Native integration of Apache Airflow with Databricks SQL. - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Databricksにおける一連のApache Airflowサポートのエンハンスを発表できることを嬉しく思います。これらの新機能によって、人気のあるオープンソースのオーケストレーターを用いて堅牢なデータおよび機械学習(ML)パイプラインを容易に構築できるようになります。新たなDatabricksSqlOperatorのような最新のエンハンスによって、お客さまはDatabricksにおける標準的なSQLを使用したデータの取り込み、クエリーを行うためにAirflowを用いることができ、ノートブック上で分析やMLタスクを実行し、レイクハウスにおけるデータを変換するためにDelta Live Tablesを起動することなどができます。
Apache Airflowは、Pythonを用いてプログラム的に、データと機械学習パイプライン(Airflowの用語ではDAGと呼ばれます)を作成、スケジュール、モニタリングすることができる人気かつ拡張可能なプラットフォームです。Airflowには、データベースからクラウドストレージに至る全てとのやりとりを容易にするビルトインのオペレーターが多数含まれています。Databricksは2017年以降Airflowをサポートしており、AirflowのユーザーはDatabricksのレイクハウスプラットフォーム上で、ノートブック、JAR、Pythonスクリプトを組み合わせたワークフローを起動することができ、地球上で最も困難なデータとMLワークフローにスケールすることができます。
リアルワールドのタスクを通じて新機能のツアーをしていきましょう。Databricksノートブックを使用せずに、APIから新たに取得した気候データをDeltaテーブルにロードするシンプルなデータパイプラインを構築します。この記事の目的のためには、全てのをAzure上で行いますが、プロセスはAWSやGCPでもほぼ同じです。また、全てのステップをSQLエンドポイント上で行いますが、all-purposeのクラスターを使ったとしてもプロセスはほぼ同じです。最終的なサンプルのDAGはAirflowのUI上で以下のようなものとなります。
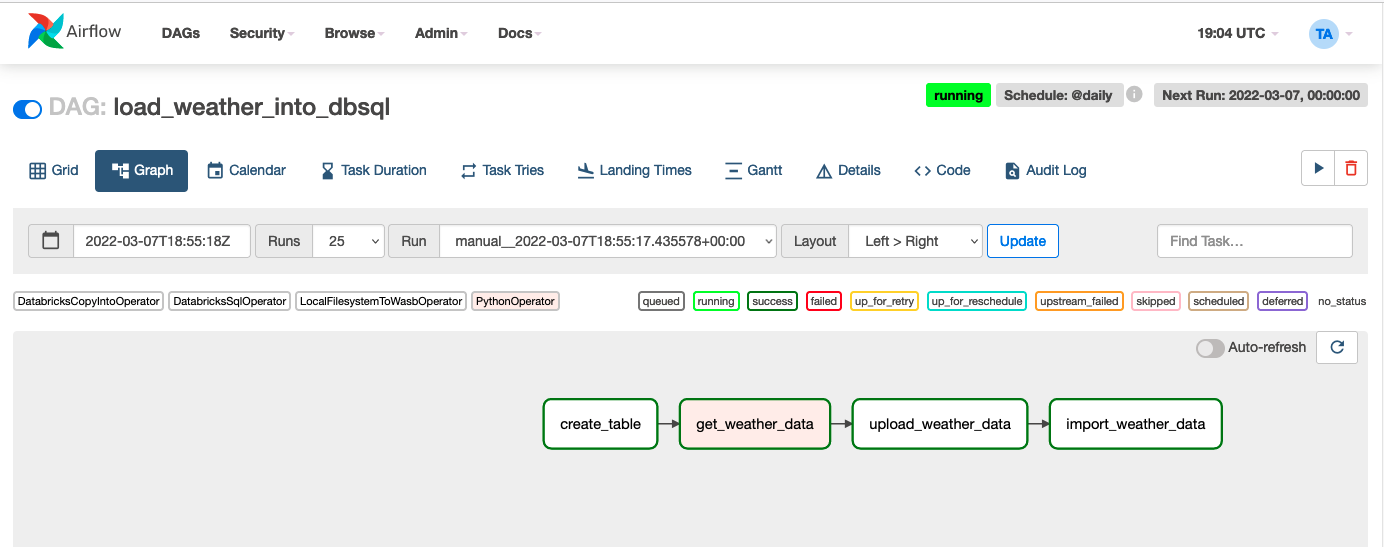
簡単にするために、この記事ではいくつかのコードを省略しています。完全なコードはこちらから参照することができます。
Airflowのインストールおよび設定
この記事では、すでにAirflow 2.1.0以降がインストールされ、Databricksとの接続が設定済みであることを前提としています。Apache Airflowに対する最新バージョンのDatabricksプロバイダーをインストールします。
pip install apache-airflow-providers-databricks
気候データを格納するためのテーブルの作成
ここでは、日次で実行するAirflowのDAGを定義します。最初のタスクcreate_tableは、テーブルが存在していない場合にdefaultスキーマ(データベース)にairflow_weatherというテーブルを作成するSQL文を実行します。このタスクでは、SQLエンドポイントを含むDatabricksの計算資源上で任意のSQL文を実行することができるDatabricksSqlOperatorをデモンストレーションします。
with DAG(
"load_weather_into_dbsql",
start_date=days_ago(0),
schedule_interval="@daily",
default_args=default_args,
catchup=False,
) as dag:
table = "default.airflow_weather"
schema = "date date, condition STRING, humidity double, precipitation double, " \
"region STRING, temperature long, wind long, " \
"next_days ARRAY<STRUCT>"
create_table = DatabricksSqlOperator(
task_id="create_table",
sql=[f"create table if not exists {table}({schema}) using delta"],
)
