こちらにチャレンジしてみます。Kaggleのアカウント作成していましたが、一つもチャレンジしたことなかったのでした。お恥ずかしい。
このコンペティションはシンプルです: どの乗客がTitanic沈没を生き延びたのかを予測するモデルを作成するために機械学習を用います。
チャレンジの項目も翻訳します。
タイタニックの沈没は、歴史上最も悪名高い沈没事故の一つです。
1912年4月15日、処女航海の勝っていで、「不沈」と広く知られていたRMS Titanicは氷山との衝突後に沈没しました。不幸なことに、全員分の救命ボートが無く、結果として2224人の乗員乗客のうち1502人が亡くなりました。
生死を分けた要因にはある程度の運も含まれましたが、あるグループの人々が他のグループよりも生存した可能性があるようです。
このチャレンジでは、乗客データ(氏名、年齢、性別、社会・経済的なクラス)を用いて「どのような人々がより生存する可能性が高かったのか?」という質問に回答する予測モデルを構築することになります。
チュートリアルの活用
ここまで読み進めたら、チュートリアルがありましたのでこちらをウォークスルーします。
右上の3点リーダーをクリックしてDownload codeをクリックします。titanic-tutorial.ipynbがダウンロードされます。
チャレンジページのDataタブをクリックし、画面を下にスクロールすると表示されるDownload Allをクリックします。titanic.zipがダウンロードされます。
