以前、ネットワンシステムズ様に弊社Databricksマーケットプレイスのローンチデータパートナーとして参画いただきました。
こちらで公開されています。
本データセットは、netone valleyで収集されたセンサーデータを提供します。本データセットを利用する事で、理想的なデータやランダム生成されたデータではなく、実環境のデータ分析を行うことが可能となります。
本パッケージ内のデータには、温度、湿度、人数、環境騒音、二酸化炭素などが含まれています。
データおよびノートブックの取得

即時アクセス権を取得をクリックします。カタログ名は適宜変更します。
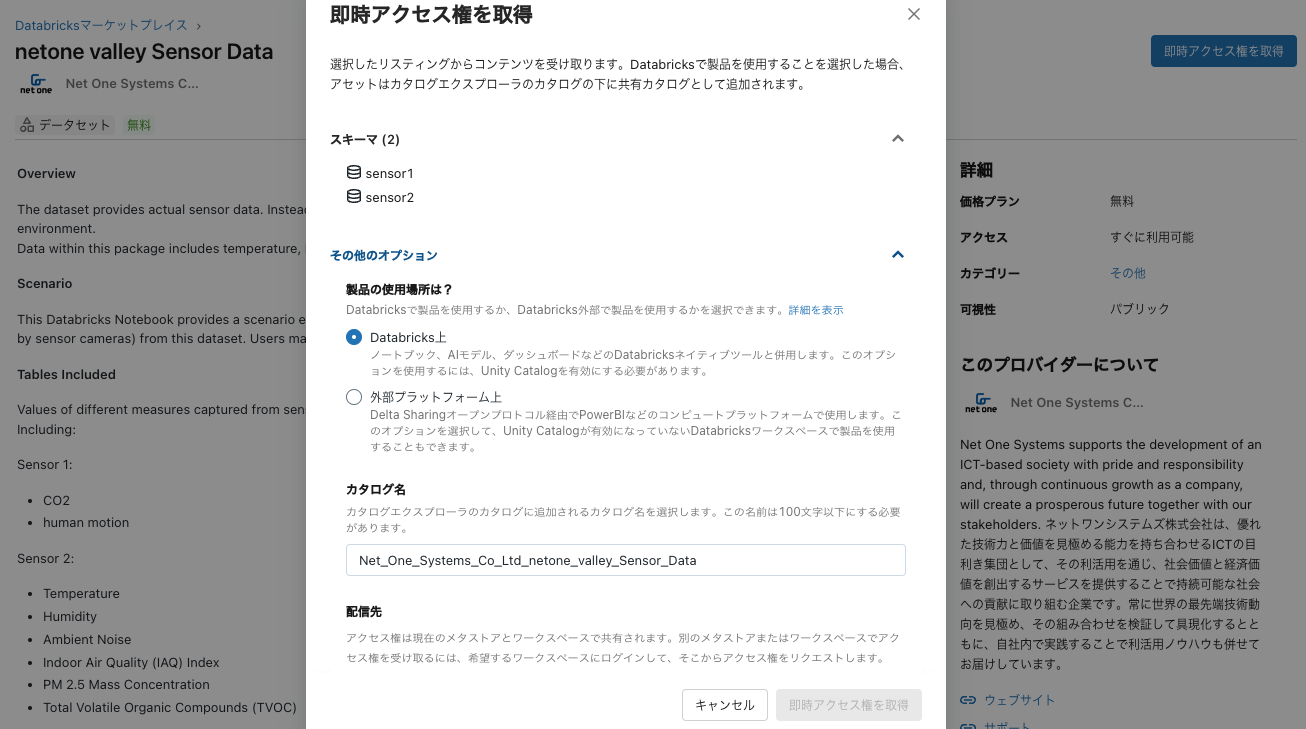
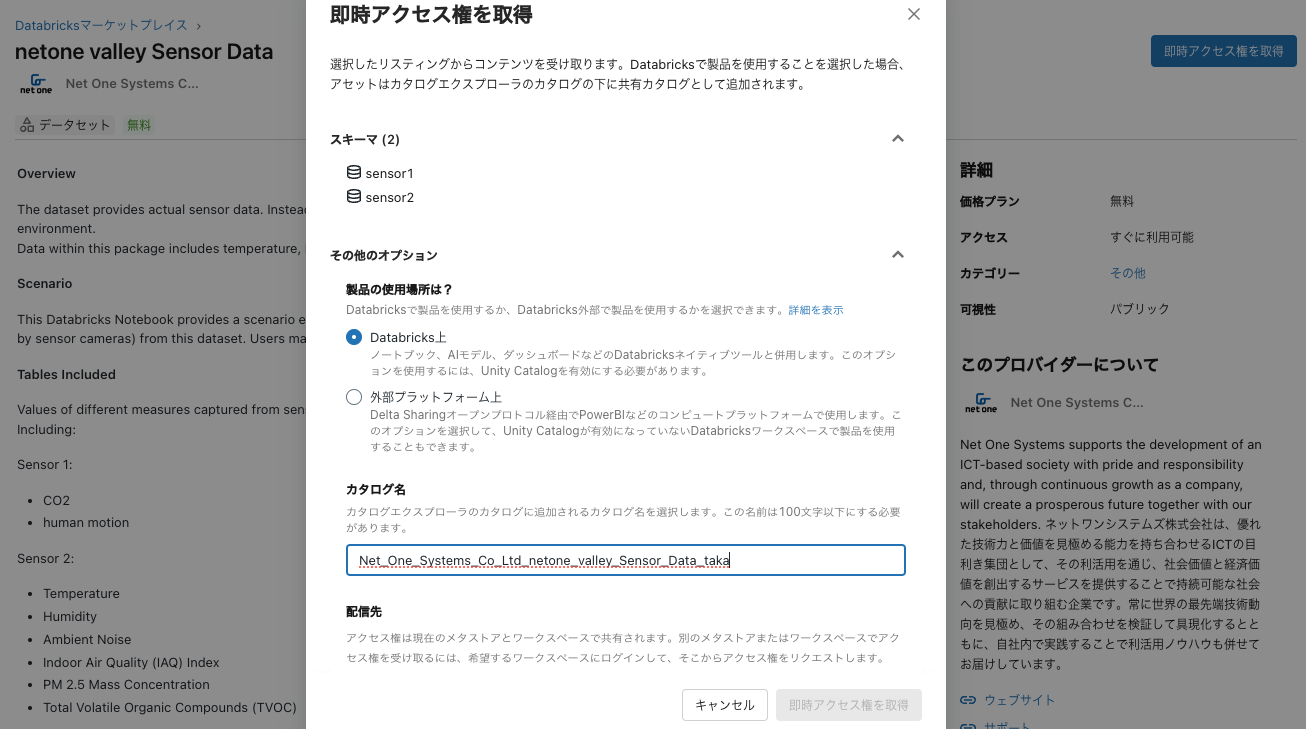
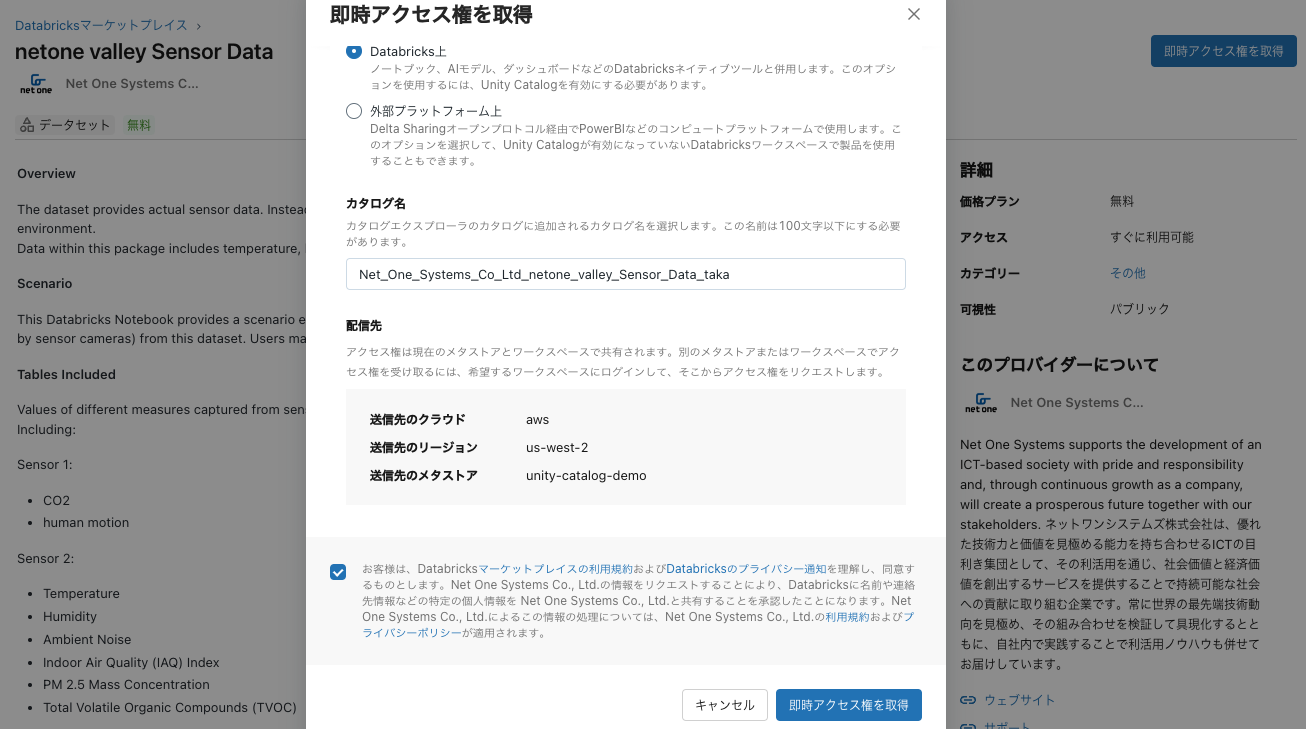