APIからの気候データの取得およびクラウドストレージへのアップロード
次に、気候APIにリクエストを行い、結果を一時的な場所にJSONファイルで格納するためにPythonOperatorを使用します。
ローカルに気候データを保存したら、我々はAzureストレージを使用しているのでLocalFilesystemToWasbOperatorを用いてクラウドストレージにアップロードします。もちろん、AirflowはAmazon S3やGoogle Cloud Storageへのファイルのアップロードもサポートしています。
get_weather_data = PythonOperator(task_id="get_weather_data",
python_callable=get_weather_data,
op_kwargs={"output_path": "/tmp/{{ds}}.json"},
)
copy_data_to_adls = LocalFilesystemToWasbOperator(
task_id='upload_weather_data',
wasb_conn_id='wasbs-prod,
file_path="/tmp/{{ds}}.json",
container_name='test',
blob_name="airflow/landing/{{ds}}.json",
)
上ではAirflowに変数をスケジュールされたタスクの実行日で置き換えるように{{ds}}を使用していることに注意してください。これにより、一貫性のあるファイル名となり、ファイル名の衝突を回避することができます。
テーブルへのデータの取り込み
最後になりますが、これでデータをテーブルにインポートする準備が整いました。これを行うためには、COPY INTOのSQL文を生成する便利なDatabricksCopyIntoOperatorを使用します。COPY INTOコマンドはシンプルですが、クラウドストレージ上のファイルからテーブルに取り込む際に冪等性を確保できるパワフルな手段です。
import_weather_data = DatabricksCopyIntoOperator(
task_id="import_weather_data",
expression_list="date::date, * except(date)",
table_name=table,
file_format="JSON",
file_location="abfss://mycontainer@mystoreaccount.dfs.core.windows.net/airflow/landing/", files=["{{ds}}.json"])
完了です!数行のコードで、APIからテーブルにデータを取り込む信頼性のあるデータパイプラインを構築しました。
これで全てではありません...
また、我々はAirflowとDatabricksのインテグレーションを簡単なものにするいくつかの改善点を発表できることを嬉しく思います。
- DatabricksSubmitRunOperatorが最新のJobs API v2.1を使用するようにアップグレードされました。新たなAPIによって、DatabricksSubmitRunOperatorを用いてサブミットされたジョブのアクセスコントロールの設定が遥かに容易なものとなり、開発者やサポートチームが容易にジョブUIやログにアクセスできるようになります。
- AirflowからDelta Live Tablesのパイプラインを起動できるようになりました。
- AirflowのDAGでJARタスクタイプにパラメーターを引き渡せるようになりました。
- ジョブが常に最新バージョンのコードを使用することを保証できるように、DatabricksのReposを特定のブランチやタグにアップデートできるようになりました。
- Azureにおいては、パーソナルアクセストークン(PAT)ではなくAzure Active Directoryのトークンを使用できるようになりました。例えば、マネージドIDを用いてAirflowがAzure VM上で稼働している場合、DatabricksのオペレーターはPATトークンを使うことなしに、Azure Databricksを認証するためにマネージドIDを使用することができます。他の認証に関するエンハンスに関しては、こちらを参照ください。
DatabricksにおけるAirflowユーザーの未来は明るいものです
我々はこれらの改善にワクワクしており、AirflowコミュニティがDatabricksで何を生み出すのかを見るのを楽しみにしています。次にどの機能を追加すべきかに関してフィードバックをお待ちしております。