MLOps at Walgreens Boots Alliance With Databricks Lakehouse Platform - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
レイクハウスにおけるMLプラクティスの標準化: Walgreens MLOpsアクセラレータのご紹介
本記事では、増加するMLOpsの重要性と、Walgreens Boots Alliance (WBA)とDatabricksによって共同開発されたMLOpsアクセラレータを説明します。MLOpsアクセラレータは、MLプラクティスを標準化するために設計されており、MLモデルのプロダクション化に要する時間を削減し、データサイエンティストとMLエンジニアのコラボレーションを促進し、ビジネス価値と投資対効果を生み出します。本記事を通じて、DatabricksレイクハウスプラットフォームにおけるMLOpsのアプリケーションとどのようにWBAがMLOpsの標準化を行ったのか、皆様が彼らの成功を追体験できるのかを説明します。
MLOpsとは何でなぜ必要なのか?
DevOps+DataOps+ModelOpsから構成されるMLOpsは、企業がコード、データ、モデルを管理できる様にするための一連のプロセスと自動化処理です。

しかし、MLOpsを実践しようとすると課題に直面します。機械学習(ML)システム、モデル、コード、データのすべては時間と共に進化し、更新スケジュールやMLパイプラインにおける摩擦を生じさせます。また、データのドリフトはモデルのトレーニングを必要とし、モデルのパフォーマンスは時間と共に劣化します。さらに、データサイエンティストはデータセットの探索を続け、モデルを改善するためにさまざまなアプローチを適用するので、より良いパフォーマンスを示す新機能やモデルのファミリーを見つけ出すかもしれません。その後、コードを更新し、デプロイします。
成熟したMLOpsシステムには、MLパイプラインをテスト、デプロイする堅牢かつ自動化された継続的インテグレーション/継続的デプロイメント(CI/CD)システムと継続的トレーニング(CT)、継続的モニタリング(CM)が必要となります。モニタリングパイプラインは、モデルパフォーマンスの劣化を特定し、自動化された再トレーニングをトリガーします。
MLOpsのベストプラクティスによって、データサイエンティストは特徴量エンジニアリング、モデルアーキテクチャ、ハイパーパラメータに関するアイデアを迅速に試すことができ、新規パイプラインは自動でビルド、テストされ、プロダクション環境にデプロイされます。堅牢かつ自動化されたMLOpsシステムは、企業のAIイニシアチブをアイデアからビジネス価値のブーストまで拡張し、データとMLの費用対効果を確実なものとします。
WBAはレイクハウスを用いてどのようにMLとアナリティクスを加速したのか
最大の小売薬品業の一つであるWalgreensはヘルス・健康企業のリーディングカンパニーであり、自身のML、アナリティクスの要件を前進させるためにレイクハウスアーキテクチャに移行しました。Azure Databricksがデータプラットフォームとして選択され、ML、アナリティクス、レポーティングのユースケースにおいて、Delta Lakeがキュレーテッドデータとセマンティックデータのソースとなりました。
彼らのテクノロジーに加え、彼らがイノベーションをもたらす方法論も変化しました。トランスフォーメーション以前は、それぞれのビジネスユニットが独立してMLとアナリティクスに責任を持っていました。トランスフォーメーションの一部として、Walgreens Boots Alliance (WBA)はIT部門の下に、MLやアナリティクスを含むデータの活用を集中化する組織を立ち上げました。このプラットフォームによって、ビジネスのニーズのプロダクション化する助けとなり、発見をアクション可能なプロダクションツールに変化することを加速しました。
WalgreensでMLとアナリティクスのパワーを解き放ったレイクハウスの事例は多数存在しています。例えば、RxAnalyticsは、在庫レベルや特定の薬品カテゴリーや店舗における返品の予測に役立ちました。これは、コスト削減と顧客の需要のバランスにおいて重要なことです。また、Retail Working Capitalのようなプロジェクトによる小売サイドにおいても類似のMLアプリケーションが存在しています。
WBAのユースケースは、薬品、小売、金融、マーケティング、物流など多岐に渡っています。これらすべてのユースケースの中心にはDelta LakeとDatabricksが存在しています。これらの成功によって、組織全体でML開発を標準化するためのベストプラクティスを確立するMLOpsを共同開発し、プロジェクトの開始からプロダクションに要する時間を1年以上から数週間に削減しました。次では、WBAのMLOpsアクセラレータの設計上の選択に関して詳細を見ていきます。
