Performance Tuning on Apache Spark for Data Engineersの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
本書はData Science Blogathonの一部として公開されました。
モチベーション
Sparkアプリケーションのチューニング問題に取り組む際、私はSpark Web UIのビジュアライゼーションを理解するために膨大な時間を費やしました。初心者にとっては、これらのビジュアライゼーションだけでは問題に対する直感を得るのが非常に難しいものとなっています。Sparkの性能に関して非常に優れたリソースは存在しますが、これらの情報が散在しています。このため、ドキュメントを作成し、自身の学びを共有すべきだと考えました。
ターゲットの読者および得られる知見
この記事では、読者がSparkのコンセプトに対する基本的な理解を有していることを前提としています。この記事は、初心者がSpark Web UIからアプリケーション実行時のパフォーマンス問題を特定する助けになるでしょう。ここでは、UIからでは明確にわからない情報と、不明瞭な情報から推論を導き出すことにのみフォーカスしています。本書では、Spark Web UIから解釈できる網羅的な情報の一覧を提供しておらず、私が自身のプロジェクトに関連しており、読者が知るのに十分一般化されるもののみとなっていることに注意してください。
Spark Web UI
Spark Web UIはアプリケーションの実行時にのみ利用できます。過去の実行結果を解析するには、Web UIにデータを表示できるようにイベントログを格納するヒストリーサーバーを有効化する必要があります。
Spark Web UIでは、以下のタブにお使いのアプリケーションに関する有用な情報を表示します。
- Executors
- Environment
- Jobs
- Stages
- Storage
本書の残りでは、それぞれのタブから得られる直感を順番に説明します。
Executorsタブ
全てのエグゼキューターで実行されるタスクの情報を提供します。
図1: Executorタブのサマリー
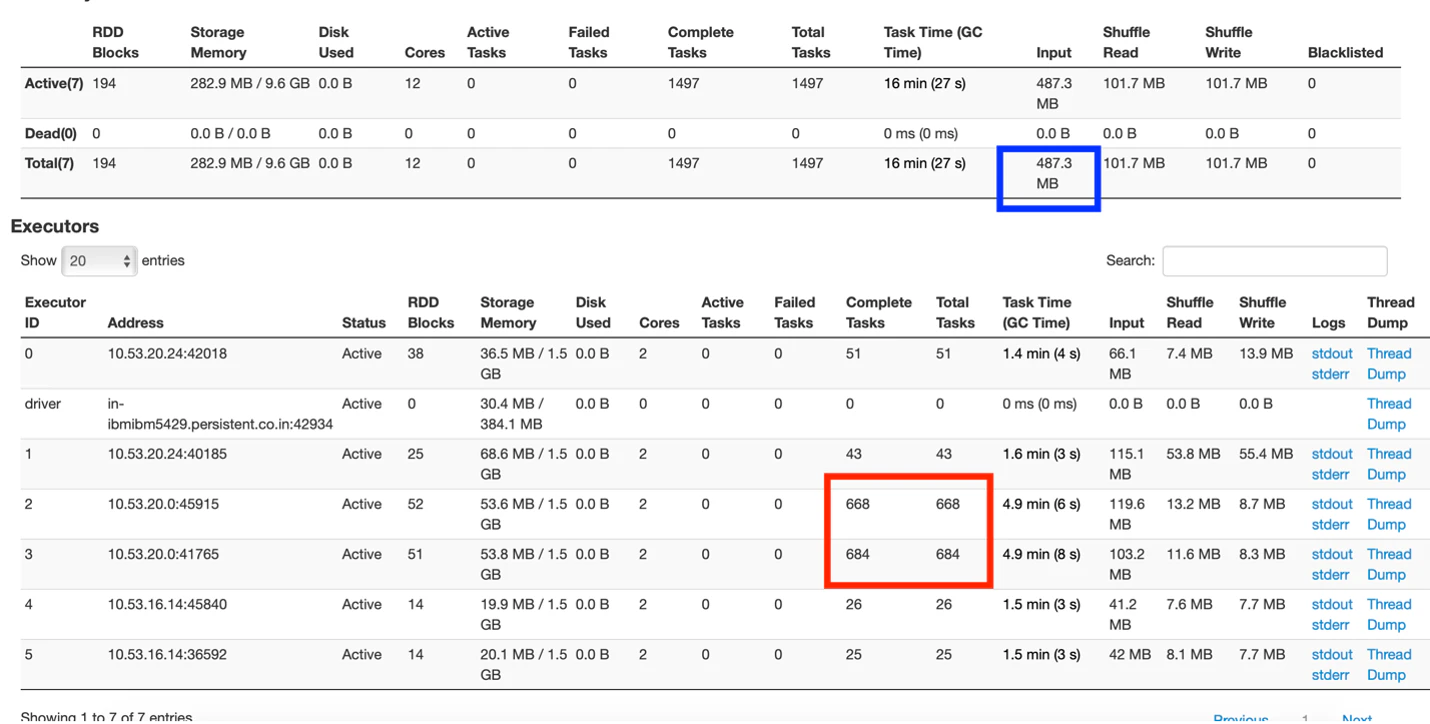
図1から、2コア、3GBメモリーを持つ1台のドライバーと5台のエグゼキューターが稼働していることがわかります。
赤い四角でマークされたボックスでは、1ノードのクラスターが過度にタスクを処理しており、他の比較的アイドル状態になっている不均衡な分布となっていることがわかります。
青い四角でマークされたボックスでは、入力サイズが487.3 MBであることが示されています。今は、このアプリケーションは83MBのサイズのデータセットに対して実行されました。入力データサイズには、読み込まれたオリジナルデータセットとノード間で転送されるシャッフルデータが含まれます。これは、多くのデータ(約400MB)がアプリケーション内でシャッフルされたことを示しています。
