Capture and view data lineage with Unity Catalog | Databricks on AWS [2022/12/6時点]の翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Databricksで実行されたクエリーに対する実行時データリネージをキャプチャするためにUnity Catalogを活用することができます。リネージはすべての言語でサポートされており、カラムレベルまで捕捉されます。リネージデータには、クエリーに関連するノートブック、ワークフロー、ダッシュボードが含まれます。リネージは、ニアリアルタイムでData Explorerに表示され、Databricks REST APIで取得することができます。
リネージはUnity Catalogメタストアにアタッチされているすべてのワークスペースから集約されます。これは、あるワークスペースでキャプチャされたリネージは、メタストアを共有する他のワークスペースで参照できることを意味します。リネージデータを参照するには、ユーザーは適切なアクセス権を持っている必要があります。リネージデータは30日間保持されます。
本書では、Data ExplorerとREST APIを用いたリネージの可視化について説明します。
要件
Unity Catalogでデータリネージをキャプチャするには以下のことが必要となります。
- ワークスペースでUnity Catalogが有効化され、Premiumプランを用いて起動されている必要があります。
- リネージがキャプチャされるためには、テーブルはUnity Catalogメタストアに登録されている必要があります。
- クエリーはSparkデータフレーム(例えば、データフレームを返却するSpark SQL関数)あるいはDatabricks SQLインタフェースを使用する必要があります。Databricks SQLやPySparkクエリーのサンプルについては、サンプルをご覧ください。
- テーブルやビューのリネージを参照するには、ユーザーは当該テーブル、ビューに対する
SELECT権限が必要となります。リネージのアクセス権をご覧ください。 - リネージをキャプチャするには、テーブルを用いてデータの作成、変更を行う必要があります。ファイルに直接書き込まれたデータのリネージはキャプチャされません。
制限
- Deltaテーブル間のストリーミングはDatabricksランタイム11.2以降でのみサポートされています。
- テーブルがクラウドストレージロケーションで定義されていたとしても、クラウドストレージのファイルに直接データが書き込まれた際にはリネージはキャプチャされません。例えば、
spark.write.save(“s3://mybucket/mytable/”)はリネージを生成しません。 - リネージは30日間のローリングウィンドウで計算されるため、30日以前にキャプチャされたリネージは表示されません。例えば、ジョブやクエリーがテーブルAからデータを読み込み、テーブルBに書き込みを行った際、テーブルAとテーブルBの間のリンクは30日間のみ表示されます。
- リネージを参照する際、Jobs APIの
runs submitリクエストを使用するワークフローは利用できません。runs submitリクエストを用いる際も、テーブル、カラムレベルのリネージはキャプチャされますが、ジョブ実行に対するリンクはキャプチャされません。 - Delta Live Tablesパイプラインのリネージはキャプチャされません。
- Unity Catalogはベストエフォートでカラムレベルへのリネージをキャプチャします。しかし、カラムレベルのリネージがキャプチャされない場合があり得ます。
- テーブル名が変更されると、テーブル名が変更されたテーブルに対するリネージはキャプチャされません。
サンプル
注意
-
以下のサンプルでは、カタログ
lineage_data、スキーマlineagedemoを使用します。別のカタログやスキーマを使用する際には、サンプルの中の名称を変更してください。 -
このサンプルを完了するには、スキーマに対する
CREATE、USAGE権限が必要となります。メタストア管理者、カタログのオーナー、スキーマのオーナーがこれらの権限を付与することができます。例えば、グループdata_engineersのすべてのユーザーにカタログlineage_dataのスキーマlineagedemoへのテーブル作成権限を与えるには、以下のクエリーを実行します。SQLCREATE SCHEMA lineage_data.lineagedemo; GRANT USAGE, CREATE on SCHEMA lineage_data.lineagedemo to `data_engineers`;
リネージのキャプチャと探索
リネージデータをキャプチャするには、以下のステップを実行します:
-
Databricksのランディングページに移動し、サイドバーの
 Newをクリックし、メニューからNotebookを選択します。
Newをクリックし、メニューからNotebookを選択します。 -
ノートブックの名前を入力し、Default LanguageでSQLを選択します。
-
Clusterで、Unity Catalogにアクセスできるクラスターを選択します。
-
Createをクリックします。
-
ノートブックの最初のセルに以下のクエリーを記述します。
