Apache Spark DataFrames for Large Scale Data Scienceの翻訳です。
2015/2時点の記事のため、一部内容が古い可能性がありますが、根底となる考え方は変わっていません。
より多くの方々が容易にビッグデータ分析を行えるようにするために設計された、新たなデータフレームAPIを発表できることを嬉しく思います。
最初にApache Sparkをオープンソース化した際、汎用プログラミング言語(Java、Python、Scala)における分散データ処理のためのシンプルなAPIを提供することを目指していました。Sparkによって、データの分散コレクション(RDD)に対する機能的変換処理を通じて分散処理を可能としました。これは信じられないほどパワフルなAPIです。数千行のコードで表現する必要があったタスクを、十数行で記述できるようになります。
Sparkは成長し続けており、我々としては「ビッグデータ」エンジニア以外の幅広いユーザーも分散処理のパワーを活用できるようにしたいと考えています。新たなデータフレームAPIは、このゴールを念頭に開発されました。このAPIはR、Python(Pandas)のデータフレームにインスパイヤされていますが、モダンなビッグデータ、データサイエンスアプリケーションをサポートするように一から設計されています。既存のRDD APIの拡張として、データフレームは以下の機能を提供します。
- 単体のラップトップにおけるキロバイトのデータから、大規模クラスターでペタバイトのデータにスケール。
- 幅広いデータフォーマット、ストレージシステムをサポート。
- Spark SQL Catalystオプティマイザーによる最新の最適化、コード生成。
- Sparkを介したビッグデータツールとインフラストラクチャのシームレスな統合。
- Python、Java、Scala、R向けAPIの提供。
他の言語のデータフレームに慣れ親しんでいるユーザーに対して、このAPIは彼らをまるで自宅にいるように感じさせるに違いありません。既存Sparkユーザーに対しては、この拡張APIを用いることで、より容易にプログラムでき、同時にインテリジェントな最適化とコード生成によってパフォーマンスを改善することができます。
データフレームとは?
Sparkにおいては、データフレームは名前付きのカラムでまとめられるデータの分散コレクションです。概念的にはリレーショナルデータベースにおけるテーブルや、R/Pythonにおけるデータフレームと同じものですが、内部では様々な最適化が行われています。データフレームは、構造化データファイル、Hiveテーブル、外部データベース、既存のRDDなど様々なデータソースから構築することができます。
以下の例では、Pythonでどのようにデータフレームを構築するのかを示しています。同様のAPIはScala、Java、Rで利用できます。
# Constructs a DataFrame from the users table in Hive.
users = context.table("users")
# from JSON files in S3
logs = context.load("s3n://path/to/data.json", "json")
どうやってデータフレームを使うの?
構築した後は、データフレームは分散データ処理のためのドメイン固有言語を提供します。以下の例では、大規模なユーザーのデモグラフィックデータを操作するために、どのようにデータフレームを用いているのか例を示しています。
# Create a new DataFrame that contains “young users” only
young = users.filter(users.age < 21)
# Alternatively, using Pandas-like syntax
young = users[users.age < 21]
# Increment everybody’s age by 1
young.select(young.name, young.age + 1)
# Count the number of young users by gender
young.groupBy("gender").count()
# Join young users with another DataFrame called logs
young.join(logs, logs.userId == users.userId, "left_outer")
Spark SQLを用いることで、データフレームを操作する際にSQLを使用することもできます。以下の例では、youngデータフレームにおけるユーザーの数をカウントしています。
