Using SHAP with Machine Learning Models to Detect Data Biasの翻訳です。
開発者のサラリーとジェンダーの関係性に関して、機械学習とSHAPは何を伝えるのか
以下で説明されるステップを再現するためには、SHAPを用いたデータバイアス検知ノートブックをトライしてください。そして、さらに詳細を学ぶにはオンデマンドのウェビナーをご覧ください。
StackOverflowの年次開発者サーベイは、今年の初頭に結論づけを行い、匿名化した2019年の結果を公開しました。世界中のソフトウェア開発者の体験に対するリッチなビュー、彼らが好きなエディタは?経験年数は?タブあるいはスペース?そして、残酷なことですがサラリーなど、を提供してくれます。ソフトウェアエンジニアのサラリーは良いものですが、時には涙が出るほど高いものです。
テック業界は嫌々ながらも、それが常に実力主義の理想に沿ったものではないことに気づいています。給与は功績の純粋な関数ではなく、有名校、年齢、人種、ジェンダーがサラリーに影響を与えているという多くの話を聞きます。
機械学習に予測以上のことができるのでしょうか?機械学習は、サラリーを説明し、望ましくない給与格差を引きをこしている要因をハイライトすることができるのでしょうか?この例では、関心のある予測を行う個々のインスタンスを検知し、それらの予測に至ったデータに対する特定の理由にディープダイブするために、SHAP (SHapley Additive exPlanations)を用いて、どのように標準的なモデルを拡張できるのかを説明します。
モデルバイアス、バイアス(に関する)データ?
ここでのトピックは、「モデルバイアス」の検知として特徴付けられますが、モデルは単にトレーニングに用いたデータの鏡となっています。モデルに「バイアス」がある場合には、データの履歴上の事実から学習したということです。モデル自身は問題ではありません。これらは、データに対してバイアスの証拠を分析する機会を提供してくれます。
モデルの説明は新しいものではありません。多くのライブラリは、モデルへの入力の相対的な重要性にアクセスすることができます。これらは入力の影響に対する集積的なビューとなります。しかし、いくつかの機械学習モデルは、特に個人に対する影響を持っています:あなたのローンは承認されたか?あなたは経済的支援を受けられるのか?あなたは怪しい部外者か?
実際、StackOverflowは、このサーベイに基づき、ある人に期待されるサラリーを計算できる便利な計算機を提供しています。全体的に予測がどれだけ正確なのかだけを検査することができますが、全ての開発者は特に自身の見込みにのみ注意を払います。
適切な質問は、全体的にデータにバイアスがあるのか?ではなく、データには固有のバイアスの事例があるのか?ということになるでしょう。
StackOverflowサーベイデータの評価
幸運なことに、2019年のデータはきれいなものであり、データの問題はありません。これには、85の設問があり、約88,000人の開発者からの回答が含まれています。
この例では、フルタイムの開発者のみにフォーカスします。このデータセットには、経験年数、学歴、ロール、デモグラフィック情報など数多くの有益な情報が含まれています。注意すべき点としては、ボーナスや金融資産の情報は含まれておらず、サラリーのみが含まれているという点です。
また、ブロックチェーン、fizz buzz、サーベイ自身に対する態度に関する幅広い質問への回答も含まれています。これらは給与を決定づけるべきであろう経験、スキルを反映したものではないと考えられるため、ここでは除外します。また、シンプルにするためここではUSの開発者のみにフォーカスします。
モデル構築を行う前に少々変換処理が必要となります。いくつかの設問では、「開発者として最も大変だったチャレンジは何ですか?」のように複数回答を許容するものがあります。これらの個々の設問は、複数のyes/noの回答を生み出すため、複数のyes/noの特徴量に分割する必要があります。
「働いている企業・組織ではおおよそ何人の従業員がいますか?」のように、「2-9人の従業員」といった複数の回答を生み出します。これらは、効率的に連続値にビン分けされ、モデルはこれらの順序と相対的な大きさを考慮でき、「2」のような推定値にマッピングしなおすのに有用です。残念ながら、この変換はマニュアルで行う必要があり、判断を伴うものになります。
添付ノートブックのApache Sparkのコードではこれらの処理を行なっていますので、興味のある方はご一読ください。
Apache Sparkによるモデル選択
データを機械学習に適した形に変換したので、次のステップは、これらの特徴量からサラリーを予測する回帰モデルのフィッティングとなります。Sparkによるフィルタリング、変換によってデータセット自身は4MBとなり、12,600人の開発者の206の特徴量を含んでおり、容易にお使いのサーバーのメモリー上のデータフレームとして保持することができます。
有名な勾配ブースティングツリーのパッケージであるxgboostを用いることで、Sparkを用いなくても、シングルマシン上で数分でモデルのフィッティングを行うことができます。xgboostは、ツリーの深さ、学習率、正則化など、モデルの品質に影響を及ぼす数多くの「ハイパーパラメーター」を提供しています。自明のことですが、シンプルかつ標準的なプラクティスは、これらの値の数多くの組み合わせを試し、最も精度の良いモデルを生成したパラメーターの組み合わせを特定するというものです。
幸いにも、ここでSparkが再度登場します。数百のモデルを並列で構築し、それぞれの結果を収集します。データセットが小さいため、これをワーカーにブロードキャストし、ハイパーパラメーターの組み合わせパターンを生成し、それぞれの組み合わせを、ローカルにモデルを構築するシンプルなxgboostのコードにSparkを用いて適用します。
...
