How to Use Geospatial Analytics to Extract Key Business Insights - The Databricks Blogの翻訳です。
データサイエンスはより一般的なものとなり、多くの企業はデータドリブンの意思決定を行える様に、分析とビジネスインテリジェンスを活用しています。しかし、皆様は位置空間データを活用して、分析と意思決定を強力にサポートしていますか?ロケーションインテリジェンス、特に位置空間分析は皆様のビジネスにインパクトを与える重要な地域的トレンド、挙動を明らかにするのに役立ちます。ここでは、アメリカや世界の他の地域において、適切な地理的境界とは言えない郵便番号ごとに集約した位置データを見る以上のことに踏み込みます。
あなたは、次にオープンするお店を探そうとしている、あるいは、同じ地域の競合へのトラフィックを理解しようとしている小売業でしょうか?あるいは、次の最適な投資を決定するために地域における不動産トレンドを見ようとしているのでしょうか?物流、サプライチェーンデータを取り扱っており、倉庫や燃料ステーションをどこに設置するのかを決定しようとしているのでしょうか?あるいは、供給が需要を満たせる様にネットワーク、またはサービスのホットスポットを特定する必要があるのでしょうか?これらのユースケース全てに共通する一つのことがあります。これらの緯度経度座標をそれぞれの地理的形状に対応づけるために、ポイント・イン・ポリゴンのオペレーションを実行するということです。
技術的な実装
ポイント・イン・ポリゴンオペレーションを実装する一般的な方法は、オープンソースの地理情報システム(GIS)プロジェクト、PostGISにおけるst_intersectsやst_containsのようなSQL関数を用いるというものでしょう。あるいは、同様な機能を分散処理で実行できるApache Sedona(以前のGeospark)やGeomesaを利用することもできます。しかし、これらの関数は多くの場合で高コストの位置情報の結合が発生し、処理に時間を要します。この記事では、どのようにH3とSparkを活用して、多くの方がメリットを享受することになるであろう、最も一般的な位置情報ワークロードの一つである大規模ポイント・イン・ポリゴン問題を高速に解くのかを見ていきます。
我々は過去のブログ記事で、UberのH3ライブラリを紹介しました。復習となりますが、H3はポリゴンやポイントの様な地理的特徴を、固定セットの同一六角形のセルで近似する位置空間グリッドシステムです。これによって、大規模あるいは計算コストがかかるビッグデータワークロードにスケールすることができます。
我々の例では、使用するWKTデータセットにはH3のpolyfill実装ではうまくいかない可能性がある、MultiPolygonsが含まれています。我々のパイプラインが正確な結果を返す様に、MultiPolygonsをそれぞれのポリゴンに分割する必要があります。
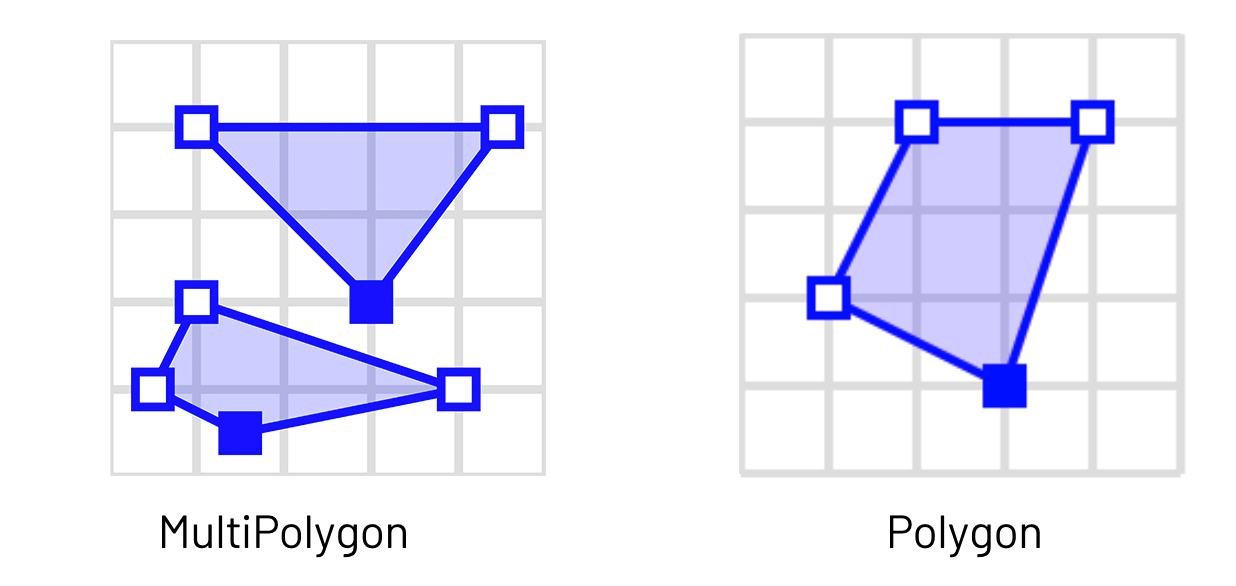
CC BY-SA 3.0でライセンスされているMwtoewsによる"SFA MultiPolygon"
%scala
import org.locationtech.jts.geom.GeometryFactory
import scala.collection.mutable.ArrayBuffer
