Query profile | Databricks on AWS [2022/6/23時点]の翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
クエリー実行の詳細を可視化するためにクエリープロファイルを活用できます。クエリープロファイルを用いることで、以下のようにしてクエリー実行時のパフォーマンスのボトルネックをトラブルシュートすることができます。
- それぞれのクエリーや処理時間、処理行数、メモリー使用量のような関連メトリクスを可視化することができます。
- パッとみてクエリー実行で最も遅い箇所を特定し、クエリー変更のインパクトを評価することができます。
- 爆発的なjoinやフルテーブルスキャンのような、よくあるSQL文の間違いを発見し、修正することができます。
要件
クエリープロファイルを参照するには、クエリーのオーナーであるか、クエリーを実行するSQLウェアハウスのCan Manage権限を持っている必要があります。
クエリープロファイルの参照
クエリーのプロファイルを参照するには、
-
クエリー履歴を参照します。
-
クエリー名をクリックします。
-
View Query Profileをクリックします。基本的なクエリーメトリクスの概要が表示されます。
注意
クエリープロファイルが利用できませんと表示された場合、このクエリーではプロファイルが利用できません。クエリーキャッシュから実行されたクエリーではクエリープロファイルを利用することはできませ。クエリーキャッシュを回避するには、LIMITを変更するか削除するなど、クエリーに些細な修正を行なってください。 -
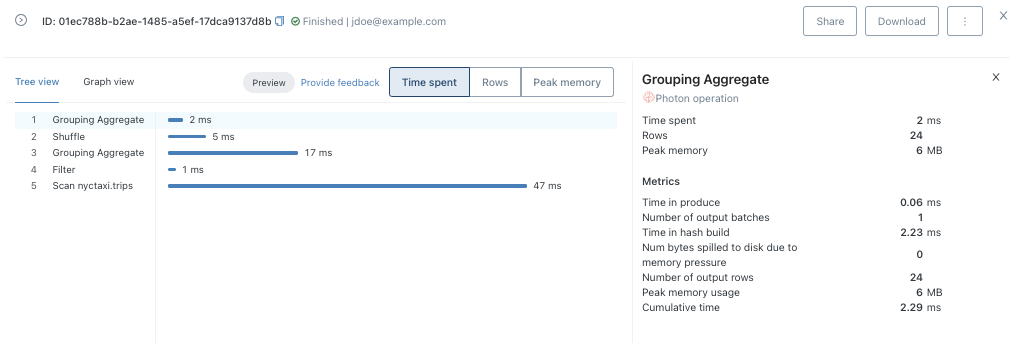
ツリービュー(デフォルト)でクエリープロファイルを参照するには、Tree viewをクリックします。グラフとしてクエリープロファイルを表示するには、Graph viewをクリックします。
- ツリービューは、最も時間を要しているオペレーターを特定するような、クエリーパフォーマンスに関する問題をクイックに特定するのに最適化されています。
- グラフビューは、あるノードから別のノードにどのようにデータが流れているのかを可視化することに最適化されています。
-
ツリービューやグラフビューでは、それぞれのクエリータスクの詳細を参照するためにページ上部にあるタブをクリックすることができます。
- Time: それぞれのオペレーションのすべてのタスクで消費された実行時間の合計です。
- Rows: それぞれのクエリータスクで影響を受けた行の数とサイズです。
- Memory: それぞれのクエリータスクで消費されたピークメモリーです。
注意
いくつかの非Photonのオペレーションはグループとして実行され、共通メトリクスをシェアします。この場合、特定のメトリックにおいてすべてのサブタスクは親のタスクと同じ値を持ちます。 -
ツリービューでサブタスクが存在する場合、
>をクリックして展開することができます。グラフビューでは、詳細を表示するためにノードをクリックします。 -
それぞれのタスクオペレーションが表示されます。デフォルトでは、いくつかのオペレーションのタスクとメトリクスは非表示となっています。これらのオペレーションはパフォーマンスのボトルネックになる可能性が低いものです。すべてのオペレーションの情報を表示し、追加のメトリクスを確認するには、ページ上部にある
 をクリックし、Enable verbose modeをクリックします。最も一般的なオペレーションを以下に示します。
をクリックし、Enable verbose modeをクリックします。最も一般的なオペレーションを以下に示します。- Scan: データソースからデータが読み込まれ、業として出力されました。
- Join: 複数のリレーションの行が一連の行セットに結合(つなぎ合わ)されました。
- Union: 同じスキーマを用いた複数のリレーションの行が一連の行セットにまとめられました。
- Shuffle: データは再分配、再パーティション化されました。シャッフルオペレーションは、クラスターのエグゼキューター間でデータを移動するので高価なオペレーションです
-
