Demo notebooks | Databricks on AWS [2021/9/24時点]のStructured Streaming demo Python notebookを翻訳・説明する記事です。
Apache Sparkには、高レベルのストリーミング処理APIである構造化ストリーミングが含まれています。ここで説明するノートブックでは、Databricksで構造化ストリーミングアプリケーションを構築するためにどのようにデータフレームAPIを活用するのかをクイックに見てみます。ここでは、ストリームにおけるタイムスタンプを伴うアクション(Open、Closeなど)に対するウィンドウ内のカウントや連続的に更新されるカウントのようなリアルタイムのメトリクスを計算します。
サンプルノートブックの説明
サンプルデータ
ここでアプリケーションを構築するために用いるサンプルのアクションデータは、/databricks-datasets/structured-streaming/events/にファイルとして格納されています。ディレクトリの中身を見てみましょう。
%fs ls /databricks-datasets/structured-streaming/events/
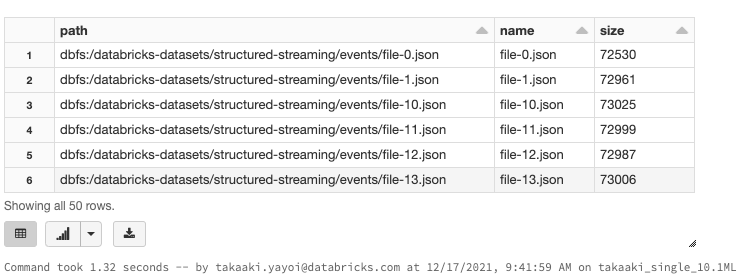
ディレクトリには約50個のJSONファイルが格納されています。個々のJSONファイルの中身を見てみましょう。
%fs head /databricks-datasets/structured-streaming/events/file-0.json
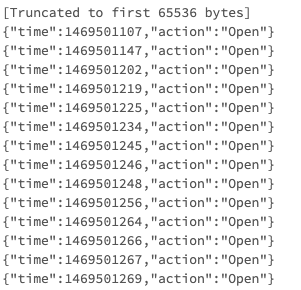
ファイル内のそれぞれの行には、2つのフィールドtimeとactionが含まれています。インタラクティブにこれらのファイルを解析してみましょう。
バッチ/インタラクティブ処理
データを処理する最初のステップは、通常はデータに対するインタラクティブなクエリーの実行です。ファイルに対する静的なデータフレームを定義し、テーブル名をつけましょう。
from pyspark.sql.types import *
inputPath = "/databricks-datasets/structured-streaming/events/"
# すでにデータのフォーマットを知っているので、処理を高速化するためにスキーマを定義しましょう(Sparkがスキーマを推定する必要がなくなります)
jsonSchema = StructType([ StructField("time", TimestampType(), True), StructField("action", StringType(), True) ])
# JSONファイルのデータを表現する静的なデータフレーム
staticInputDF = (
spark
.read
.schema(jsonSchema)
.json(inputPath)
)
display(staticInputDF)
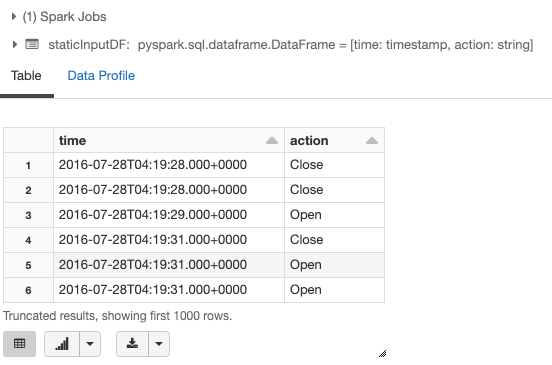
