本記事で説明しているノートブックはこちらです。
SQLを用いてデータをロードし、Pythonを用いて結果を探索したいと思うかもしれません。Databricksノートブックの新機能としてSQLセルとPythonセルでネイティブにデータのやり取りが行えるようになりました。
DatabricksのPythonノートブックでは、SQL言語セルから得られるテーブルの結果は、自動的にPythonデータフレームとして利用できるようになります。Pythonデータフレームの名前は_sqldfとなります。
データロード
Sparkデータフレームとしてデータをロードし、一時ビューとして登録します。
Python
path = "/databricks-datasets/learning-spark-v2/flights/departuredelays.csv"
df = spark.read.option("inferSchema", True).option("header", True).csv(path)
df.createOrReplaceTempView("departure_delays")
SQLからのアクセス
データは一時ビューとして登録されているのでSQLでアクセスできます。SQLで集計を行います。
SQL
%sql
SELECT origin, destination, count(*) as num_flights
FROM departure_delays
GROUP BY origin, destination
ORDER BY num_flights DESC
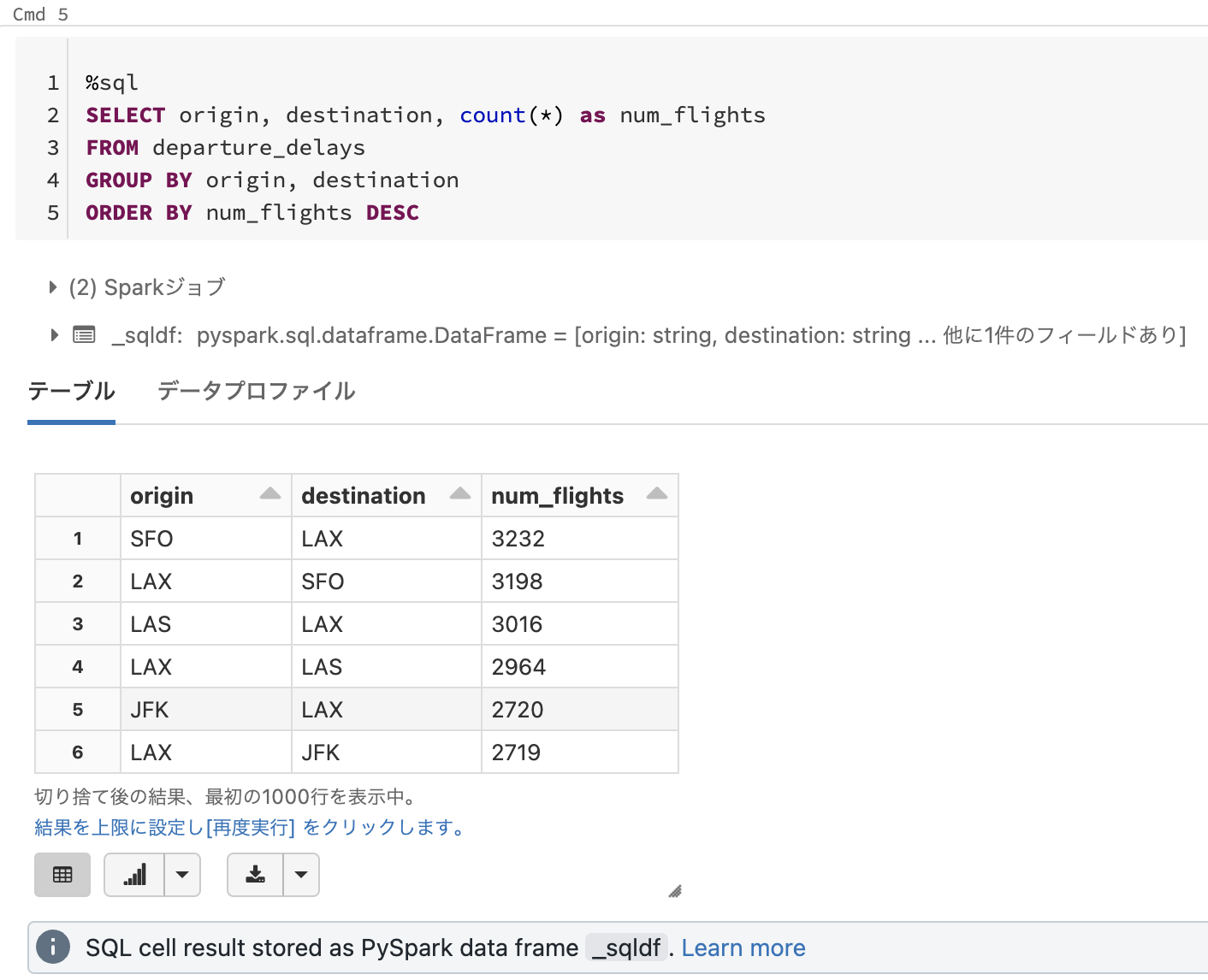
結果が以下のように表示されます。SQLの実行結果は_sqldfというSparkデータフレームに格納されます。
SQL cell result stored as PySpark data frame
_sqldf
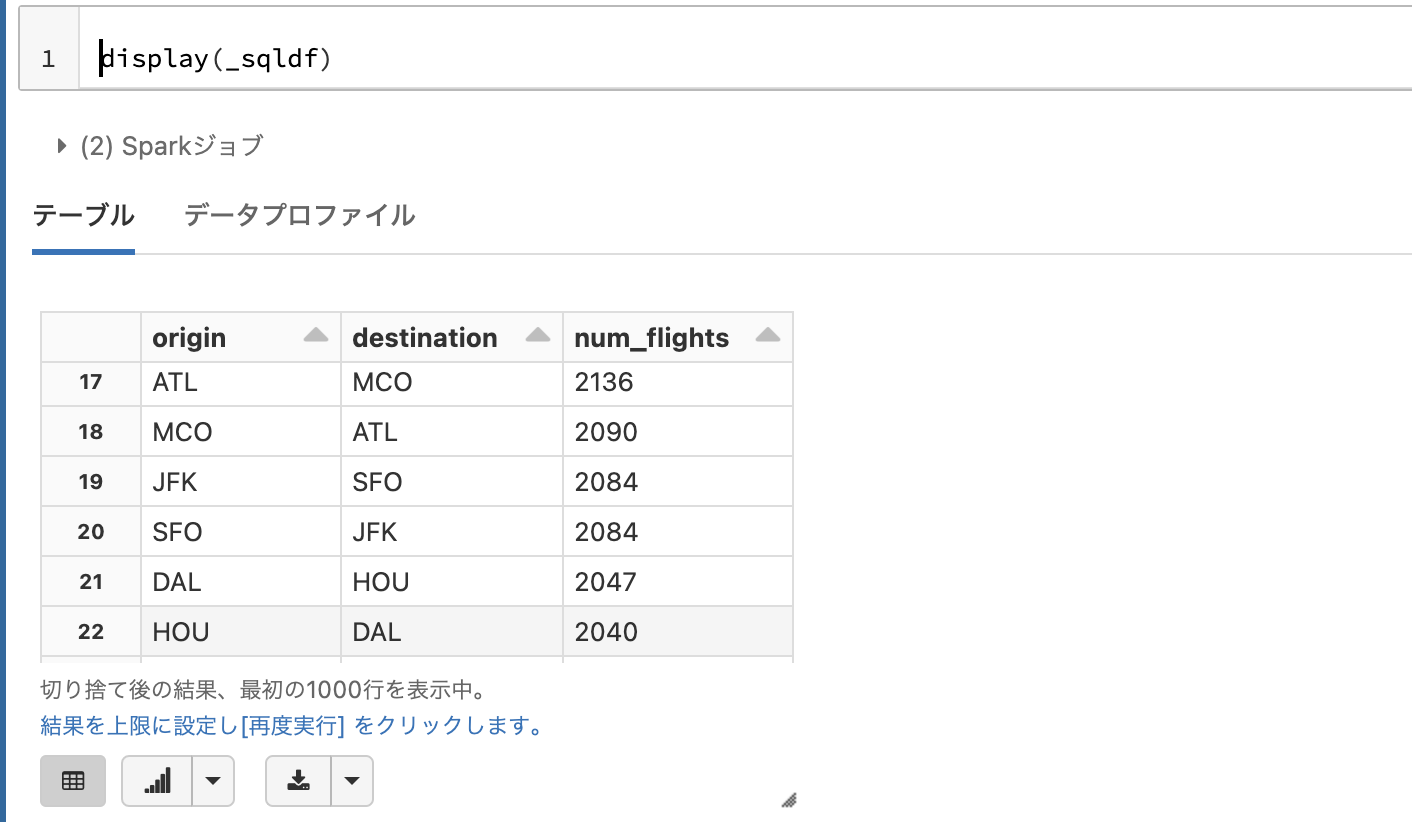
Pythonからのアクセス
Pythonセルからデータフレーム_sqldfにアクセスします。
Python
display(_sqldf)
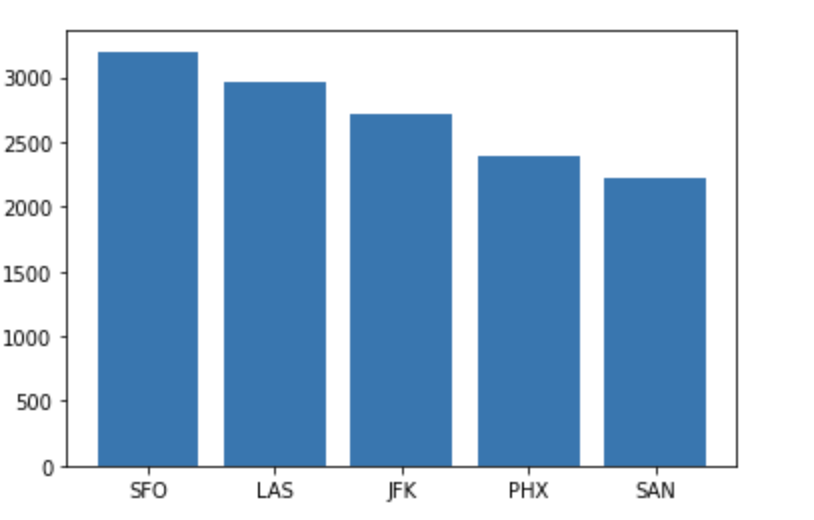
pandasデータフレームに変換して、matplotlibを用いた可視化を行います。
Python
pdf = _sqldf.toPandas()
Python
import matplotlib.pyplot as plt
# 出発地がLAXの上位5件に限定
lax_pdf = pdf[pdf["origin"]=="LAX"][0:5]
x = lax_pdf['destination']
y = lax_pdf['num_flights']
label_x = lax_pdf['destination']
# 中央寄せで棒グラフ作成
plt.bar(x, y, align="center")
plt.xticks(x, label_x) # X軸のラベル
plt.show()
これまで以上に、SQLが得意とする処理はSQL、Pythonが得意とするPythonと棲み分けをしながらシームレスにロジックを記述できるようになりました!