def train_model(params):
(max_depth, learning_rate, reg_alpha, reg_lambda, gamma, min_child_weight) = params
xgb_regressor = XGBRegressor(objective='reg:squarederror', max_depth=max_depth,\
learning_rate=learning_rate, reg_alpha=reg_alpha, reg_lambda=reg_lambda, gamma=gamma,\
min_child_weight=min_child_weight, n_estimators=3000, base_score=base_score,\
importance_type='total_gain', random_state=0)
xgb_model = xgb_regressor.fit(b_X_train.value, b_y_train.value,\
eval_set=[(b_X_test.value, b_y_test.value)],\
eval_metric='rmse', early_stopping_rounds=30)
n_estimators = len(xgb_model.evals_result()['validation_0']['rmse'])
y_pred = xgb_model.predict(b_X_test.value)
mae = mean_absolute_error(y_pred, b_y_test.value)
rmse = sqrt(mean_squared_error(y_pred, b_y_test.value))
return (params + (n_estimators,), (mae, rmse), xgb_model)
...
max_depth = np.unique(np.geomspace(3, 7, num=5, dtype=np.int32)).tolist()
learning_rate = np.unique(np.around(np.geomspace(0.01, 0.1, num=5), decimals=3)).tolist()
reg_alpha = [0] + np.unique(np.around(np.geomspace(1, 50, num=5), decimals=3)).tolist()
reg_lambda = [0] + np.unique(np.around(np.geomspace(1, 50, num=5), decimals=3)).tolist()