カタログエクスプローラでテーブルにアクセスできるようになります。

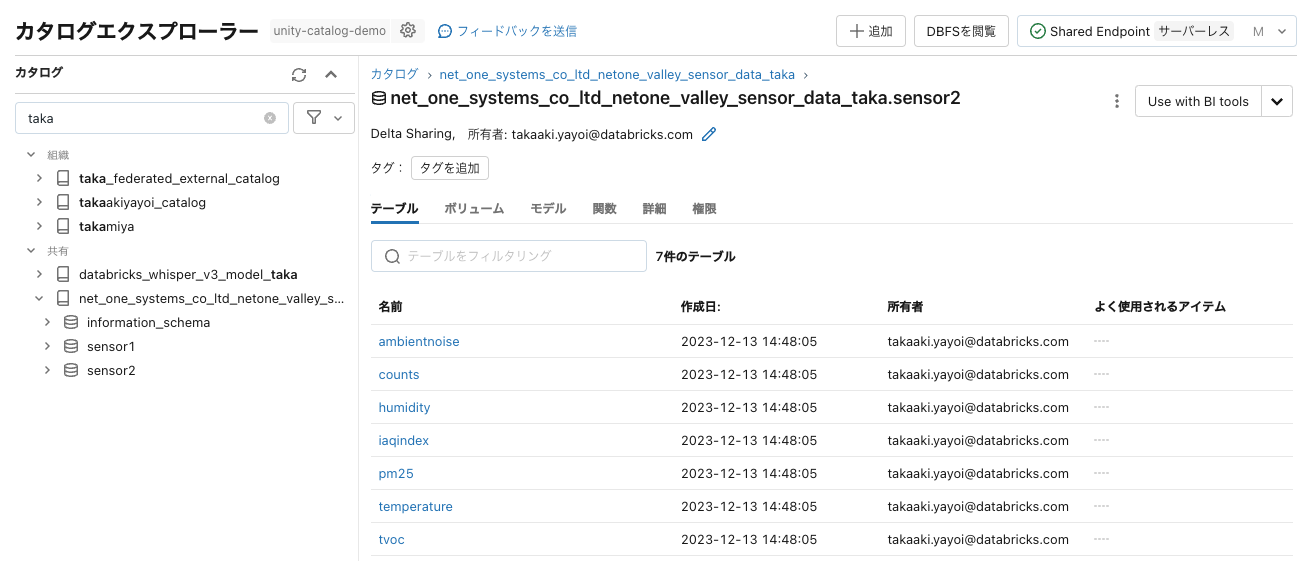
添付されているノートブックもインポートします。
ノートブックのウォークスルー
%pip install prophet
import pandas as pd
from prophet import Prophet
from pyspark.sql.functions import *
カタログ名は適宜変更します。
df = spark.table("net_one_systems_co_ltd_netone_valley_sensor_data_taka.sensor2.counts")
display(df)

# area1のデータを取得し、データ一覧の表示とデータの可視化させる
max_pop_area1_df = df.filter(df.areaid != "area1").select('ts','counts_max')