young.registerTempTable("young")
context.sql("SELECT count(*) FROM young")
Pythonでは、自由にPandasデータフレームとSparkデータフレームを変換することができます。
# Convert Spark DataFrame to Pandas
pandas_df = young.toPandas()
# Create a Spark DataFrame from Pandas
spark_df = context.createDataFrame(pandas_df)
RDDと同様に、データフレームはレイジーに評価されます。すなわち、アクション(例:結果の表示、出力の保存)が必要とされた時にのみ計算が行われます。これによって、この後「内部処理:インテリジェントな最適化およびコード生成」で説明する述語プッシュダウンやバイトコード生成などのテクニックを適用することで処理を最適化することができます。全てのデータフレームの操作は自動でクラスター上で並列分散されます。
データフォーマット、データソースのサポート
モダンなアプリケーションにおいては、様々なソースからのデータを収集、分析する必要が多くあります。データフレームはアウトオブボックスで、JSONファイル、Parquetファイル、Hiveテーブルを含む様々な人気のあるフォーマットからのデータ読み込みをサポートしています。ローカルのファイルシステム、分散ファイルシステム(HDFS)、クラウドストレージ(S3)、JDBC経由で外部のリレーショナルデータベースから読み込むことができます。さらに、Spark SQLの外部データソースAPIを用いることで、あらゆるサードパーティのデータフォーマット、データソースをサポートするようにデータフレームを拡張することができます。既存のサードパーティ拡張には、すでにAvro、CSV、ElasticSearch、Cassandraが含まれています。

データソースに対するデータフレームのサポートによって、アプリケーションは散在しているソースからのデータを容易に組み合わせることができます(データベースにおけるクエリーのフェデレーション)。例えば、以下のコードでは、それぞれのユーザーがサイトに訪問した回数をカウントするために、S3に格納されているサイトの通信ログテキストと、PostgreSQLデータベースを結合しています。
users = context.jdbc("jdbc:postgresql:production", "users")
logs = context.load("/path/to/traffic.log")
logs.join(users, logs.userId == users.userId, "left_outer") \
.groupBy("userId").agg({"*": "count"})
アプリケーション:先進的分析、機械学習
データサイエンティストは、joinや集計よりも洗練されている技術を活用しはじめています。これに対応するために、MLlibの機械学習パイプラインAPIで直接データフレームを利用することができます。さらに、データフレームに対して、任意の複雑なユーザー関数を適用することができます。
最も一般的な先進的分析タスクは、MLlibの新たなパイプラインAPIを用いて指定することができます。例えば、以下のコードは、トークナイザ、ハッシング単語頻度特徴量抽出器、ロジスティック回帰から構成されるシンプルなテキスト分類パイプラインを構築します。
tokenizer = Tokenizer(inputCol="text", outputCol="words")
hashingTF = HashingTF(inputCol="words", outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
パイプラインがセットアップされれば、データフレーム上で直接トレーニングを行うことができます。
df = context.load("/path/to/data")
model = pipeline.fit(df)
機械学習パイプラインAPIが提供するよりも複雑なタスクにおいては、アプリケーションはデータフレームに対して任意の関数を適用することができます。また、Sparkの既存のRDD APIを用いて操作を行うこともできます。以下のスニペットでは、データフレームのbio列に対して、ビッグデータにおける「hello world」とも言えるワードカウントを実行します。
df = context.load("/path/to/people.json")