デプロイコードパターンを理解する
MLOpsのデプロイメントパターンには、モデルのデプロイとコードのデプロイという2つのパターンが存在します。モデルデプロイにおいては、モデルのアーティファクトが環境を通じてプロモーションしていきます。しかし、これには、The Big Book of MLOpsで詳細を説明している様に、いくつかの制限があります。一方、コードのデプロイでは、リソースの設定やMLパイプラインのコードを含むコードを、MLシステム全体における単一の真の情報源として取り扱い、コードが環境をプロモーションしていきます。コードのデプロイは、すべてのMLパイプライン(特徴量生成、トレーニング、推論、モニタリングなど)の自動テスト、自動デプロイにCI/CDを使用します。これによって、以下の図のように、モデルはそれぞれの環境のトレーニングパイプラインを通じてフィッティングされることになります。まとめると、コードのデプロイは、パイプラインから生成されるモデルの再トレーニングとデプロイメントを自動化するMLパイプラインのコードをデプロイすることになります。
モニタリングパイプラインはプロダクションにおけるデータドリフト、モデルドリフトや、オンライン/オフラインデータの偏りを分析します。データのドリフトやモデルパフォーマンスの劣化が生じた際には、同じコードリポジトリにあるトレーニングパイプラインを更新されたデータセットに対して再実行し、新バージョンのモデルを生成するモデルの再トレーニングを実行します。モデル生成コードやデプロイメントの設定が更新されると、プルリクエストが送信され、CI/CDワークフローを起動します。

企業において、データサイエンティストによる開発環境やステージング環境からプロダクションデータへのアクセスを制限する際には、コードのデプロイによって、アクセスコントロールを考慮しつつプロダクションデータに対するトレーニングを行うことができます。データサイエンティストにとっての急峻な学習曲線と比較的複雑なリポジトリ構成がデメリットではありますが、長期で見ると、デプロイコードパターンはコラボレーションを促進し、MLパイプラインを本格運用するためのシームレスな自動化・再現可能なプロセスを実現することができます。
このデプロイコードパターンとそのメリットを説明するために、WBAのMLOpsアクセラレータとインフラストラクチャのデプロイメント、CICDワークフロー、MLパイプラインの実装をウォークスルーしていきましょう。
WBAアクセラレータの概要
まず最初にスタックを見ていきましょう。WBAは、インフラストラクチャをデプロイし、大規模にDatabricksワークスペースを配備するために、内製ツールを開発しました。WBAは、CI/CDとバージョン管理を行うために、それぞれAzure DevOpsとAzure Reposを活用しています。DatabricksとWBAとで共同開発されたMLOpsアクセラレータは、ノートブック、ライブラリ、ジョブ、initスクリプトなどをデプロイするために、Databricksワークスペースにフォーク、連携できるリポジトリです。事前定義済みのMLステップ、MLパイプラインを実行するノートブック、事前構築済みのCI/CD用Azureパイプラインを提供しており、実行するには設定ファイルを更新するだけです。DataOpsサイドでは、特徴量管理にDelta LakeとDatabricks Feature Storeを活用しています。モデル構築のエクスペリメントはMLflowによって追跡、管理されます。さらに、プロダクション環境のデータドリフトを監視し、実験プラットフォームを汎用的なものにするために、Databricksのプレビュー機能であるモデルモニタリングを導入しました。
以下の図に示す様に、このアクセラレータのリポジトリ構造は大きく3つのコンポーネントから構成されています: MLパイプライン、設定ファイル、CI/CDワークフローです。アクセラレータのリポジトリは、CI/CDワークフローに対応する環境のDatabricksワークスペースのそれぞれと同期されます。WBAでは、開発作業にProdofix、テストにQA、プロダクションにProdという名称を用いています。Azureリソースや他のインフラストラクチャは、WBA内製ツールのスイートによってサポート、管理されています。

WBAのMLOpsアクセラレータの構造
MLOpsユーザージャーニー
通常、ワークフロー全体には2つのタイプのチーム/ペルソナが関与します: MLエンジニアとデータサイエンティストです。以下のセクションでユーザージャーニーをウォークスルーしていきましょう。