データのアップロード
ボリュームの機能を使ってクイックにzipファイルをDatabricksに取り込みます。
ボリュームを選択してこのボリュームにアップロードをクリックして、titanic.zipをドラッグ&ドロップします。
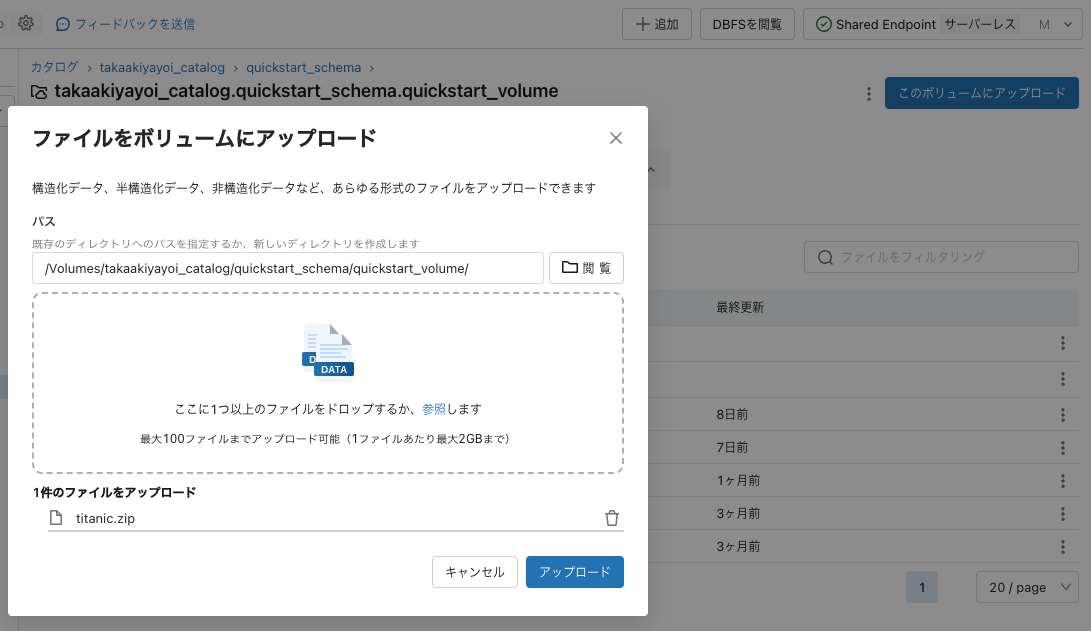
ノートブックのインポート
Databricksワークスペースでフォルダを作成して、メニューからインポートを選択します。titanic-tutorial.ipynbをドラッグ&ドロップします。
zipファイルの解凍
上でインポートしたノートブックにセルを追加してもいいですが、ここでは新規ノートブックを作成します。%shマジックコマンドを使ってシェルコマンドを実行していきます。
%sh
ls /Volumes/takaakiyayoi_catalog/quickstart_schema/quickstart_volume/titanic.zip
/Volumes/takaakiyayoi_catalog/quickstart_schema/quickstart_volume/titanic.zip
ファイルを解凍します。
%sh