これで、1時間のタイムウィンドウにおけるopenとcloseアクションの数を計算することができます。このためには、actionカラムとtimeカラムに対する1時間のウィンドウでグルーピングを行います。
from pyspark.sql.functions import * # window()関数を使用するために必要
staticCountsDF = (
staticInputDF
.groupBy(
staticInputDF.action,
window(staticInputDF.time, "1 hour"))
.count()
)
staticCountsDF.cache()
# データフレームをテーブル'static_counts'として登録します
staticCountsDF.createOrReplaceTempView("static_counts")
これで、テーブルに対してSQLを用いて直接クエリーを実行できます。例えば、以下のように全ての時間におけるアクションの総数を計算します。
%sql select action, sum(count) as total_count from static_counts group by action
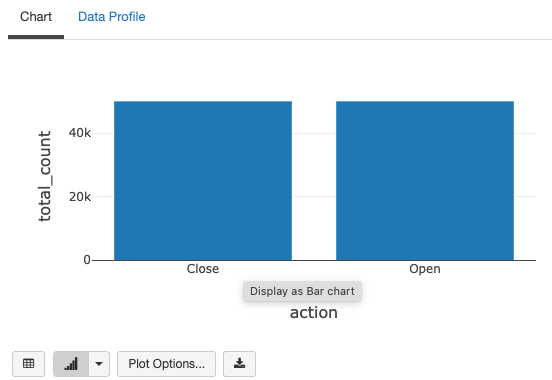
ウィンドウ内のカウントはどうでしょうか?
%sql select action, date_format(window.end, "MMM-dd HH:mm") as time, count from static_counts order by time, action
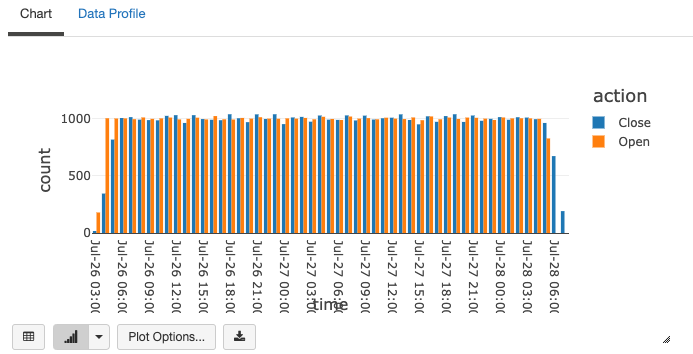
グラフの最後の2つに注意してください。対応するOpenアクションの後にCloseアクションが生じるように生成されており、最初に多くの"Open"が存在し、最後に多くの"Close"が存在しています。
ストリーム処理
ここまではデータをインタラクティブに分析しましたが、データの到着に伴って連続的に更新するストリーミングクエリーに切り替えましょう。今回は一連の静的なファイルがあるのみなので、一度に一つのファイルを時系列に読み込むことでストリームをシミュレートします。ここで記述すべきクエリーは、上述のインタラクティブなクエリーと非常に似たものとなります。
from pyspark.sql.functions import *
# 上で定義したstaticInputDFの定義と似ていますが、`read`ではなく`readStream`を使用します
streamingInputDF = (
spark
.readStream
.schema(jsonSchema) # JSONデータのスキーマを設定
.option("maxFilesPerTrigger", 1) # 一度に一つのファイルを取り込むことで一連のファイルをストリームとして取り扱います
.json(inputPath)
)
# staticInputDFと同じクエリー
streamingCountsDF = (
streamingInputDF
.groupBy(
streamingInputDF.action,
window(streamingInputDF.time, "1 hour"))
.count()
)
