Using Structured Streaming with Delta Sharing in Unity Catalog - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Azure、AWS、GCPにおけるDelta Sharingの構造化ストリーミングサポートのGAを発表できることを嬉しく思っています!この新機能によって、Databricksレイクハウスプラットフォームのデータ受信者はUnity Catalogを通じて共有されるDeltaテーブルからの変更ストリームを受け取ることができるようになります。
Data提供者は自身のdata-as-a-serviceを容易にスケールするために本機能を活用し、大規模データセットを共有する際のオペレーションコストを削減し、新規データが到着すると即座の検証、品質チェックによってデータ品質を改善し、リアルタイムのデータデリバリーによって顧客サービスを改善します。同様に、データ受信者は共有されたデータセットから最新の変更ストリームを受け取ることができ、大規模バッチデータを処理するためのインフラストラクチャコストを削減し、最先端のリアルタイムデータアプリケーションの基盤を構築することができます。この新機能によって、様々な業界におけるデータ受信者は以下のようなメリットを享受することができます:
- 小売: データアナリストは季節のファンションラインに対する最新の数値をストリーミングし、BIレポートの形でビジネス洞察を表現することができます。
- ヘルスケアライフサイエンス: ヘルスケアの実践者は、以上を特定するために心電図のデータをMLモデルにストリーミングすることができます。
- 製造: ビル管理チームはスマートサーモスタットのデータをストリーミングし、昼夜の冷暖房ユニットを効率的にオンオフするのはいつなのかを特定できるようになります。
多くの場合、バッチ処理が堅牢で実装が容易であることから、データチームはデータを処理するためにバッチで実行されるデータパイプラインに依存しています。しかし、現在、企業はリアルタイムの意思決定を行うために、到着する最新のデータを必要としています。構造化ストリーミングは、リアルタイム処理をシンプルにするだけではなく、大量のバッチ処理を数個のストリーミングジョブに削減することで、バッチ処理をシンプルにすることができます。構造化ストリーミングは同じデータフレームAPIを実装しているので、バッチデータパイプラインをストリーミングに変換するのは簡単です。