Environmentタブ
アプリケーションをコントロールし、ファインチューニングするための数多くのsparkプロパティが存在します。これらのプロパティは、ジョブのサブミットやコンテキストオブジェクトを作成する際に設定することができます。明示的にプロパティが追加されない限り、プロパティは適用されません。我々は、明示的に設定しない場合、これらのデフォルト値が適用されるものだと誤解していました。適用されている全てのプロパティはEnvironmentタブで確認することができます。プロパティがここで表示されていない場合は、そのプロパティは全く適用されていないことを意味します。
Jobsタブ
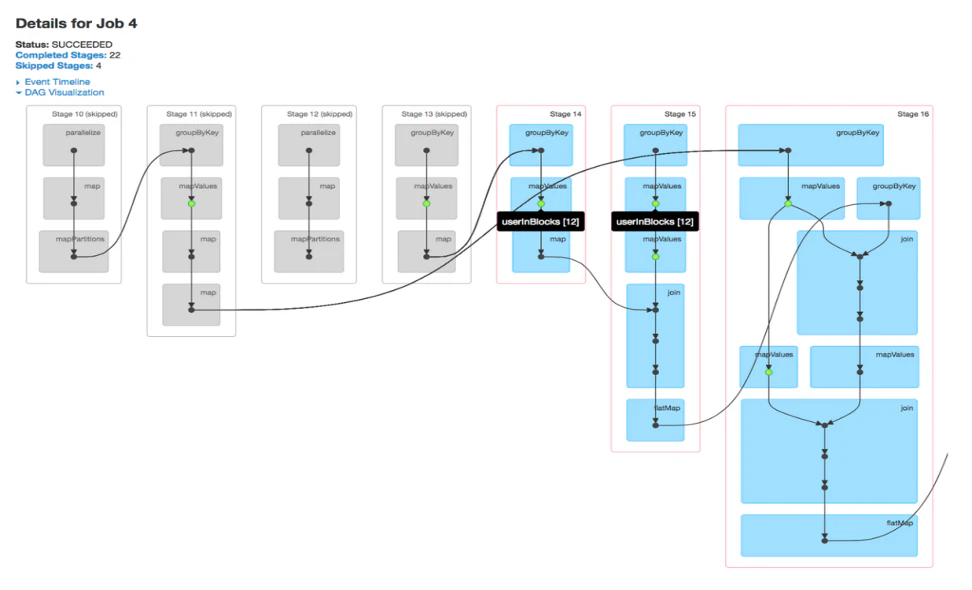
ジョブは、図2のように有効非巡回グラフ(DAG) で整理されるResilient Distributed Dataset(RDD)の依存関係のチェーンと関連づけられます。DAGのビジュアライゼーションからは、複数のステージが実行され、多くのステージがスキップされていることがわかります。デフォルトでは、明示的に永続化/キャッシュされない限り、Sparkはステージ上で計算されたステージを再利用しません。スキップされたステージは灰色でマークされたキャッシュ済みステージであり、計算された値はインメモリに格納されており、HDFSにアクセスした後では再計算されません。DAGのビジュアライゼーションをパッと見るだけで、RDDの計算が繰り返し行われており、キャッシュされたステージが使用されているかどうかを理解するには十分です。