# このデータフレームはストリーミングデータフレームでしょうか?
streamingCountsDF.isStreaming

上でわかるように、streamingCountsDFはストリーミングデータフレームです(streamingCountsDF.isStreamingがtrueでした)。sinkを定義し、起動することで、ストリーミング処理をスタートすることができます。
今回のケースでは、カウントをインタラクティブに取得(上と同じクエリー)したいので、インメモリのテーブルに1時間ごとのカウントをセットします。
spark.conf.set("spark.sql.shuffle.partitions", "2") # シャッフルのサイズを小さくします
query = (
streamingCountsDF
.writeStream
.format("memory") # memory = インメモリテーブルに格納
.queryName("counts") # counts = インメモリテーブルの名称
.outputMode("complete") # complete = 全てのカウントをテーブルに保持
.start()
)

queryはバックグラウンドで実行されるストリーミングクエリーのハンドルとなります。このクエリーは継続的にファイルを取得し、ウィンドウ内のカウントを更新します。
上のセルのクエリーのステータスに注意してください。プログレスバーはクエリーがアクティブであることを示しています。さらに、上の> countsを展開すると、すでに処理されたファイルの数を確認することができます。
いくつかのファイルが処理されるまで待ち、インメモリのcountsテーブルに対してインタラクティブにクエリーを実行してみましょう。
from time import sleep
sleep(5) # 計算がスタートするまで少し待ちます
%sql select action, date_format(window.end, "MMM-dd HH:mm") as time, count from counts order by time, action
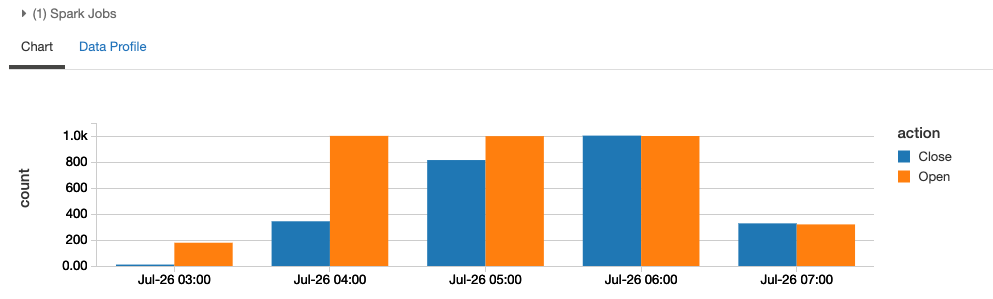
クエリーを実行するごとに結果が更新されていることがわかります。

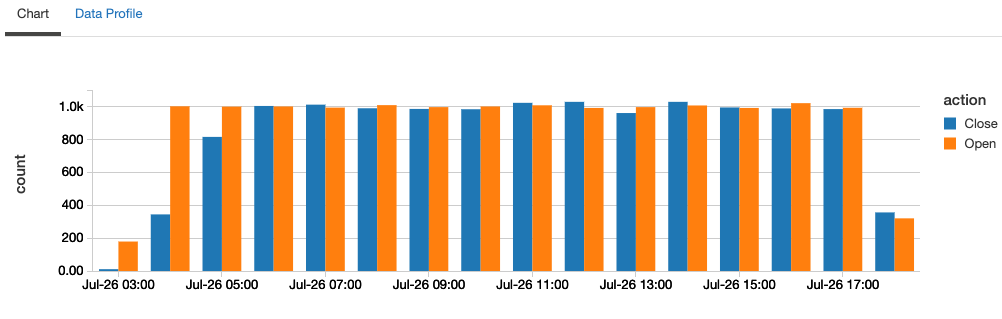
上のクエリーを繰り返し実行し続けることで、"Close"が常に対応する"Open"の後に出現するデータストリームで期待されたように、常に"Close"の数より"Open"の数が多いことを確認することができます。これは、構造化ストリーミングがprefix integrityを保証していることを示しています。prefix integrityの詳細を知りたい方は以下のブログ記事を参照ください。
Spark Structured Streaming - The Databricks Blog
ここでは少数のファイルしか取り扱っていないので、全てのファイルを処理してしまうとカウントは更新されなくなります。再度ストリーミングクエリーを操作したい場合には、クエリーを際実行してください。
最後に、クエリーのセルのCancelリンクをクリックするか、query.stop()を実行することで、バックグラウンドで実行しているクエリーを停止します。いずれの方法でも、クエリーが停止されると対応するセルのステータスは自動的にTERMINATEDとなります。
サンプルノートブック