How M Science Uses Databricks Structured Streaming to Wrangle Its Growing Data - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
この記事はM Scienceのデータサイエンス & データエンジニアリングチームによるゲスト投稿です。
モダンなデータは成長を止めません
「エンジニアはこれまでの人生経験を通じて、何かをクイックに行うことと、何かを正しく行うことは相互に排他的であるということを学んでいます!Databricksの構造化ストリーミングを用いることで、M Scienceでは毎回最初からインフラストラクチャを再構築することなしに、分析プラットフォーム上でスピードと精度の両方を手に入れることができています」– Ben Tallman, CTO
あなたはビッグデータ時代の「謙虚なデータ配管工」であり、オンライン小売データセット向けの分析ソリューションを構築するというタスクが与えられているものとします。
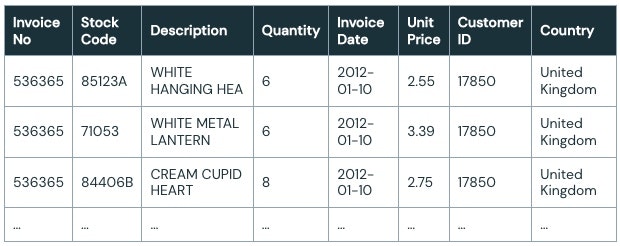
依頼された分析はシンプルなものであり、それぞれのストックコードごとのドル、販売ユニット、日毎のユニークなユーザー数の集計です。数行のPySparkコードで、生のデータを有用な集計結果に変換することができます。
import pyspark.sql.functions as F
df = spark.table("default.online_retail_data")
agg_df = (
df
# Group data by month, item code and country
.groupBy(
"InvoiceDate",
"StockCode",
)
# Return aggregate totals of dollars, units sold, and unique users
.agg(
F.sum("UnitPrice")
.alias("Dollars"),
F.sum("Quantity")
.alias("Units"),
F.countDistinct("CustomerID")
.alias("Users"),
)
)
(
agg_df.write
.format('delta')
.mode('overwrite')
.saveAsTable("analytics.online_retail_aggregations")
)
新たに作り出した集計データを用いて、素晴らしいビジュアライゼーションやビジネスに関することを実行できるようになります。
これはうまく動作します。そうでしょう?
データが更新されることがない静的な分析ではETLプロセスはうまく動作します。手元のデータは常にそのままであり続けるとの前提を置くことができます。静的な分析の問題とは何でしょうか?
