Optimizing Order Picking to Increase Omnichannel Profitability with Databricks - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
詳細を確認し、ノートブックするためには、新たなオーダーピッキング最適化ソリューションアクセラレータにアクセスしてみてください。
オンライン購入/店舗ピックアップ(BOSIPS)、同日中の配送への要求によって、小売業者は迅速なフルフィルメントセンターとして地域の店舗を活用しなくてはならなくなっています。パンデミックの不意をつかれた時期の初めには、多くの小売業者は迅速に商品を配達するために既存の店舗在庫とインフラストラクチャを用いてこれらのサービスを導入し、可用性を拡大しようと殺到しました。顧客が店舗に戻っても、これらのサービスに対する要件は衰えず、最近の調査では向こう数年においてもより多くより迅速な選択肢に対する期待は高まる一方であるということが示されています。これにより、小売業者は引き続き長期的な視点でこれらの機能をどのように提供するのがベストなのかを考え続けなくてはならない状況にあります。
現在多くの小売業者が直面している重要な課題は、商品を顧客にどのようにして迅速に配達することではなく、収益性を維持しつつ迅速に配達を行うのかということです。迅速に注文を充足するためにオンラインで行われる注文ごとに、マージンが3〜8パーセントポイント減少していると推定されています。注文ごとに作業員を店舗の棚に送り出すコストが最も疑わしい容疑者であり、労働者のコストは増加の一途を辿る(そして、顧客はベースラインのサービスで何が増加しているのかにはほとんど興味がありません)ことで、小売業者は恐れ慄いています。
ピッキングの効率を最適化する自動倉庫やダークストアがソリューションとして提案されてきました。しかし、必要となる初期投資と大規模ではない市場におけるこのようなモデルの有効性に関する疑問によって、多くの人々を既存の店舗敷地を活用し続けることにフォーカスさせました。実際、世界最大の小売業者であるWalmartは最近、彼らの取り組みの効率性を改善する目的において、店舗内の変更を行う方向性に対するコミットメントを発表しました。
店舗のレイアウトは意図的に非効率なものとなっています
Walmartや多くの企業によって提案されているフルフィルメントモデルにおいては、既存の店舗敷地は高速フルフィルメント戦略のコアコンポーネントとなっています。これらのモデルで最もシンプルなものでは、作業員は店舗のレイアウトを移動し、オンライン注文の商品をピックアップし、カウンターやバックルームでパッケージングされて出荷されます。最も洗練されたモデルにおいては、需要の高い商品はバックルームのフルフィルメントエリアに整理され、生産性が低下するような作業員の店舗フロアへの移動を限定します。
