Getting Started with Personalization through Propensity Scoring - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
顧客はこれまで以上にパーソナライズされた方法でエンゲージされることを期待しています。最近購入したものを補完する商品を提案するメールのメッセージであろうが、頻繁に参照されるカテゴリーの製品のセールを発表するオンライバナーであろうが、表現された興味にアラインされたコンテンツであろうが、顧客はお金を費やす場所に対してさらなる数の選択肢を持ち、個人的な需要や嗜好を理解してくれるチャネルを好みます。
McKinseyによる最近の調査では、顧客の3/4が自身の購買体験の一部としてパーソナライズされたやり取りを期待していることをハイライトしています。このリサーチでは、パーソナライズされたエンゲージメントを通じて40%以上の収益を生み出すことに取り組んでいる企業もハイライトしており、トップの小売業者においてはパーソナライゼーションが鍵となる差別化要因となっています。
しかし、いまだ多くの小売業者がパーソナライゼーションに奮闘しています。Forresterによる最近の調査では、USの30%、UKの26%の消費者だけが、小売業者が彼らに対して適切な体験を生み出しているのに良い仕事をしていると信じていることがわかっています。3radicalによる別の調査では、回答者の18%のみがカスタマイズされたレコメンデーションを受け取っていると強く信じていますが、52%が不適切なコミュニケーションとオファーにフラストレーションを感じているという結果になっています。これまで以上に顧客がブランドやチャネルを切り替える力を持つにつれて、適切にパーソナライゼーションを行うことは、より多くのビジネスにとって重要事項となっています。
パーソナライゼーションは旅のようなものです
パーソナライゼーションに新たに取り組む企業にとって、ワンツーワンのエンゲージメントをデリバリーするという考え方には怯むかもしれません。このアプローチに必要なデータを組み立てるために、どうやってサイロ化されたプロセス、貧弱なデータスチュワードシップ、データプライバシーに関する懸念を克服するのでしょうか?限られたマーケティングリソースだけでどうやって、本当にパーソナライズされたと感じられるコンテンツやメッセージを作り出せるのでしょうか?どうすれば、作成するコンテンツが進化する需要と嗜好を持つ個人に対して効果的にターゲティングできるのでしょうか?
パーソナライゼーションに関する多くの文献は、自身の目新しさ(しかしそれらは常に効果ではありません)を際立たせる最先端のアプローチにハイライトしていますが、現実はパーソナライゼーションは旅のようなものであるということです。初期フェースでは、プライバシーと顧客の信頼を容易に維持できるファーストパーティのデータを活用することに重きが置かれます。立証された能力を前進させるために標準的な予測技術が適用されます。価値が明らかになり、開発を進めていくと、企業はこれらの新技術に満足するだけでなく、自身のプラクティスにインテグレーションすることになり、より洗練されたアプローチが適用されることになります。
多くの場合傾向スコアリングがパーソナライゼーションの最初のステップとなります
パーソナライゼーションのジャーニーの第一ステップの一つは、多くの場合は売上データから顧客個人の嗜好に対する洞察を得るための検証になります。傾向スコアリングと呼ばれるプロセスにおいては、企業は商品のサブセットに関連づけられるコンテンツあるいはオファーに対する顧客の潜在的な受容度を推定することができます。これらのスコアを用いることで、マーケターは利用できる多くのメッセージのどれを特定の顧客に提供すべきかを決定することができます。同様に、これらのスコアは特定の形態のエンゲージメントにより反応する、あるいは、あまり反応しない顧客セグメントの特定にも使うことができます。
多くの傾向スコアリングエクササイズのスタート地点は、過去のやり取りから数値的属性(特徴量)を計算することになります。これらの特徴量には、顧客の購買頻度、特定の製品カテゴリーに関連づけられる消費の割合、最後の購入からの経過日数、その他履歴データから導き出される多くのメトリクスが含まれます。そして、これらの特徴量を計算した期間のすぐ後の期間のデータを用いて、特定カテゴリー内の商品の購入やクーポンの利用といった興味のある振る舞いを検証します。振る舞いを観測すると、特徴量に対してラベル1が関連づけられ、そうでない場合には0が割り当てられます。
ラベルの予測器として特徴量を用いることで、データサイエンティストは興味のある振る舞いが発生する可能性を推定するモデルをトレーニングすることができます。トレーニングしたこのモデルを最新の期間で計算された特徴量に適用することで、マーケターは観測可能な未来において顧客はこの挙動にエンゲージする可能性を予測することができます。
大量のオファー、プロモーション、メッセージ、他のコンテンツが利用できるので、それぞれが異なる挙動を予測する大量のモデルがトレーニングされ、同じ特徴量セットに適用されます。興味のある振る舞いそれぞれに対するスコアから構成される顧客ごとのプロファイルがコンパイルされ、さまざまなキャンペーンとの組み合わせでマーケティングによって活用される後段のシステムに公開されます。
Databricksは傾向スコアリングにおける重要な機能を提供します
傾向スコアリングはわかりやすいものに見えますが、課題が無い訳ではありません。傾向スコアリングを実装しているお客様との会話では、多くのケースで以下の3つの同じ疑問に遭遇しました。
- 自分の傾向モデルのトレーニングに使用する100、あるいは1000もの特徴量をどのように管理すればいいのでしょうか?