gamma = np.unique(np.around(np.geomspace(5, 20, num=5), decimals=3)).tolist()
min_child_weight = np.unique(np.geomspace(5, 30, num=5, dtype=np.int32)).tolist()
parallelism = 128
param_grid = [(choice(max_depth), choice(learning_rate), choice(reg_alpha),\
choice(reg_lambda), choice(gamma), choice(min_child_weight)) for _ in range(parallelism)]
params_evals_models = sc.parallelize(param_grid, parallelism).map(train_model).collect()
これによって、数多くのモデルが構築されます。結果を追跡し評価するために、mlflowがメトリクスとハイパーパラメーターを記録し、ノートブック上のエクスペリメントとして参照することができます。ここでは、数多くのランにおける一つのハイパーパラメーターと結果の精度(MSE)と比較しています。
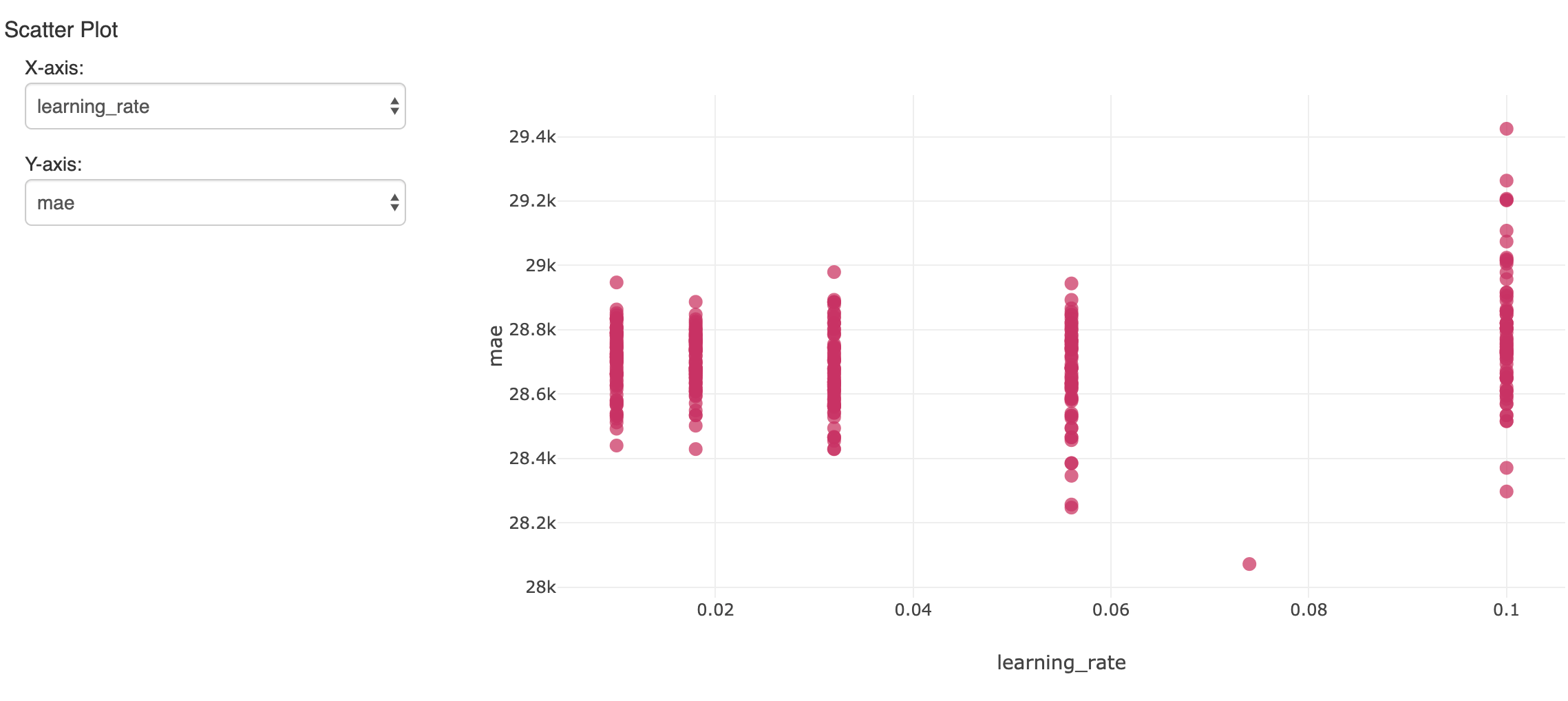
ホールドアウトしておいた検証用データセットにおいて、最も低い誤差を示した単一のモデルが興味の対象となります。平均誤差が$119,000であるのに対して、このモデルは$28,000の誤差を達成しています。恐ろしいことではありませんが、モデルはサラリーの変動の大部分を説明できるということを我々は理解しなくてはなりません。
xgboostモデルの解釈
モデルは将来的なサラリーを予測するために活用することができますが、ここでの疑問はモデルはデータに対してどのようなことを述べているのか、ということです。サラリーを正確に予測するために、どの特徴量が最も影響を与えているのでしょうか?xgboostモデル自身が、特徴量の重要度を計算します。
import mlflow.sklearn
best_run_id = "..."
model = mlflow.sklearn.load_model("runs:/" + best_run_id + "/xgboost")
sorted((zip(model.feature_importances_, X.columns)), reverse=True)[:6]
