これも一年以上の記事なので、再度ウォークスルーします。
Databricksのジョブはマルチタスクジョブなので、個々の処理をタスクとして定義し、処理フローを組み立ててジョブとして構成することができます。タスクには以下のようなものを定義できます。
- ノートブック
- Delta Live Tablesパイプライン
- SQLクエリー
- ダッシュボード
- 別のジョブ
- if/else(日本リージョンでも利用できるようになりました!)
ここではシンプルな例として、2つのノートブックタスクから構成されるジョブを構築して実行します。
ノートブックの作成
データ取得ノートブック
まず、COVID-19感染者データを取得してテーブルに保存するノートブックを作成します。
import re
# Username を取得
user_id = spark.sql('select current_user() as user').collect()[0]['user']
# Username の英数字以外を除去し、全て小文字化。Username をファイルパスやデータベース名の一部で使用可能にするため。
username = re.sub('[^A-Za-z0-9]+', '', user_id).lower()
print(username)
import pandas as pd
# pandasを使ってURLから直接データを取得します
pdf = pd.read_csv("https://covid19.mhlw.go.jp/public/opendata/newly_confirmed_cases_daily.csv")
# データを表示します
display(pdf)
# 縦長に変換
# id_vars: Dateをidとして、変換後のデータフレームにそのまま残します
# var_name: variable変数の列名をPrefectureにします
# value_name: value_name変数はCaseとします
long_pdf = pdf.melt(id_vars=["Date"], var_name="Prefecture", value_name="Cases")
display(long_pdf)
ジョブで使用するテーブル名をジョブで使う他のタスクから参照できるように、タスクバリューを活用します。dbutils.jobs.taskValues.setでテーブル名をタスクバリューとして設定します。
# pandasデータフレームをSparkデータフレームに変換します
sdf = spark.createDataFrame(long_pdf)
# 他のユーザーと重複しないようにテーブル名にユーザー名を埋め込みます
table_name = f"takaakiyayoi_catalog.quickstart_schema.{username}_covid_table"
# タスクバリューとしてジョブに含める他のノートブックから参照できるようにします
dbutils.jobs.taskValues.set(key="table_name", value=table_name)
# テーブルとして保存します
sdf.write.format("delta").mode("overwrite").saveAsTable(table_name)
可視化ノートブック
テーブルのデータからグラフを作成するノートブックを作成します。dbutils.jobs.taskValues.getでタスクバリューとして設定されているテーブル名を取得します。
import pyspark.pandas as ps
# タスクバリューからテーブル名を取得します
table_name = dbutils.jobs.taskValues.get("get_data", "table_name")
print(table_name)
sdf = spark.read.table(table_name)
psdf = ps.DataFrame(sdf)
#display(psdf)
%matplotlib inline
# 東京のデータを可視化
tokyo_psdf = psdf[psdf["Prefecture"]=="Tokyo"][["Date", "Cases"]].set_index("Date")
tokyo_psdf.plot.line()
このように、2つのノートブックを作成します。

ジョブの作成
サイドメニューからワークフローを選択します。ワークフローとジョブの関係についてはこちらをご覧ください。
ジョブを作成をクリックします。

ジョブに名前をつけます。
タスクを組み合わせてジョブを構成していきます。1つ目のタスクを作ります。名前はget_dataにします。なお、タスク名にスペースを含めることはできません。
種類はノートブックで、パスをクリックして上で作成したノートブックを選択します。