モダンデータは成長を止めません
より多くのデータを手にするとした場合、どうしますか?
素朴な回答は、毎日同じコードを実行するというものかもしれません。しかし、コードを実行するたびに全てのデータを再処理することになり、新規の更新は既に処理済みのデータを再度処理することを意味します。データ増加すると、処理に要する時間と計算コストが膨大なものになってしまうことでしょう。
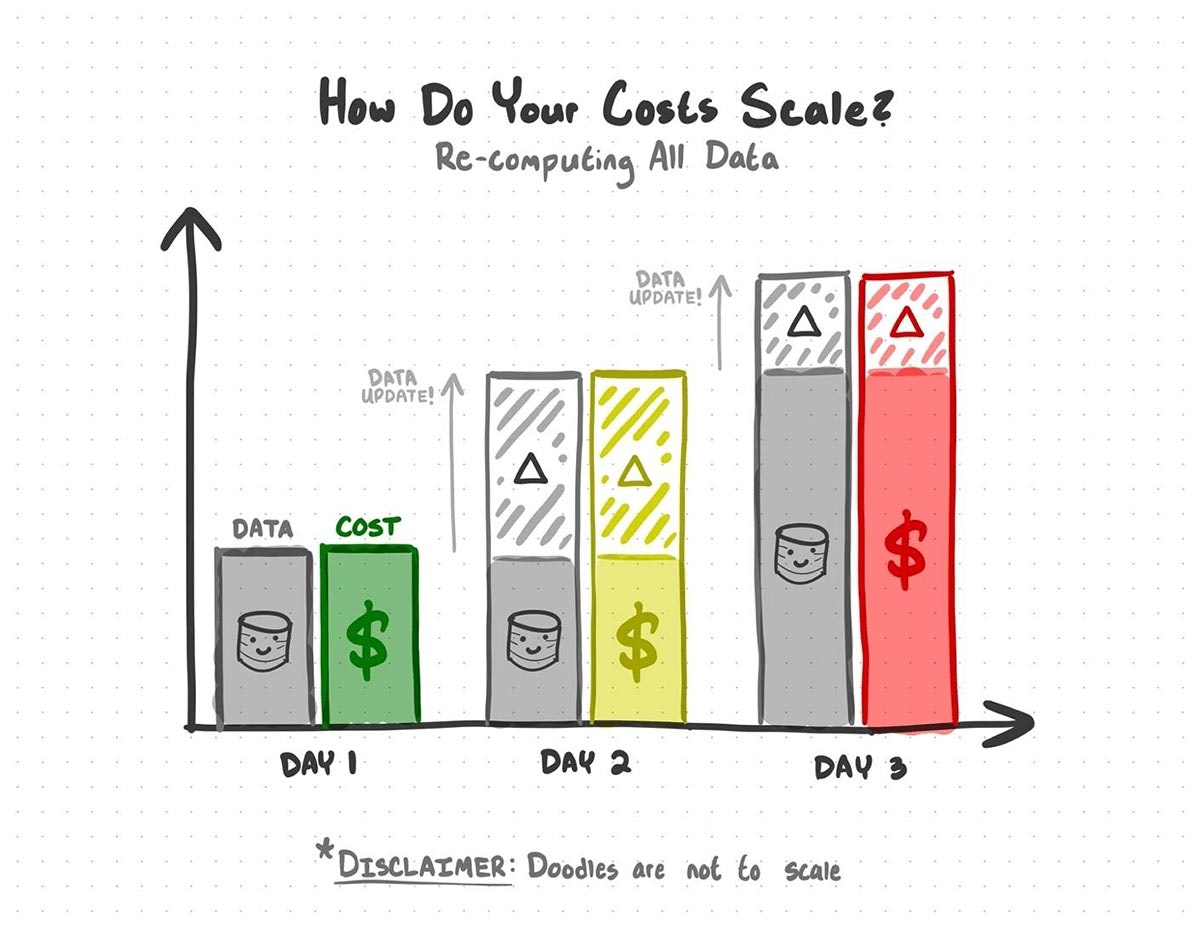
静的な分析では、既に処理済みのデータを再処理することにお金を費やすことになります。
更新されないモダンなデータソースというのは稀です。データソースの増大に対応し続け、かつ計算コストを削減するには、より良いソリューションが必要となります。
データが成長するのであれば我々はどうしたらいいのでしょうか?
過去数年で「ビッグデータ」という単語は...十分ではなくなってきています。データのボリュームが急激に増加し、生活の大部分がオンラインに移行することで、ビッグデータの時代は、「助けてください、データが大きくなるだけでは済まなくなっています」の時代になってしまいました。良いデータソースは、あなたが作業している間にも成長を止めないため、データプロダクトを最新の状態に保つことは非常に重要なタスクとなっています。
M Scienceにおけるミッションは、皆様が通常使用する四半期レポートやストックトレンドのデータソース以外のオルタナティブデータの活用です。市場や経済の変化を分析、改善、予測するためにこれらのデータを活用します。
日々、我々のアナリストやエンジニアは課題に直面しています。オルタナティブデータは非常に急速に成長しています。仮にデータが成長を止めたらとしたら、経済のどこかで非常にまずいことが起こっていると言っても過言ではありません。
データの成長とともに、我々の分析ソリューションもそれらの成長に対応する必要がありました。成長を考慮するだけではなく、順番を守らずに遅れて到着するデータを考慮する必要もありました。あらゆる新たなバッチデータには、経済で劇的な変化の兆候を示すバッチデータである可能性があるため、これは我々のミッションにおいて重要なことです。
M Scienceのアナリストとクライアントが毎日頼りにする分析プロダクトをスケーラブルなソリューションにするために、我々はDatabricksレイクハウスプラットフォームとSpark SQLエンジン上に構築されたスケーラブルかつ耐障害性を提供するApache Spark™ APIであるDatabricks構造化ストリーミングを活用しています。構造化ストリーミングを用いることで、データが成長したとしても、我々のソリューションもスケールすることを保証できます。
Spark構造化ストリーミングを使います