このブログ記事では、金融業界のサンプルを用いて、ニアリアルタイムで自身のデータのビジネス価値を最大化するために、企業がどのようにDelta Sharingと構造化ストリーミングを活用できるのかを探索します。また、リアルタイムデータアプリケーションを構築するために、Databricksワークフローのようなその他の補完的な機能を用いてどのようにDelta SharingとUnity Catalogを組み合わせられるのかを検証します。
構造化ストリーミングのサポート
おそらく過去数ヶ月でDelta Sharingに最も求められた機能は、構造化ストリーミングにおけるソースとしての共有Deltaテーブルの活用のサポートであったのでしょう。この新機能によって、データ受信者はDatabricksレイクハウスプラットフォームのUnity Catalogを通じて共有されたDetlaテーブルを用いて、リアルタイムアプリケーションを構築できるようになります。
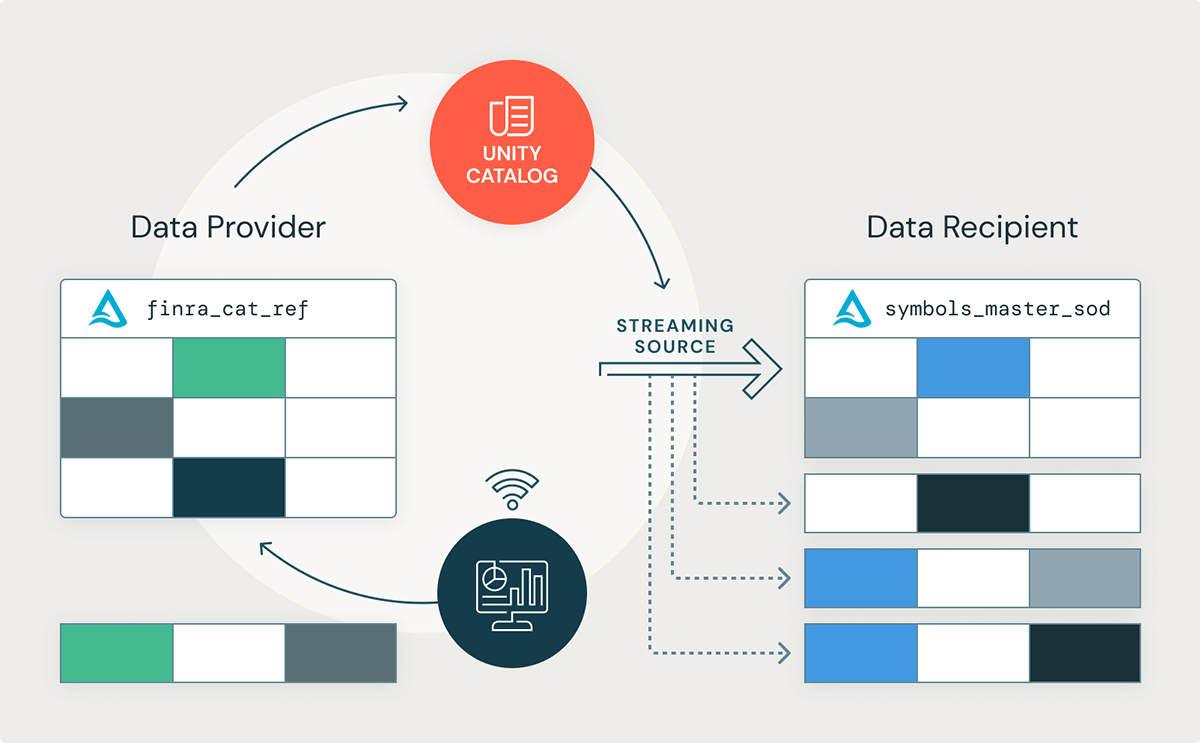
Delta Sharingでは構造化ストリーミングのソースとして共有Deltaテーブルを活用できるようになりました
構造化ストリーミングを用いたDelta Sharingの使い方
データ受信者がリアルタイムの取引の洞察を得るために、どのように公開されている株式シンボル情報をストリーミングするのかを詳細に見ていきましょう。本書では、U.S. National Market System (NMS)で取引されているすべての株式や有価証券のリストであるFINRA CAT Reportable Equity Securities Symbol Masterを使用します。構造化ストリーミングはリアルタイムアプリケーションの構築で活用できますが、データがそれほど頻繁に到着しないシナリオでも有効です。シンプルなノートブックのデモンストレーションとして、1日に3回アップデートされるデータセットを使用します。最初は取引日の開始時点(SOD)、日中の全ての変更を反映するための二番目の更新、そして、三番目は取引日の最後(EOD)です。週末やアメリカに休日にアップデートはありません
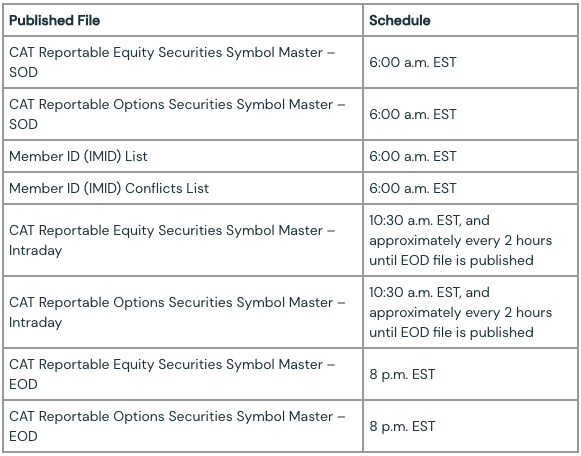
テーブル 1.1 - FINRA CATとメンバーリファレンスデータは営業日に公開されます。週末やアメリカの休日にはアップデートされません。
データ提供者の視点から: Databricksワークフローを用いたCATデータの取り込み
