Databricks Reposを使うことで、GitHub、Azure DevOps、AWS CodeCommitなどとDatabricksワークスペースを同期できるようになります。それ以外の機能として、ノートブック以外の任意のファイルをDatabricks上で利用できるようになる機能があります。これをFiles in Repos機能と呼びます。
Files in Repos機能の一般的なユースケースは:
- カスタムのPython、Rのモジュール。これらのモジュールをRepoに取り込むことで、Repoのノートブックは
import文を用いてこれらの関数にアクセスすることができます。 - Repoの
requirements.txtファイルで環境を定義。ノートブックの環境を作成し、パッケージをインストールするには、ノートブックからpip install -r requirements.txtを実行するだけです。 - Repoに小規模データファイルを格納。これは開発やユニットテストで有用です。Repoのデータファイルの最大サイズは100MBです。Databricks Reposでは小さいファイル(< 10 MB)のエディタを提供します。
本記事では、この機能をウォークスルーします。
Databricks Reposに関してはこちらをご覧ください。
GithubなどのリポジトリとDatabricksワークスペースを同期する機能Repositoriesを略してReposと呼んでいます。このため、ここでは、個々のリポジトリをRepoと呼称します。
今回使うサンプルノートブックはこちらです。上のマニュアルで紹介されているサンプルノートブックです。
環境の準備
まず、上記サンプルノートブックで使用するファイルを利用できるようにするために、リポジトリをクローンします。
- Databricksにログインします。
- サイドバーからリポジトリを選択し、右上のリポジトリを追加ボタンをクリックします。

-
GitレポジトリのURLに
https://github.com/databricks/files_in_reposを入力し、作成をクリックします。

- これでリポジトリがクローンされました。

- すでに
files-in-reposというノートブックがクローンされているので、こちらを使ってもいいですが、日本語訳したものが良い場合には、元のファイルの名前を変更の上、こちらからpyファイルをダウンロードし、同じ場所にインポートしてください。 - 画面左上から稼働中のクラスターを選択し、ノートブック
files-in-reposをクラスターにアタッチして準備は完了です。Reposのノートブックを開いた際には、画面左上ノートブック名の左にmainという形で同期しているブランチが表示されます。

Pythonモジュールの取り扱い
現在の作業ディレクトリ(/Workspace/Repos/<username>/<repo_name>)は自動的にPythonパスに追加されます。現在のディレクトリ、サブディレクトリにある任意のモジュールをインポートすることができます。
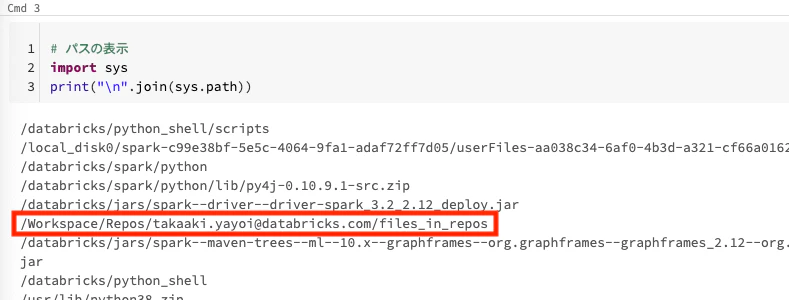
# パスの表示
import sys
print("\n".join(sys.path))
from sample import n_to_mth
n_to_mth(3, 4)

