こちらの機能を試してみたら思った以上に便利だったのです。
これまでは、Databricksのモデル管理はモデルレジストリで行っていたのですが、この機能自体がUnity Catalogに組み込まれました。
サンプルがこちらにあるので、日本語訳した上でウォークスルーします。
ノートブックの日本語訳はこちらです。
Unity Catalogにおける機械学習モデルのサンプル
このノートブックでは、風力発電の日次の電力出力を予測する機械学習アプリケーションを構築するために、どのようにUnity Catalogのモデルを活用するのかを説明します。このサンプルでは以下の方法を説明します:
- MLflowによるモデルの追跡と記録
- Unity Catalogへのモデルの登録
- モデルの説明文の追加、推論のためのエイリアスを用いたデプロイ
- プロダクションアプリケーションと登録モデルのインテグレーション
- Unity Catalogでのモデルの検索と特定
- モデルのアーカイブと削除
本書では、Unity CatalogのUIとAPIを通じたモデルとMLflowトラッキングを用いて、これらのステップの実行方法を説明します。
前提条件
- ワークスペースでUnity Catalogが有効化されていること。
- ワークスペースが権限継承をサポートしているUnity Catalogメタストアにアタッチされていること。2022/8/25移行に作成されたすべてのメタストアではサポートされています。
- Unity Catalogにアクセスできるクラスターにアクセスできること。
- このノートブックはデフォルトでは
main.defaultスキーマにモデルを作成します。これには、mainカタログに対するUSE CATALOG権限、main.defaultスキーマに対するUSE SCHEMA権限が必要となります。同じ権限を持っている限り、このノートブックで使用するカタログやスキーマを変更することができます。
MLflow Pythonクライアントのインストール
Unity Catalogのモデルにアクセスするには、バージョン2.4.1以降のMLflow Pythonクライアントが必要です。以下のセルでは、それとMLモデルのトレーニングで使用するtensorflowのインストールを行っています。
%pip install --upgrade "mlflow-skinny[databricks]>=2.4.1" tensorflow
dbutils.library.restartPython()
Unity CatalogのモデルにアクセスするようにMLflowクライアントを設定