図2: ジョブのDAGビジュアライゼーション
Stagesタブ
アプリケーション実行のタスクレベルの詳細なビューを提供します。ステージは個々のタスクによって並列で実行された処理のセグメントを表示します。タスクとデータパーティションの間には1対1のマッピングがあり、データパーティションあたり1タスクとなります。Spark Web UIからジョブ、特定のステージ、ステージの全てのタスクにドリルダウンすることができます。
ステージは、タスクのDAGのビジュアライゼーション、イベントタイムライン、サマリー/集計メトリクスなど処理実行に対する優れた概観を提供します。
私はタスクを分析するためにイベントタイムラインを見ることを好みます。これらは、ステージ実行に費やされた時間の詳細に対する図画による表現を提供します。パッと見るだけで、ステージがどれだけうまく実行されているのか、どのようにすれば実行時間をさらに改善できるのかに対するクイックな推論を導くことができます。
図3: イベントタイムラインのサンプル
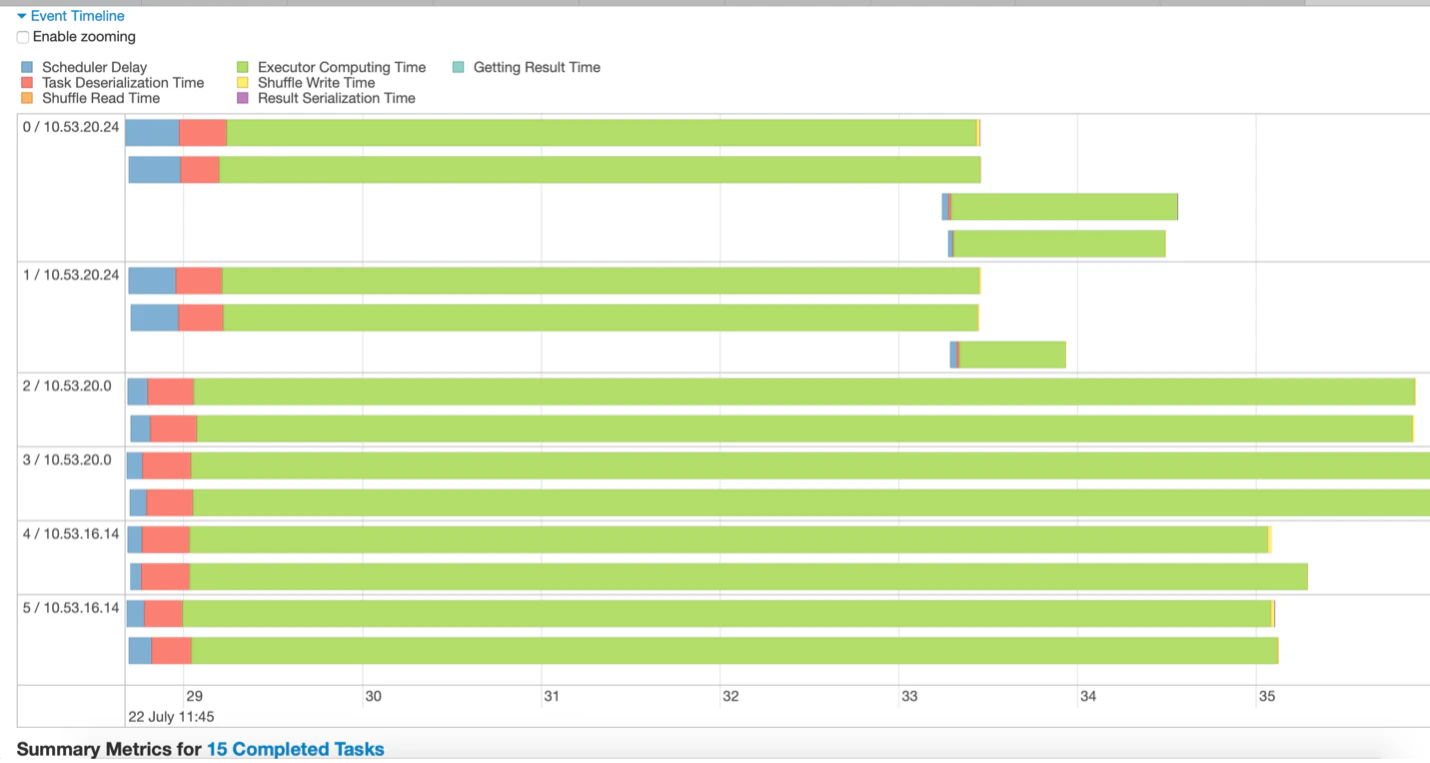
例えば、図3から以下のような推論を導くことができます。
- データは15のパーティションに分割されています。すなわち15のタスク(15のグリーンの線で表現されています)が実行されています。
- タスクは2つのエグゼキューターを持つ3つのノードで実行されています。
