こちらを参考にさせていただきながら。
他にもこちらの記事を参考にさせていただきました。
ライブラリのインストール
%pip install sentencepiece==0.1.97 datasets evaluate accelerate
スクリプトをクローンしておきます。
%sh
git clone https://github.com/huggingface/transformers
ソースからtransformersをインストールしろと言われたのでインストールします。
%pip install git+https://github.com/huggingface/transformers
MLflowトラッキングサーバーの設定
DatabricksにはMLflowがインテグレーションされているので、適切な設定を行えばシェルによるトレーニングもトラッキングできます。
Hugging FaceとDeepSpeedによる大規模言語モデルのファインチューニング
MLFLOW_EXPERIMENT_NAMEはMLflowエクスペリメントのパスなので適宜変更してください。
Python
import os
os.environ['DATABRICKS_TOKEN'] = dbutils.notebook.entry_point.\
getDbutils().notebook().getContext().apiToken().get()
os.environ['DATABRICKS_HOST'] = "https://" + spark.conf.get("spark.databricks.workspaceUrl")
os.environ['MLFLOW_EXPERIMENT_NAME'] = "/Users/takaaki.yayoi@databricks.com/20230422_rinna/japanese-gpt2-medium"
os.environ['MLFLOW_FLATTEN_PARAMS'] = "true"
ファインチューニング
データは/dbfs/FileStore/shared_uploads/takaaki.yayoi@databricks.com/dolly/taka_qiita.csvにあるものを使用しています。モデルはrinna/japanese-gpt2-mediumを使用しています。output_dirにはモデルの保存先を指定します。
%sh
python ./transformers/examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path=rinna/japanese-gpt2-medium \
--train_file=/dbfs/FileStore/shared_uploads/takaaki.yayoi@databricks.com/dolly/taka_qiita.csv \
--do_train \
--num_train_epochs=3 \
--save_steps=10000 \
--block_size 512 \
--save_total_limit=3 \
--per_device_train_batch_size=1 \
--output_dir=/dbfs/tmp/takaaki.yayoi@databricks.com/rinna/output/ \
--overwrite_output_dir \
--use_fast_tokenizer=False
今回使用したGPUクラスターでは2.5時間程度かかりました。DeepSpeedをも使いこなせるようにならなくてはです。
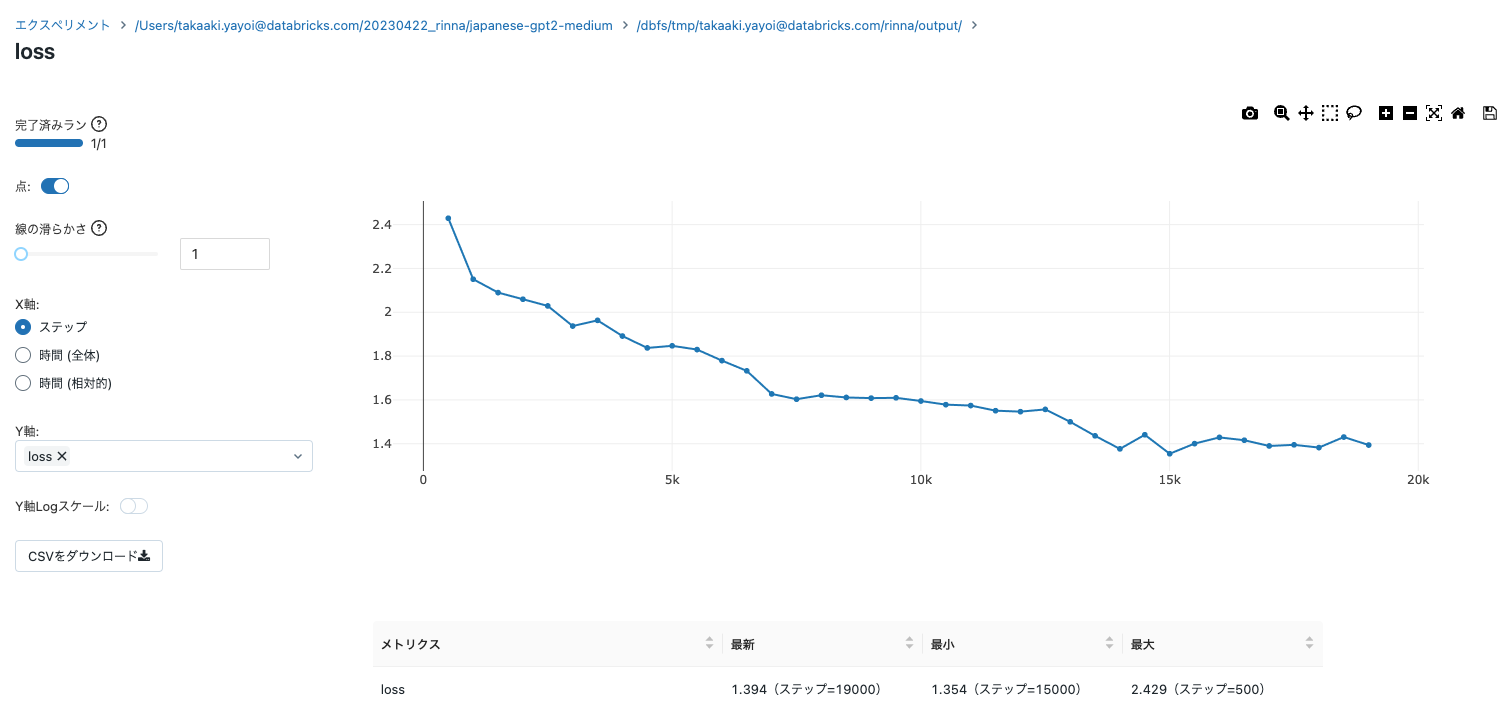
なお、エクスペリメントでトラッキングされるので、lossをリアルタイムで確認できます。便利ですね。
%fs
ls /tmp/takaaki.yayoi@databricks.com/rinna/output/
DBFSに永続化しているので、クラスターを停止してもモデルが消えることはありません。
推論
保存したモデルをロードします。
Python
from transformers import T5Tokenizer, AutoModelForCausalLM
tokenizer = T5Tokenizer.from_pretrained("/dbfs/tmp/takaaki.yayoi@databricks.com/rinna/output/")
model = AutoModelForCausalLM.from_pretrained("/dbfs/tmp/takaaki.yayoi@databricks.com/rinna/output/")
Python
input = tokenizer.encode("機械学習とは", return_tensors="pt")
output = model.generate(input, do_sample=True, max_length=100, num_return_sequences=1)
print(tokenizer.batch_decode(output))
['機械学習とは</s> 機械学習(<unk> )は、コンピュータービジョン技術と人工知能を用いた様々な種類の機械学習、コンピュータービジョンアプリケーションです。機械学習のユースケースには、予測や不正検知のようなセンシティブなタスク、画像分類、テキスト分類、不正検知のようなエンドツーエンドのユースケース、<unk> のインフラストラクチャの管理、モデルとモデルのバージョンの管理が含まれます。 この記事の後半では、モデル開発、<unk> の自動化を支援する様々なツールを探索し、<unk>ata']
<unk>が含まれていますが、トレーニングデータが反映されています。面白い。
この辺りの挙動を理解しつつ、データも整理して、さらにはMLflowの新機能も活用していこうと思います。いやー、LLM面白いです。