こちらの予測用サンプルノートブックをウォークスルーします。
ノートブック自体はこちらです。
要件
- Databricks機械学習ランタイム10.0以降。
- モデルの予測結果を保存するためには、Databricks機械学習ランタイム10.5以降が必要です。
注意
こちらのノートブックは、Databricks機械学習ランタイム12.2で動作確認しています。執筆時点では13.2など新しいランタイムでAutoMLを実行しようとするとエラーが発生します。
COVID-19データセット
このデータセットにはアメリカにおけるCOVID-19ウィルスの日毎の感染者数が位置情報と共に記録されています。ここでのゴールは、アメリカで次の30日にどれだけの感染者数が発生するのかを予測することです。
import pyspark.pandas as ps
df = ps.read_csv("/databricks-datasets/COVID/covid-19-data")
df["date"] = ps.to_datetime(df['date'], errors='coerce')
df["cases"] = df["cases"].astype(int)
display(df)
AutoMLのトレーニング
以下のコマンドはAutoMLの実行を起動します。引数target_colでモデルが予測すべきカラムと時刻のカラムを指定する必要があります。実行が完了すると、トレーニングのコードを検証するために、ベストな結果を示したトライアルのノートブックへのリンクにアクセスすることができます。
この例では以下も指定しています:
-
horizon=30で、AutoMLが未来の30日を予測すべきことを指定。 -
frequency="d"で、予測は日別で行うことを指定。 -
primary_metric="mdape"で、トレーニングの間に最適化するメトリクスを指定。
import databricks.automl
import logging
# fbprophetの情報に関するメッセージを抑制
logging.getLogger("py4j").setLevel(logging.WARNING)
# 注意: Databricks機械学習ランタイム10.4以前を使用している場合には、代わりに以下の行を実行してください:
# summary = databricks.automl.forecast(df, target_col="cases", time_col="date", horizon=30, frequency="d", primary_metric="mdape")
summary = databricks.automl.forecast(df, target_col="cases", time_col="date", horizon=30, frequency="d", primary_metric="mdape", output_database="default")
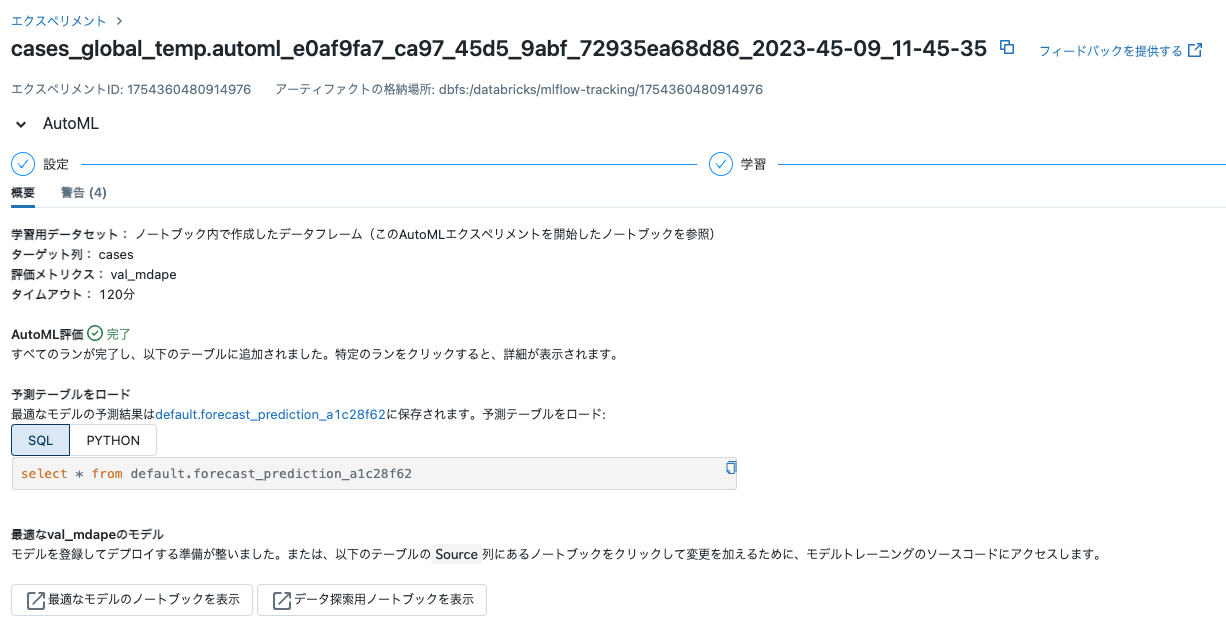
シングルノードクラスターでは14分ほどで完了しました。以下のようにノートブックへのリンクなどが表示されます。

データ探索用ノートブック

ベストなトライアルのノートブック
MLflowエクスペリメント
次のステップ
- 上でリンクされたノートブックとエクスペリメントを探索する。
- ベストなトライアルのノートブックのメトリクスが好適であれば、次のセルに進む。
- ベストなトライアルで生成されたモデルを改善したいのであれば:
- ベストなトライアルのノートブックに移動し、クローンする。
- モデルを改善するために必要に応じてノートブックを編集する。
- モデルに満足したら、トレーニングしたモデルのアーティファクトが記録されているURIをメモする。次のセルの
model_uri変数にこのURIを割り当てる。
ベストなモデルの予測結果の表示
注意: このセクションでは、Databricks機械学習ランタイム10.5以降が必要です。
