PEFTの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
🤗 PEFT、あるいはParameter-Efficient Fine-Tuning (PEFT)は、モデルのすべてのパラメーターをファインチューニングすることなしにることなしに、さまざまな後段のアプリケーションに事前学習済み言語モデル(PLM)を効率的に適応させるライブラリです。PEFTのメソッドは少数の(追加の)モデルパラメーターのみをファインチューンするので、大規模なPLMのファインチューニングは非常に高コストですが、劇的に計算コストとストレージコストを削減することができます。最先端のPEFTテクニックは、完全なファインチューニングと同等のパフォーマンスを達成します。
PEFTはDeepSpeedとBig Model Inferenceを活用して大規模モデルに対する🤗 Accelerateとシームレスにインテグレーションされています。
PEFTが初めてであれば、QuicktourガイドとLoRAやPromptingメソッドのコンセプトガイドを読むところからスタートしてください。
サポートされるメソッド
- LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- Prefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- P-Tuning: GPT Understands, Too
- Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
- AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
サポートされるモデル
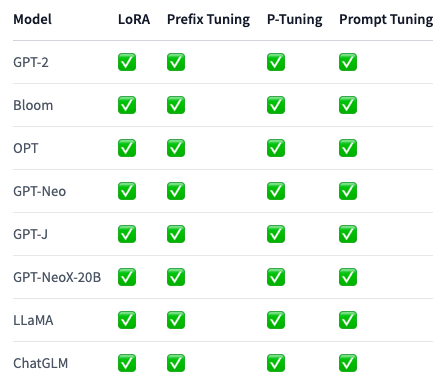
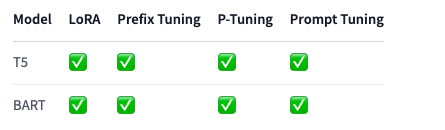
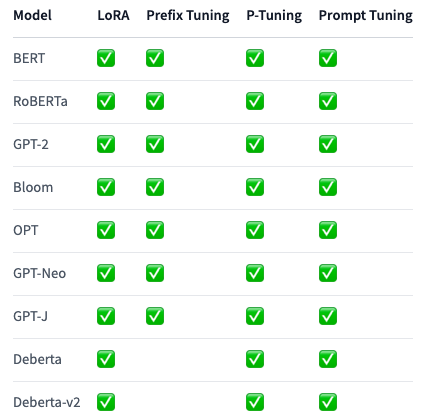
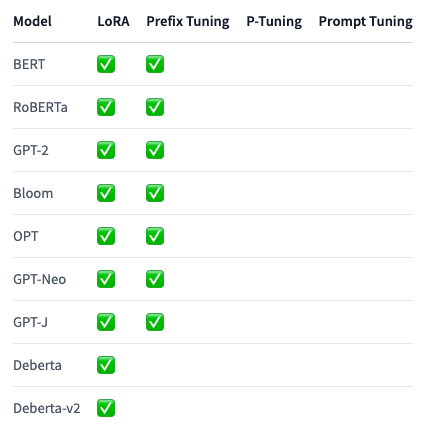
以下のテーブルでは、タスクごとにサポートされるPEFTのメソッドとモデルを一覧しています。タスクに特定のPEFTメソッドを適用するには、対応するタスクガイドを参照ください。
Causal Language Modeling
Conditional Generation
Sequence Classification
Token Classification
Text-to-Image Generation

Image Classification

Image to text (Multi-modal models)
画像分類でのファインチューニングでViTとSwinに対するLoRAをテストしました。しかし、🤗 TransformersのすべてのViT-based modelに対してLoRAを使用することは可能に違いありません。詳細は、Image classificationタスクガイドをご覧ください。問題に遭遇した場合には、イシューをオープンしてください。

Semantic Segmentation
image-to-textモデルと同様に、すべてのsegmentation modelsにLoRAを適用できることは可能に違いありません。我々はこれをすべてのアーキテクチャでまだテストしていないことに注意する必要があります。このため、いかなる問題に遭遇した場合にも、イシューレポートを作成ください。