これで、一つ目のタスクができたので作成をクリックします。

タスクを追加するので、タスクを追加をクリックします。
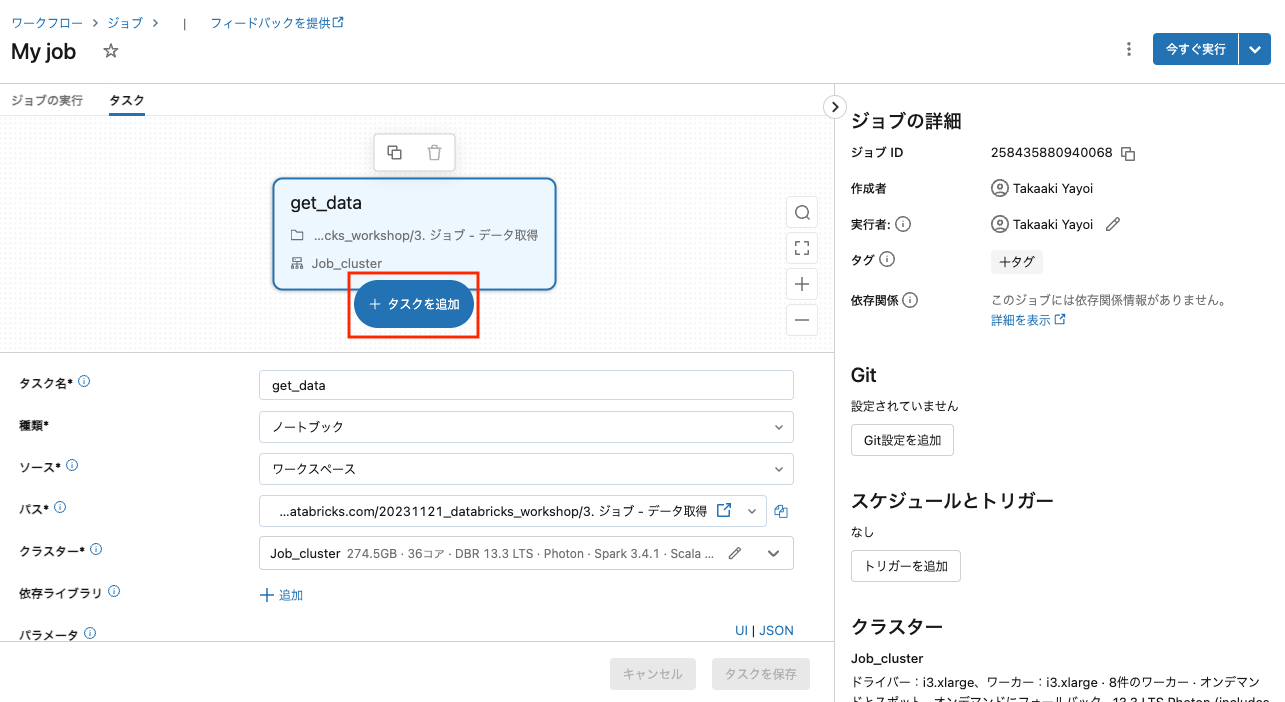
ノートブックを選択して、後続のタスクを追加します。
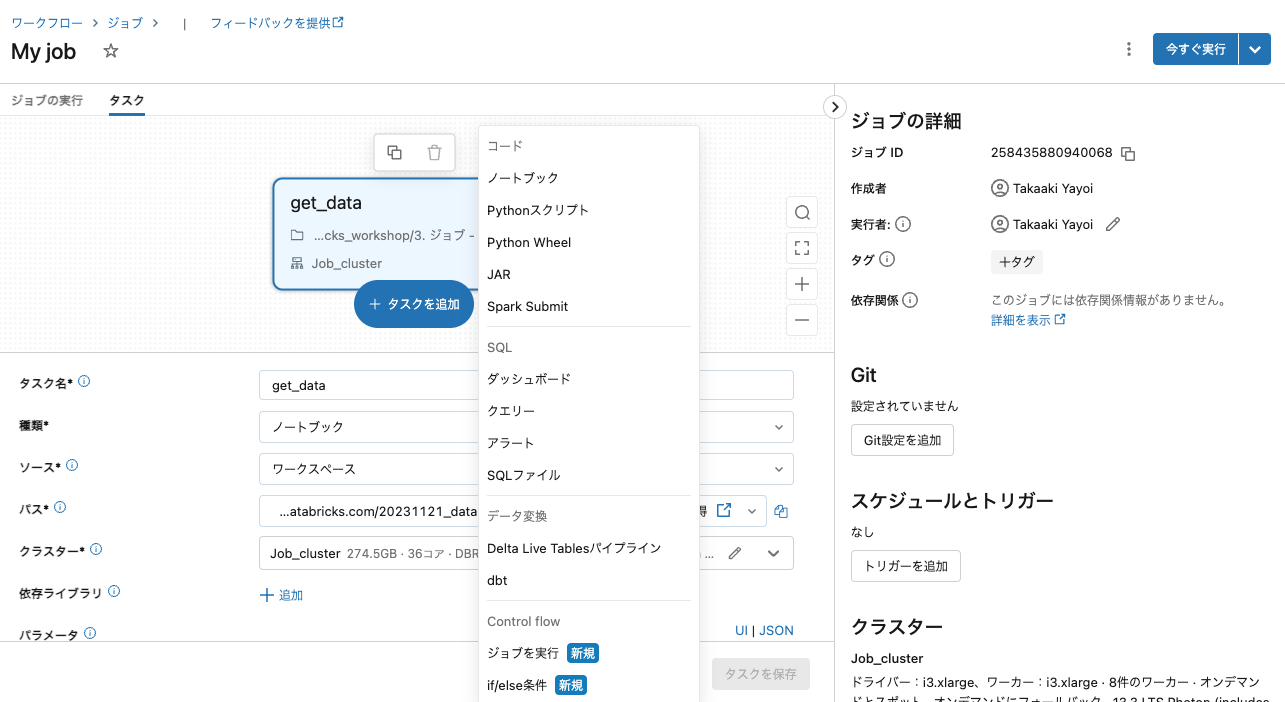

