本記事では、DatabricksとLabelboxの連携で説明されている手順を実際にウォークスルーしています。
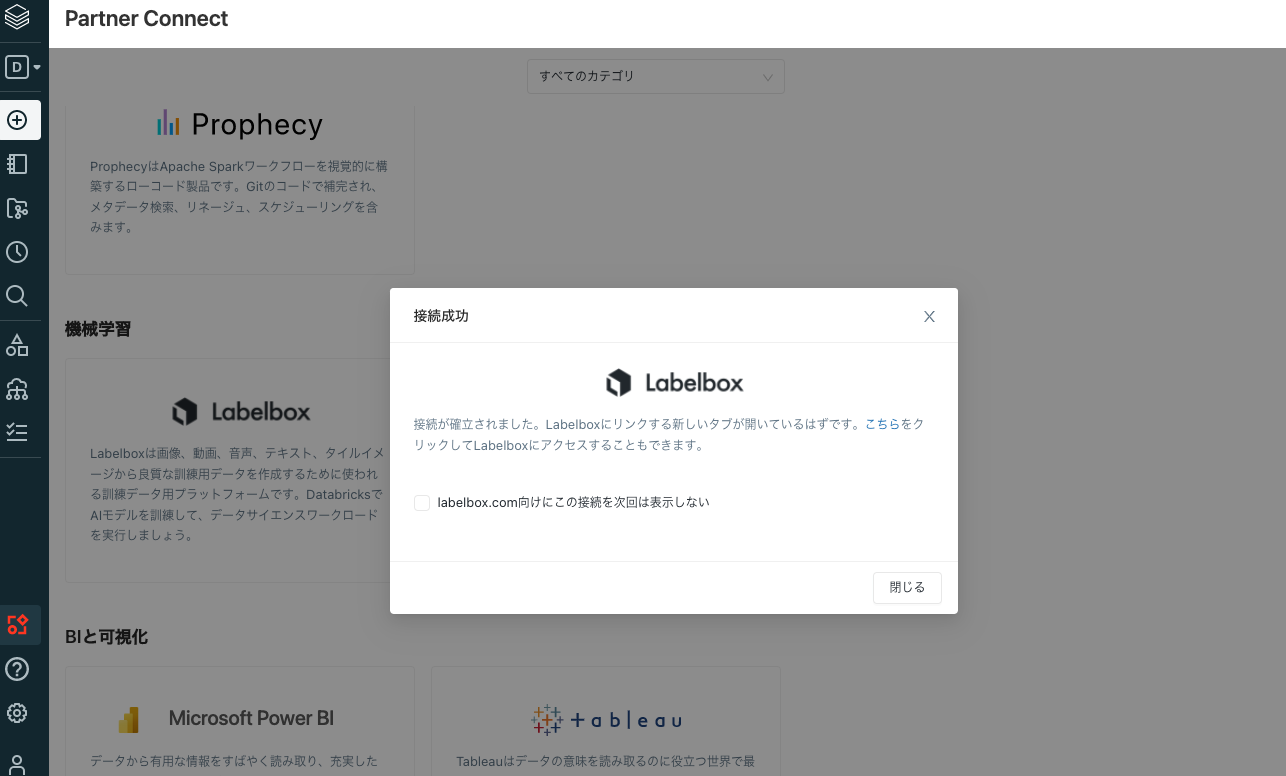
Partner ConnectによるLabelboxへの接続
ワークスペースのサイドバーのPartner Connectをクリックします。
機械学習にあるLabelboxをクリックします。
次のページをクリックします。
Labelboxに接続をクリックします。
新規タブでLabelboxが開きますので、Continue trial sign-upをクリックします。
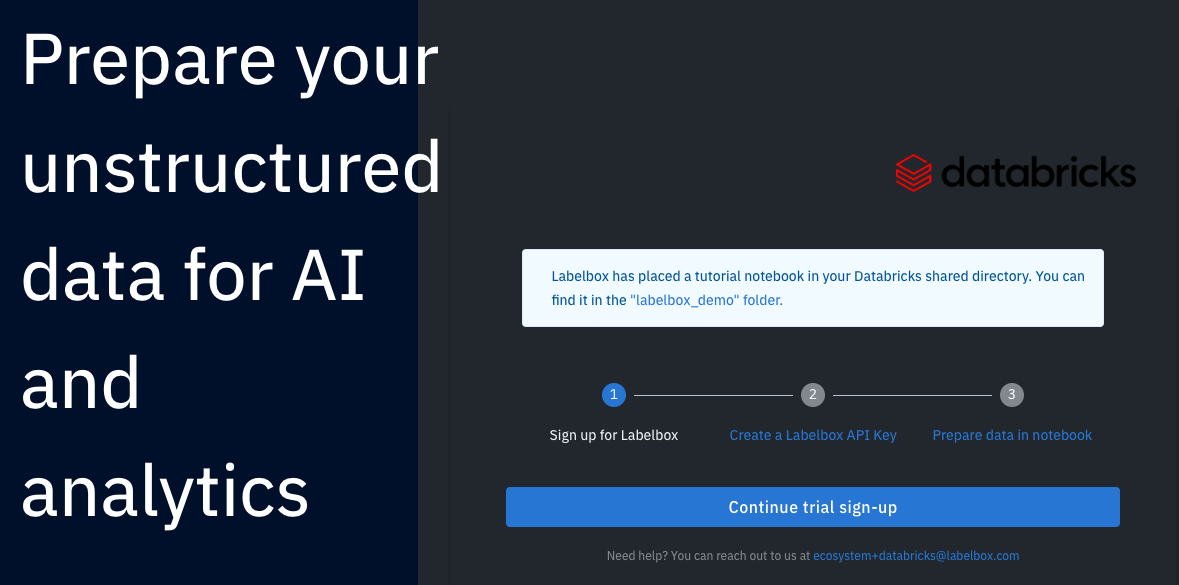
アカウントが存在しない場合には、Sign Upを選択し、企業名、パスワード、氏名を入力します。
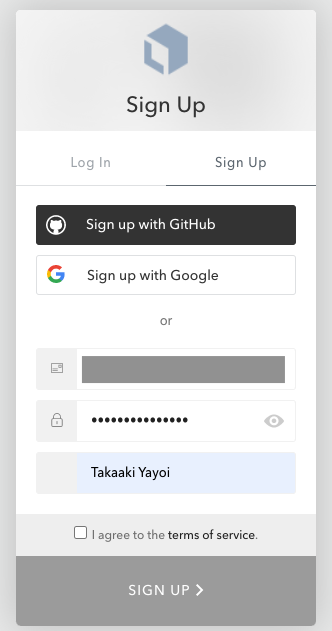
確認メールが送信されます。

メールに記載のVerify Accountをクリックします。
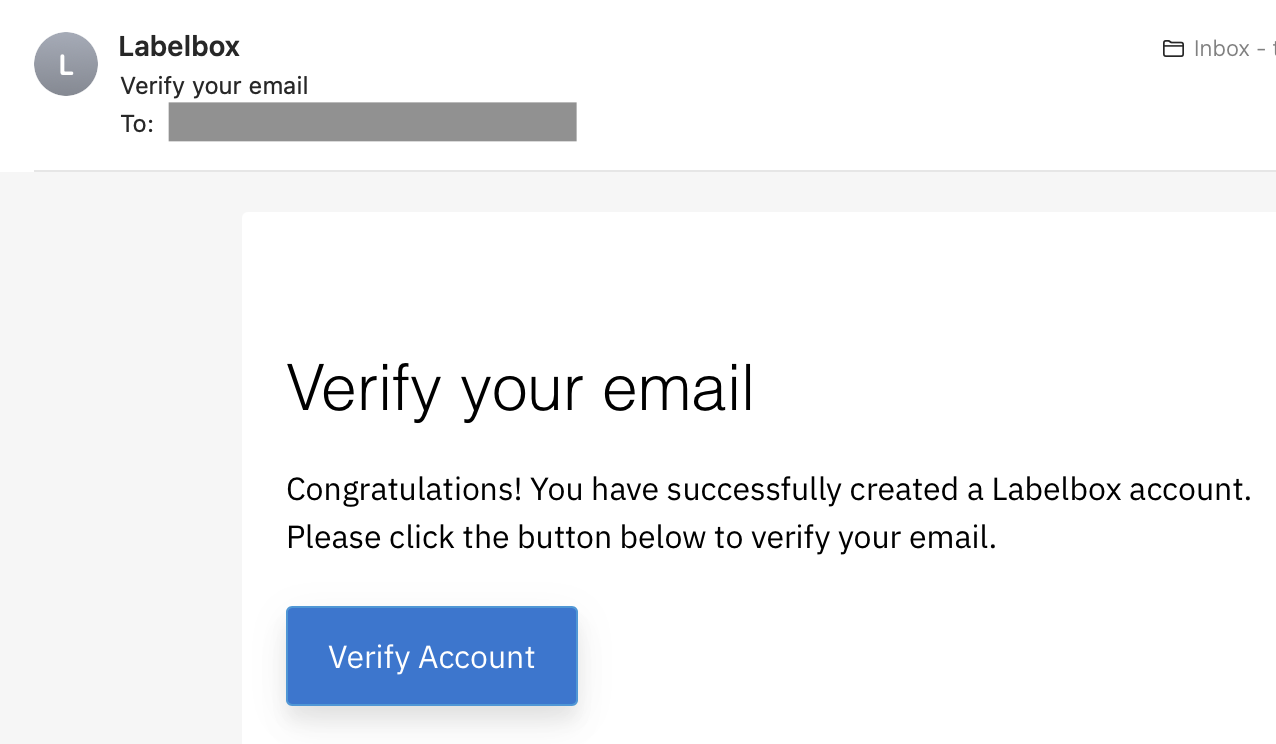
会社名とロールを選択します。
これで、Labelboxへの接続が確立されました。
Databricks側でも接続成功のメッセージが表示されます。

クラスターとLabelboxスターターノートブックのセットアップ
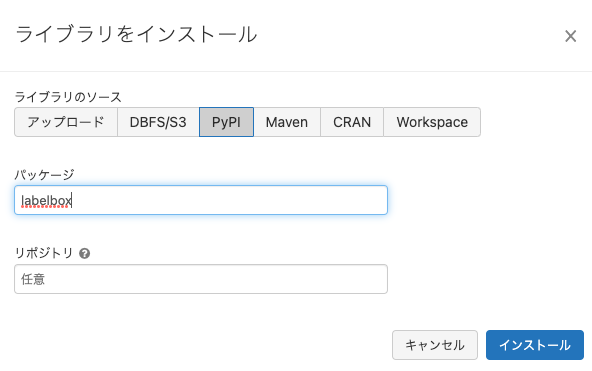
上の設定でLABELBOX_CLUSTERというクラスターが作成されているので、このクラスターに必要なライブラリをインストールします。
ライブラリの画面に移動します。
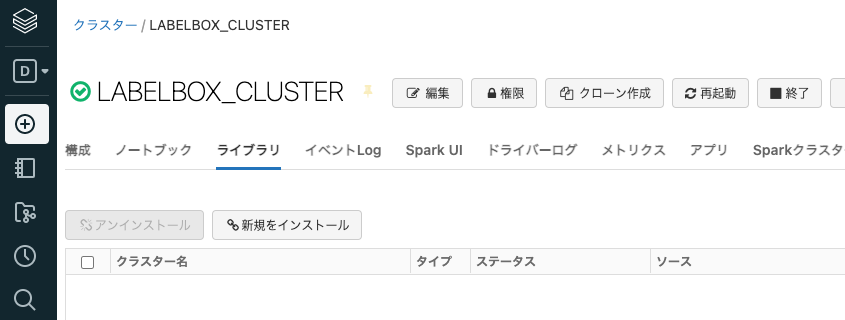
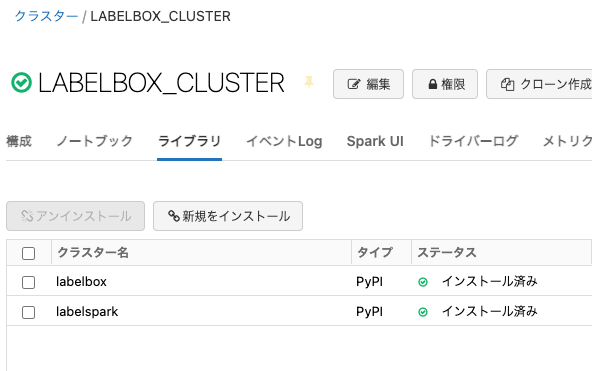