デフォルトでは、MLflow PythonクライアントはDatabricksワークスペースのモデルレジストリにモデルを作成します。Unity Catalogのモデルにアップグレードするには、以下のようにMLflowクライアントを設定します:
import mlflow
mlflow.set_registry_uri("databricks-uc")
データセットのロード
以下のコードでは、アメリカの気候と風力発電の出力情報を含むデータセットをロードします。データセットには6時間ごと(00:00に1回、08:00に1回、16:00に1回)にサンプリングされるwind direction、wind speed、air temperatureの特徴量、数年分の日毎の電力出力合計(power)が含まれています。
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
モデルのトレーニング、登録、デプロイ
以下のコードでは、データセットの気候特徴量に基づいて電力出力を予測するために、TensorFlow Kerasを用いたニューラルネットワークをトレーニングします。Unity Catalogにフィッティングしたモデルを登録するためにMLflow APIを活用します。
# 必要に応じて必要に応じてUnity Catalogのモデルを格納するカタログとスキーマ名を変更することができます
CATALOG_NAME = "takaakiyayoi_catalog"
SCHEMA_NAME = "wind_power"
MODEL_NAME = f"{CATALOG_NAME}.{SCHEMA_NAME}.wind_forecasting"
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from mlflow.models import infer_signature
def train_and_register_keras_model(X, y):
with mlflow.start_run():
model = Sequential()
model.add(Dense(100, input_shape=(X.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X, y, epochs=100, batch_size=64, validation_split=.2)
example_input = X[:10].to_numpy()