他のリポジトリからモジュールをインポートするには、Pythonパスにそれらを追加します。例えば、Pythonモジュールlib.pyを持つsupplemental_filesというRepoがある場合には、次のセルのようにすることでインポートすることができます。
import sys
import os
# 以下のコマンドでは <username> をご自身のDatabricksユーザー名で置き換えてください
sys.path.append(os.path.abspath('/Workspace/Repos/takaaki.yayoi@databricks.com/supplemental_files'))
# これで、supplemental_files RepoからPythonモジュールをインポートすることができます
import lib
自動リロード
長方形の面積を計算する関数rectangleを追加するためにsample.pyを編集したとします。以下のコマンドを実行することでモジュールは自動でリロードされます。
%load_ext autoreload
%autoreload 2
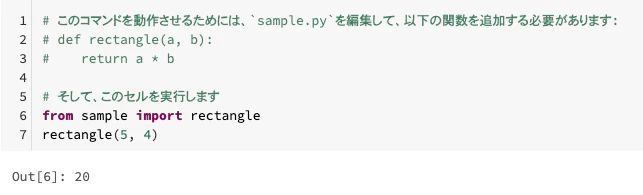
# このコマンドを動作させるためには、`sample.py`を編集して、以下の関数を追加する必要があります:
# def rectangle(a, b):
# return a * b
# そして、このセルを実行します
from sample import rectangle
rectangle(5, 4)
上の指示に従って、Repoにあるsample.pyを開きます。
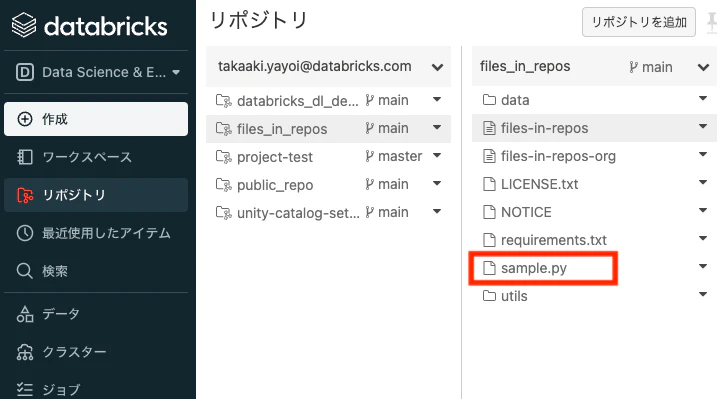
エディタが表示されます。

ここに関数を追加します。ファイルは自動で保存されます。

# そして、このセルを実行します
from sample import rectangle
rectangle(5, 4)
追加された関数が実行できていることがわかります。
requirements.txtファイルからのパッケージのインストール
pip install -r requirements.txt

小さいデータファイルの取り扱い
Repoに小さいデータファイルを格納することができ、開発やユニットテストが便利になります。Repoにおけるデータファイルの最大サイズは100MBです。Databricks Reposは小さいファイル(< 10 MB)のエディタを提供します。Python、シェルコマンド、pandas、Koalas、PySparkでデータファイルを読み込むことができます。
Pythonによるファイルの参照
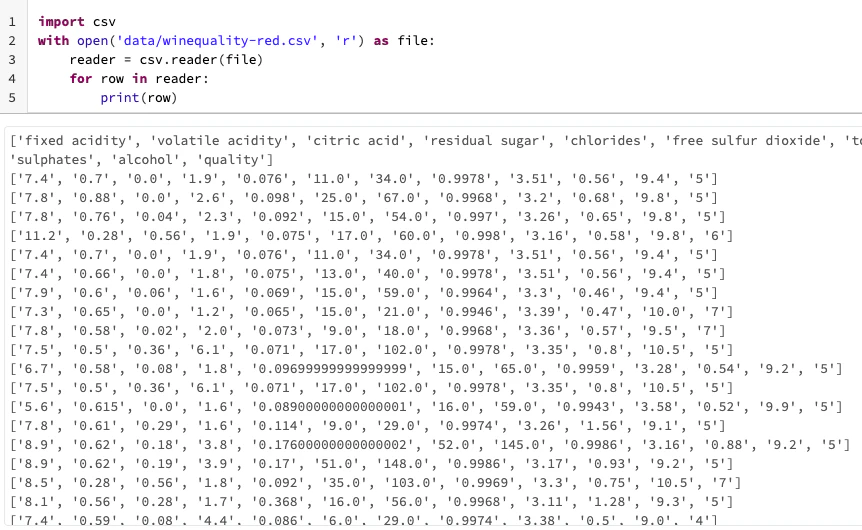
import csv
with open('data/winequality-red.csv', 'r') as file:
reader = csv.reader(file)
for row in reader:
print(row)
シェルコマンドによるファイルの参照
%sh head -10 data/winequality-red.csv

pandasによるファイルのロード
import pandas as pd
df= pd.read_csv("data/winequality-red.csv")
display(df)
Koalasによるファイルのロード
Koalasでは絶対ファイルパスが必要です。
import os
import databricks.koalas as ks
df= ks.read_csv(f"file:{os.getcwd()}/data/winequality-red.csv") # Koalasでは "file:" プレフィクスと絶対ファイルパスが必要です
display(df)
KoalasプロジェクトはSparkプロジェクトとマージされました。ビルトインのpandas API on Sparkのご利用を検討ください。
PySparkによるファイルのロード
PySparkでは絶対ファイルパスが必要です。
import os
df=spark.read.csv(f"file:{os.getcwd()}/data/winequality-red.csv", header=True) # PySparkでは "file:" プレフィクスと絶対ファイルパスが必要です
display(df)
制限
プログラムからファイルに書き込みを行うことはできません。