構造化ストリーミングは、データソースに新たなバッチデータが到着した際に活躍します。構造化ストリーミングは、更新部分のデータが何であるのかを特定するためにデータの変更箇所を追跡するDelta Lakeの機能を活用しており、新規データに影響を受ける分析の箇所のみを再計算します。
ストリーミングデータをどのように捉えるのかを再フレーミングすることが重要です。多くの人にとって、「ストリーミング」はリアルタイムのデータを意味しています。映画のストリーミング、Twitterのチェック、天気のチェックなどなど。あなたがアナリスト、エンジニア、サイエンティストであるのならば、更新されるデータば全てストリームとなります。更新頻度は問題ではありません。秒、時間、日、あるいは月ごとかもしれません。データが更新されるのであれば、そのデータはストリームです。データがストリームなのであれば、構造化ストリーミングがあなたの持つ多くの頭痛を取り去ってくれます。
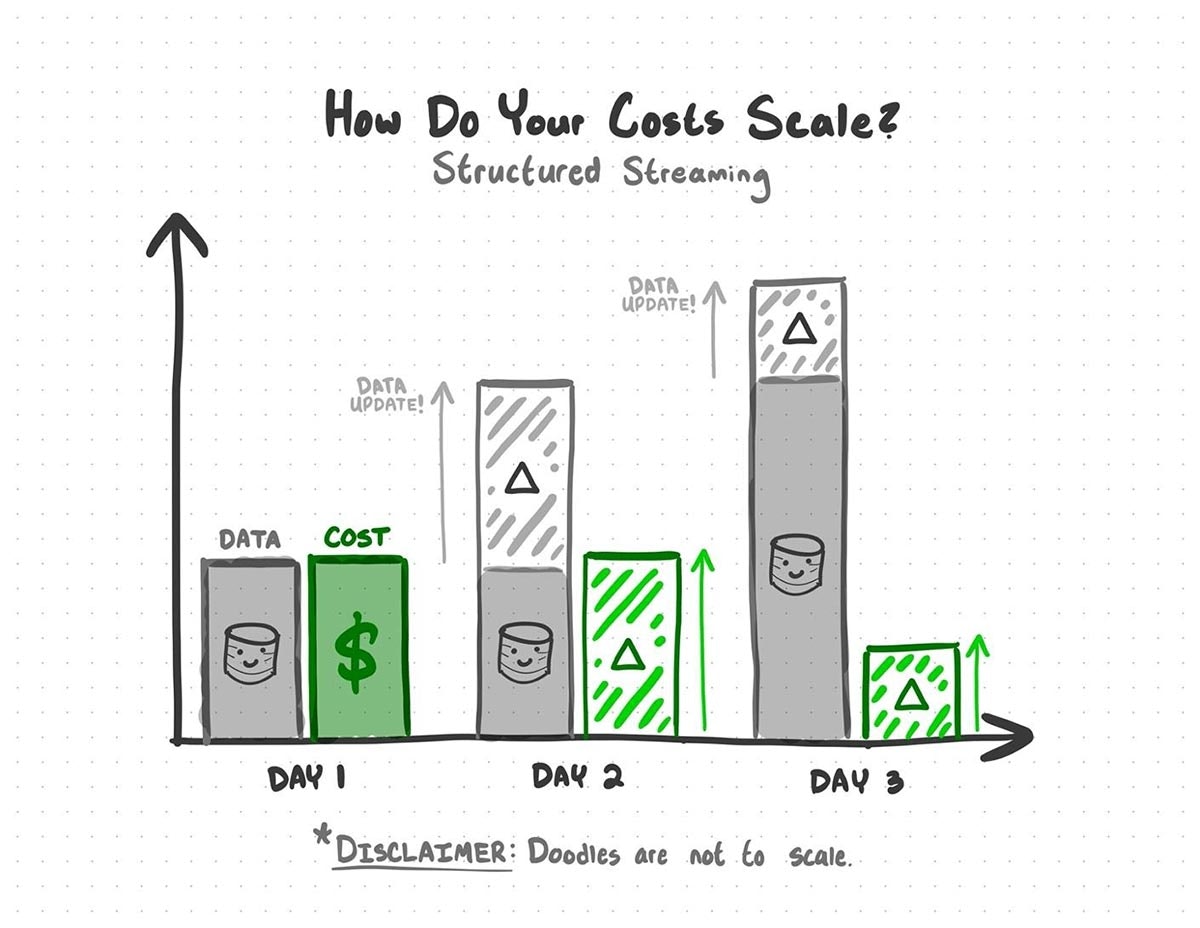
構造化ストリーミングを用いることで、以前のデータの再処理に伴うコストを回避することができます。
我々の仮説に戻りましょう。本日の集計結果を提供し、新たなデータが到着するたびに更新し続けなくてはならないものとします。今回は、前回の一度きりの分析の無益さを思い出させるために、DeliveryDateカラムが追加されています。
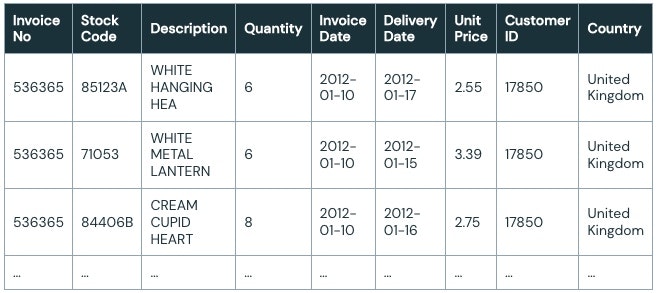
ありがたいことに、構造化ストリーミングのインタフェースは、オリジナルのPySparkのスニペットと信じられないほど同じようなものとなっています。こちらがオリジナルの静的なバッチ分析コードです。
# =================================
# ===== OLD STATIC BATCH CODE =====
# =================================
import pyspark.sql.functions as F
df = spark.table("default.online_retail_data")
agg_df = (
df
# Group data by date & item code
.groupBy(
"InvoiceDate",
"StockCode",
)
# Return aggregate totals of dollars, units sold, and unique users
.agg(
F.sum("UnitPrice")
.alias("Dollars"),
F.sum("Quantity")
.alias("Units"),
F.countDistinct("CustomerID")
.alias("Users"),
)
)
(
agg_df.write
.format('delta')
.mode('overwrite')