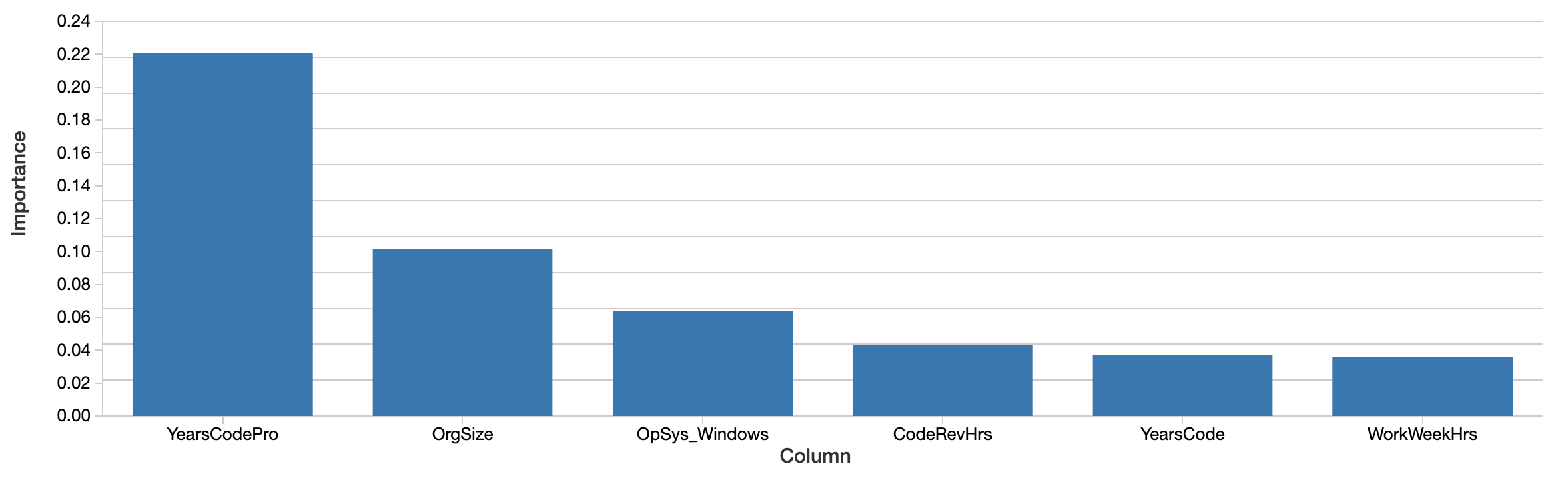
コーディングの経験年数、企業の規模、Windowsを使っているかといったファクターが最も「重要」となっています。興味深いことではありますが、解釈は困難です。この値は相対的なものであり、絶対値ではありません。すなわち、この効果はドルで計測されたものではありません。ここでの重要度の定義(トータルゲイン)は、どのように決定木が構築されたのかにフォーカスしたものであり、直感的な解釈にマッピングすることが困難です。この特徴量の重要度は、必ずしもサラリーと正の相関があるとも限りません。
さらに重要なことですが、これは全体として特徴量がどれだけ影響しちえるのかの「グローバル」なビューとなっています。ジェンダーや人種のようなファクターはこのリストの上位には現れてきません。これは、これらのファクターが重要ではないということを意味するわけではありません。例えば、特徴量に相関や相互作用があるケースがあり得ます。性別のようなファクターが、決定木によって選択された別の特徴量と相関しており、このことによって、ジェンダーの効果がある程度隠されてしまうケースが考えられます。
より興味深い質問は、これらのファクターが全体的にどの程度影響しているのかというものではありません。これらの平均的な影響は比較的小さい場合があります。ここでの質問は、いくつかの特定のケースにおいては大きな影響を及ぼすかどうかというものです。これは、モデルが個人の体験に関して重要な何かを知らせてくれる事例となり、この個人にとっては、この体験が問題となります。
開発者レベルでの説明のためのSHAPパッケージの適用
幸いにも、5年ほど前から理論的に優れた個人の予測レベルにおけるモデル解釈のための技術が出現しています。これらをまとめて「Shapley Additive Explanations」と呼んでおり、Pythonパッケージshapとして実装されています。
あらゆるモデルに対して、このライブラリはモデルから「SHAP値」を計算します。これらの値は予測に対する特徴量の影響を自身の単位で示しているので、すぐに解釈することができます。SHAP値1000はここでは「予測されるサラリーを+$1,000」と説明されます。また、SHAP値は、相関や相互作用を分離するようにして計算されます。
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X, y=y.values)
SHAP値はモデル全体ではなく、全ての入力に対して計算することができるので、全ての入力それぞれに対して説明を行うことができます。それぞれの特徴量の主要な効果とは別に、それぞれの予測における特徴量の相互作用の効果を推定することができます。