unzip /Volumes/takaakiyayoi_catalog/quickstart_schema/quickstart_volume/titanic.zip -d /Volumes/takaakiyayoi_catalog/quickstart_schema/quickstart_volume/titanic/
Archive: /Volumes/takaakiyayoi_catalog/quickstart_schema/quickstart_volume/titanic.zip
inflating: /Volumes/takaakiyayoi_catalog/quickstart_schema/quickstart_volume/titanic/gender_submission.csv
inflating: /Volumes/takaakiyayoi_catalog/quickstart_schema/quickstart_volume/titanic/test.csv
inflating: /Volumes/takaakiyayoi_catalog/quickstart_schema/quickstart_volume/titanic/train.csv
%sh
ls /Volumes/takaakiyayoi_catalog/quickstart_schema/quickstart_volume/titanic
3つのcsvファイルが解凍されました。
gender_submission.csv
test.csv
train.csv
ノートブックの実行
インポートしたtitanic-tutorialノートブックを実行していきます。
ファイルを読み込みます。train.csvはトレーニング用のデータセットです。
train_data = pd.read_csv("/Volumes/takaakiyayoi_catalog/quickstart_schema/quickstart_volume/titanic/train.csv")
train_data.head()

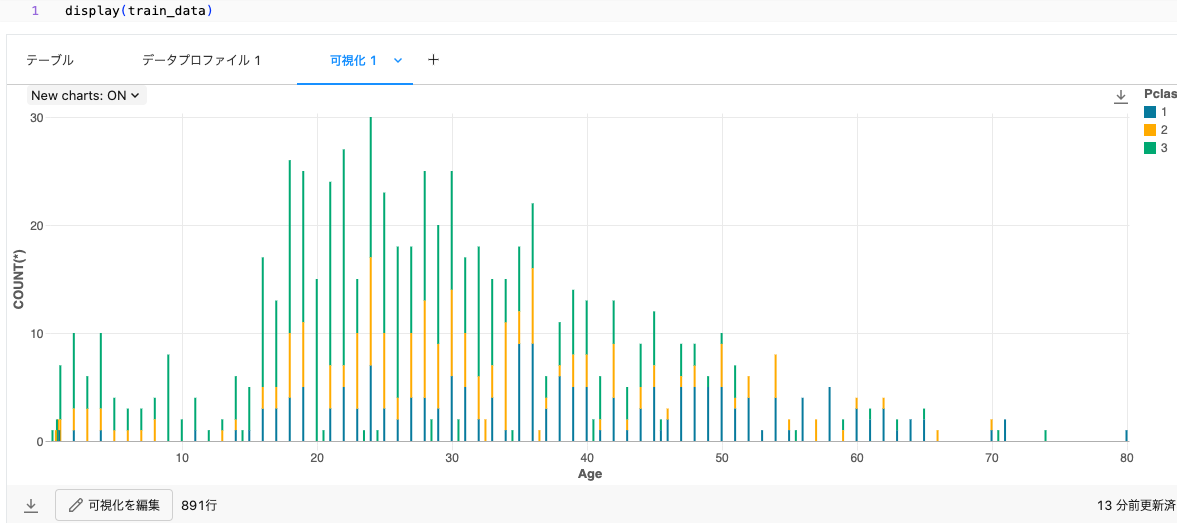
せっかくなので、Databricksのdisplay関数を活用します。
display(train_data)
よりリッチな一覧が表示されます。
これで終わりではありません。一覧の上にある + をクリックしてデータプロファイルを選択します。
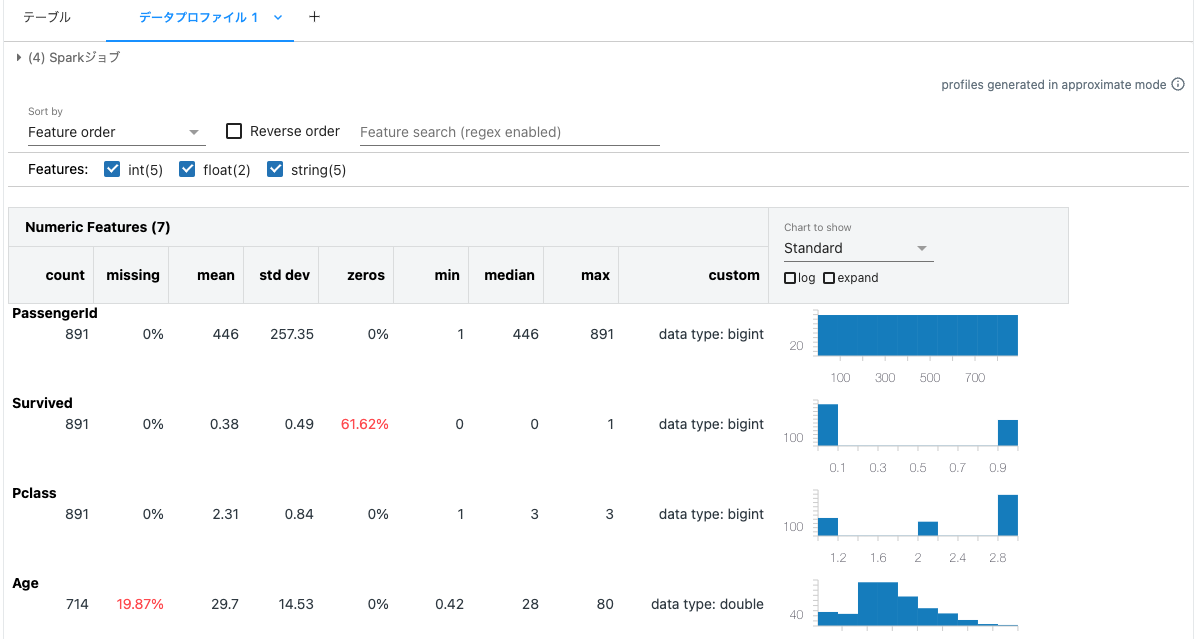
これだけで、データの概要を掴む助けとなるデータプロファイルが生成されます。
さらにデータの可視化も行います。 + をクリックして可視化を選択します。
チケットのクラスと年齢のグラフを設定します。
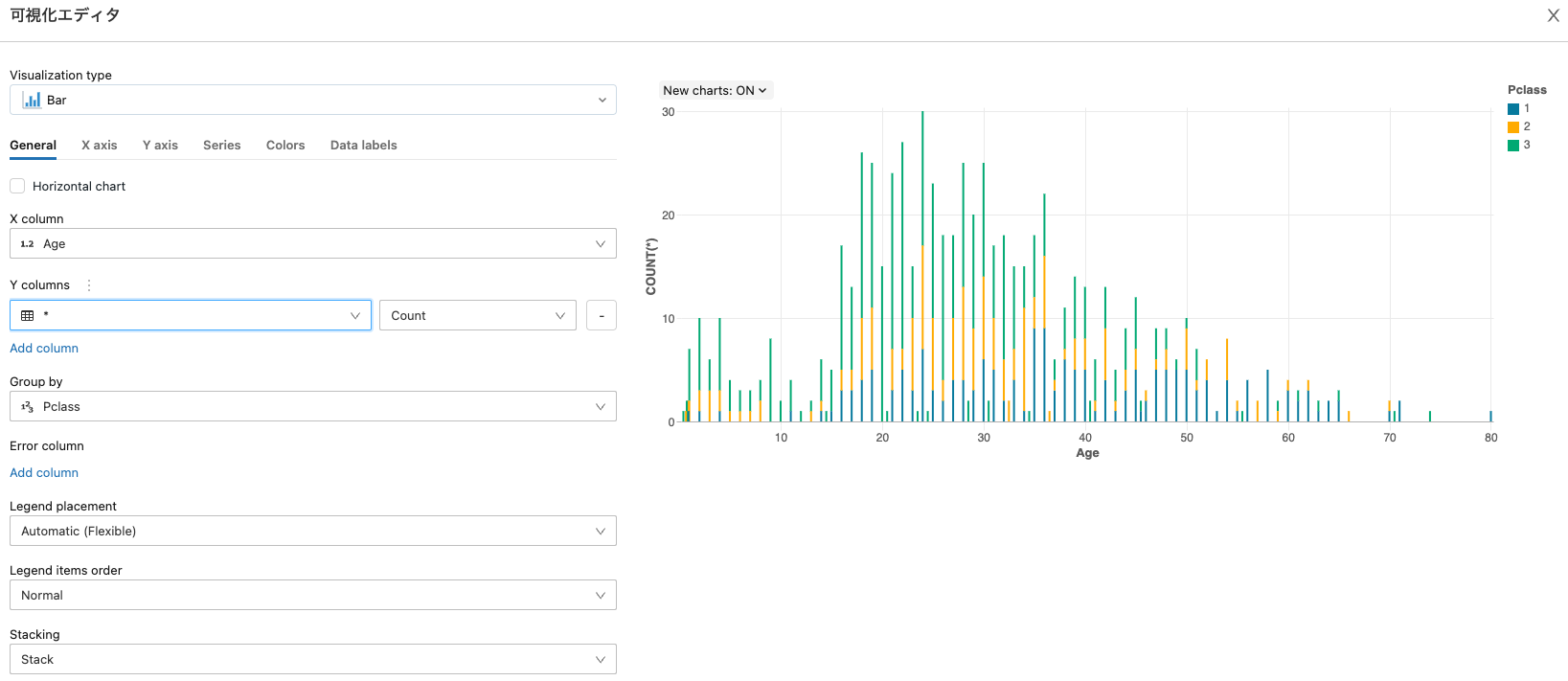
これだけでグラフが追加されます。
テストデータも確認します。