def getPolygon = udf((geometry: Geometry)=>{
var numGeometries = geometry.getNumGeometries()
var polygonArrayBuffer = ArrayBuffer[Geometry]()
for( geomIter <- 0 until numGeometries)
{polygonArrayBuffer += geometry.getGeometryN(geomIter)}
polygonArrayBuffer
})
val wktDF_polygons = wktDF.withColumn("num_polygons", st_numGeometries(col("the_geom")))
.withColumn("polygon_array", getPolygon(col("the_geom")))
.withColumn("polygon", explode($"polygon_array"))
ポリゴンを分割後は、ポイントとポリゴン両方に対するH3インデックスを定義する関数を作成します。Sparkを用いてスケールできるようにするには、PythonあるいはScalaの関数をSparkのUDFでラップする必要があります。
%scala
val res = 7 //the resolution of the H3 index, 1.2km
val points = df
.withColumn("h3index", hex(geoToH3(col("pickup_latitude"), col("pickup_longitude"), lit(res))))
points.createOrReplaceTempView("points")
val polygons = wktDF
.withColumn("h3index", multiPolygonToH3(col("the_geom"), lit(res)))
.withColumn("h3", explode($"h3index"))
.withColumn("h3", hex($"h3"))
polygons.createOrReplaceTempView("polygons")
H3では0から15の解像度をサポートしており、0は約1,107kmの長さの六角形となり、15は50cmのきめ細かい六角形となります。お使いのデータセットにおけるユニークなポリゴンの数の倍数となる解像度を選択するのが理想的です。この例では、解像度7を選択しました。
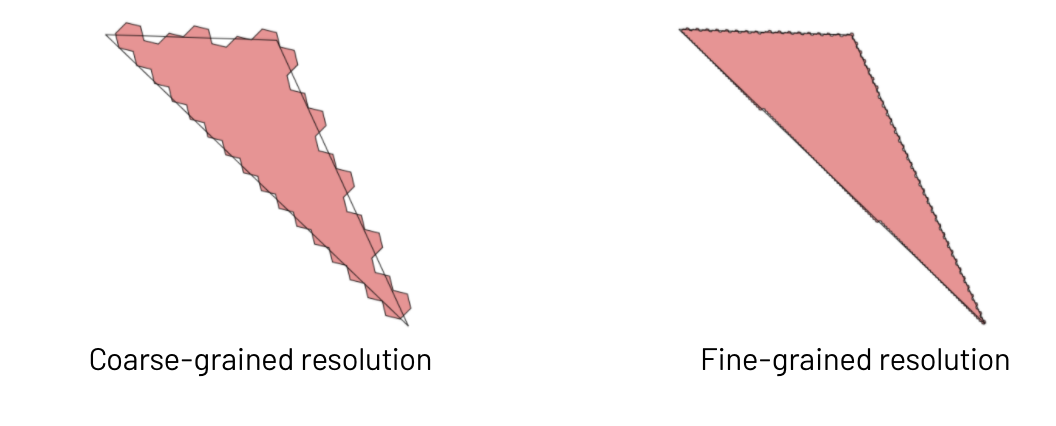
ここで注意すべきことは、ポイント・イン・ポリゴンオペレーションでH3を利用することで、近似された結果を得ることになり、基本的には精度を引き換えにスピードを手に入れるということになるということです。粒度の粗い解像度を選択することで、ポリゴン境界においていくばくかの精度を失いますが、クエリーは高速に実行できることになります。きめ細かい解像度は精度は改善されますが、結合するユニークな六角形の数が増加するので、この後の結合クエリーにおける計算コストが増加します。適切な解像度の選択はある種の芸術であり、どれだけ正確な結果が必要なのかを検討する必要があります。お使いのGPSポイントがそれほど正確でもなくて良いのであれば、スピードに対してある程度精度を犠牲にするというのは許容できると言えます。