説明可能なAI: 全体的な特徴量の影響を明らかに
開発者レベルの説明は、それぞれの絶対値を単純に平均することで、データセット全体のサラリーに対する特徴量の影響をの説明に集計することができます。最も重要な特徴量全体のSHAPの評価は類似したものになります。
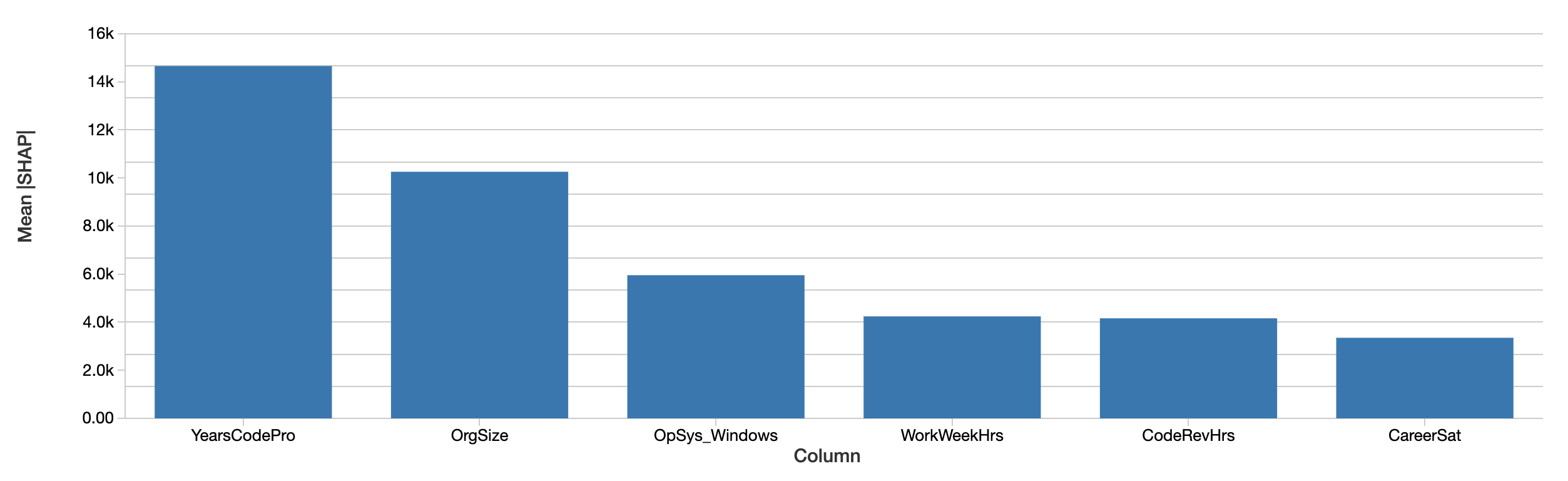
SHAP値は同じストーリーを伝えています。まず、SHAPはサラリーに対する影響をドルで定量化しており、結果の解釈を劇的に改善しています。上のプロットは、予測したサラリーに対するそれぞれの特徴量の絶対的な効果を開発者で平均したものを示しています。コーディング経験年数が依然として支配的であり、サラリーに対して$15,000の影響を与えています。
SHAP値によるジェンダーの効果の検証
サラリー自体を予測するのには用いられなかった、ジェンダー、種族などの他のファクターの影響を見ていきましょう。この例では、探索するバイアスのうち最も重要なものではありませんが、性別の影響を見てみます。
ジェンダーは2値ではありません。このサーベイでの回答は「男性」、「女性」、「性的マイノリティ、未確認」、「トランス」があります(このサーベイでは性別の質問が別にありますが、ここでは考慮しません)。SHAPはそれぞれにおける予測サラリーに対する影響度を計算します。男性の開発者(「male」として識別)においては、ジェンダーの効果は、男性であることによる効果ではなく、女性、トランスジェンダーとして識別されなかったものによるものです。
SHAP値によって、4つのカテゴリーにおける開発者の効果の総和を読み取ることができます。

男性の開発者のジェンダーは、平均値$225、-$230から$890のそれなりの影響を説明しています。女性の場合、範囲は-$4,260から-$690へと広がり、平均は-$1,320となります。トランスジェンダーおよび不明の開発者の場合にも同様の傾向を示していますが、若干値が高くなっています。
これが何を意味するのかを評価する際には、ここでのデータとモデルの制限を思い出すことが重要です。
- 相関は因果ではありません。予測されたサラリーの「説明」は示唆的なものであり、特徴量が直接的にサラリーの増減を決めたことを証明しているわけではありません。
- モデルは完全に正確というわけではありません。
- このデータはUSの1年分のデータです。
- これはベースサラリーのみを反映したものであり、より変動幅の大きいボーナスや株を考慮していません。
ジェンダーと相互作用する特徴量を可視化するためにSHAPを利用