Hash / Sort: 行がグルーピングされ、各グループに対して
SUM、COUNT、MAXのような集計関数を用いて評価が行われました。 -
Filter:
WHERE句を用いるなどして、評価指標に基づいて入力がフィルタリングされ、行のサブセットが返却されました。 - (Reused) Exchange: 希望されるパーティショニングに基づいて、クラスターノード間でデータを再分配するために、シャッフルあるいはブロードキャストエクスチェンジが使用されました。
-
Collect Limit:
LIMIT文を用いて返却行が切り捨てられました。 - Take Ordered And Project: クエリー結果のトップN行が返却されました。
-
Apache Spark UIでクエリープロファイルを表示するには、ページ上部にある
をクリックし、Open in Spark UIをクリックします。 -
インポートしたクエリープロファイルを閉じるには、ページ上部のXをクリックします。
クエリープロファイルで利用できる情報の詳細に関しては、クエリープロファイル詳細の参照をご覧ください。
クエリープロファイル詳細の参照
クエリープロファイルでは、最後のタスクが先頭に来るように逆順でトップレベルのクエリータスクが一覧されます。左側には、当該タスクのタスクシーケンス、オペレーション名、選択されたメトリックのグラフが表示されます。クエリープロファイルのさまざまなパーツに慣れるために以下の手順を踏んでください。
- それぞれのサブタスクに期間を確認するためにTimeをクリックします。
- クエリーによって返却された行の数とサイズを確認するためにRowsをクリックします。
- それぞれのクエリータスクで消費されたメモリーを確認するためにMemoryをクリックします。サブタスクがある場合には、**>**でそれぞれのサブタスクの詳細を確認できます。
- 右側で、クエリーのSQL文、ステータス、開始・終了時刻、期間、クエリー実行ユーザー、クエリー実行に用いられたウェアハウスを確認するためにOverviewをクリックします。
- タスクの説明文、タスク期間、消費メモリー、返却業の数とサイズのようなメトリクス、リネージュ(依存関係)といったタスクの詳細を確認するためにタスクをクリックします。
- サブタスクの詳細を閉じるには、Xをクリックします。
- ウェアハウスのプロパティを参照するにはSQLウェアハウス名をクリックします。
- Apache Spark UIでクエリープロファイルを表示するには、ページ上部にあるをクリックし、Open in Spark UIをクリックします。
- クエリープロファイルを閉じるには、ページ上部のXをクリックします。
クエリープロファイルの共有
別のユーザーとクエリープロファイルを共有するには、
- クエリー履歴を参照します。
- クエリー名をクリックします。
- クエリーを共有するには2つの選択肢があります。
- 他のユーザーがクエリーに対するCan Manage権限を持っているのであれば、クエリープロファイルのURLを共有することができます。Shareをクリックします。クリップボードにURLがコピーされます。
- あるいは、他のユーザーがCan Manage権限を持っていない、ワークスペースのメンダーではない場合、JSONオブジェクトとしてクエリープロファイルをダウンロードすることができます。Downloadをクリックします。ローカルシステムにJSONファイルがダウンロードされます。
クエリープロファイルのインポート
クエリープロファイルのJSONファイルをインポートするには、
-
クエリー履歴を参照します。
-
Importをクリックします。
-
共有されたJSONファイルをブラウザで選択し、Openをクリックします。JSONファイルがアップロードされ、クエリープロファイルが表示されます。
クエリープロファイルをインポートすると、動的にブラウザセッションにロードされワークスペースには永続化されません。参照したい都度、再インポートする必要があります。
-
インポートしたクエリープロファイルを閉じるには、ページ上部のXをクリックします。
次のステップ
- query history APIを用いたクエリーメトリクスへのアクセス方法を学びます。
- クエリー履歴について学びます。