こちらのサンプルノートブックをウォークスルーします。
翻訳版のノートブックはこちらです。
GraphFramesによるグラフ分析
このノートブックでは、spark-packages.orgで利用できるGraphFramesパッケージを用いた基本的なグラフ分析をウォークスルーします。このノートブックのゴールは、グラフ分析を行うためにどの様にGraphFramesを使うのかを説明することです。Kaggleのベイエリアのバイクシェアのデータを用いてこれを行います。
グラフ理論とグラフ処理
グラフ処理は多くのユースケースに適用される重要な分析の観点です。基本的に、グラフ理論とグラフ処理は、異なるノードとエッジ間の関係性の定義に関するものです。ノード(vertex)はユニットであり、エッジはそれらの間に定義される関係性です。これは、関係性を理解し、重みづけを行うソーシャルネットワーク分析や、PageRankのようなアルゴリズムの実行において非常に役立ちます。
いくつかのビジネスユースケースにおいては、ソーシャルネットワークの中心人物[友達グループで誰が一番人気なのか]、文献ネットワークにおける論文の重要性[どの論文が最も引用されているのか]、Webページのランキングの原因を探すと言ったことが考えられます!
グラフとバイク移動データ
上で述べた様に、このサンプルではベイエリアのバイクシェアデータを使います。皆様が分析に慣れる様に、すべてのノードをステーションにし、2つのステーションを結ぶエッジが個々の移動になります。これは、有向グラフを作成します。
その他のリファレンス:
データの準備
- KaggleからBay Area Bike Shareデータをダウンロードして解凍します。サードパーティの認証を用いてKaggleにサインインするか、Kaggleアカウントを作成してサインインする必要があります。
-
Explore and create tables in DBFSで説明されている方法で
station.csvとtrip.csvをアップロードします。テーブル名はstation_csvとtrip_csvになります。
データフレームの作成
上のデータの準備で作成したテーブルを指定してデータを読み込みます。
val bikeStations = spark.sql("SELECT * FROM takaakiyayoi_db.station_csv")
val tripData = spark.sql("SELECT * FROM takaakiyayoi_db.trip_csv")
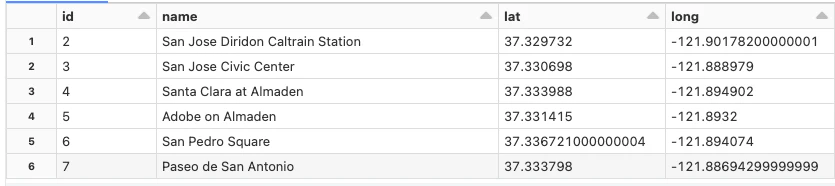
display(bikeStations)
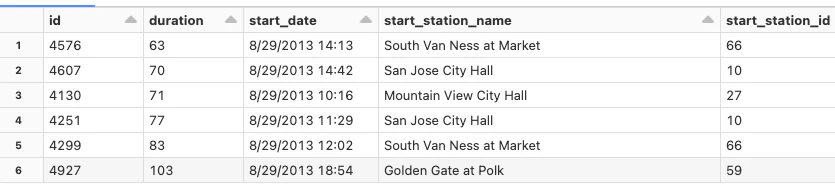
display(tripData)
適切な型が適切なカラムに割り当てられていることを確認するために、正確なスキーマを確認することは多くの場合有用です。
bikeStations.printSchema()
tripData.printSchema()

インポート
続ける前にいくつかのインポートが必要です。データフレームの操作を簡単にするさまざまなSQL関数ををインポートし、GraphFramesに必要な全てをインポートします。