display(max_pop_area1_df)


# 時系列データをふさわしいタイムゾーンに調整
max_pop_area1_df = max_pop_area1_df.withColumn("Timezone=Asia/Tokyo", from_utc_timestamp(col('ts'), 'Asia/Tokyo')).sort(desc("Timezone=Asia/Tokyo"))
display(max_pop_area1_df)
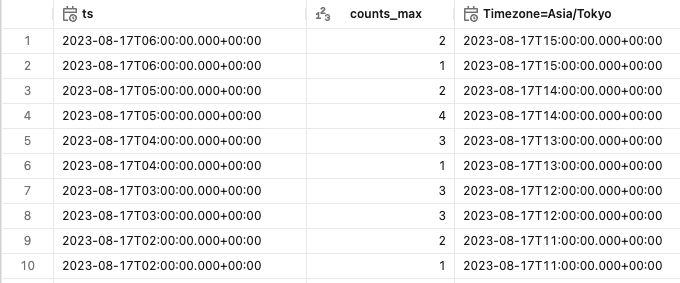
# Pyspark DataframeからPandas化させて、Prophetモデルに適合させるためカラム名を変更
area1_data_df = max_pop_area1_df.toPandas().drop(columns=["ts"]).rename(columns={"counts_max":"y","Timezone=Asia/Tokyo":"ds"})