Databricksレイクハウスプラットフォームの主要なメリットの一つは、Deltaテーブルに対して非常に簡単に連続的な変更のストリーミングを反映できるということです。取引日の最初(SOD)にFINRA CAT有価証券シンボルファイルをダウンロードするシンプルなPythonタスクを定義するところからスタートします。そして、Databricksファイルシステムに高アキされているファイルを保存します。
# First, we'll download the FINRA CAT Equity Securities Symbols file for today's Start of Day
request = requests.get(catReferenceDataURL, stream=True, allow_redirects=True)
# Next, save the published file to a temp directory on the Databricks filesystem
with open(dbfsPath, "wb") as binary_file:
for chunk in request.iter_content(chunk_size=2048):
if chunk:
binary_file.write(chunk)
binary_file.flush()
コード 1.1 - 取引日の最初にFINRA CAT有価証券シンボルファイルをダウンロードするシンプルなPythonタスク
デモンストレーションのために、更新ファイルが公開されるたびに生のファイルを取り込み、Delta Lakeテーブルのブロンズテーブルを継続的にアップデートする関数も定義します。
# Finally, we'll ingest the latest equity symbols CSV file into a "bronze" Delta table
def load_CAT_reference_data():
return (
spark.read.option("header", "true")
.schema(catEquitySymbolsMasterSchema)
.option("delimiter", "|")
.format("csv")
.load(localFilePath)
.withColumn("catReferenceDataType", lit("FINRACATReportableEquitySecurities_SOD"))
.withColumn("currentDate", current_date())
.withColumn("currentTimestamp", current_timestamp())