- 最長のタスクの終了したときにステージが完了します。最長のタスクが終了するまで他のエグゼキューターはアイドル状態であり続けます。
- いくつかのタスクは非常に短い時間で完了している一方で、一部のタスクは長い時間を要しており、データがよくパーティションされていないことを示しています。
- このステージでは、多くの時間がスケジューラーの遅延やシリアライゼーションに費やされている訳では無いので、良い傾向です。
図4: 多くのデータパーティションを持つステージのイベントタイムライン
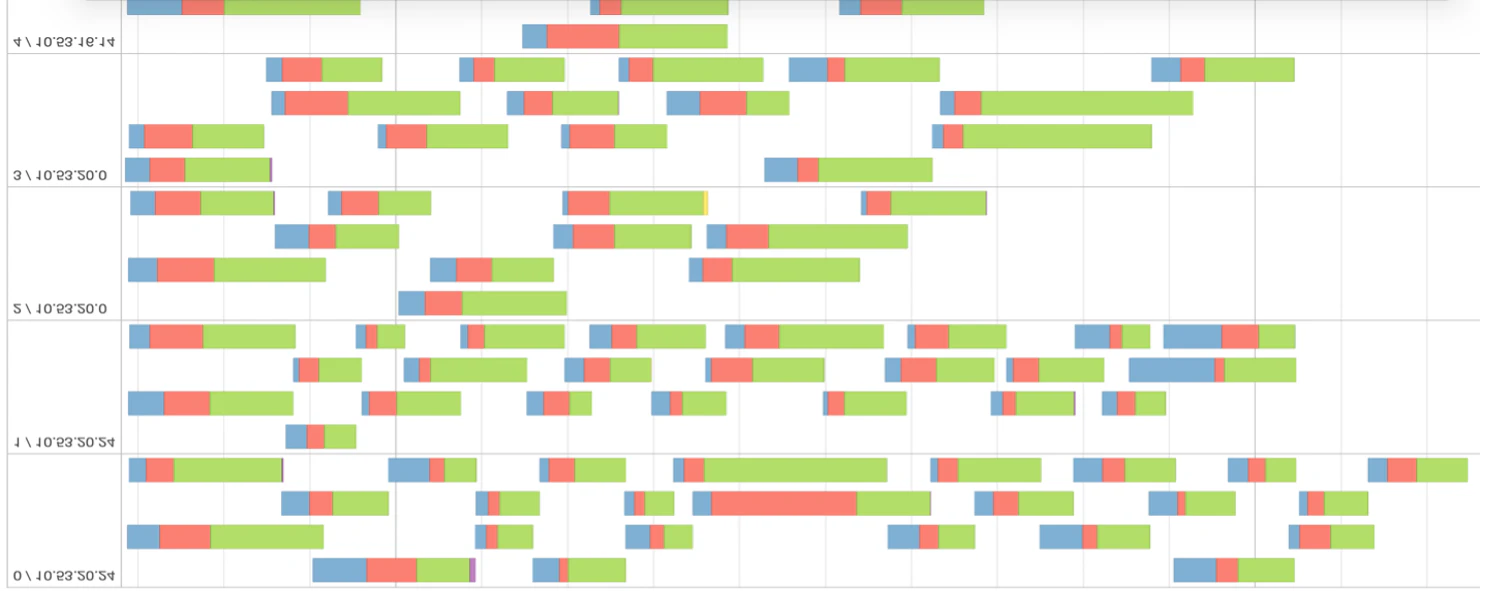
図4を見ることで、データはうまく分散されておらず、不必要にパーティションされていることを導き出すことができます。評価メトリクスからは、タスクのスケジューリングが実際の実行時間よりも多くの時間を要していることが確認できます。タイムラインのグリーンの割合が大きいほど、ステージの計算処理が効率的であることを意味します。
ジョブに含まれるステージの数は少ない方が望ましいです。データがシャッフルされると新たなステージが追加されます。シャッフルのコストは高いので、お使いのプログラムが必要とするステージの数を減らすようにすべきです。
入力データサイズ
他に見るべき重要な洞察はシャッフルされるデータの入力サイズです。ゴールの一つは、このシャッフルデータのサイズを減らすことになります。
図5: ステージタブのオーバービュー
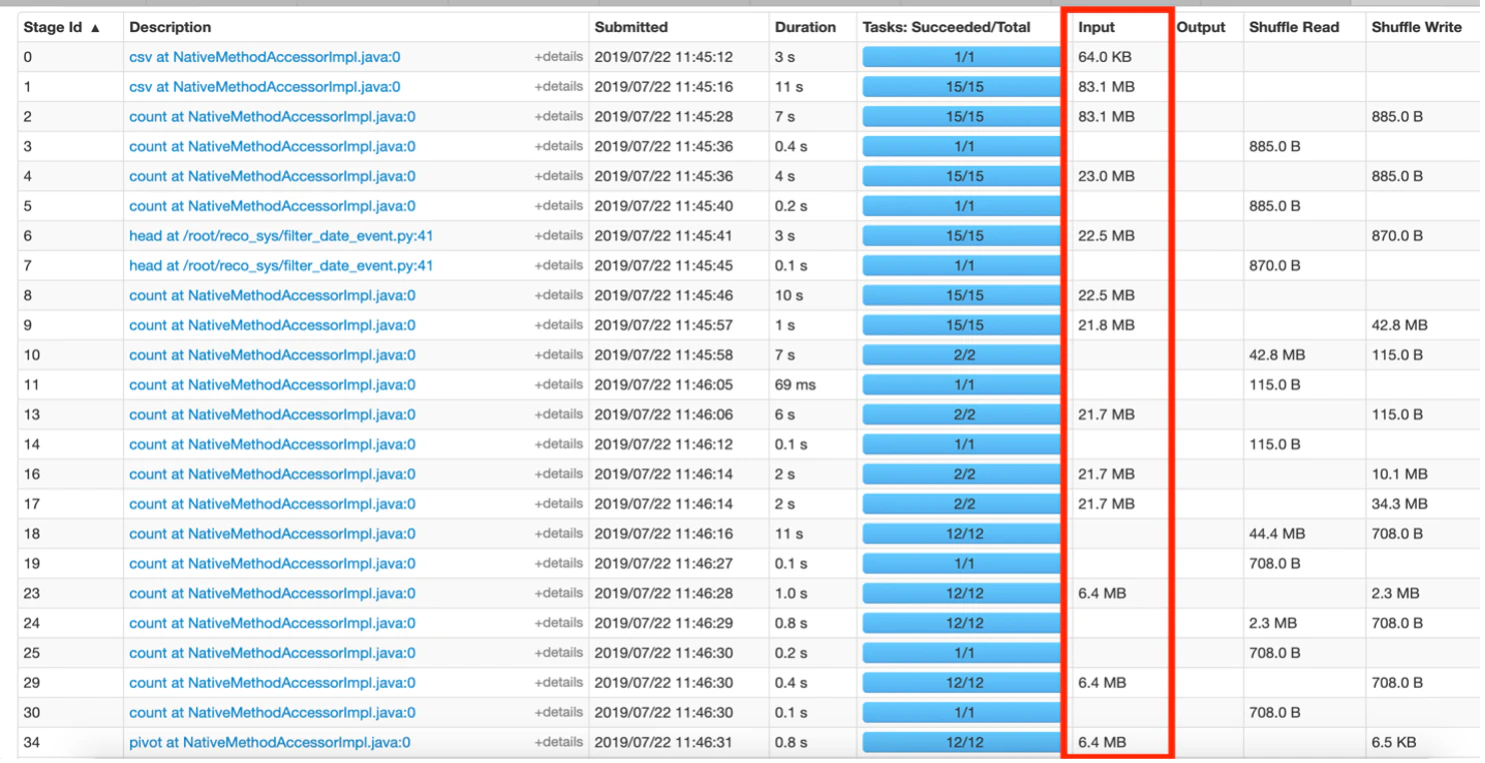