test_data = pd.read_csv("/Volumes/takaakiyayoi_catalog/quickstart_schema/quickstart_volume/titanic/test.csv")
test_data.head()
パターンを探索します。
women = train_data.loc[train_data.Sex == 'female']["Survived"]
rate_women = sum(women)/len(women)
print("% of women who survived:", rate_women)
% of women who survived: 0.7420382165605095
こちらも可視化で確認することができます。
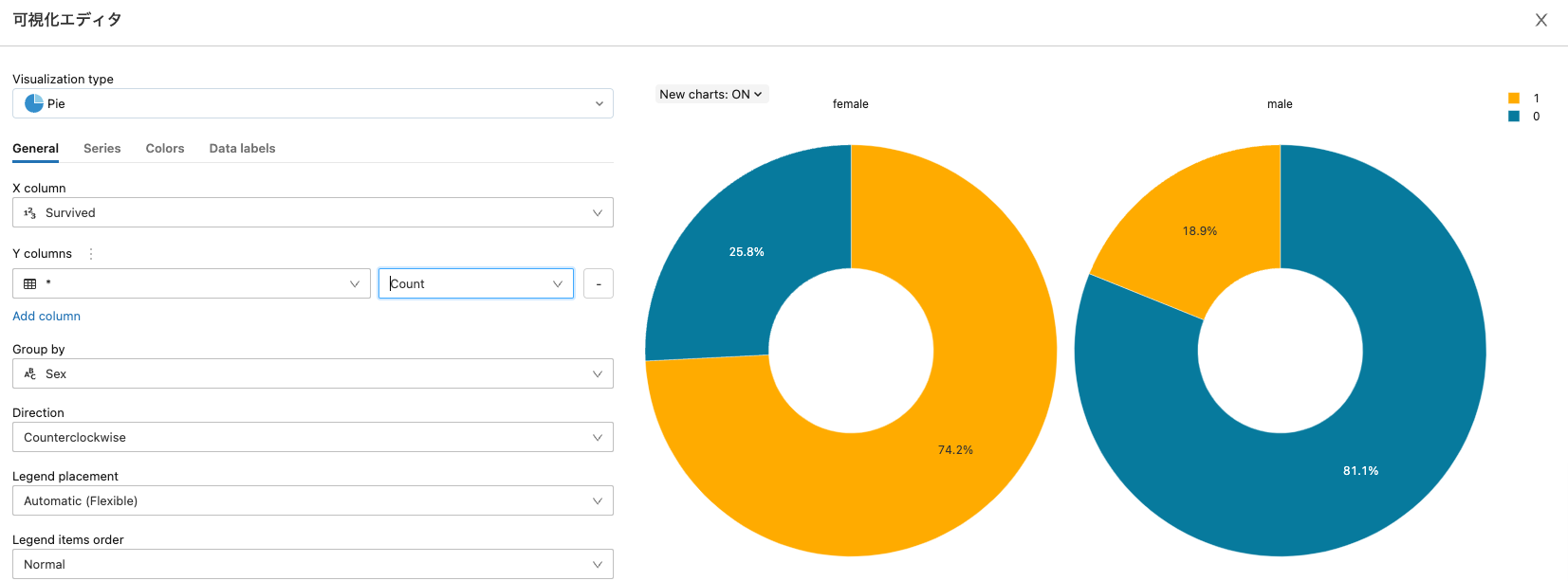
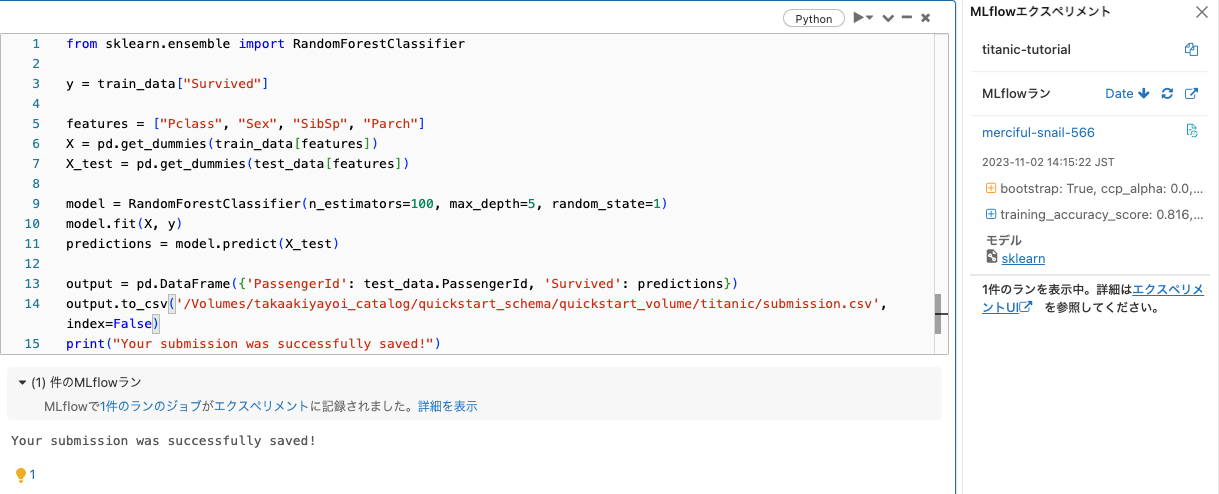
Random Forestで分類器を構築します。
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('/Volumes/takaakiyayoi_catalog/quickstart_schema/quickstart_volume/titanic/submission.csv', index=False)
print("Your submission was successfully saved!")