SQLCREATE TABLE IF NOT EXISTS lineage_data.lineagedemo.menu ( recipe_id INT, app string, main string, dessert string ); INSERT INTO lineage_data.lineagedemo.menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); CREATE TABLE lineage_data.lineagedemo.dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM lineage_data.lineagedemo.menu -
クエリーを実行するには、セルをクリックしshift+enterを押すか、
 をクリックしてRun Cellを選択します。
をクリックしてRun Cellを選択します。
これらのクエリーによって生成されたリネージをData Explorerで参照するには、以下のステップを実施します。
- DatabricksワークスペースのトップバーにあるSearchボックスで、
lineage_data.lineagedemo.dinnerと入力し、Search lineage_data.lineagedemo.dinner in Databricksをクリックします。 -
Tables View all tablesの下で、
dinnerテーブルをクリックします。 -
Lineageタブを選択します。Lineageパネルが表示され、
menuテーブルが表示されます。

- データリネージのインタラクティブなグラフを表示するには、See Lineage Graphをクリックします。デフォルトではグラフには1レベルのみが表示されます。更なるコネクションが存在する場合には、ノードの
 アイコンをクリックします。
アイコンをクリックします。 -
Lineage connectionパネルをオープンするために、リネージグラフでノードを接続している矢印をクリックします。Lineage connectionパネルはソースとターゲットのテーブル、ノートブック、ワークフローを含む接続の詳細を表示します。
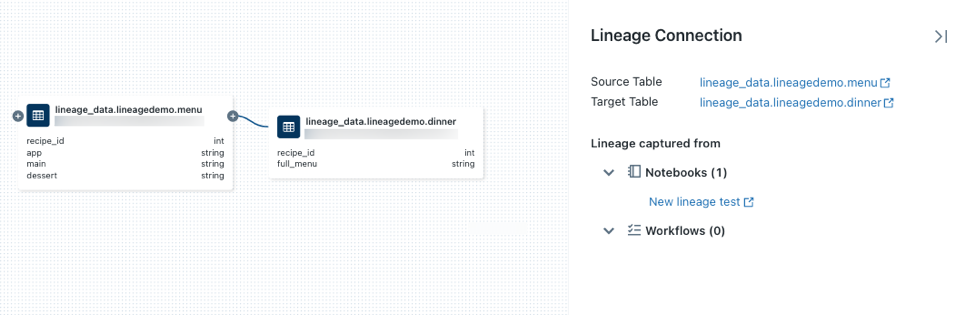
-
dinnerテーブルに関連するノートブックを表示するには、Lineage connectionパネルでノートブックを選択するか、リネージグラフを閉じてNotebooksをクリックします。新規タブでノートブックを開くにはノートブック名をクリックします。 - カラムレベルのリネージを参照するには、関連カラムへのリンクを表示するためにグラフのカラムをクリックします。例えば、カラム
full_menuをクリックすると派生元の上流のカラムが表示されます。

Pythonなど別の言語によるリネージの作成、参照をデモンストレーションするために、以下のステップを実行します。
-
上で作成したノートブックをオープンし、新規セルを作成し、以下のPythonコードを入力します。
Python%python from pyspark.sql.functions import rand, round df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") df.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.price") dinner = spark.read.table("lineage_data.lineagedemo.dinner") price = spark.read.table("lineage_data.lineagedemo.price") dinner_price = dinner.join(price, on="recipe_id") dinner_price.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.dinner_price") -
セルをクリックして、shift+enterを押すか、
をクリックしてRun Cellを選択します。 -
DatabricksワークスペースのトップバーにあるSearchボックスで、
lineage_data.lineagedemo.priceと入力し、Search lineage_data.lineagedemo.price in Databricksをクリックします。 -
Tablesの下の
priceをクリックします。 -
Lineageタブを選択し、See Lineage Graphをクリックします。SQLやPythonクエリーによって生成されたデータリネージを探索するために
アイコンをクリックします。
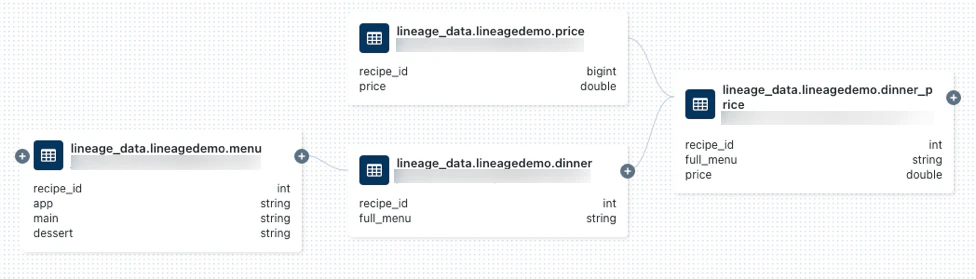
-
Lineage connectionパネルをオープンするために、リネージグラフでノードを接続している矢印をクリックします。Lineage connectionパネルはソースとターゲットのテーブル、ノートブック、ワークフローを含む接続の詳細を表示します。
ワークフローのリネージのキャプチャと参照
また、Unity Catalogに対して読み書きを行うすべてのワークフローのリネージもキャプチャされます。Databricksワークフローのリネージの参照をデモンストレーションするには、以下のステップを実施します。
-
Databricksのランディングページに移動し、Data Science & Engineeringペルソナに切り替えます。
-
サイドバーの
Newをクリックし、メニューからNotebookを選択します。 -
ノートブックの名前を入力し、Default LanguageでSQLを選択します。
-
Createをクリックします。
-
最初のセルに以下のクエリーを記述します。
SQLSELECT * FROM lineage_data.lineagedemo.menu -
トップバーのScheduleをクリックします。スケジュールのダイアログでManualを選択し、Unity Catalogにアクセスできるクラスターを選択し、Createをクリックします。