新規をインストールをクリックして、labelboxとlabelsparkをPyPI経由でインストールします。
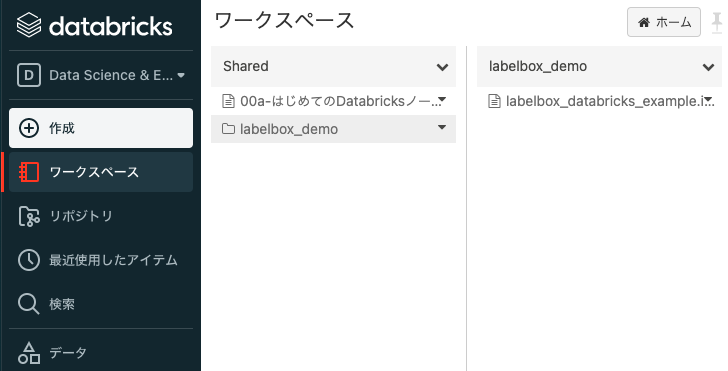
サンプルノートブックがWorkspace > Shared > labelbox_demo > labelbox_databricks_example.ipynbに作成されているので、これを開きます。
サンプルノートブックの実行
上のクラスターにノートブックをアタッチします。

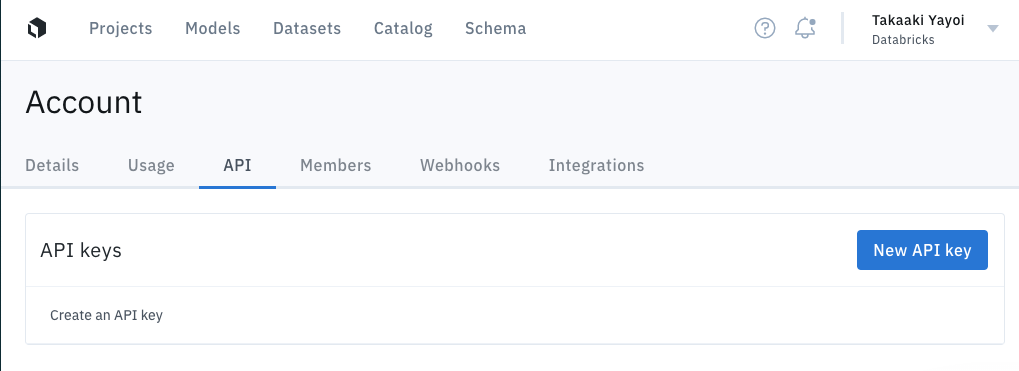
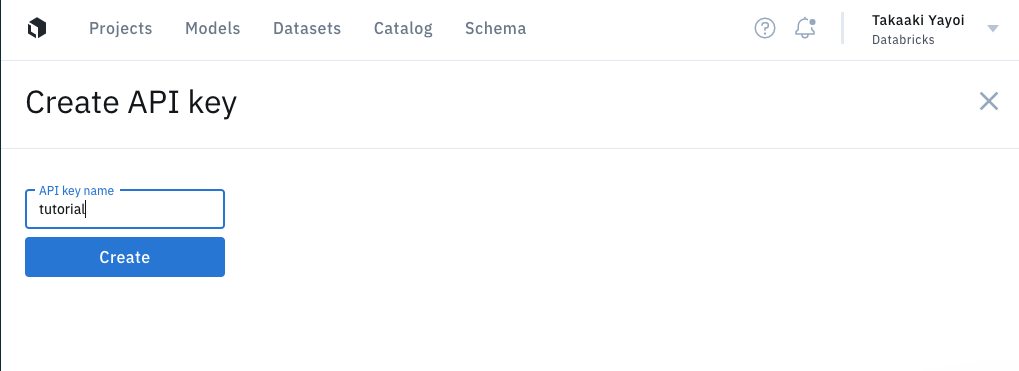
Labelboxに移動して、Account > APIに移動し、APIキーを作成します。

SDKの設定
LabelboxとDatabricksのライブラリがインストールできたので、SDKを設定する必要があります。こちらからAPIキーを作成する必要があります。DatabricksシークレットAPIを用いてキーを格納することも可能です。SDKは環境変数LABELBOX_API_KEYの読み込みを試行します。
from labelbox import Client, Dataset
from labelbox.schema.ontology import OntologyBuilder, Tool, Classification, Option
import databricks.koalas as pd
import labelspark
API_KEY = "<APIキー>"
if not(API_KEY):
raise ValueError("Go to Labelbox to get an API key")
