以前こちらの記事を書きました。
マニュアルにも掲載されています。気づいたらMLflowもバージョン2.9.1になってました。
こちらのノートブックをウォークスルーします。
import os
os.environ["OPENAI_API_KEY"] = dbutils.secrets.get("demo-token-takaaki.yayoi", "openai")
import openai
import pandas as pd
import mlflow
eval_df = pd.DataFrame(
{
"inputs": [
"How does useEffect() work?",
"What does the static keyword in a function mean?",
"What does the 'finally' block in Python do?",
"What is the difference between multiprocessing and multithreading?",
],
"ground_truth": [
"The useEffect() hook tells React that your component needs to do something after render. React will remember the function you passed (we’ll refer to it as our “effect”), and call it later after performing the DOM updates.",
"Static members belongs to the class, rather than a specific instance. This means that only one instance of a static member exists, even if you create multiple objects of the class, or if you don't create any. It will be shared by all objects.",
"'Finally' defines a block of code to run when the try... except...else block is final. The finally block will be executed no matter if the try block raises an error or not.",
"Multithreading refers to the ability of a processor to execute multiple threads concurrently, where each thread runs a process. Whereas multiprocessing refers to the ability of a system to run multiple processors in parallel, where each processor can run one or more threads.",
],
}
)
with mlflow.start_run() as run:
system_prompt = "Answer the following question in two sentences"
basic_qa_model = mlflow.openai.log_model(
model="gpt-3.5-turbo",
task=openai.ChatCompletion,
artifact_path="model",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "{question}"},
],
)
results = mlflow.evaluate(
basic_qa_model.model_uri,
eval_df,
targets="ground_truth", # specify which column corresponds to the expected output
model_type="question-answering", # model type indicates which metrics are relevant for this task
evaluators="default",
)
results.metrics
{'toxicity/v1/mean': 0.00021154171190573834,
'toxicity/v1/variance': 2.705208305975482e-09,
'toxicity/v1/p90': 0.0002699144184589386,
'toxicity/v1/ratio': 0.0,
'exact_match/v1': 0.0}
メトリクスに関してはこちらに説明がありました。
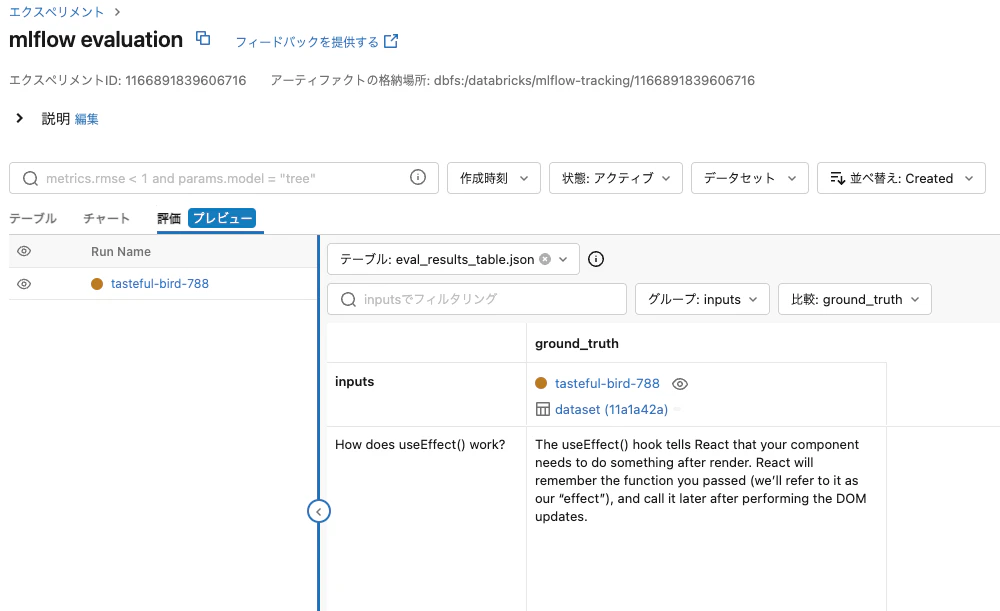
results.tables["eval_results_table"]

評価ビューでも確認できました。
と思ったら、すでに包括的に評価されていらっしゃいました。脱帽です。