.withColumn("compositeKey", concat_ws(".", "symbol", "listingExchange"))
)
コード 1.2 - 毎日の取引日の最初にFINRA CAT有価証券シンボルファイルがDeltaテーブルに取り込まれます。
処理が開始すると、Databricksワークフローは毎日の取引日の最初にCAT有価証券シンボルデータセットを作成し始めます。
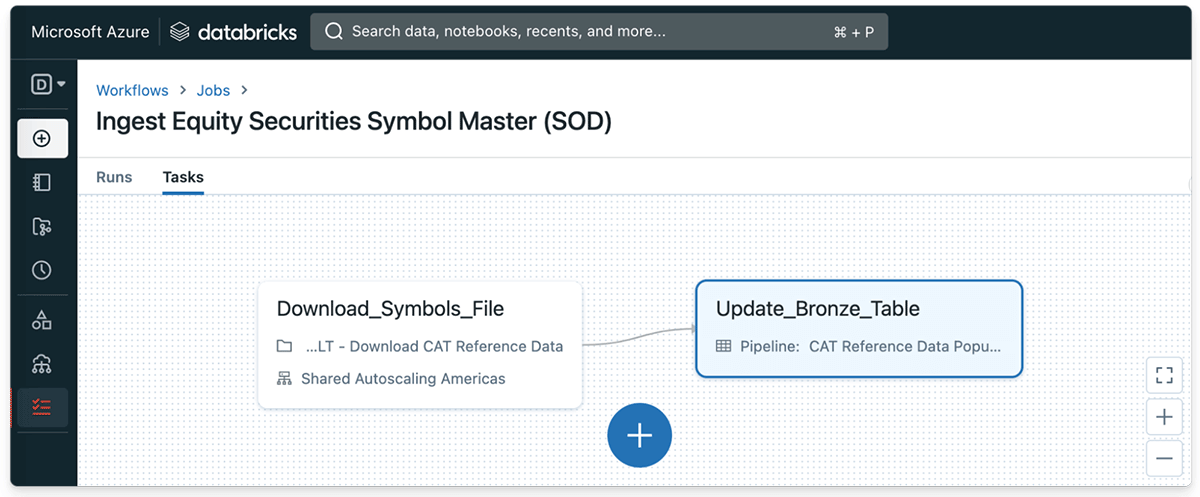
図1.1 - 取引日の最初にCAT有価証券シンボルマスターファイル(CSV)が日時で取り込まれ、ブロンズDeltaテーブルに挿入されます。
データ提供者の視点から: ストリーミングソースとしてDeltaテーブルを共有
これで、取引日ごとにシンボルファイルをへのアップデートを取り込むストリーミングパイプラインを作成したので、データ受信者にDeltaテーブルを共有するためにDelta Sharingを活用することができます。DatabricksレイクハウスプラットフォームでDeltaの共有を作成するのは、ボタンの数クリック、あるいはSQL構文が好きなのであれば単一のSQL文で実現できます。
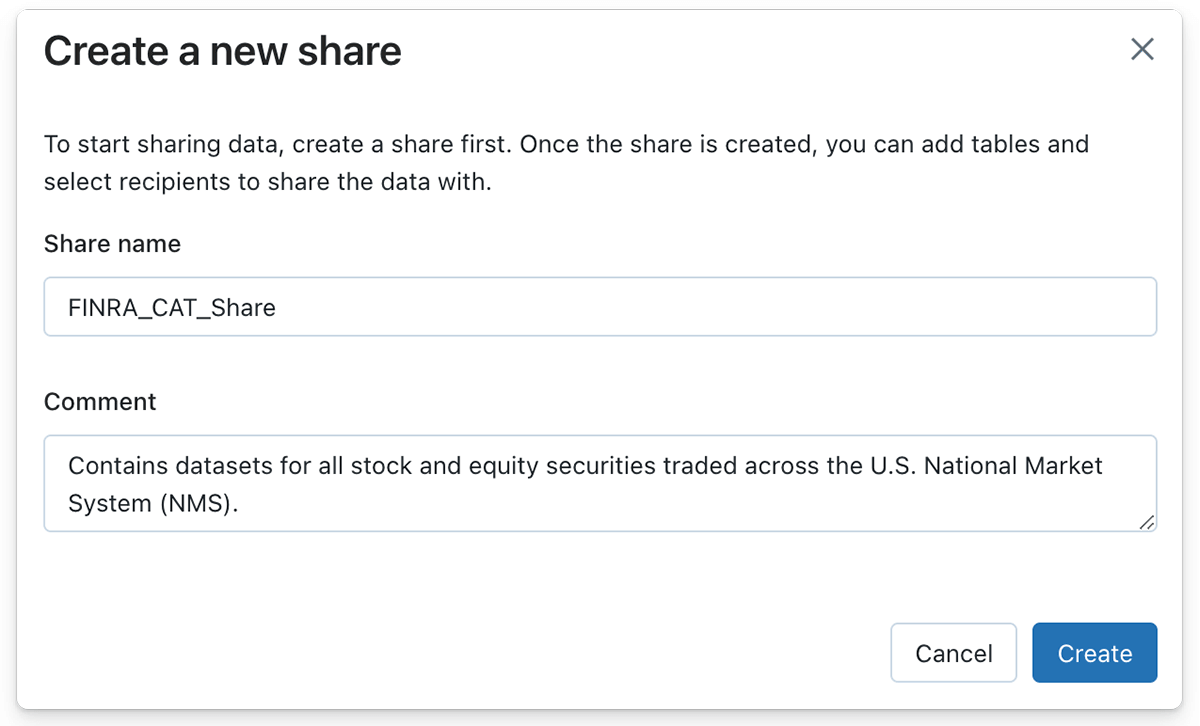
図 1.2 - データ提供者は最初に、後で共有Deltaテーブルを保持することになるDelta共有を作成します。
同様に、データ提供者はManage assetsボタン、Edit tablesボタンをクリックすることで1つ以上のテーブルをDelta共有に含めることができます。この場合、有価証券シンボルデータを格納するブロンズDeltaテーブルを共有オブジェクトに追加します。
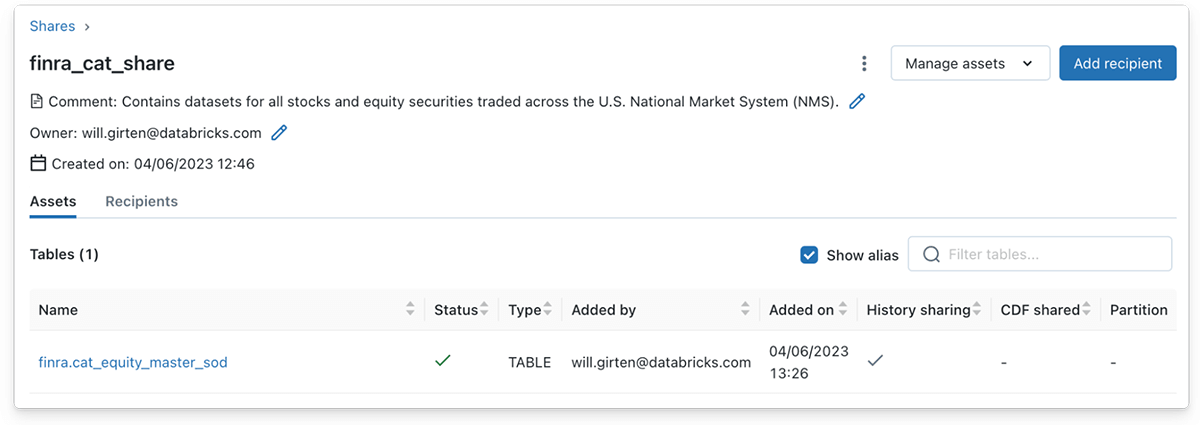
図 1.3 - Delta Sharingのデータ提供者は、通常のDeltaテーブルのようにストリーミングテーブルをDelta共有に追加することができます。
構造化ストリーミングを用いた読み込みをサポートするためには、Deltaテーブルの全ての履歴を共有する必要があることに注意してください。共有にDeltaテーブルを追加するDatabricksのUIを用いる際に、デフォルトで履歴の共有は有効になっています。しかし、SQL構文を使用する際には、履歴共有を明示的に指定しなくてはなりません。
/**
A Delta table must be shared with history in order to support
Spark Structured Stream reads.