client = Client(API_KEY)
シードデータの取り込み
次に、デモ用データセットをSparkテーブルにロードし、URLを通じて簡単にアセットをLabelboxにロードする方法を理解することができます。シンプルにするために、LabelboxからデータセットIDを取得することができ、みなさまが使用できるようにこれらのURLをSparkテーブルにロードします(なので、このデモノートブックを実行するためにデータを見つけ出す必要はありません)。以下では、Labelboxトライアルに含まれる"Example Nature Dataset"を取得します。
また、LabelboxはAWS、Azure、GCPのクラウドストレージをネイティブでサポートしています。Delegated Accessを通じてLabelboxをお使いのストレージに接続することができ、アノテーションするためにこれらのアセットを簡単にロードすることができます。詳細については、こちらの動画をご覧ください。
sample_dataset = next(client.get_datasets(where=(Dataset.name == "Example Nature Dataset")))
sample_dataset.uid
# ディレクトリをパースし、画像URLのSparkテーブルを作成することができます
SAMPLE_TABLE = "sample_unstructured_data"
tblList = spark.catalog.listTables()
if not any([table.name == SAMPLE_TABLE for table in tblList]):
df = pd.DataFrame([
{
"external_id": dr.external_id,
"row_data": dr.row_data
} for dr in sample_dataset.data_rows()
]).to_spark()
df.registerTempTable(SAMPLE_TABLE)
print(f"Registered table: {SAMPLE_TABLE}")
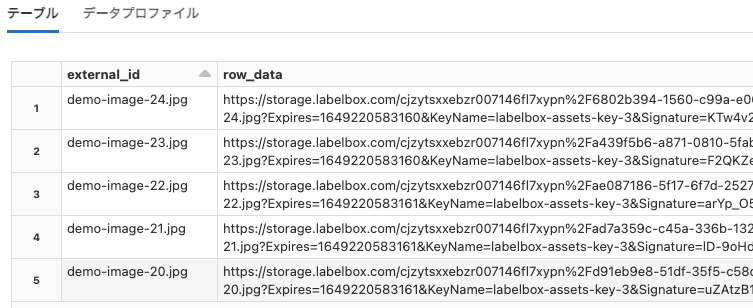
テーブルの中身を確認します。
display(sqlContext.sql(f"select * from {SAMPLE_TABLE} LIMIT 5"))
ラベリングプロジェクトの作成
プロジェクトはチームがラベルを作成する場所となります。プロジェクトにはラベル付けされるアセットのデータセットと、ラベリングの推論を設定するためのオントロジーを必要となります。
ステップ 1: データセットの作成
Labelbox Connector for Databricksは、2つのカラムを持つSparkテーブルを期待します。最初のカラムは"external_id"で、2つ目のカラムは"row_data"となります。
external_idは"birds.jpg"や"my_video.mp4"のようなファイル名となります。
row_dataはファイルに対するURLパスとなります。Labelboxはラベリングを行う際、ユーザーのマシンにローカルにレンダリングするので、ラベリング担当はアセットにアクセスする権限を必要とします。
サンプル:
| external_id | row_data |
|---|---|
| image1.jpg | https://url_to_your_asset/image1.jpg |
| image2.jpg | https://url_to_your_asset/image2.jpg |