H3を用いてポイントとポリゴンをインデクシングすることで、結合クエリーを実行できる様になります。ここでは、高コストな空間joinを行うst_intersectsやst_containsのような空間コマンドを実行するのではなく、H3のインデックスカラムに対してシンプルなSparkのinner joinを実行することができます。数十億のポイント、数千・数百万のポリゴンに対するポイント・イン・ポリゴンクエリーを数分規模で実行することができます。
%sql
SELECT *
FROM
Points p
INNER JOIN
Polygons s
ON p.h3 = s.h3
さらに精度が必要な場合、別のアプローチとして、位置空間joinに渡す行数を削減するためにH3インデックスを活用することができます。この場合、お使いのクエリーはこの様になります。st_intersects()やst_contains()コマンドは、GeosparkやGeomesaのようなサードパーティパッケージから使用される形になります。
%sql
SELECT *
FROM
points p
INNER JOIN
shape s
ON p.h3 = s.h3
WHERE st_intersects(st_makePoint(p.pickup_longitude, p.pickup_latitude), s.the_geom);
ポテンシャルの最適化
位置情報データでデータの偏り(skew)に直面することは一般的です。例えば、過疎地と比較して都市部では大量の携帯電話のGPSデータポイントを受信することになるでしょう。このことは、特定のH3インデックスが他のものよりも大量のデータになり、Spark SQLのjoinで偏りが発生することを意味します。我々のサンプルノートブックでも同様のことが発生しており、ニューヨークの他の部分と比較してマンハッタンでのタクシーの乗車が大量になっています。ここでは、joinの性能を改善するためにskewのヒントを活用することができます。
最初に、トップのH3インデックスがどれかを特定します。
display(points.groupBy("h3").count().orderBy($"count".desc))
次に、トップのインデックスに対して定義したskewヒントを指定してjoinクエリーを再実行します。ポリゴンテーブルがワーカーノードのメモリーに収まるほど小さいのであれば、ブロードキャストを試すこともできます。
SELECT /*+ SKEW('points_with_id_h3', 'h3', ('892A100C68FFFFF')), BROADCAST(polygons) */
*
FROM
points p
INNER JOIN
Polygons s
ON p.h3 = s.h3
また、joinの左側のテーブルの行が多くなる様にすることを忘れないでください。これによって、joinの途中のシャッフルを削減し、劇的にパフォーマンスを改善することができます。
Spark 3.0の新たなAdaptive Query Execution(AQE)によって、skewに対する手動でのブロードキャストや最適化はほぼ不要となります。お好きな位置空間パッケージがSpark 3.0をサポートしているのであれば、ワークロードを加速するために、どのようにAQEを活用で着るのかチェックしてみてください!
