに
Tutorialと入力します。 -
Createをクリックします。Experiment IDをメモします。この例では、
14622565となります。

ステップ2: MLflowチュートリアルプロジェクトの実行
以下のステップでは、環境変数MLFLOW_TRACKING_URIをセットアップし、プロジェクトを実行し、上でメモしたエクスペリメントにトレーニングパラメーター、メトリクス、トレーニングしたモデルを記録します。
-
Databricksワークスペースで
MLFLOW_TRACKING_URI環境変数を設定します。Bash
export MLFLOW_TRACKING_URI=databricks
1. MLflowチュートリアルプロジェクトを実行し、ワインモデルをトレーニングします。`<experiment-id>`を、上のステップでメモしたExperiment IDで置き換えます。
```bash:Bash
mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>
```
=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u ===
=== Uploading project to DBFS path /dbfs/mlflow-experiments//projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz ===
=== Finished uploading project to /dbfs/mlflow-experiments//projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz ===
=== Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks ===
=== Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... ===
=== Check the run's status at https://#job//run/1 ===
1. MLflowランのアウトプットの最後の行のURL`https://<databricks-instance>#job/<job-id>/run/1`をコピーします。
## ステップ3: Databricksジョブ実行の参照
1. Databricksジョブ実行のアウトプットを参照するために、ブラウザーに以前のステップのURLをオープンします。

## ステップ4: エクスペリメント、MLflowラン詳細の参照
1. Databricksワークスペースでエクスペリメントにナビゲートします。
1. エクスペリメントをクリックします。

1. ランの詳細を表示するためにDateカラムのリンクをクリックします。
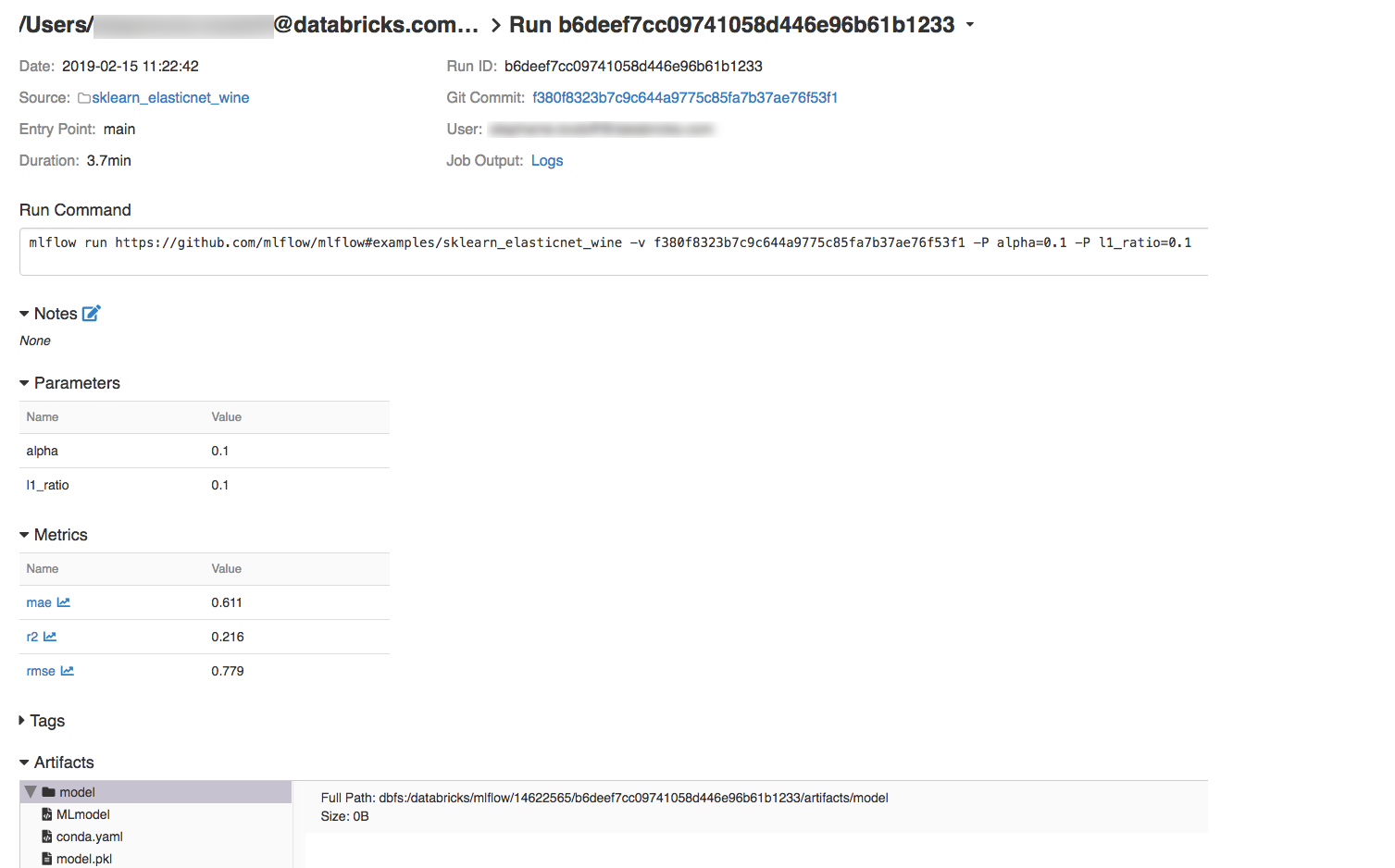
Job Outputフィールドの**Logs**リンクをクリックすることで、ランのログを参照することも可能です。
# リソース
MLflowプロジェクトのサンプルについては、お使いのコードにML機能を用意に取り込むことを狙いとした、すぐに利用できるプロジェクトのリポジトリがある[MLflow App Library](https://github.com/mlflow/mlflow-apps)を参照ください。
### Databricks 無料トライアル
[Databricks 無料トライアル](https://databricks.com/jp/try-databricks)