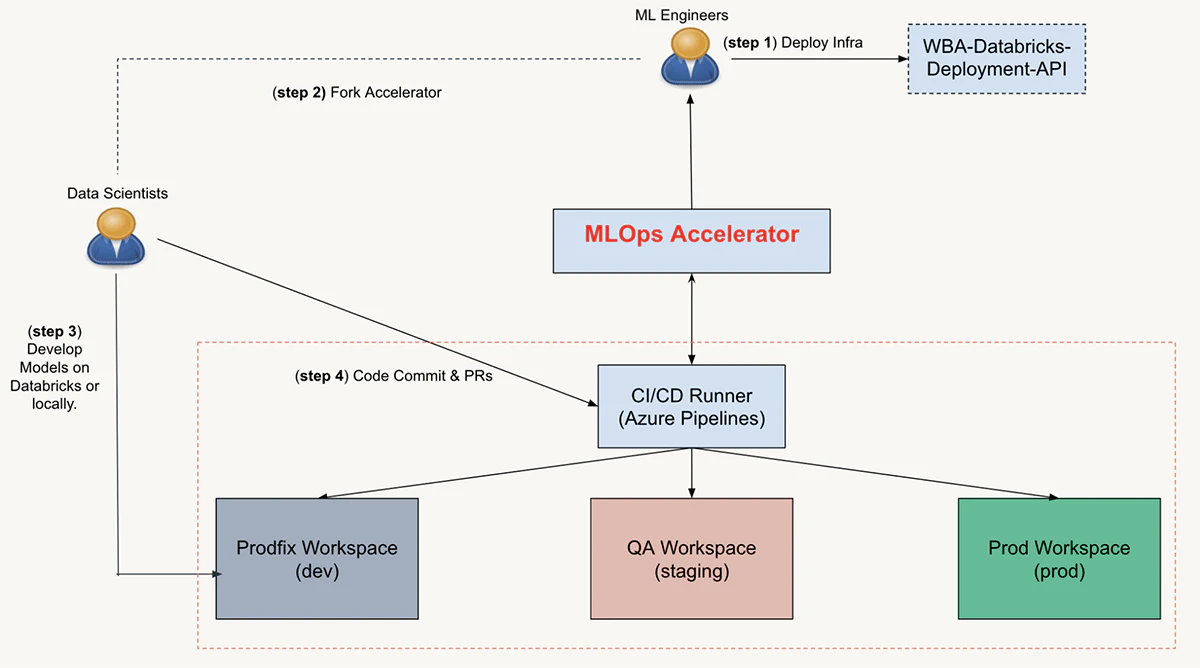
WBAのMLOpsアクセラレータのユーザージャーニー
プロジェクトをスタートするために、MLエンジニアはインフラストラクチャパイプラインをデプロイし、MLプロジェクトのリポジトリにMLOpsアクセラレータリポジトリをフォークし、リポジトリをデータサイエンスチームに共有することで、MLプロジェクトのリソースとリポジトリの初期化を行います。
プロジェクトリポジトリの準備ができたら、データサイエンティストはすぐにMLモジュールやノートブックでのイテレーションをスタートします。コミット、PR、コードのマージによって、ユニットテスト、インテグレーションのCI/CDランナーを起動し、最終的なデプロイを行います。
MLパイプラインがデプロイされると、MLエンジニアは設定ファイルへの変更をコミットし、PRをマージすることで、バッチ推論のスケジューリングジョブやクラスター設定のようなデプロイメンントの設定を更新することができます。コードの変更と同じ様に、設定ファイルへの変更はDatabricksワークスペース内のアセットを再デプロイするために、対応するCI/CDワークフローを起動します。
レイクハウスインフラストラクチャの管理
MLOpsアクセラレータは、すべてのAzure、Databricksのリソースを作成、更新、設定するインフラストラクチャシステム上に構築されています。このセクションでは、ユーザージャーニーの最初のステップであるプロジェクトリソースの初期化を実行するシステムを説明します。適切なツールを用いることで、それぞれのMLプロジェクトごとにAzure、Databricksのリソースの配備を自動化することができます。
Azureリソースのオーケストレーション
WBAでは、Azureに対するすべてのデプロイメントは、必要なAzureリソースマネジメント(ARM)のテンプレートとパラメーターファイルを作成する中央のチームによって管理されています。また、彼らはこれらのテンプレートのデプロイメントパイプラインを維持し、アクセスの許可を行います。
WBAは、一箇所でプロジェクトが必要とするすべてのリソースと設定を収集するための、環境固有のYAML設定ファイルを使用するDevelopment APIというFastAPIマイクロサービスを構築しました。Development APIはYAML設定が変更されたかどうか、そしてリソースを更新する必要があるかどうかを追跡します。それぞれのリソースタイプでは、中央のデプロイメントパイプラインのアクティビティを拡張するための追加の自動化を含む、デプロイ後の設定フックを活用することができます。
Databricksの設定
DatabricksワークスペースをデプロイするためにDeployment APIを使用した後は、空の状態です。プロジェクトの要件に応じてDatabricksワークスペースが設定される様にするために、Development APIはDatabricksワークスペースの設定をアップデートを強制するマイクロサービスに送信するデプロイメント後設定フックを活用します。
Databricksワークスペース設定の最初の観点は、DatabricksのSCIMインテグレーションを用いたDatabricksユーザー、グループの同期です。マイクロサービスは、アクセスできる様に設定されたグループのメンバーシップに基づいて、ユーザーの追加・削除を行います。それぞれのグループに対して、クラスター作成権限やDatabricks SQLへのアクセスなどのきめ細かいアクセス権限を提供します。SCIMインテグレーションやアクセス権に加え、マイクロサービスはデフォルトクラスターポリシー、クラスターポリシーのカスタマイズ、クラスターの作成、内製のpythonライブラリをインストールするためのinitスクリプトの定義などを行います。
点をつなぐ
Deployment API、Databricks自動設定、MLOpsアクセラレータのすべては、プロジェクトが迅速にイテレーション、テスト、プロダクション化を行える様に相互に連携して動作します。インフラストラクチャがデプロイされると、MLエンジニアはプロジェクトリポジトリ設定ファイルに情報(ワークスペースURL、ユーザーグループ、ストレージアカウント名など)を入力します。この情報は、事前定義済みのCI/CDパイプラインやMLリソース定義から参照されることになります。
Azure Pipelinesによるデプロイメントの自動化