上の図5では、データが移動したステージをMBで表示しています。これは、ステージ間でデータがやり取りされるサイズを削減するためにコードを改善するヒントとなります。例えば、ある特定のイベントxのデータに対してフィルタリングを適用し、結果のRDDの全ての行のeventカラムがxになった結果、冗長となったとします。シャッフルのオペレーションの際に転送される追加情報を削減するために、このフィルタリングされたデータのRDDからこのカラムを削除すべきかもしれません。
Storageタブ
persist()やcache()を用いて永続化されたRDDのみが表示されます。よりわかりやすくするために、setName()を用いて格納時にRDDに名前を割り当てることができます。あなたが永続化したいRDDのみがStorageタブに表示され、カスタム名称を指定することでより判別しやすくなります。
サマリー
本書では、シャッフルされるデータのサイズ、ステージの実行時間、キャッシュの欠如によるRDDの再計算などSpark Web UIから問題を特定するための洞察を得るための助けとなる情報を示しました。ご自身のデータとアプリケーションを理解すれば、実行UIから推定することで、理想のデータの分布、望ましいパーティションの数を導き出すことができます。クラスターにおける1ノードへの過積載 vs 他ノードは、UIから観測できる別の改善領域です。これらのいくつかの問題に対する解決策がApache Spark Performance Tuning articleで議論されています。