データの可視化
H3のヘキサゴンを可視化する良い方法は、Uberによって開発されたKepler.glを活用するというものです。Databricksノートブックで活用できる、Kepler.gl向けのPyPIライブラリが存在します。試してみたい場合には、サンプルノートブックを参照ください。
Kepler.glライブラリはシングルマシンで動作します。このことは、大規模データセットを可視化する際にはサンプリングを行う必要があることを意味します。ポイント・イン・ポリゴンのjoinの結果からランダムでサンプリングし、Pandasデータフレームに変換した後でKepler.glに引き渡します。
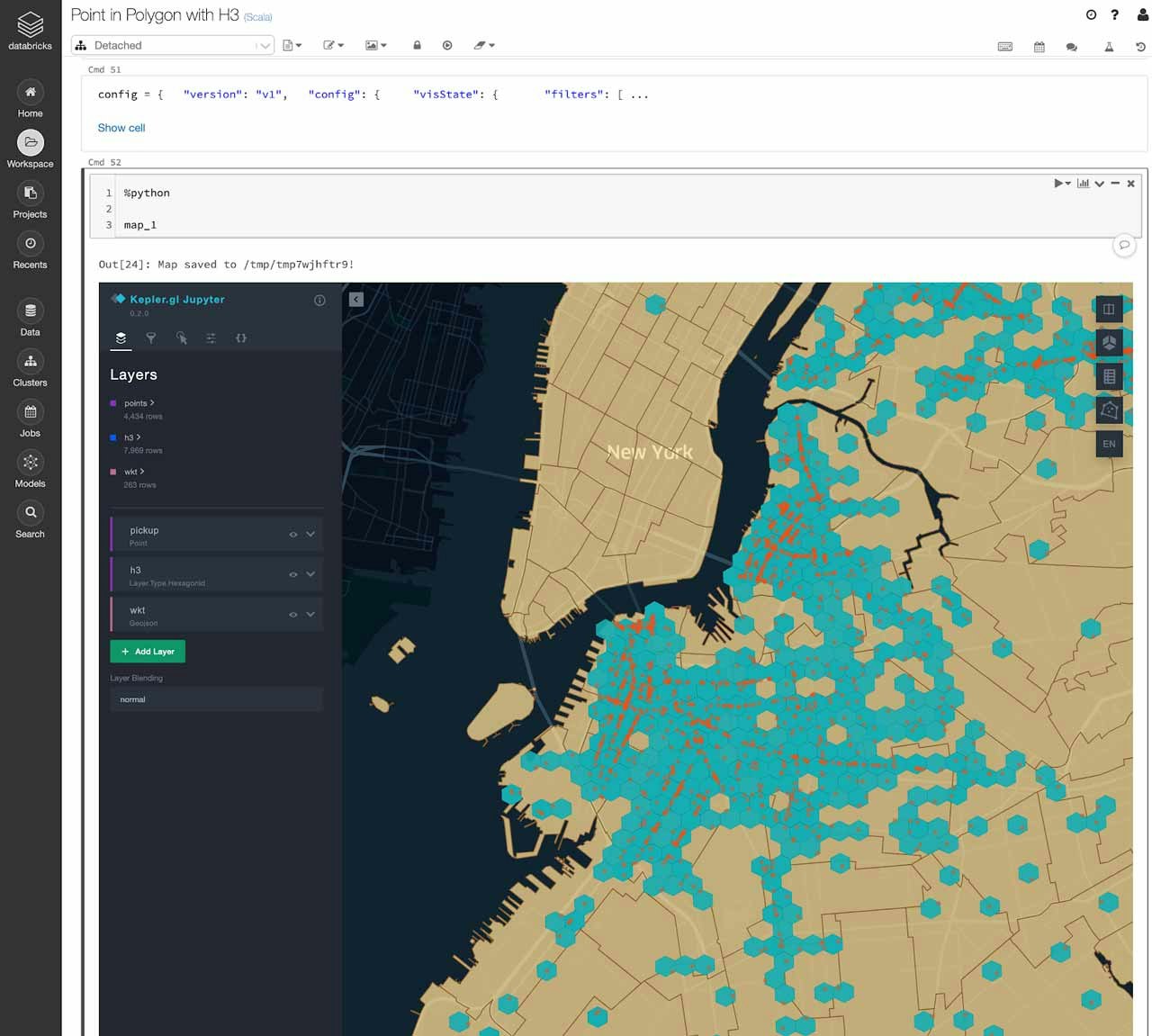
これで、Databricksノートブック上の地図で、ポイント、ポリゴン、ヘキサゴングリッドを探索することができます。これは、ご自身のポイント・イン・ポリゴンマッピングの検証にも適した方法です!
サンプルノートブックを試す。
上のノートブックをブラウザーで表示した際に適切に表示されない場合があります。ベストな結果を見るためには、ノートブックをダウンロードしてDatabricksワークスペースで実行してください。