2つ目のタスク名はvisualizeにします。先ほどと同様に可視化のノートブックを選択します。
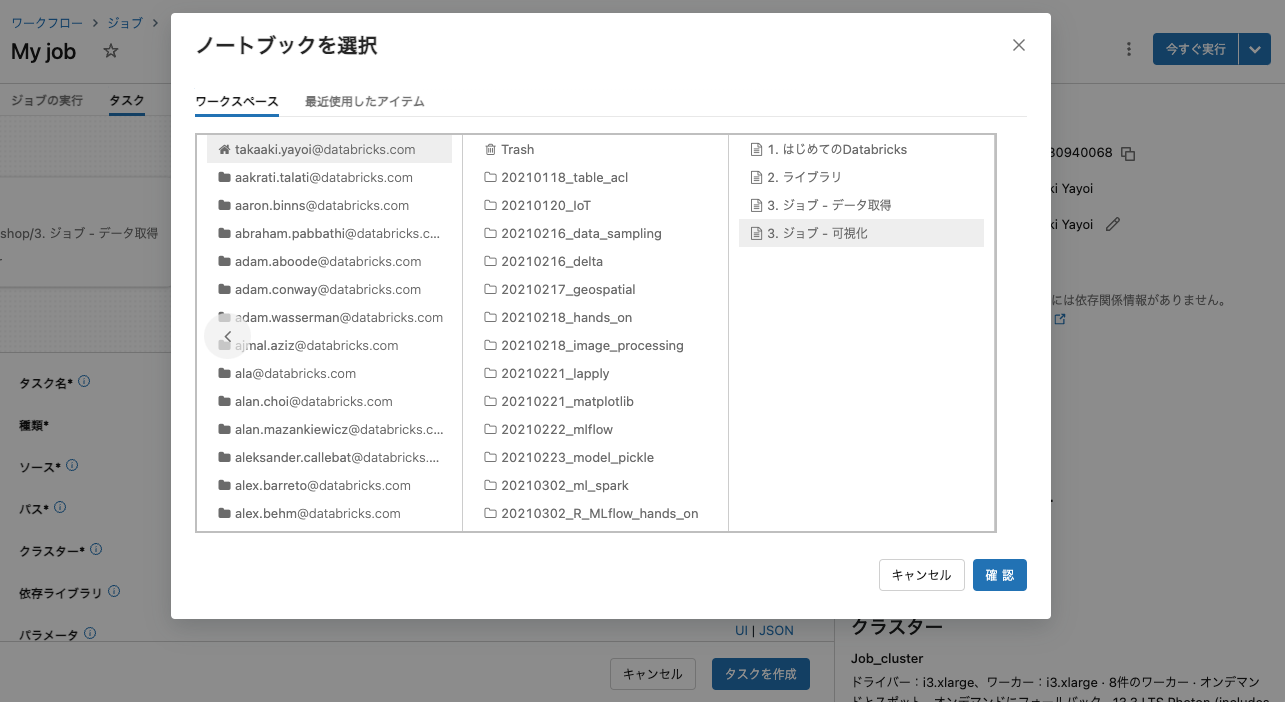
タスクを作成をクリックします。