ボリュームに予測結果が保存されます。さらにDatabricksでは、MLflowによってモデルが自動で記録されます。
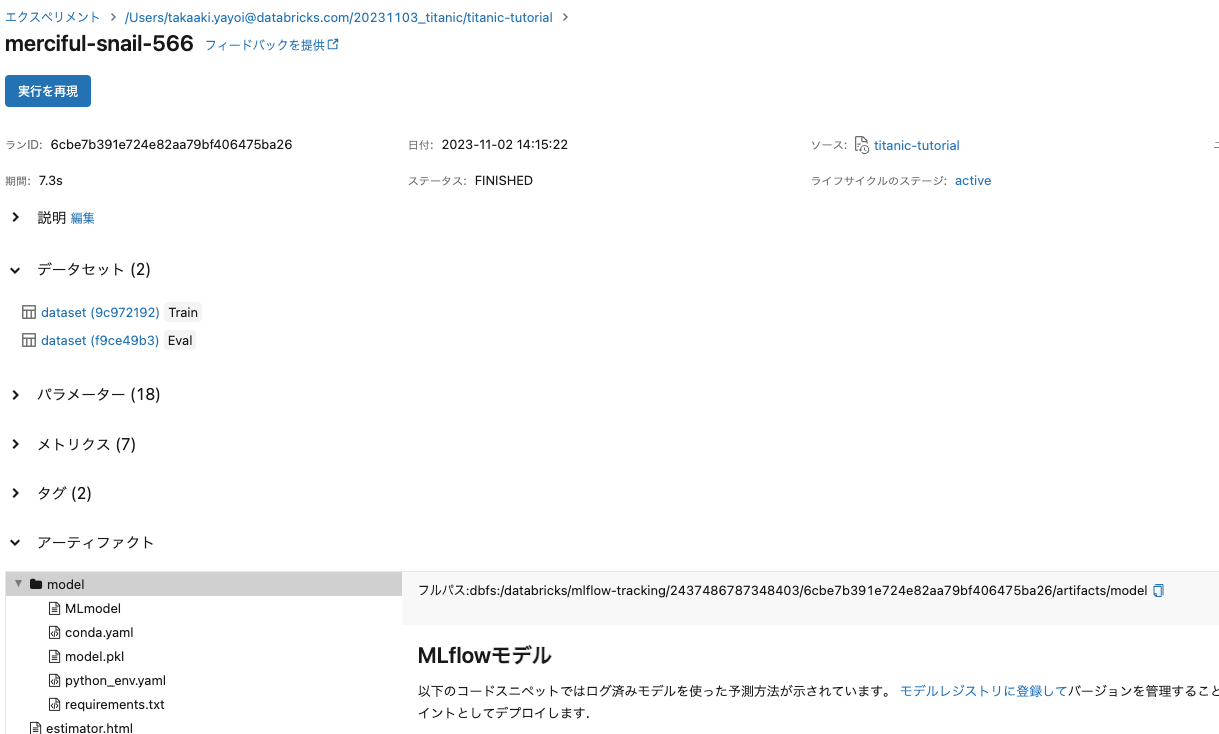
結果のダウンロードと提出
ボリュームからsubmission.csvをダウンロードします。
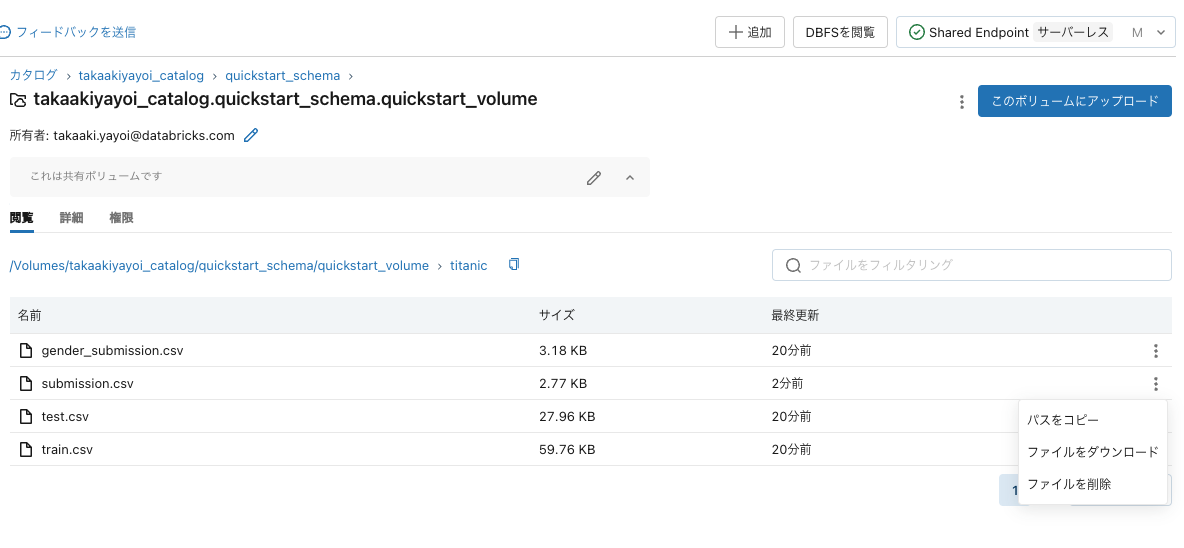