SHAPライブラリは特徴量の相互作用の効果を分離するために活用できる興味深い可視化機能を提供します。例えば、上述の値は、男性と識別された開発者は、他の場合よりも若干高いサラリーを得ると予測することを示唆していますが、他にはないのでしょうか?依存性のプロットが役立ちます。
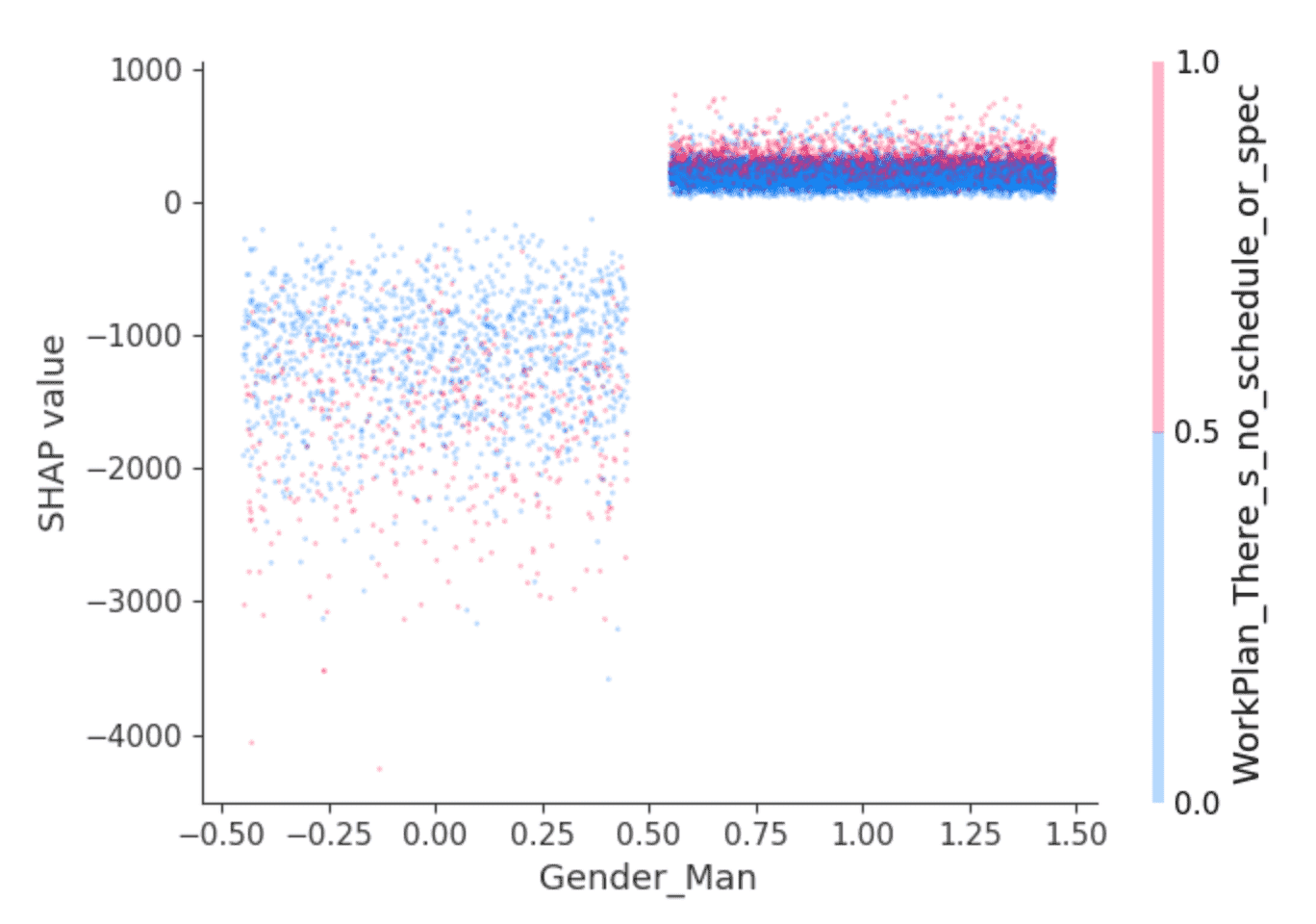
点が開発者となります。左側の開発者は、男性と識別されなかった開発者で、右側は男性と識別された開発者です(見やすくするために、点は水平方向にランダムに分散させています)。y軸はSHAP値となり、それぞれの開発者のサラリーを予測する際に、男性であるか否かがどのように影響しちえるのかを説明しています。上のように、男性と識別されなかった開発者は全体的に負のSHAP値、高い振れ幅を示しており、そうでない場合には小さな正のSHAP値となっています。
この差は何を意味するのでしょうか?SHAPでは、特定の値、ここでは男性と識別されるか否かを最も変化させた2番目の特徴量を選択することができます。ここでは、質問「あなたの仕事は構造化、計画されていますか?」に対して「最も重要か緊急に見える仕事をしているようだ」という回答が選択されました。男性と識別された開発者においては、このように答えた方々(赤い点)は若干高いSHAP値を示しています。残りに関しては、効果はより混ざっていますが、一般的に低いSHAP値を示しているように見えます。
読み手に解釈は委ねられますが、おそらく、このような感覚で下支えされている男性の開発者は若干高いサラリーを楽しんでおり、この感覚を持っている他の開発者は手と手を取って低いサラリーに甘んじているということになるのでしょうか?
極端なジェンダーの効果の例の探索
サラリーに最もネガティブな影響を受けた開発者を調査してみましょう。ジェンダーに関連する特徴量の全体的な影響を見ることができるのと同じように、予測されたサラリーにジェンダーに関連する特徴量が最も影響を与えた開発者を検索することができます。この人物は女性であり、影響はネガティブなものとなっています。このモデルによると、彼女はジェンダーのために年間$4,260の収入減と予測されました。

予測されたサラリーは$157,000となっており、実際のサラリーは$150,000であったため、この場合予測は正確なものとなっています。
彼女の予測サラリーに、最もポジティブ、ネガティブな影響を与えた特徴量は以下の通りとなっています。
- 大学の学位(のみ)をもっている(+$18,200)
- 10年の職業経験がある(+$9,400)
- 東部アジア人と識別された(+$9,100)
- ...