店舗におけるピッキングの生産性定価はデザインによるものです。従来型の小売のシナリオにおいては、小売業者は顧客の店舗内時間を増加させるために、顧客によって提供される無料の労働力を活用します。訪問中に頻繁に必要となる商品をピックアップするために顧客を店舗の一方から一方に移動させることで、小売業者は顧客に対して提供可能な商品やサービスの露出を増やすことができます。このようにすることで、小売業者は追加で購入してもらうことで収益性を高めています。
顧客に代わって注文のピッキングを行う作業員にとっては、衝動的な購入は当たり前ですが選択肢とはならず、長い移動時間はフルフィルメントのコストを増加させるだけです。あるアナリストは「店舗環境の生産性を殺すのは移動距離です」と述べています。顧客が対面で購入する確率を最大化する店舗デザインの意思決定は、オムニチャネルのフルフィルメントに責務を持つ人たちにとっては逆行するものです。
顧客はこれを知っていますが、ピッキング担当者はそうではありません
多くの顧客は、多くの店舗レイアウトにおけるこの本質的な非効率性を理解しています。節約家の顧客は大抵購入する商品のリストを持ち歩き、棚間の移動の行ったり来たりを最小化するために、リスト上の商品の順序を最適化します。商品配置や特定商品の取り扱い方法に対する知識によって、店舗を効率的に移動し、移動中に商品を壊してしまうことで繰り返しの移動が発生する可能性を最小化します。
しかし、数年に渡って何度も商品を購入することによる経験から得られるこの知識は、一時的な副業として他の人の注文のピッキングを行うギグワーカーは持ち得ません。これらの作業員にとって、ピッキングリスト上の商品は、最適な順序に関するアイデアを提供しないので、作業員は注文リスト通りに店舗内で商品をピッキングするために移動することになります。
ピッキング順序の最適化が役立ちます
Pietriらによって最近発表された論文The Buy-Online-Pick-Up-in-Store Retailing Model: Optimization Strategies for In-Store Picking and Packingでは、図1に示すレイアウトを持つ現実の雑貨店において、いくつかのピッキング順序最適化を検証しました。
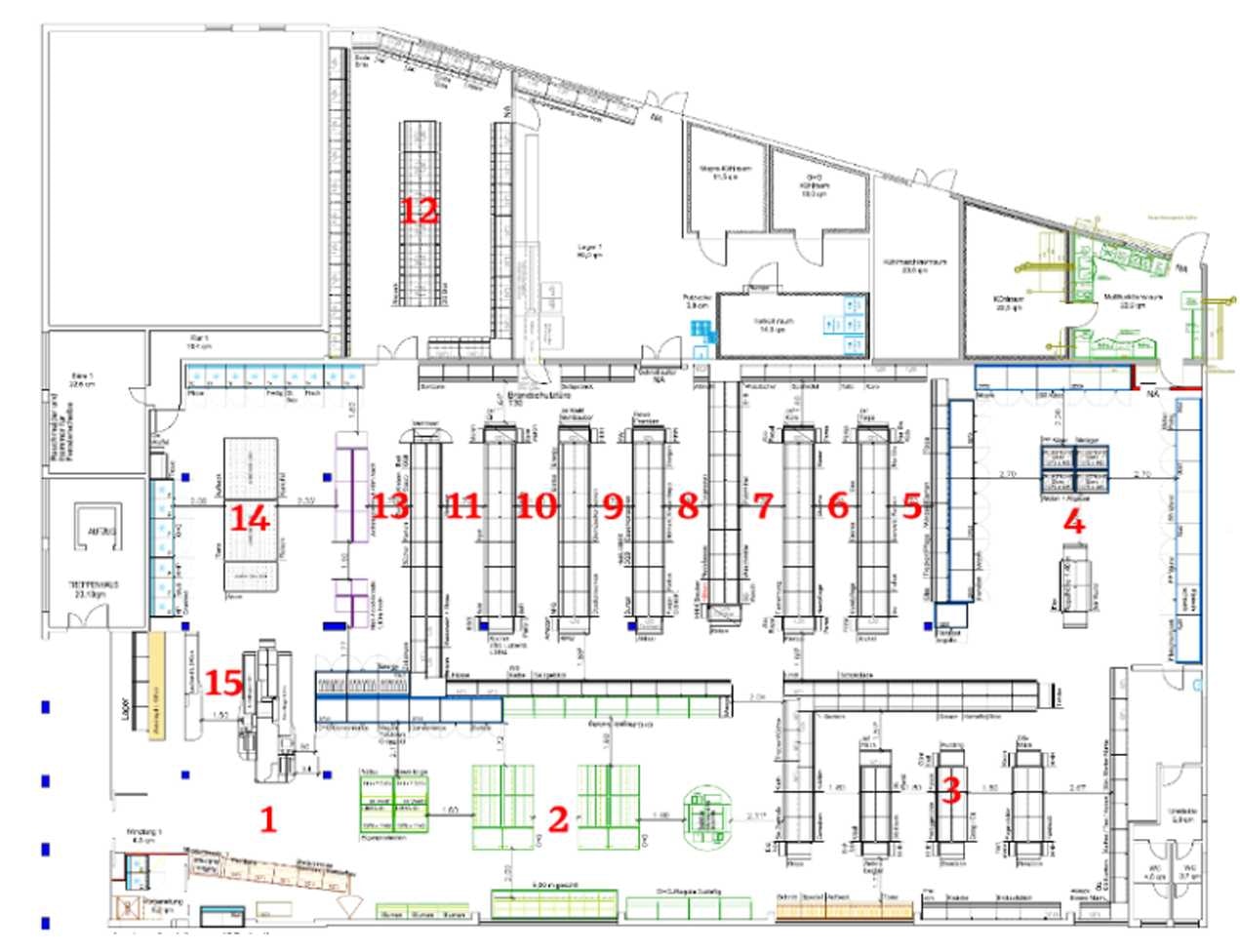
図1: 注文のピッキングを行う店舗のレイアウト、15のゾーンに分割されています。
注文履歴を用いて、合計移動時間を最小化する、商品のダメージを最小化すると言った様々な目標に基づき、著者は商品のピッキング順序を変化させました。そして、オンラインのカートに追加された順番に基づいて、作業員がピッキングを行うデフォルトの順序との比較を行いました。彼らの目的は、すべての小売シナリオにおいて最適なアプローチを特定することではなく、ピッキングの効率を改善する方法を探索するために、ほかの人が模倣できる様々なアプローチを評価するためのフレームワークを提供することでした。