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.graphframes._
グラフの構築
データをインポートした後に必要なのはグラフの構築です。これを行うために2つのことが必要です。ノード(vertex)の構造を構築し、エッジの構造を構築します。GraphFramesの素晴らしいところは、このプロセスが信じられないほどシンプルだということです。必要なのは、ノードのテーブルの別個のid値を取得し、エッジテーブルの起点と終点のステーションをそれぞれsrcとdstに変更するということです。これは、GraphFramesにおけるノードとエッジに必要な決まり事です。
val stationVertices = bikeStations
.distinct()
val tripEdges = tripData
.withColumnRenamed("start_station_name", "src")
.withColumnRenamed("end_station_name", "dst")
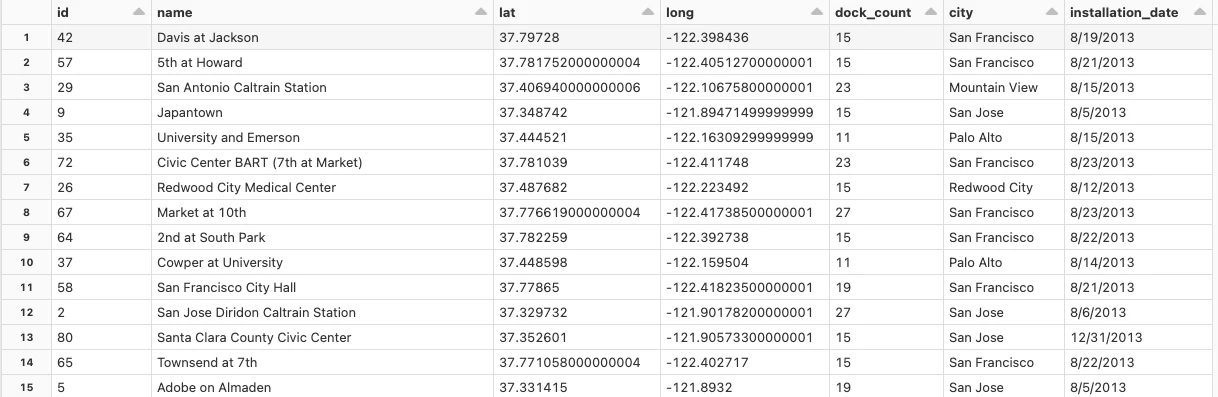
display(stationVertices)
display(tripEdges)

これでグラフを構築できます。
また、ここでグラフへの入力データフレームをキャッシュしておきます。
val stationGraph = GraphFrame(stationVertices, tripEdges)
tripEdges.cache()
stationVertices.cache()
println("Total Number of Stations: " + stationGraph.vertices.count)
println("Total Number of Trips in Graph: " + stationGraph.edges.count)
println("Total Number of Trips in Original Data: " + tripData.count)// sanity check

ステーション間の移動
よく尋ねられる質問は、データセットにおいて最も共通している目的地が何かということです。グルーピングオペレーターとエッジのカウントを組み合わせることで、これを行うことができます。これは、エッジを除外した新たなグラフを作り出し、意味的に同じエッジすべての合計値となります。この様に考えてみましょう: 全く同じステーションAからステーションBへの移動回数が存在し、単にこれらをカウントするだけです!
以下のクエリーでは、最も共通するステーション間移動を抽出し、トップ10を表示しています。
val topTrips = stationGraph
.edges
.groupBy("src", "dst")
.count()
.orderBy(desc("count"))
.limit(10)
display(topTrips)
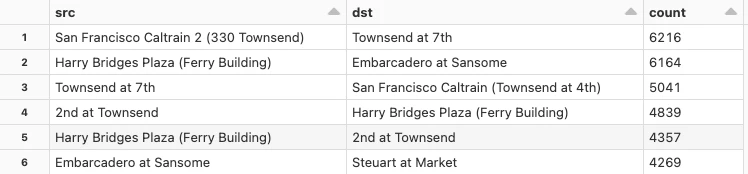
上の結果から、特定のノードがカルトレインのステーションであることが重要であることがわかります!これらは自然な接続点であり、車を使わない方法で、これらのバイクシェアプログラムを用いてAからBに移動するには最も人気のある利用法なのでしょう!