.saveAsTable("analytics.online_retail_aggregations")
)
いくつかの調整を施すことで、このコードで構造化ストリーミングを活用できるようになります。上のコードを変換するには、以下のことを行います。
- 静的なバッチデータではなくストリームとして入力テーブルを読み込みます。
- チェックポイントを格納するためのディレクトリをお使いのファイルシステムに作成します。
- ウォーターマークを設定し、分析で無視するまでデータの到着の遅延をどこまで待つのかの境界を定義します。
- 保存するチェックポイントの状態が大きくなりすぎないようにするために、変換処理を一部変更します。
- 入力データをインクリメンタルに処理するストリームとして最終的な分析テーブルを書き込みます。
これらの変更を行うことで、それぞれの変更に対して処理を行い、お使いのストリームの挙動をどのように設定するのかに関する幾つかのオプションを提供します。
こちらが「ストリーム化」されたバージョンのコードです。
# =========================================
# ===== NEW STRUCTURED STREAMING CODE =====
# =========================================
+ CHECKPOINT_DIRECTORY = "/delta/checkpoints/online_retail_analysis"
+ dbutils.fs.mkdirs(CHECKPOINT_DIRECTORY)
+ df = spark.readStream.table("default.online_retail_data")
agg_df = (
df
+ # Watermark data with an InvoiceDate of -7 days
+ .withWatermark("InvoiceDate", f"7 days")
# Group data by date & item code
.groupBy(
"InvoiceDate",
"StockCode",
)
# Return aggregate totals of dollars, units sold, and unique users
.agg(
F.sum("UnitPrice")
.alias("Dollars"),
F.sum("Quantity")
.alias("Units"),
+ F.approx_count_distinct("CustomerID", 0.05)
.alias("Users"),
)
)
(
+ agg_df.writeStream
.format("delta")
+ .outputMode("update")
+ .trigger(once = True)
+ .option("checkpointLocation", CHECKPOINT_DIR)