これで、2つのタスクから構成されるジョブが完成しました!
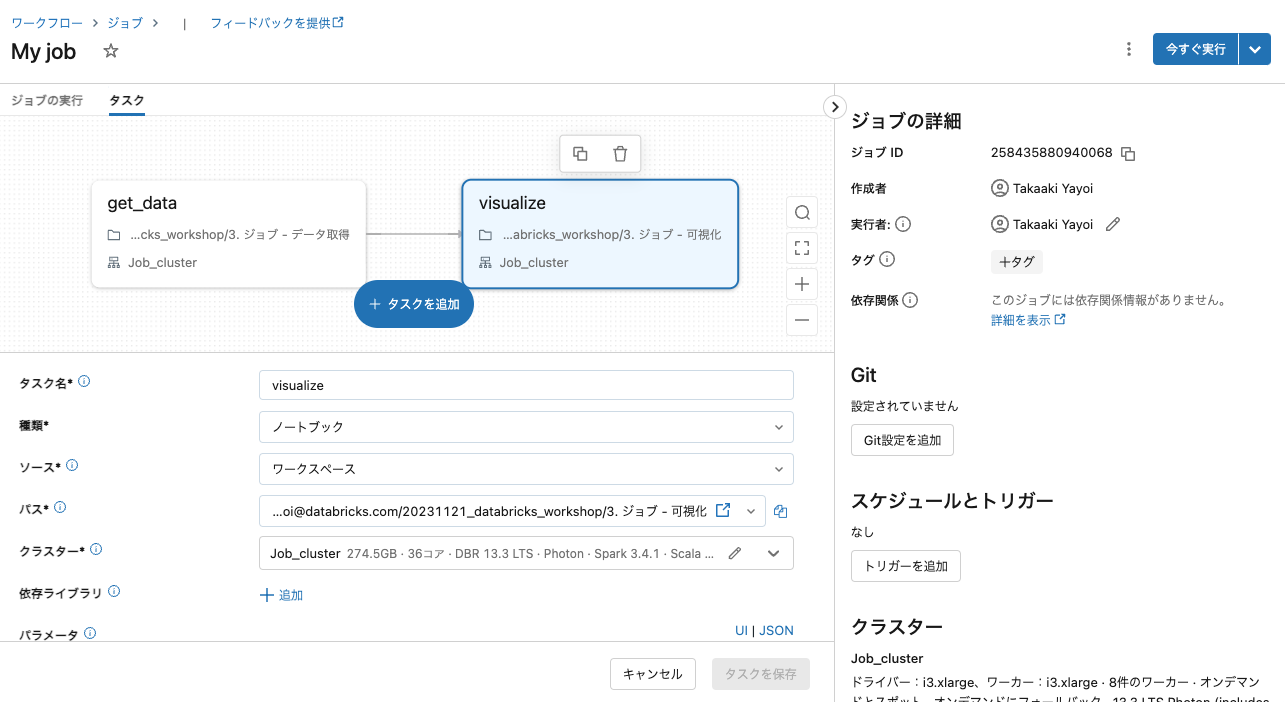
ジョブにおけるクラスター
Databricksでプログラムの処理を実行する際には、クラスターが必要となります。ジョブにおいても同様です。ただ、ジョブの場合にはジョブクラスターを活用することができます。従来のall purposeクラスターは明示的に停止するか自動停止を活用しない限り稼働し続けますが、ジョブクラスターはジョブの完了後に自動で停止します。本格運用する際にはジョブクラスターの利用をお勧めします。単価もお安くなっています。
ただ、ジョブのデバッグを行う際にジョブクラスターを使うと、実行の都度クラスターが停止するので生産性が上がりません。この場合には、ジョブでもall purposeクラスターを使う方が合理的といえます。
ジョブの画面でクラスターセクションにある切り替えボタンを押して、all purposeクラスターを使用することができます。繰り返しになりますが、本格稼働させる際にはジョブクラスターを選択することを忘れないようにしてください。