入次数(in degree)と出次数(out degree)
この例では有向グラフを使っていることを思い出してください。これは、移動には方向があること - ある地点からある地点へ - を意味します。これによって、あなたが活用できる分析はさらにリッチなものになります。特定のステーションに移動する数や、特定のステーションから移動する数を見つけ出すことができます。
通常、この情報で並び替えを行い、インバウンドとアウトバウンドの移動が多いステーションを見つけ出すことができます!詳細に関しては、Vertex Degreesの定義をチェックしてみてください。
このプロセスを定義したので、次に進んでインバウンドとアウトバウンドの移動が多いステーションを見つけましょう。
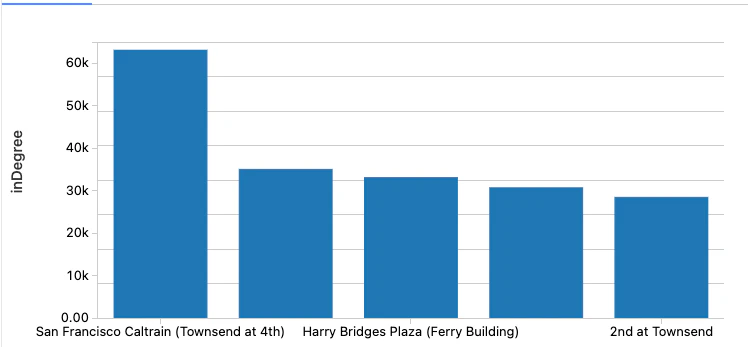
val inDeg = stationGraph.inDegrees
display(inDeg.orderBy(desc("inDegree")).limit(5))
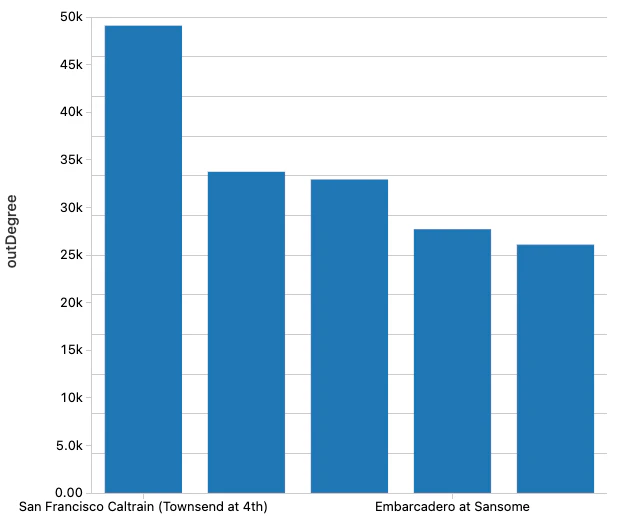
val outDeg = stationGraph.outDegrees
display(outDeg.orderBy(desc("outDegree")).limit(5))
もう一つの興味深い質問は、入次数が最も高いが、出次数が少ないステーションがどれかということです。すなわち、どのステーションが純粋な移動のシンクになっているかということです。移動がそこで終了しますが、ほとんどそこから移動を開始しない場所です。
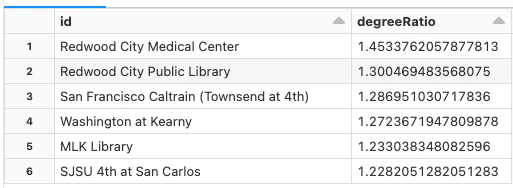
val degreeRatio = inDeg.join(outDeg, inDeg.col("id") === outDeg.col("id"))
.drop(outDeg.col("id"))
.selectExpr("id", "double(inDegree)/double(outDegree) as degreeRatio")
degreeRatio.cache()
display(degreeRatio.orderBy(desc("degreeRatio")).limit(10))
出次数に対する入次数の比率が最も低いステーションを得ることで、同様のことを行うことができます。これは、そのステーションからの移動開始が多いが、移動がそこで終わることがあまりないことを意味します。これは、基本的に上で見たのと逆の内容になります。
display(degreeRatio.orderBy(asc("degreeRatio")).limit(10))
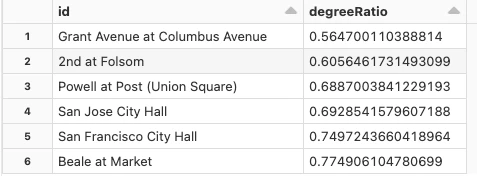
上の分析から得られる結論は比較的わかりやすいものです。高い値は出てくるよりも入る移動が多いことを意味し、低い値はそのステーションからの移動開始が多いが、移動終了は少ないということです!
このノートブックから何かしらの価値を得ていただけたら幸いです!グラフ構造は探し始めるとどこにでもあり、GraphFramesが分析を容易にしてくれることを願っています!