*/
ALTER SHARE finra_cat_share
ADD TABLE finance_catalog.finra.symbols_master
WITH HISTORY;
コード 1.4 - SQL構文を使用する際、構造化ストリーミングの読み込みをサポートするためにDeltaテーブルの履歴を明示的に指定しなくてはなりません。
データ受信者の視点から: 共有Deltaテーブルのストリーミング
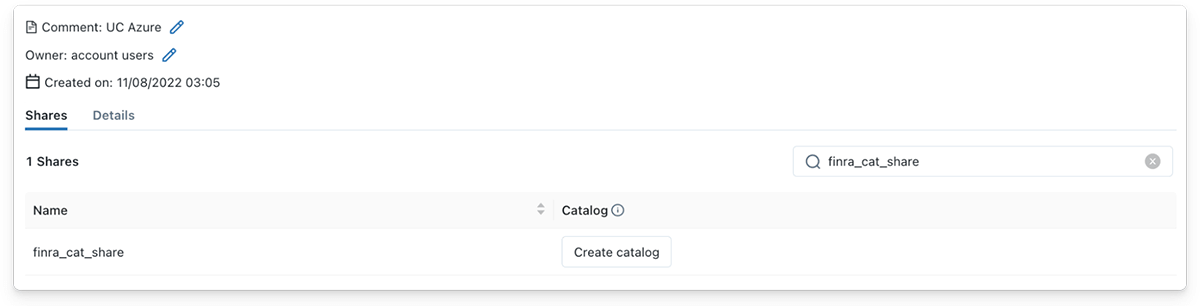
図 1.4 - データ受信者はDelta共有から新規カタログを作成することができます。
データ受信者として、共有Deltaテーブルからストリーミングを読み込むことはとてもシンプルです!データ受信者にDelta共有が共有されると、受信者は即座にUnity Catalogで提供者詳細の配下の共有を参照できるようになります。そのあとで、データ受信者はCreate Catalogボタンをクリックし、意味のある名前を指定し、共有のコンテンツを説明するオプションのコメントを追加します。
データ受信者は、Databricksランタイム12.1以降を用いたUnity Catalogを通じて共有されたDeltaテーブルからストリームを読み込むことができます。このサンプルでは、Databricks 12.2 LTS RuntimeがインストールされたDatabricksクラスターを使用しました。データ受信者は、deltaSharingデータソースと共有テーブルの名前を指定することで、Spark構造化ストリームとして共有Deltaテーブルを読み込むことができます。
# Stream from the shared Delta table that's been created with a new Catalog in Unity Catalog
equity_master_stream = (spark.readStream
.format('deltaSharing')
.table('finra_cat_catalog.finra.cat_equity_master'))
equity_master_stream.display()
コード 1.4 - データ受信者はdeltaSharingデータソースを用いて共有Deltaテーブルからストリームを読み込むことができます。
追加のサンプルとして、共有CAT有価証券シンボルマスターデータセットと、受信者のUnity Catalogに格納されている株価履歴のデータセットを結合してみましょう。特定の株価ティッカーシンボルの週次の株価履歴を取得するユーティリティ関数を定義します。
import yfinance as yf
import pyspark.sql.functions as F
def get_weekly_stock_prices(symbol: str):
""" Scrapes the stock price history of a ticker symbol over the last 1 week.
arguments:
symbol (String) - The target stock symbol, typically a 3-4 letter abbreviation.
returns:
(Spark DataFrame) - The current price of the provided ticker symbol.