+ .toTable("analytics.online_retail_aggregations")
)
構造化ストリーミングが動作するように適用した変更を見ていきましょう。
-
Python
+ df = spark.readStream.table("default.online_retail_data")素晴らしいDeltaテーブルの機能の中で、これが最高なものだと思います。これらをストリームのように取り扱うことができます。Deltaは更新の記録を取るので、このプロセスを実行するたびに新規の更新をストリーミングするために
.readStream.table()を使うことができます。この処理を行うためには入力テーブルがDeltaテーブルでなくてはならないことに触れておくことも重要です。別の方法で他のデータフォーマットからストリーミングすることは可能ですが、
.readStream.table()ではDeltaテーブルが必要となります。 -
Python
+ # Create checkpoint directory + CHECKPOINT_DIRECTORY = "/delta/checkpoints/online_retail_analysis" + dbutils.fs.mkdirs(CHECKPOINT_DIRECTORY)構造化ストリーミングの用語では、この分析の集計処理はステートフルな変換処理となります。詳細を気にすることなしに、分析処理が更新されるたびに、構造化ストリーミングは集計処理の状態をチェックポイントとして保存します。
これによって、計算コストを劇的に削減することができます。毎回最初から全てのデータを再処理するのではなく、前回の更新以降のデータのみをシンプルに更新します。
-
Python
+ # Watermark data with an InvoiceDate of -7 days + .withWatermark("InvoiceDate", f"7 days")新規データを取得する際、順序を守らないデータを受け取る可能性があります。データをウォーターマーキングすることで、集計処理をどこまで遡って行うのかに関する期限を定義することができます。ある意味、「ライブ」と「安定した」の間の境界を作成することになります。
データプロダクトには月の7日までのデータが含まれているものとします。我々はウォーターマークを7日に設定したものとします。これは、7日から1日の集計結果はまだ「ライブ」であることを意味します。新たな更新によって1日から7日の集計結果が変化する可能性がありますが、7日以上遅れた新規データは更新処理に含まれません。1日以前の集計は「安定した」 ものであり、その期間に対する更新処理は無視されます。
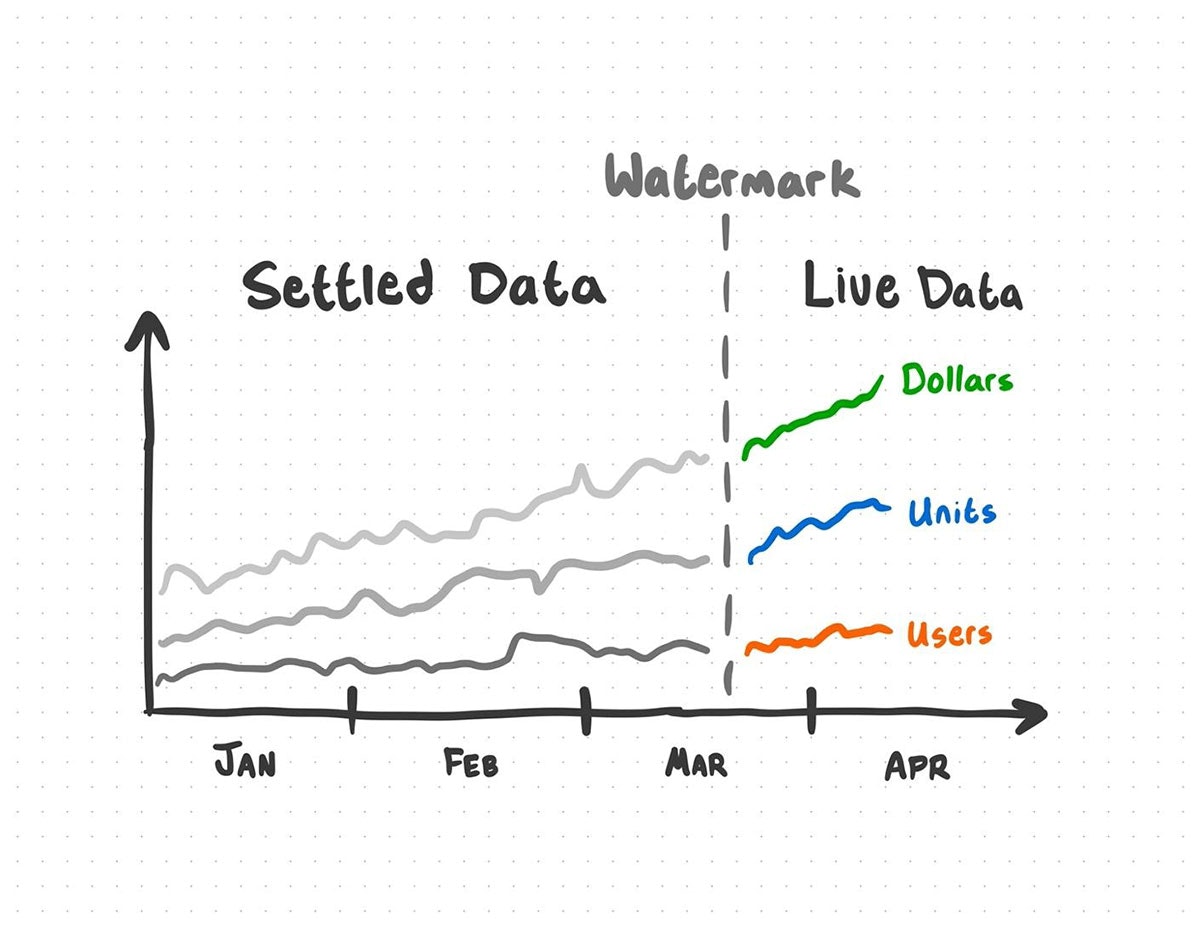