コードのプロモーションプロセスの概要を以下に示しています。gitのブランチ作成のスタイルとCI/CDワークフローは主張すべきところですが、それぞれのユースケースに応じて調整することが可能です。WBAにおけるさまざまなプロジェクトの性質上、それぞれのチームは少しずつ異なる方法でオペレーションを行うことがあります。アクセラレータからフォークしたプロジェクトを目的に応じてカスタマイズし、コンポーネントを選択することは自由です。

MLOpsアーキテクチャデザインとCI/CDワークフロー
コードプロモーションのワークフロー
プロジェクトオーナーは、プロダクションブランチ(我々のサンプルアーキテクチャではmasterブランチ)を定義することでスタートします。データサイエンティストはProdfixワークスペースの非プロダクションブランチですべてのML開発を行います。masterブランチにPRを送信する前に、データサイエンティストは開発ワークスペースでテストやバッチジョブデプロイメントを起動することができます。コードをプロダクションに配備する準備ができたらPRが作成され、QA環境で完全なるテストスイートが実行されます。テストに通過し、レビュアーがPRを承認するとデプロイメントワークフローが呼び出されます。Prodワークスペースでは、最終的なモデルを登録するためにトレーニングパイプラインが実行され、推論パイプライン、モニタリングパイプラインがデプロイされます。以下でそれぞれの環境の詳細を見ていきます。
- Prodfix: Prodfix環境で、探索的データ分析、モデル探索、トレーニング、推論パイプラインの全てが開発される必要があります。また、データサイエンティストはモデルの根拠やどのメトリクスを監視するのがベストなのかを理解しているので、データサイエンティストがモニタリング設定の設計やメトリクスの分析を行うべきです。
-
QA: QAでユニットテストとインテグレーションテストが行われます。インテグレーションテストの一部として、モニターの作成と分析パイプラインはテストされる必要があります。サンプルのインテグレーションテストのDAGを以下に示しています。QAにトレーニングパイプラインや推論パイプラインをデプロイすることはオプションとなります。

- Prod: CDワークフローを用いて、トレーニング、推論、モニタリングパイプラインがプロダクション環境にデプロイされます。ノートブックワークフローを用いてトレーニングと推論は繰り返しジョブとしてスケジューリングされます。モニタリングパイプラインはDelta Live Table (DLT)パイプラインとなります。
ワークスペースリソースの管理
コードに加えて、MLflowエクスペリメント、モデルのようなMLリソースやジョブが設定され、CI/CDによってプロモートされます。インテグレーションテストはジョブとして実行されるので、それぞれのインテグレーションテストごとにジョブ定義を構築する必要があります。また、これによって、デバッグのためにテスト結果を調査し、過去のテストを整理する助けになります。コードリポジトリでは、DLTパイプラインとジョブの仕様はYAMLファイルとして保存されます。上述した通り、アクセラレータではワークスペースリソースのアクセス管理にWBA内製のツールを使用しています。DLT、ジョブ、テスト仕様はDatabrikcs APIのペイロードとして指定されますが、カスタムのラッパーライブラリによって使用されます。アクセス権管理は、CICD/configsフォルダにある環境プロファイルYAMLファイルで設定されます。
ハイレベルのプロジェクト構成を以下に示します。
├── cicd < CICD configurations
│ ├── configs
│ └── main-azure-pipeline.yml < azure pipeline
├── delta_live_tables < DLT specifications, each DLT must have a corresponding YAML file
├── init_scripts < cluster init scripts
├── jobs < job specifications, each job to be deployed must have a corresponding YAML file
├── libraries < custom libraries (wheel files) not included in MLR
├── src < ML pipelines and notebooks
└── tests < test specifications, each test is a job-run-submit in the Databricks workspace
