本機能を利用するには、Databricksランタイム 10.0 ML以降が必要です。
Databricksランタイム 10.0以降でAutoMLの時系列データ予測をサポートしました。この記事では、GUIによる操作方法をご説明します。なお、APIからも本機能を利用できます。
データの準備
事前にトレーニングデータを「forecast_train_df」としてデータベースに登録しておきます。ここでは、COVID-19感染者数の時系列データを使用します。
import pyspark.pandas as ps
df = ps.read_csv("/databricks-datasets/COVID/covid-19-data")
df["date"] = ps.to_datetime(df['date'], errors='coerce')
df["cases"] = df["cases"].astype(int)
display(df)
# AutoML UIから参照できるようにデータフレームをテーブルに保存します
sdf = df.to_spark()
sdf.write.saveAsTable("forecast_train_df")
GUIを用いた時系列データ予測AutoML
-
ペルソナスイッチャーで「Machine Leaning」を選択し、Experimentにアクセス
-
Create AutoML Experimentをクリック
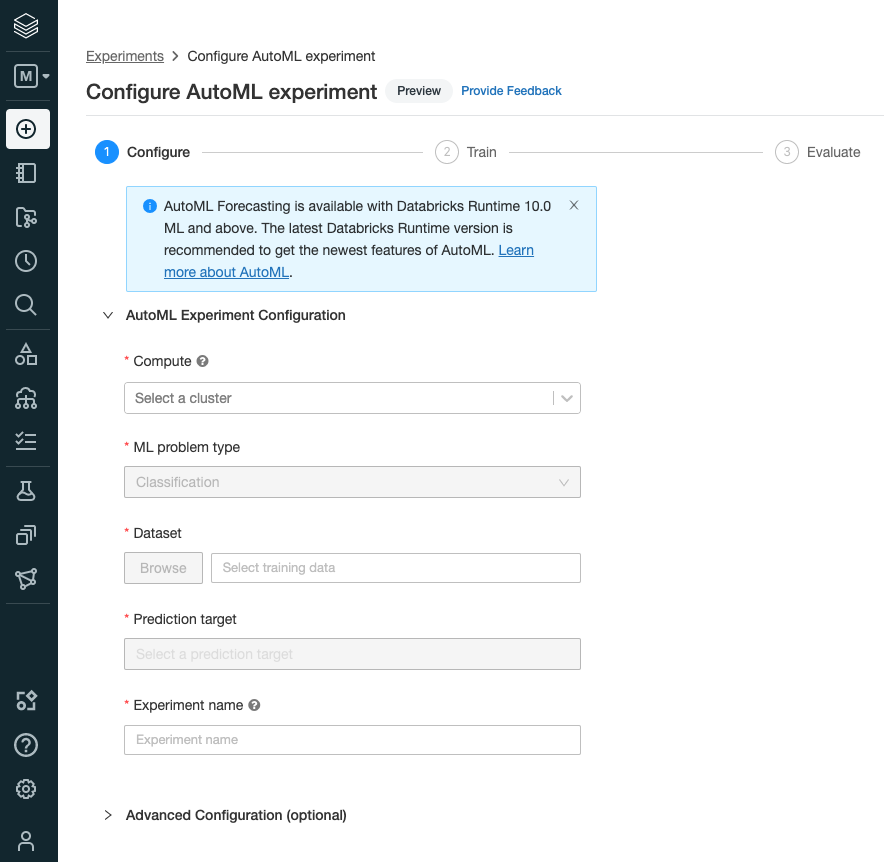
Computeフィールドで、Databricksランタイム 10.0ML以降が稼働しているクラスターを選択します。
-
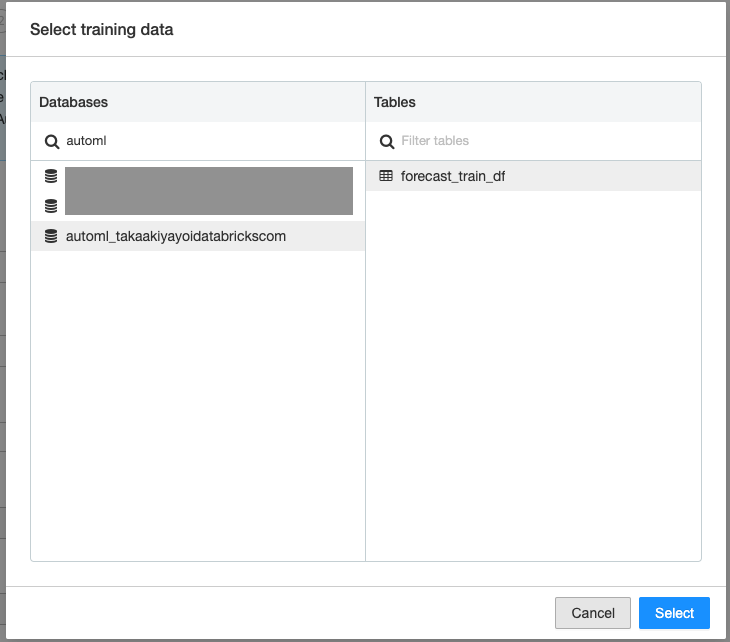
Datasetフィールドではデータベースに保存したテーブルを選択します。
-
Prediction targetでは
casesを選択します。 -
Time columnでは
dateを選択します。 -
Forecast horizon and frequencyでは