"""
ticker = yf.Ticker(symbol)
# Retrieve the last recorded stock price in the last week
current_stock_price = ticker.history(period="1wk")
# Convert to a Spark DataFrame
df = spark.createDataFrame(current_stock_price)
# Select only columns relevant to stock price and add an event processing timestamp
event_ts = str(current_stock_price.index[0])
df = (df.withColumn("Event_Ts", F.lit(event_ts))
.withColumn("Symbol", F.lit(symbol))
.select(
F.col("Symbol"), F.col("Open"), F.col("High"), F.col("Low"), F.col("Close"),
F.col("Volume"), F.col("Event_Ts").cast("timestamp"))
)
# Return the latest price information
return df
次に、3つのテック大企業、Apple Inc. (AAPL)、Microsoft Corporation (MSFT)、Invidia Corporation (NVDA)の株価の履歴と有価証券と株のマスターデータストリームをjoinします。
# Grab the weekly price histories for three major tech stocks
aapl_stock_prices = get_weekly_stock_prices('AAPL')
msft_stock_prices = get_weekly_stock_prices('MSFT')
nvidia_stock_prices = get_weekly_stock_prices('NVDA')
all_stock_prices = aapl_stock_prices.union(msft_stock_prices).union(nvidia_stock_prices)
# Join the stock price histories with the equity symbols master stream
symbols_master = spark.readStream.format('deltaSharing').table('finra_catalog.finra.cat_equity_master')
(symbols_master.join(all_stock_prices, on="symbol", how="inner")
.select("symbol", "issueName", "listingExchange", "testIssueFlag", "catReferenceDataType",
"Open", "High", "Low", "Close", "Volume", "event_ts")
).display()
最後に、データ受信者はオプションで宛先となるシンクを追加し、ストリーミングクエリーをスタートすることができます。
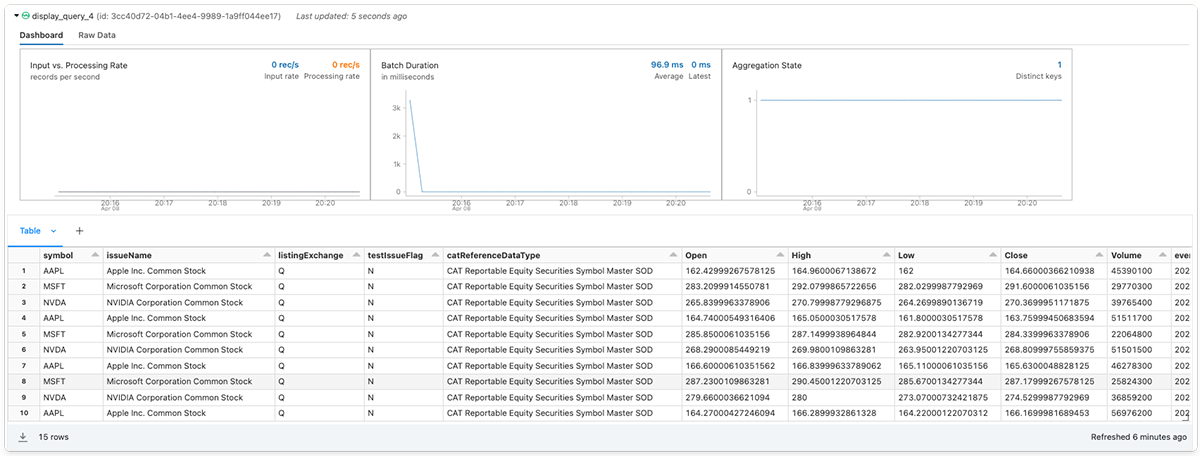
図 1.6 - データ受信者は、Spark構造化ストリームとして共有Deltaテーブルを読み込むことができます。
DatabricksでDelta Sharingを使い始める
企業がニアリアルタイムで自分たちのデータからのビジネス価値を最大化するために、どのようにDelta Sharingを活用できるのかという、このサンプルを楽しんでいただけたら幸いです。
Delta Sharingを使い始めたいと思っていても、どこからスタートしたらわかりませんか?すでにDatabricksを利用されているのであれば、Delta Sharingのガイド(AWS | Azure | GCP)に従ってください。この機能に含まれる設定のオプションについてはドキュメントを参照ください。まだ、Databricksを利用されていないのでしたら、プレミアムあるいはエンタープライズプランでフリートライアルにサインアップしてください。
クレジット
Abhijit Chakankar、Lin Zhou、Shixiong Zhuを含むこのリリースに貢献してくれた皆さんに感謝の意を表します。
リソース
- 添付ノートブック
- Learn about Data Sharing and Collaboration with Databricks Lakehouse
- Data, analytics and AI governance on the Lakehouse