論文の著者によって用いられた商品注文履歴データは利用できないので、我々はこの目標をを念頭に置き、指定された店舗レイアウトにマッピングされたInstacartデータセットの330万の注文データを用いて、彼らの取り組みの一部を再現しました。注文履歴データセットは異なりますが、ピッキング時間における様々な順番決定アプローチの相対的なインパクトは、著者による発見と類似していることがわかりました(図2)。

図2: 様々な最適化戦略を用いた際の平均ピッキング時間(秒)
Databricksを用いることで最適化がより効率的になります
最適化戦略の評価において、履歴データに様々なアルゴリズムを適用することは一般的なプラクティスです。事前の設定やシナリオを用いることで、現実世界に適用する前に最適化戦略の効果を評価することができます。このような評価を行うことで、企業は予期しない結果を回避し、アプローチをマイナーチェンジすることによるインパクトを評価することができますが、実施には非常に膨大な時間を要することもあり得ます。
しかし、処理を並列化することで、数日、場合によっては数週間かかるアプローチの評価が数時間、場合によっては数分に短縮することができます。鍵となるのは、大規模な評価ユニットから別々の独立した作業ユニットを特定し、これらを大規模な計算インフラストラクチャに分散するテクノロジーを活用することです。
上で探索したピッキング最適化においては、それぞれの注文はほかの注文の順序に影響を与えない商品の順序としての作業ユニットとして表現されます。極端な話ですが、我々の取り組みを信じられないほど迅速に行うために、330万のすべての注文の最適化を同時に実行することができます。多くの場合、少数のリソースを配備し、大規模データセットのサブセットをそれぞれの計算リソースに分配することで、我々の分析を実行するのに要する時間とインフラストラクチャ配備のコストのバランスを取ります。
このシナリオにおけるDatabricksのパワーは、クラウドでのリソース配備を非常にシンプルにするというものです。Sparkデータフレームに注文履歴をロードすると、配備されたリソースに対し即座にデータは分散されます。リソースを増減させると、我々が何をしなくてもデータフレームは自分で再度バランスを取ります。
このトリックは、それぞれの注文への最適化ロジックにも適用されます。pandasユーザー定義関数(UDF)を用いることで、効率的な方法でオープンソースライブラリとカスタムロジックを適用することができます。データフレームに結果が戻されるので、今後の分析のために永続化することもできます。上で説明した分析でこれがどのように実装され、行われているのかを確認するには、注文ピッキング最適化のソリューションアクセラレーターをチェックしてみてください。