10 Daysを指定して、向こう10日間の予測を行うように指示します。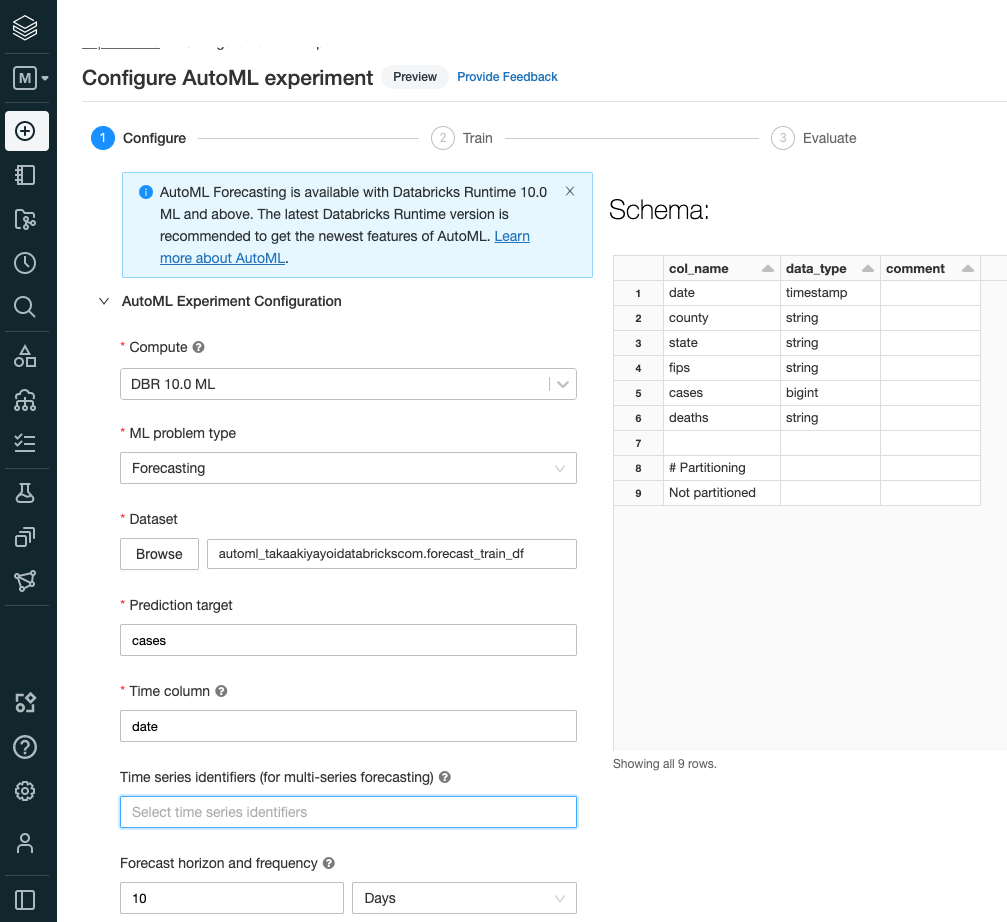
-
必要に応じてAdvanced Configuration (optional) を展開して終了条件を指定した後、Start AutoMLをクリックし、トレーニングを開始します。
-
トレーニング、評価が完了すると、ベストモデルを生成したノートブック(View notebook for best model)とトレーニングデータのトレンドを分析したノートブック(View data exploration notebook)にアクセスできるようになります。
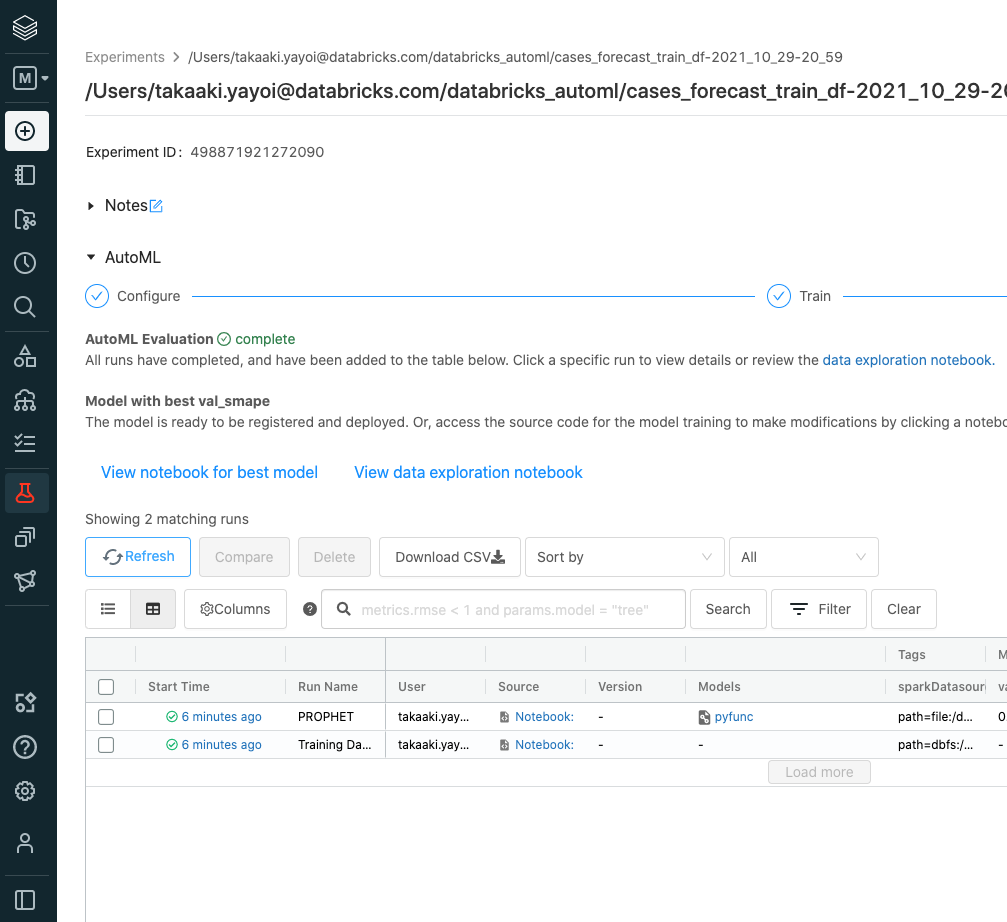
APIを用いた時系列データ予測AutoML
APIを用いたサンプルノートブックはこちらにあります。
ノートブック上で予測結果をプロットすることも可能です。
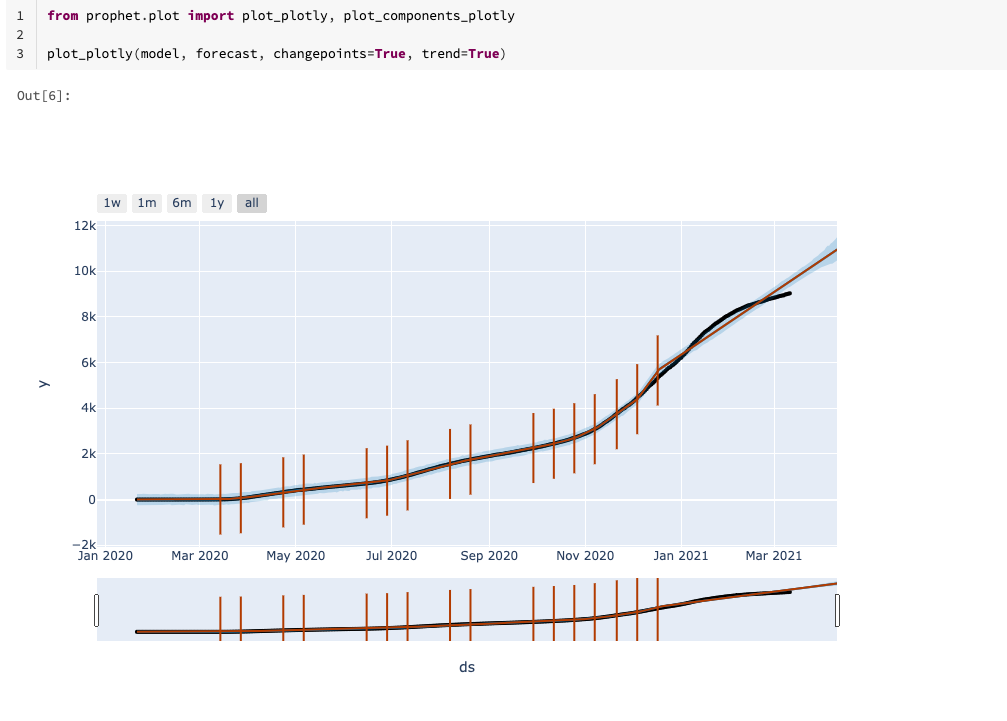
詳細はDatabricks AutoMLのマニュアルをご覧ください。