例として、以下に/jobsフォルダーにある簡素化したtraining.ymlファイルを示します。ここでは、トレーニングパイプラインとしてtrainingというノートブックジョブをデプロイし、US中央時の毎日深夜に11.0MLランタイムと1ワーカーノードを用いてTrainノートブックを実行する様に定義しています。
name: training
email_notifications:
no_alert_for_skipped_runs: false
timeout_seconds: 600
schedule:
quartz_cron_expression: 0 0 0 * * ?
timezone_id: US/Central
pause_status: UNPAUSED
max_concurrent_runs: 1
tasks:
- task_key: training
notebook_task:
notebook_path: '{REPO_PATH}/src/notebooks/Train'
new_cluster:
spark_version: 11.0.x-cpu-ml-scala2.12
node_type_id: 'Standard_D3_v2'
num_workers: 1
timeout_seconds: 600
email_notifications: {}
description: run model training
以下にリポジトリを同期するステップを示します。
- DatabricksワークスペースのReposにリポジトリをインポート
- 設定プロファイルに基づいて指定のMLflowエクスペリメントを作成し、アクセス権を付与
- 設定プロファイルに基づいてMLflowモデルレジストリにモデルを作成し、アクセス権を付与
- テストの実行(テストではMLflowエクスペリメントとモデルレジストリを使用するので、ステップ1-3の後に実行される必要があります。いかなるリソースをデプロイする前にテストは実行されなくてなりません)
- DLTパイプラインの作成
- すべてのジョブの作成
- 使われなくなったジョブのクリーンアップ
MLパイプラインの標準化
事前定義済みMLパイプラインを持つことで、データサイエンティストは再利用可能かつ再現可能なMLコードを作成することができます。一般的なMLワークフローは、データ取り込み、特徴量生成、トレーニング、評価、デプロイメント、予測の逐次的なプロセスです。MLOpsアクセラレータリポジトリでは、これらのステップはモジュール化されており、Databricksノートブックで使用されます(詳細についてはReposのGit連携をご覧ください)。データサイエンティストはユースケースに合わせてステップをカスタマイズすることができます。ドライバーノートブックはパイプラインの引数とオーケストレーションロジックを定義しています。アクセラレータには、トレーニングパイプライン、推論パイプライン、モニタリングパイプラインが含まれています。
├── src
│ ├── datasets
│ ├── notebooks
│ │ ├── Train.py
│ │ ├── Batch-Inference.py
│ │ ├── MonitorAnalysis.py
│ ├── steps < python module
│ │ ├── __init__.py
│ │ ├── utils.py < utility functions
│ │ ├── ingest.py < load raw dataset
│ │ ├── featurize.py < generate features
│ │ ├── create_feature_table.py < write feature tables
│ │ ├── featurelookup.py < lookup features in FS
│ │ ├── train.py < train and log model to MLflow
│ │ ├── evaluate.py < evaluation
│ │ ├── predict.py < predictions
│ │ ├── deploy.py < promote the registered model to Staging/Production
│ │ └── main.py
│ └── tests < unit tests
データとアーティファクトの管理
MLシステムにおいてはデータとモデルは定常的に進化するので、次にMLパイプラインのデータとアーティファクト管理について話しましょう。パイプラインはDeltaとMLflowを中心としています。Deltaフォーマットで入出力データを強制し、実験トライアルとモデルアーティファクトを記録するためにMLflowを用いています。