area1_data_df
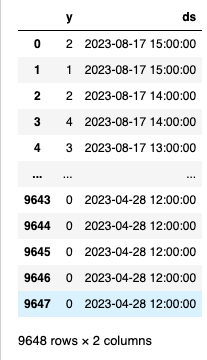
# データをProphetモデルにfit
m = Prophet()
m.fit(area1_data_df)
# 未来90日の予測データ結果を生成させる
future = m.make_future_dataframe(periods=90)
forecast = m.predict(future)
# 人数予測結果を表示
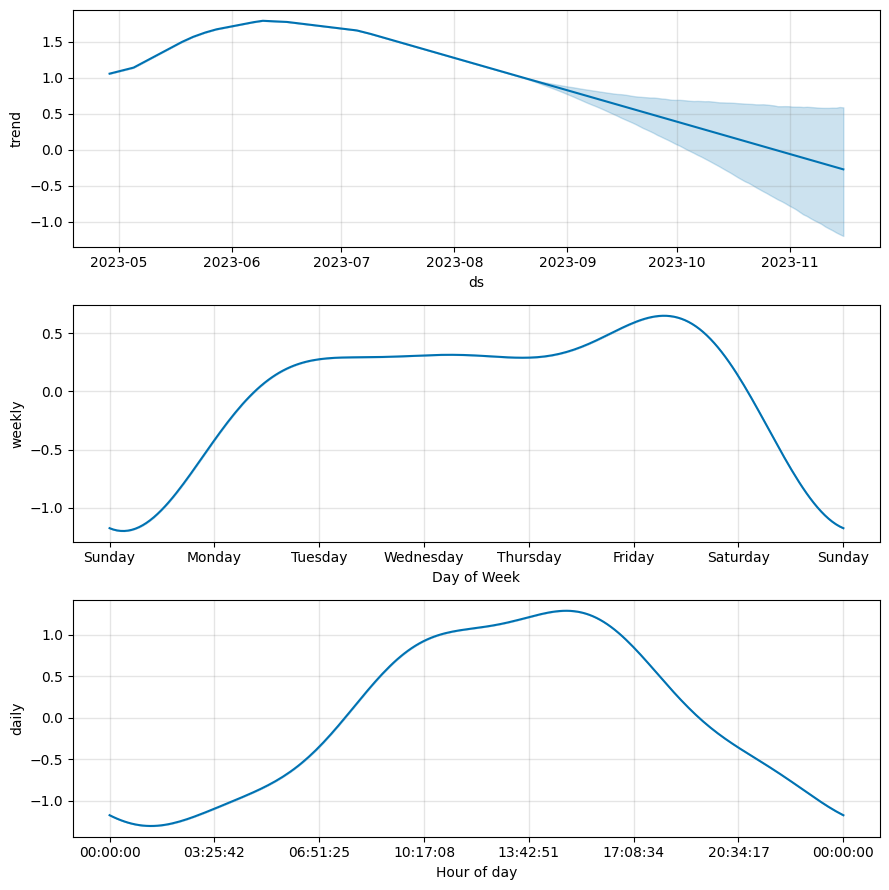
fig1 = m.plot(forecast)

fig2 = m.plot_components(forecast)
Databricksマーケットプレイスではプロバイダーを募集しています!