- 週40時間勤務(-$4,000)
- 男性と識別されなかった(-$4,250)
- 100-499人規模の中規模の組織に勤務(-$9,700)
男性と識別されなかったことによる予測サラリーへの影響度合いを考えると、ここでストップし、オフラインで調査を行い、この開発者に関わる文脈、経験、サラリーを理解した方がいいのかもしれません。
SHAP値を用いた相互作用の説明
この-$4,260から、さらに詳細な情報を得ることができます。SHAPはこれらの特徴量の影響を相互作用にブレークダウンすることができます。女性と識別されることによる予測へのトータルの影響は、女性として識別されること、そして、エンジニアリングマネージャーであること、そして、Windowsを使っていることなどの影響にブレークダウンすることができます。
ジェンダーファクターで説明される予測サラリーに対する影響は、合算で約-$630のみとなります。むしろ、SHAPはジェンダーの影響の多くを他の特徴量に割り当てています。
gender_interactions = interaction_values[gender_feature_locs].sum(axis=0)
max_c = np.argmax(gender_interactions)
min_c = np.argmin(gender_interactions)
print(X.columns[max_c])
print(gender_interactions[max_c])
print(X.columns[min_c])
print(gender_interactions[min_c])
DatabaseWorkedWith_PostgreSQL
110.64005
Ethnicity_East_Asian
-1372.6714
女性と識別されること、PostgreSQLで作業していることは、サラリーに若干ポジティブな影響を与えており、東部アジア人として識別されることはサラリーにネガティブな影響を与えています。この粒度でこれらの値を解釈することは、この文脈では困難ですが、この追加レベルでの説明も可能です。
Apache SparkによるSHAPの適用
SHAP値は、与えられたモデルを用いて、それぞれの行に対して独立で計算できるので、Sparkによる並列処理が可能です。以下の例では、並列でSHAP値を計算し、特に大きいジェンダー関係のSHAP値を持つ開発者を特定しています。
X_df = pruned_parsed_df.drop("ConvertedComp").repartition(16)
X_columns = X_df.columns
def add_shap(rows):
rows_pd = pd.DataFrame(rows, columns=X_columns)
shap_values = explainer.shap_values(rows_pd.drop(["Respondent"], axis=1))
return [Row(*([int(rows_pd["Respondent"][i])] + [float(f) for f in shap_values[i]])) for i in range(len(shap_values))]
shap_df = X_df.rdd.mapPartitions(add_shap).toDF(X_columns)
effects_df = shap_df.\
withColumn("gender_shap", col("Gender_Woman") + col("Gender_Man") + col("Gender_Non_binary__genderqueer__or_gender_non_conforming") + col("Trans")).\
select("Respondent", "gender_shap")
top_effects_df = effects_df.filter(abs(col("gender_shap")) >= 2500).orderBy("gender_shap")
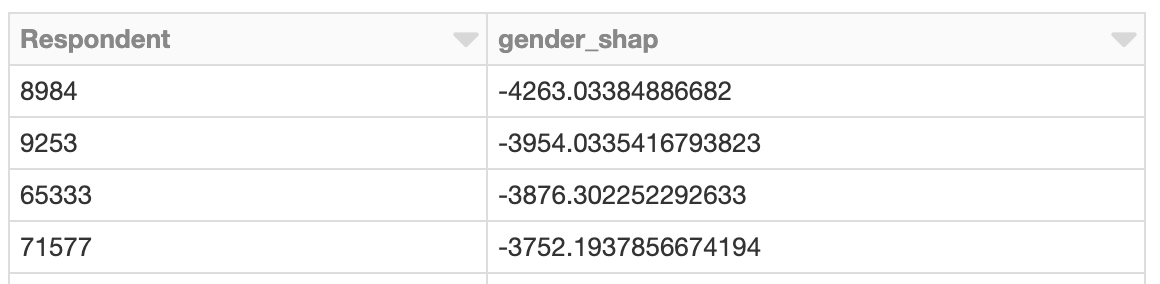
SHAP値のクラスタリング
SHAPを用いて大規模の予測を評価する際には、Sparkを活用するメリットがあります。アウトプットを得た後は、例えば、bisecting k-meansを用いて、結果のクラスタリングにSparkを活用することができます。
assembler = VectorAssembler(inputCols=[c for c in to_review_df.columns if c != "Respondent"],\
outputCol="features")
assembled_df = assembler.transform(shap_df).cache()
clusterer = BisectingKMeans().setFeaturesCol("features").setK(50).setMaxIter(50).setSeed(0)
cluster_model = clusterer.fit(assembled_df)
transformed_df = cluster_model.transform(assembled_df).select("Respondent", "prediction")
ジェンダー関係のSHAP値のトータルが最もネガティブな値を示したクラスターに関しては、さらなる調査が必要になるかもしれません。クラスターに含まれる回答者のSHAP値は何になるのでしょうか?クラスターのメンバーは全体的な開発人口に対してどのように見えるのでしょうか?