- マーケティングチームが追求したいと考えている新たなキャンペーンに割り当てるモデルを、どのように迅速にトレーニングできるのでしょうか?
- 顧客のパターンにドリフトがあった場合に、どのように迅速に再トレーニングを行い、スコアリングパイプラインに再デプロイすればいいのでしょうか?
Databricksにおいては、企業のエンドツーエンドのニーズに応える分析プラットフォームを通じてお客様を支援することにフォーカスしています。このために、堅牢な傾向スコアリングプロセスの一部として、これらの課題に取り組むために活用できるFeature Store、AutoML、MLflowのような機能をプラットフォームに統合しました。
Feature Store
Databricks Feature Storeは集中管理されるリポジトリであり、特徴量の永続化、検索、さまざまなモデルトレーニングのエクササイズにおける特徴量の共有を可能にします。特徴量が捕捉され、リネージュや他のメタデータも捕捉されるので、他の人によって作成された特徴量を再利用したいと考えるデータサイエンティストが、自信もって容易に再利用できるようになります。標準的なセキュリティモデルは、これらの特徴量の利用許可を持つユーザー、プロセスのみに利用を限定できるので、データサイエンスプロセスをデータアクセスに対する企業ポリシーと調和させることができます。
AutoML
Databricks AutoMLを用いることで、業界のベストプラクティスを活用してクイックにモデルを生成することができます。ガラスボックスソリューションとして、AutoMLは最初にあなたのシナリオに合わせた異なるモデルバリエーションを表現する一連のノートブックを生成します。あなたのデータセットに対してベストな結果をモデルを特定するために、異なるモデルを繰り返しトレーニングしますが、これによって、それぞれのモデルに関連づけられたノートブックにアクセスすることができます。多くのデータサイエンスチームにとっては、これらのノートブックが様々なモデルのバージョンを探索するための編集可能なスタート地点となり、最終的には自身の目標に到達したと自信を持てるモデルに到達することを可能にします。
MLflow
MLflowはDatabricksプラットフォーム内でマネージドサービスとして提供される、オープンソースの機械学習モデルリポジトリです。このリポジトリを用いることで、データサイエンスチームはAutoMLあるいは同様のカスタムトレーニングサイクルの両方で生成されるさまざまなモデルを追跡、解析することができます。ワークフロー管理機能によって、企業は迅速にトレーニングしたモデルを開発段階からプロダクションに移行することができ、トレーニングしたモデルを即時にオペレーションに適用することができます。