WBA MLOpsアクセラレータにおいては、モデルの前段のリネージュ(データソースや特徴量からモデルへ)と後段のリネージュ(モデルからデプロイメントエンドポイントへ)の両方を追跡するために、DeltaとMLflowをベースとしたDatabricks Feature Storeも活用しています。事前に計算された特徴量は、プロジェクト固有の特徴量テーブルに書き込まれ、モデルトレーニングのためにコンテキストの特徴量と一緒に活用されます。推論プロセスにおいては、Databricks Feature Store APIから利用できるバッチスコアリング機能を使用しています。このようにすることで、プロダクションのモデルは常に最新バージョンの特徴量をロードする様になります。
パイプラインのオーケストレーション
上述した通り、トレーニングと推論はバッチジョブですが、モニタリングはDLTパイプラインとしてデプロイされます。トレーニングパイプラインは最初にADLSに格納されているDeltaテーブルからデータをロードし、特徴量エンジニアリングを行い、ワークスペースのFeature Storeに特徴量を書き込みます。そして、特徴量テーブルからトレーニングデータセットを生成し、トレーニングデータセットにMLモデルをフィットさせ、Feature Store APIを用いてモデルを記録します。トレーニングパイプラインの最後のステップはモデルの検証です。モデルが検証を通過すると、対応するステージ(QA環境はStaging、Prod環境はProduction)にモデルを自動でプロモートします。
推論パイプラインはモデルレジストリからモデルをロードし、予測を行うためにfs.score_batch()を呼び出します。ユーザーは、データのスコアリングに完全な特徴量セットを提供する必要はなく、単に特徴量テーブルのキーを指定するだけで構いません。Feature Store APIは計算済みの特徴量を検索し、スコアリングのためにコンテキストの特徴量と結合します。

Databricks Feature Storeによるトレーニングと推論
開発ステージでは、データサイエンティストはモデルのパフォーマンスを評価するために追跡すべきメトリクス(全カラムのmin、max、median、集計時間ウィンドウ、モデル品質メトリクス、ドリフトメトリクスなど)がどれであるのかといったモデルモニタリングの設定を決定します。
プロダクション環境では、推論リクエストと対応する予測結果が、モニタリングプロセスと関連づけられたマネージドDeltaテーブルに記録されます。通常、真のラベルは後で別の取り込みパイプラインから到着します。ラベルが利用できる様になると、リクエストテーブルに追加され、モデル評価の分析が実行されます。すべてのモニタリングメトリクスは、レイクハウスにある別のDeltaテーブルに格納され、Databricks SQLのダッシュボードで可視化されます。選択したドリフトメトリクスの閾値に応じてアラートが設定されます。また、モニタリングフレームワークによって、将来的なユースケースのためのモデルのA/Bテスト、公正性、バイアスの研究が可能となります。
まとめ
MLOpsは、業界においてエンドツーエンドの大規模なMLサイクルを自動化するツールを開発している成長中の領域です。DevOpsとソフトウェア開発のベストプラクティスを組み合わせていることに加え、MLOpsにはDataOpsとModelOpsも関連しています。WBAとDatabricksでは、コードデプロイパターンに沿ったMLOpsアクセラレータを共同開発しました。これは、ML開発のDay 1のプロジェクトの初期化からのガードレールを提供し、MLパイプラインのプロダクション化に至る時間を数年から数週間に劇的に削減します。このアクセラレータでは、MLライフサイクル管理のためにDelta Lake、Feature Store、MLflowの様なツールを活用しています。これらのツールは元からMLOpsをサポートしています。インフラストラクチャ、リソース管理においては、アクセラレータはWBA内部のスタックをベースにしています。Terraformのようなオープンソースプラットフォームも同様の機能を提供しています。アクセラレータの複雑性を恐れないでください。本書で議論されたプロダクションMLベストプラクティスに興味があるのであれば、Databricksでプロダクションに活用できるMLOpsソリューションを作成するためのリファレンス実装を提供します。リファレンス実装のリポジトリにアクセスするには、こちらからリクエストしてください。
WBAにおけるエキサイティングなジャーニーにジョインすることに興味があるのであれば、Working at WBAをチェックしてみてください。PeterはPrincipal MLOps Engineerを採用中です!
著者に関して
原文を参照ください。