ベストなモデルの予測結果のロード
Databricks機械学習ランタイム10.5以降でoutput_databaseが指定されている場合、AutoMLはベストなモデルの予測結果を保存します。
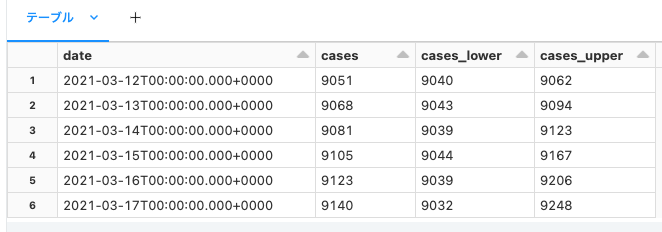
# 保存された予測結果のロード
forecast_pd = spark.table(summary.output_table_name)
display(forecast_pd)
予測にモデルを活用
このセクションのコマンドは、Databricks機械学習ランタイム10.0以降で使用することができます。
MLflowによるモデルのロード
AutoMLのtrial_idを用いることで、MLflowは容易にモデルをPythonに読み込むことができます。
import mlflow.pyfunc
from mlflow.tracking import MlflowClient
run_id = MlflowClient()
trial_id = summary.best_trial.mlflow_run_id
model_uri = "runs:/{run_id}/model".format(run_id=trial_id)
pyfunc_model = mlflow.pyfunc.load_model(model_uri)
予測を行うためにモデルを活用
予測を行うために、predict_timeseriesモデルメソッドを呼び出します。
Databricks機械学習ランタイム10.5以降では、予測データのみを取得するためにinclude_history=Falseを設定することができます。
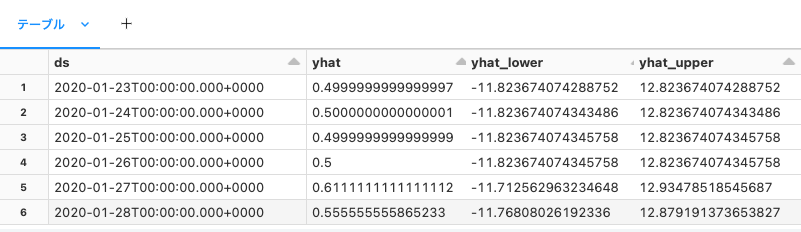
forecasts = pyfunc_model._model_impl.python_model.predict_timeseries()
display(forecasts)
# Databricks機械学習ランタイム10.5以降のみのオプション
#forecasts = pyfunc_model._model_impl.python_model.predict_timeseries(include_history=False)
#display(forecasts)
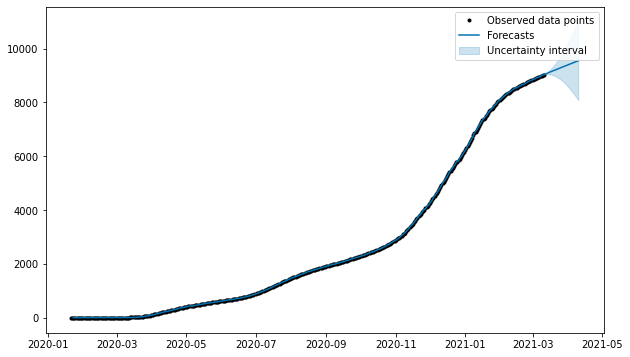
予測ポイントのプロット
以下のプロットでは、太い黒線が時系列データセットを示し、青い線がモデルによる予測です。
df_true = df.groupby("date").agg(y=("cases", "avg")).reset_index().to_pandas()
import matplotlib.pyplot as plt
fig = plt.figure(facecolor='w', figsize=(10, 6))
ax = fig.add_subplot(111)
forecasts = pyfunc_model._model_impl.python_model.predict_timeseries(include_history=True)
fcst_t = forecasts['ds'].dt.to_pydatetime()
ax.plot(df_true['date'].dt.to_pydatetime(), df_true['y'], 'k.', label='Observed data points')
ax.plot(fcst_t, forecasts['yhat'], ls='-', c='#0072B2', label='Forecasts')
ax.fill_between(fcst_t, forecasts['yhat_lower'], forecasts['yhat_upper'],
color='#0072B2', alpha=0.2, label='Uncertainty interval')
ax.legend()
plt.show()