KaggleでSubmit Predictionsをクリックします。submission.csvをアップロードします。
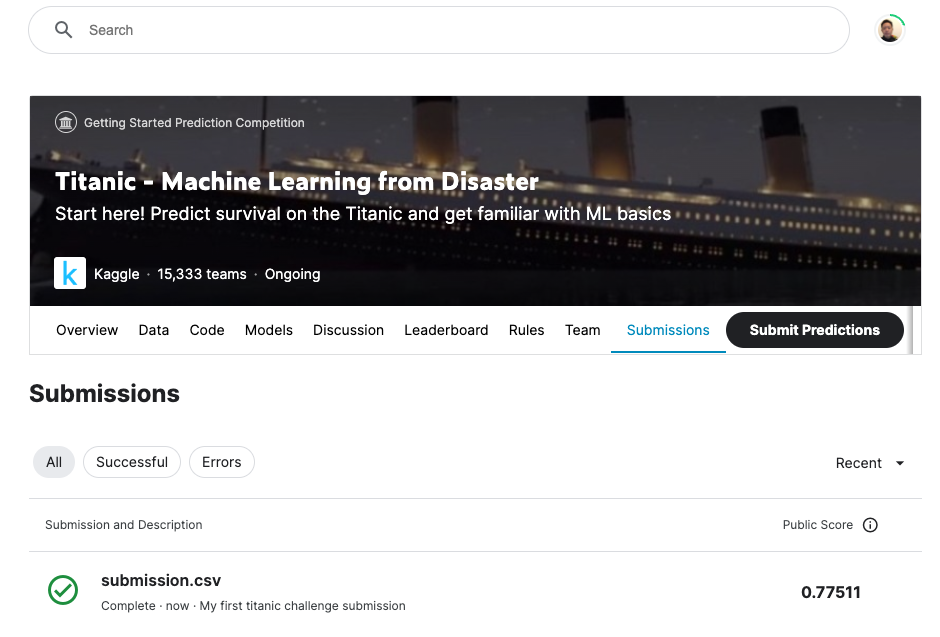
提出できました!
この後はおそらく、パラメーターチューニングなどで精度を改善していくことになるのですが、そういった場合でもMLflowが活躍します。可視化機能含めて是非ご活用ください!