Databricks Feature Storeと組み合わせることで、MLflowに記録されたモデルにはトレーニングに使用された特徴量に関する知識を保持するようになります。推論のためにモデルが呼び出されると、同じ情報を用いることでモデルはFeature Storeから適切な特徴量を取得することができ、スコアリングワークフローを非常にシンプルなものにし、高速なデプロイメントを実現します。
傾向スコアリングワークフローの構築
これらの機能を組み合わせて活用することで、多くのお客様が3パートのワークフローの一部として傾向スコアリングを実装するのを目撃しています。最初のパートでは、データエンジニアが傾向スコアリングのエクササイズに適した特徴量を定義し、これらをFeature Storeで永続化します。そして、新規入力データが到着するのに合わせて最新の特徴量を計算するために、日次あるいはリアルタイムの特徴量エンジニアリングプロセスが定義されます。
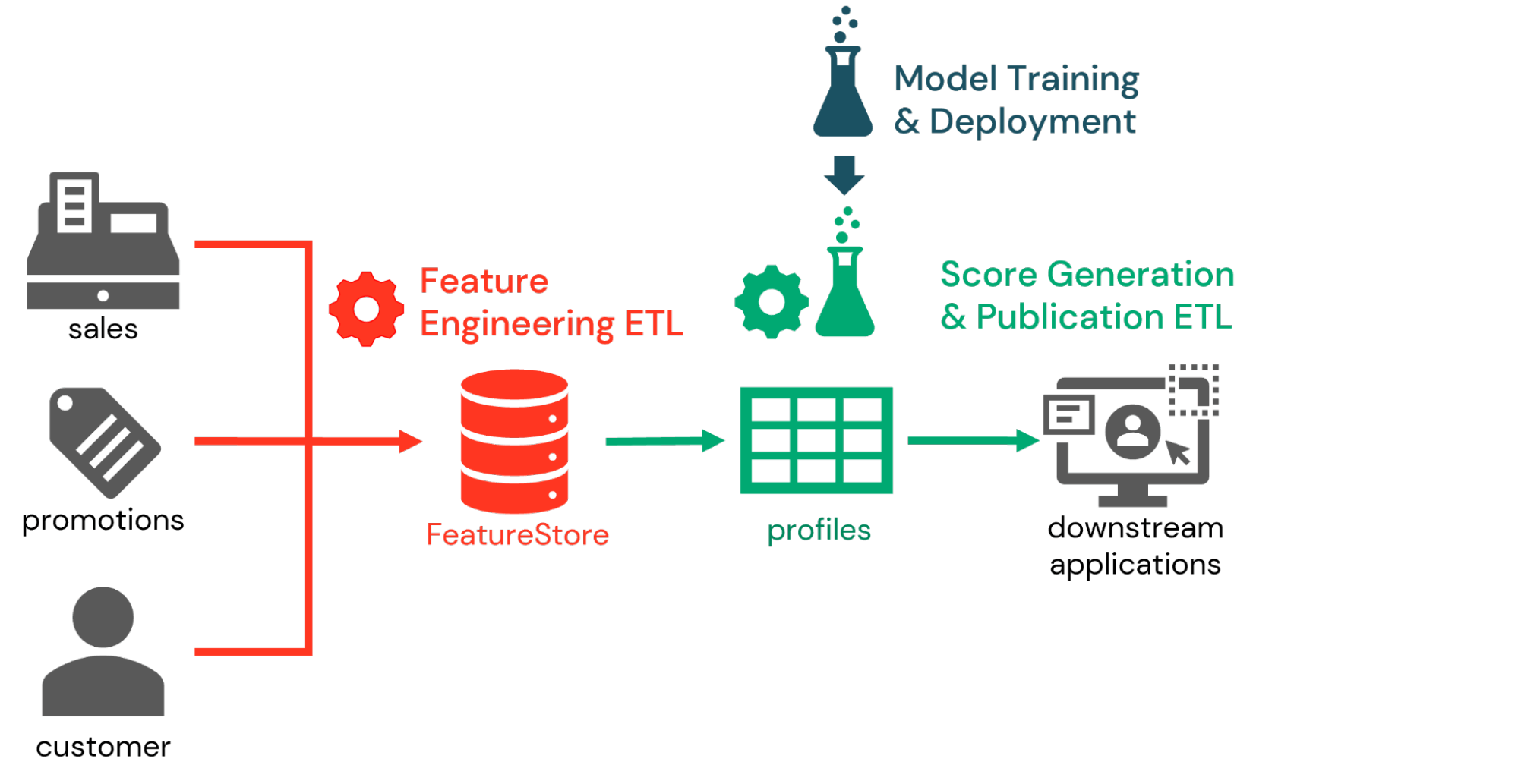
図1. 3パートの傾向スコアリングワークフロー
次に、推論ワークフローの一部として、最新の特徴量に基づいて傾向スコアを生成するために以前トレーニングしたモデルに顧客IDが提示されます。モデルに記録されているFeature Storeの情報を用いることで、データエンジニアはこれらの特徴量を取得し、比較的簡単に必要とするスコアを生成することができます。これらのスコアを分析のためにDatabricksプラットフォームに永続化することもできますが、多くの場合これらは後段のマーケティングシステムに公開されます。
最後に、モデルのトレーニングワークフローの中で、顧客の挙動のシフトを捉えるために、データサイエンティストが定期的に傾向スコアリングモデルを際トレーニングします。これらのモデルはMLflowに記録されているので、モデルを評価し、企業の評価指標に合致するこれらのモデルをプロダクション状態にプロモートするために変更管理プロセスを適用します。推論ワークフローの次のイテレーションでは、顧客スコアを生成するためにそれぞれのモデルの最新のプロダクションバージョンが利用されます。
これらの機能がどのように共に動くのかをデモンストレーションするために、パブリックに公開されているデータセットに対する傾向スコアリングモデルのエンドツーエンドのワークフローを作成しました。このワークフローでは、上述した3パートのワークフルオーをデモンストレーションしており、効果的な傾向スコアリングパイプラインを構築するためにどのようにDatabricksのキーとなる機能を活用しているのかを説明しています。
こちらのアセットをダンロードし、Databricksを活用してご自身のパーソナライゼーションの基礎を作るスタート地点として活用してみてください。