# RDD-style methods such as map, flatMap are available on DataFrames
# Split the bio text into multiple words.
words = df.select("bio").flatMap(lambda row: row.bio.split(" "))
# Create a new DataFrame to count the number of words
words_df = words.map(lambda w: Row(word=w, cnt=1)).toDF()
word_counts = words_df.groupBy("word").sum()
内部処理:インテリジェントな最適化およびコード生成
RやPythonにおける先行評価のデータフレームと異なり、Sparkのデータフレームは、クエリーオプティマイザーによって自動で最適化される自身の実行処理を有しています。データフレームに対する計算がスタートする前に、Catalystオプティマイザーが、データフレームを構築するのに必要なオペレーションを物理的実行計画にコンパイルします。オプティマイザーはオペレーションのセマンティクスとデータの構造を理解するので、処理を高速化するために賢明な決定を下すことができます。
ハイレベルにおいては、二つの種類の最適化が存在します。まず、Catalystは述語プッシュダウンのような論理的最適化を適用します。オプティマイザーはフィルターの述語をデータソースにプッシュダウンし、物理的実行が不要なデータをスキップできるようにします。Parquetファイルの場合、ブロック全体をスキップでき、ディクショナリーエンコーディングを通じて、文字列の比較をより低コストな整数の比較に変換することができます。リレーショナルデータベースの場合、述語は外部データベースにプッシュダウンされ、データトラフィックを削減することができます。
次に、Catalystはオペレーションを物理的な実行計画にコンパイルし、手書きのコードよりも最適化できるように、これらの実行計画に対応するJVMのバイトコードを生成します。例えば、ネットワークトラフィックを削減するために、ブロードキャストジョインかシャッフルジョインかを適切に選択できます。高コストなオブジェクト配置の除外や、バーチャルな関数呼び出しの削減など低レベルの最適化も実施します。このため、既存のSparkプログラムをデータフレームに移行することで性能改善を期待できます。
オプティマイザーが実行時にJVMバイトコードを生成するので、PythonユーザーはScala、Javaユーザーと同等の高性能を体験することができます。
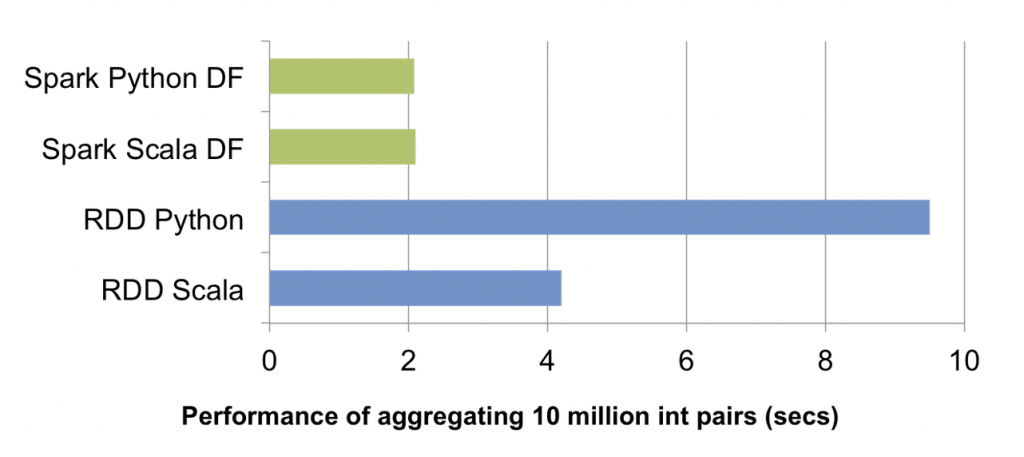
上のチャートでは、シングルマシン上で1000万の整数値ペアに対するgroup by集計を実行した際の処理時間の比較です(ソースコード)。Scala、Pythonデータフレームのオペレーションは、実行時にJVMバイトコードにコンパイルされるため、二つの言語間の違いはほとんどなく、単なるPython RDDと比較して5倍、Scala RDDと比較して2倍の性能を示しています。
データフレームは、AdataoのDDFやAyasdiのBigDFなど以前の分散データフレームの取り組みにインスパイヤされています。しかし、これらのプロジェクトとの大きな違いは、データフレームがCatalystオプティマイザーを経由し、Spark SQLクエリーと同じように実行を最適化するということです。我々はCatalystオプティマイザーを改善し続けているので、このエンジンはより賢くなり、新たなSparkのリリースとともにアプリケーションは高速化されています。
Databricksのデータサイエンスチームは、内部のデータパイプラインにデータフレームAPIを使用しています。データフレームAPIは、使っているSparkプログラムをより理解しやすいように簡潔にしつつも、性能改善をもたらしています。我々はこれを非常に喜ばしいことだと考えており、より幅広いユーザーがビッグデータ処理にアクセスできるようになると信じています。
2015年3月上旬にSpark1.3の一部としてこのAPIはリリースされます。待ちきれない場合には、GithubのSparkを試してみてください。
これまでのデータフレームの実装なしには、この機能を実現することはできませんでした。R、Pandas、DDF、BigDFの開発者たちに感謝の意を表します。