min_shap_cluster_df = transformed_df.filter("prediction = 5").\
join(effects_df, "Respondent").\
join(X_df, "Respondent").\
select(gender_cols).groupBy(gender_cols).count().orderBy(gender_cols)
all_shap_df = X_df.select(gender_cols).groupBy(gender_cols).count().orderBy(gender_cols)
expected_ratio = transformed_df.filter("prediction = 5").count() / X_df.count()
display(min_shap_cluster_df.join(all_shap_df, on=gender_cols).\
withColumn("ratio", (min_shap_cluster_df["count"] / all_shap_df["count"]) / expected_ratio).\
orderBy("ratio"))
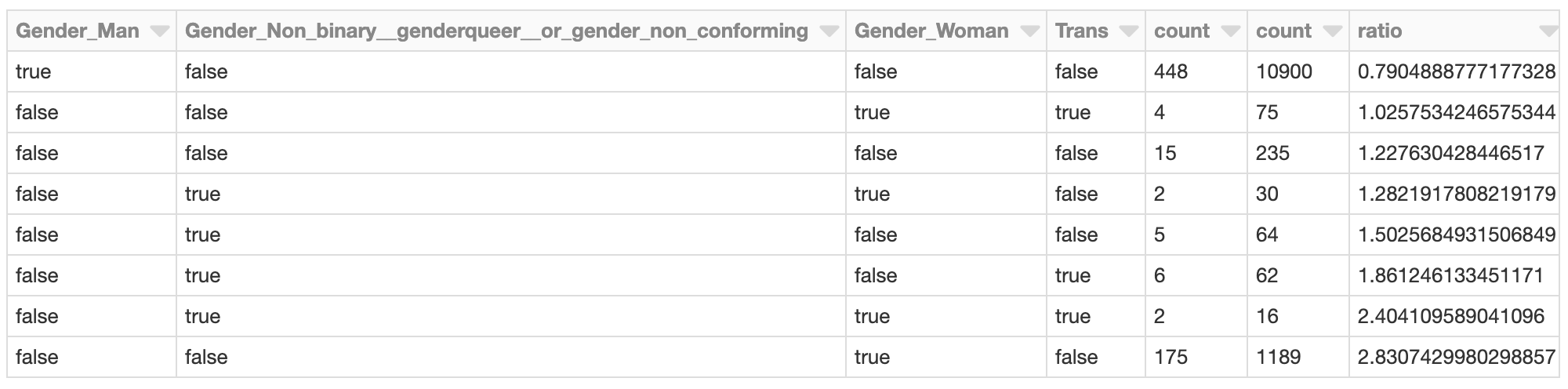
クラスターで表現される、女性(のみ)と識別された開発者は、例えば、全体的な開発者人口において、最大の2.8の比率を示しています。これは初期の分析を踏まえると、驚くことではありません。このクラスターにおいては、この固有のグループの低い予測サラリーに影響を及ぼした他のファクターを評価するために、さらなる調査が必要かもしれません。
まとめ
SHAPを用いたこの種の分析は、あらゆるモデル、あらゆる規模に対して実行することができます。分析ツールとしては、モデルをデータに対する探偵に変化させ、より検証が必要な予測の個別の事例を浮かび上がらせます。SHAPのアウトプットは容易に解釈でき、直感的なプロットを生成することができ、ビジネスユーザーによってケースごとに評価を行うことができます。
もちろん、この分析はジェンダー、年齢、種族のバイアスに対する疑問の検証に限定されるものではありません。顧客解約モデルに適用することもできます。ここでの疑問は「この顧客は解約するのか?」ではなく「なぜ顧客は解約するのか?」というものになります。価格起因で解約するお客様に対してはディスカウントを提案し、利用料が限定されているお客様に対してはアップせるを提案することができます。
最後に、この分析は検証プロセスの一部として実行することもでき、全体的な機械学習モデルに対する優れた透明性をもたらします。モデル検証は多くのケースでモデルの全体的な精度にフォーカスしがちです。モデルの「理由付け」や何の特徴量が予測に寄与しているのかにもフォーカスすべきです。SHAPを用いることで、個々の予測の説明の多くが、全体的な特徴量の重要度と噛み合わないケースを検知できるようになります。