| image3.jpg | https://url_to_your_asset/image3.jpg |
unstructured_data = spark.table(SAMPLE_TABLE)
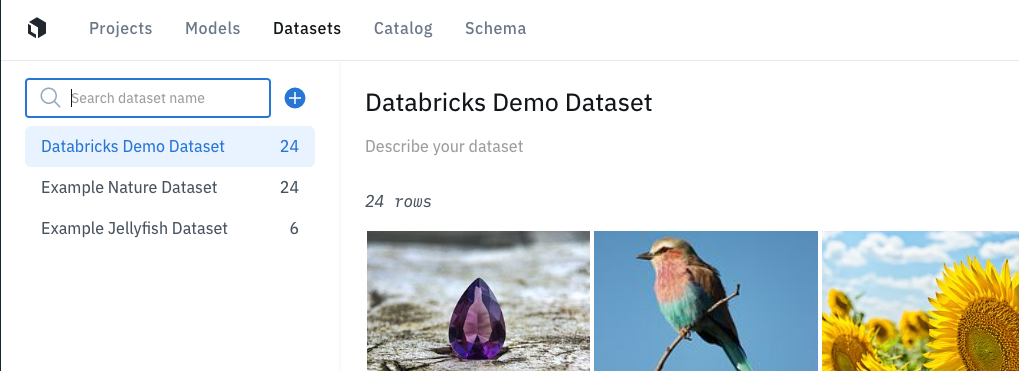
demo_dataset = labelspark.create_dataset(client, unstructured_data, "Databricks Demo Dataset")
print("Open the dataset in the App")
print(f"https://app.labelbox.com/data/{demo_dataset.uid}")
表示されるURLにアクセスするとデータセットを確認できます。
ステップ 2: プロジェクトの作成
使用するオントロジー(次に実施します)を構築するためにlabebox SDKを使用します。app.labelbox.comのウェブサイトを通じて、プロジェクト全体をセットアップすることができます。
ontology creation documentation.をチェックしてください。
# 新規プロジェクトの作成
project_demo = client.create_project(name="Labelbox and Databricks Example")
project_demo.datasets.connect(demo_dataset) # キューにデータセットを追加
ontology = OntologyBuilder()
tools = [
Tool(tool=Tool.Type.BBOX, name="Frog"),
Tool(tool=Tool.Type.BBOX, name="Flower"),
Tool(tool=Tool.Type.BBOX, name="Fruit"),
Tool(tool=Tool.Type.BBOX, name="Plant"),
Tool(tool=Tool.Type.SEGMENTATION, name="Bird"),
Tool(tool=Tool.Type.SEGMENTATION, name="Person"),
Tool(tool=Tool.Type.SEGMENTATION, name="Sleep"),
Tool(tool=Tool.Type.SEGMENTATION, name="Yak"),
Tool(tool=Tool.Type.SEGMENTATION, name="Gemstone"),
]
for tool in tools:
ontology.add_tool(tool)
conditions = ["clear", "overcast", "rain", "other"]
weather_classification = Classification(
class_type=Classification.Type.RADIO,
instructions="what is the weather?",
options=[Option(value=c) for c in conditions]
)
ontology.add_classification(weather_classification)
# エディターのセットアップ
for editor in client.get_labeling_frontends():
if editor.name == 'Editor':
project_demo.setup(editor, ontology.asdict())
print("Project Setup is complete.")