-
Run nowをクリックします。
-
DatabricksワークスペースのトップバーにあるSearchボックスで、
lineage_data.lineagedemo.menuと入力し、Search lineage_data.lineagedemo.menu in Databricksをクリックします。 -
Tables View all tablesの下で
menuテーブルをクリックします。 -
Lineageタブを選択しWorkflowsをクリックして、Downstreamタブを選択します。
menuテーブルのコンシューマーとしてJob Nameの下にジョブ名が表示されます。
ダッシュボードのリネージのキャプチャと参照
SQLダッシュボードのリネージの参照をデモンストレーションするために、以下のステップを使用します。
- Databricksのランディングページに移動し、サイドバーのDataをクリックすることでData Explorerをオープンします。
- カタログ名をクリックし、lineagedemoをクリックし、
menuテーブルを選択します。また、menuテーブルを検索するためにトップバーの検索ボックスを使うこともできます。 - Actions > Create a quick dashboardをクリックします。
- ダッシュボードに追加するカラムを選択しCreateをクリックします。
- DatabricksワークスペースのトップバーにあるSearchボックスで、
lineage_data.lineagedemo.menuと入力し、Search lineage_data.lineagedemo.menu in Databricksをクリックします。 -
Tables View all tablesの下で
menuテーブルをクリックします。 -
Lineageタブを選択しDashboardsをクリックします。
menuテーブルのコンシューマーとしてDashboard Nameの下にダッシュボード名が表示されます。
リネージのアクセス権
リネージグラフは、Unity Catalogと同じアクセス権モデルを共有します。ユーザーがテーブルに対するSELECT権限を有していない場合、リネージを探索することはできません。さらに、参照権限を持つノートブック、ワークフロー、ダッシュボードのみを参照することができます。例えば、管理者ではないユーザーuserAに対して以下のコマンドを実行するとします。
GRANT USAGE on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
userAがlineage_data.lineagedemo.menuテーブルのリネージグラフを参照する際、menuテーブルを参照することができますが、下流のlineage_data.lineagedemo.dinnerテーブルのように参照権限を持たないテーブルに関する情報を参照することはできません。userAに対してdinnerテーブルはmaskedノードとして表示され、userAはアクセス権を持たないためテーブルの下流のグラフを展開することはできません。
ワークスペースオブジェクトに対するアクセス権の管理に関しては、Databricksにおけるワークスペースオブジェクトのアクセスコントロールをご覧ください。
リネージデータの削除
警告!
以下の手順を実行するとUnity Catalogに格納されているすべてのオブジェクトを削除します。必要な場合にのみこれらの手順を用いるようにしてください。例えば、コンプライアンス要件に対応するためといったことが考えられます。
リネージデータを削除するには、メタストアが管理するUnity Catalogオブジェクトを削除する必要があります。メタストアの削除に関してはDelete a metastoreをご覧ください。データは30日以内に削除されます。
データリネージAPI
データリネージAPIを用いることで、テーブルやカラムのリネージを取得することができます。
重要!
Databricks REST APIにアクセスするためには、認証を受ける必要があります。
テーブルリネージの取得
このサンプルではdinnerテーブルのリネージデータを取得します。
リクエスト
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<databricks-instance/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}}'
<databricks-instance>を、dbc-a1b2345c-d6e7.cloud.databricks.comのようなお使いのワークスペースインスタンス名で置き換えてください。
このサンプルでは.netrcファイルを使用しています。
レスポンス
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
カラムリネージの取得
このサンプルではdinnerテーブルのカラムデータを取得します。
リクエスト
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<databricks-instance/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}}'
<databricks-instance>を、dbc-a1b2345c-d6e7.cloud.databricks.comのようなお使いのワークスペースインスタンス名で置き換えてください。
このサンプルでは.netrcファイルを使用しています。
レスポンス
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}