ウォーターマークの外の新規データは分析で考慮されません。ウォーターマークとして使用するカラムはTimestampかWindowでなくてはなりません。
-
Python
+ F.approx_count_distinct("CustomerID", 0.05)チェックポイントのステータスが膨大にならないようにするために、お使いの変換処理をよりストレージ効率の高いものに置き換える必要があるかもしれません。ユニークな個々の値を多く含むカラムに対してapprox_count_distinct関数を用いることで、定められた相対標準偏差を持つ結果を得ることができます。
-
Python
+ agg_df.writeStream .format("delta") + .outputMode("update") + .trigger(once = True) + .option("checkpointLocation", CHECKPOINT_DIR) + .toTable("analytics.online_retail_aggregations")最後のステップは分析結果のDeltaテーブルへの書き込みです。お使いのストリームがどのように動作するのかを決める幾つかのオプションがあります。
-
.outputMode("update")によって、コードが最初から動作するのではなく、ストリームは前回の場所からの変更をピックアップして集計処理が行われるように設定されます。"complete"を用いて従来のバッチ集計を行うこともでき、将来的な"update"の実行のために集計状態を保持することができます。 -
trigger(once = True)を用いることで、クエリーは一度のみ実行され、出力のコードがスタートする時点でクエリーが起動され、新規データの全ての処理が完了したらクエリーは停止されます。 -
"checkpointLocation"を用いることで、チェックポイントの場所を指定しています。
これらの設定オプションによって、オリジナルの一度きりのソリューションと同じようにストリームを動作させることができます。
これら全ては、データの成長に対応できるスケーラブルなソリューションを作成するために役立ちます。お使いのソースに新規のデータが追加されると、あなたの分析ソリューションは膨大なコストを要することなしに新規データを処理します。
-
ある時には、データが更新されないような文脈を見つけ出したい誘惑に駆られたかもしれません。データアナリスト、データエンジニア、データサインティストがモダンなデータに取り組む際には暗黙の了解が存在しています。データは成長し続けるものであり、これらの成長に対応するための方法を見つけ出さなくてはなりません。
Sparkの構造化ストリーミングを用いることで、規模と共にもたらされる頭痛を気にすることなしに、ベストなプロダクトを提供するために最新かつ素晴らしいデータを活用することができます。