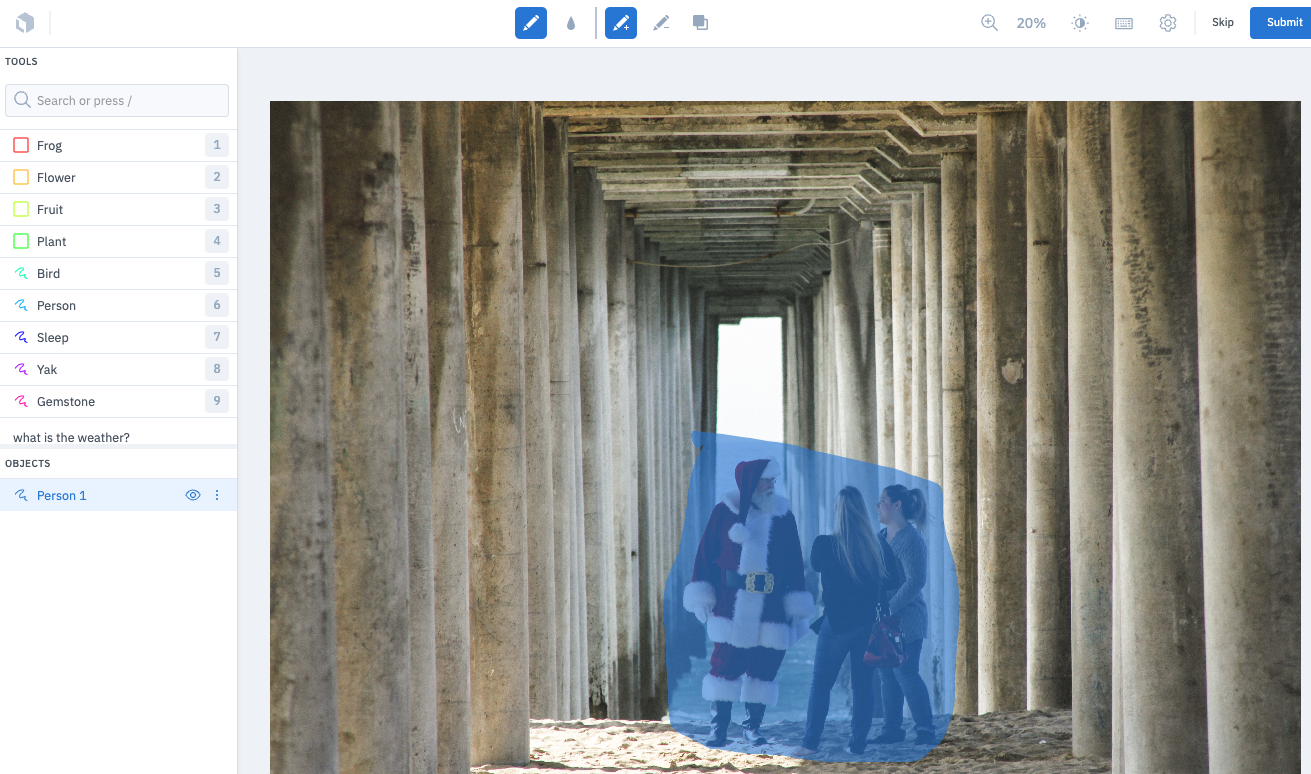
ステップ 3: データラベリングの実施
print("Open the project to start labeling")
print(f"https://app.labelbox.com/projects/{project_demo.uid}/overview")
表示されるURLにアクセスして、ラベリングを行います。
ラベル・アノテーションのエクスポート
Labelboxでラベルを作成した後は、Databricksでモデルのトレーニング、分析に使用するためにこれらをエクスポートすることができます。
LABEL_TABLE = "exported_labels"
labels_table = labelspark.get_annotations(client, project_demo.uid, spark, sc)
labels_table.registerTempTable(LABEL_TABLE)
display(labels_table)
サンプルノートブックはこちらからダウンロードできます。