ジョブの実行
右上の今すぐ実行をクリックしてジョブを実行します。

なお、スケジュール実行したい場合にはスケジュールとトリガーのトリガーを追加をクリックして、スケジュールを指定します。
ジョブの実行タブに切り替えます。

リアルタイムで実行の進捗を確認できます。

少しするとジョブが完了します。開始時刻のリンクをクリックします。

タスクごとの実行結果を確認します。タスクvisualizeをクリックします。
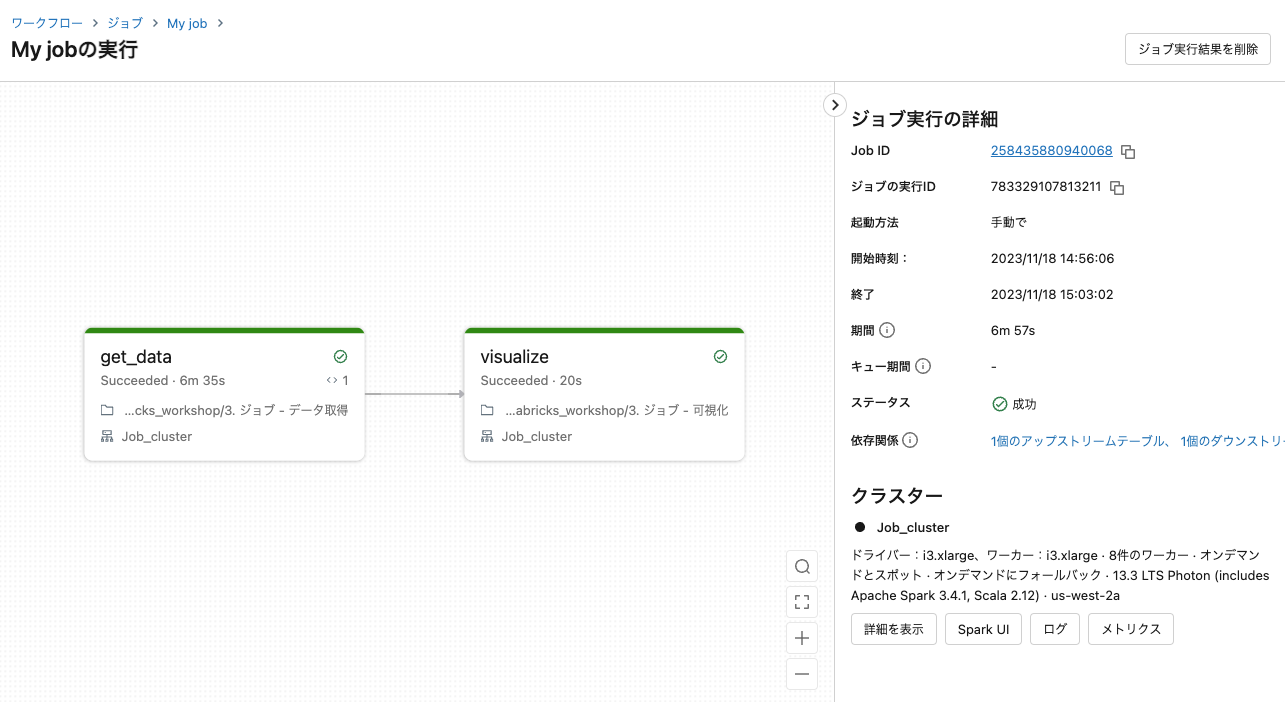
可視化の結果を確認できます。

今回は静的なデータから可視化を行っているだけですが、これが日次で更新される場合であっても、ジョブをスケジュール実行することで常に最新の可視化結果を自動で手に入れることができます。ジョブというと定期実行のためのものとのイメージがありますが、複雑な処理をオーケストレーションできることもジョブの大きなメリットです。是非ご活用ください!