example_output = model.predict(X)
mlflow.tensorflow.log_model(
model,
artifact_path="model",
signature=infer_signature(example_input, example_output),
registered_model_name=MODEL_NAME
)
return model
X_train, y_train = get_training_data()
model = train_and_register_keras_model(X_train, y_train)
これで、データエクスプローラを確認するとモデルの下にモデルが作成されていることがわかります。
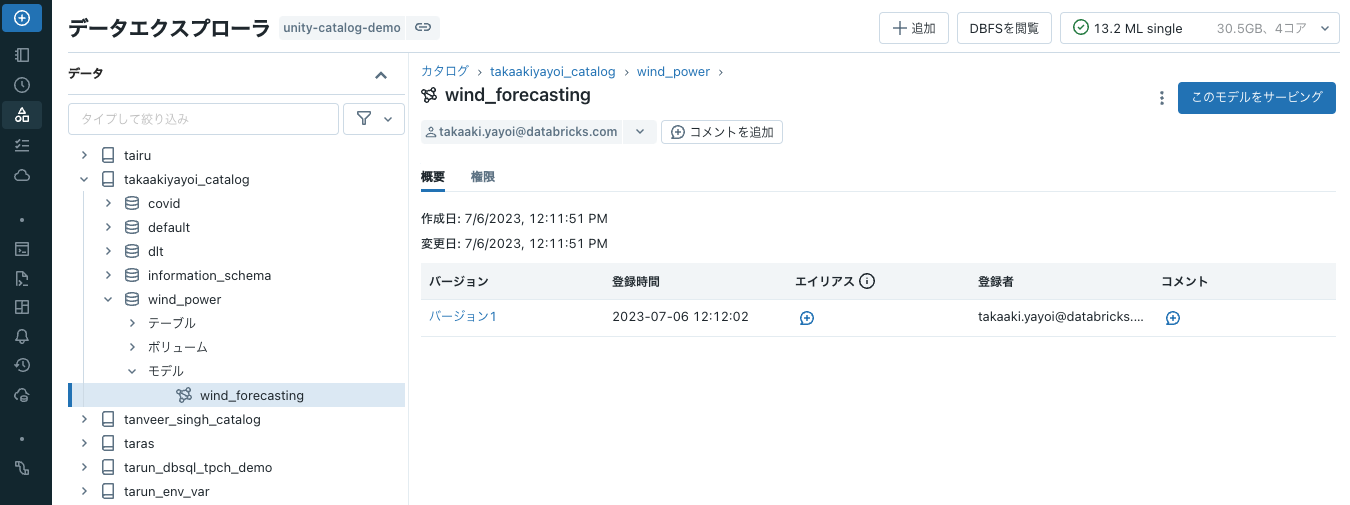
APIによるモデルとモデルバージョンの説明の追加
先ほどトレーニングしたモデルバージョンを特定し、モデルバージョンと登録モデルに説明文を追加するためにMLflow APIを活用することができます:
from mlflow.tracking.client import MlflowClient
def get_latest_model_version(model_name):
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
return max([model_version_info.version for model_version_info in model_version_infos])
latest_version = get_latest_model_version(model_name=MODEL_NAME)
client = MlflowClient()
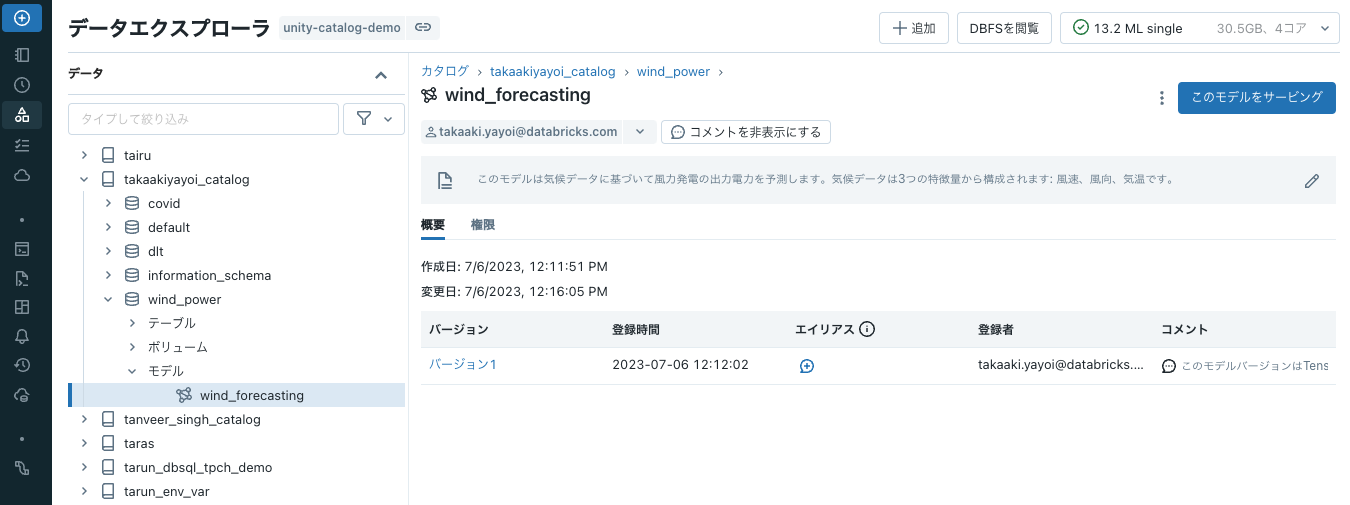
client.update_registered_model(
name=MODEL_NAME,
description="このモデルは気候データに基づいて風力発電の出力電力を予測します。気候データは3つの特徴量から構成されます: 風速、風向、気温です。"
)
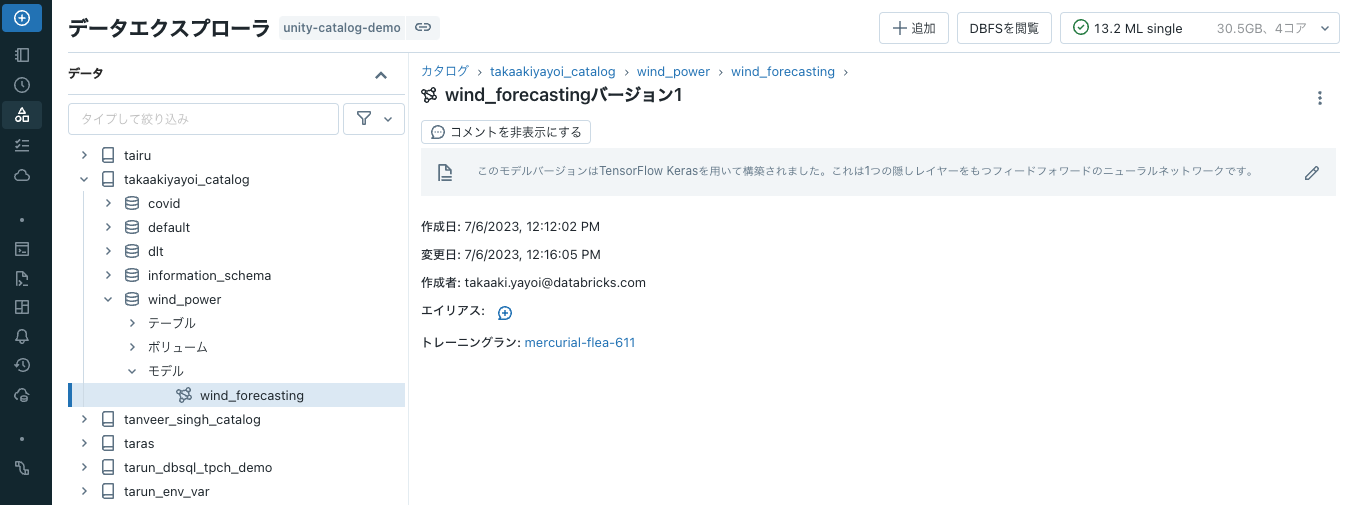
client.update_model_version(
name=MODEL_NAME,
version=1,
description="このモデルバージョンはTensorFlow Kerasを用いて構築されました。これは1つの隠しレイヤーをもつフィードフォワードのニューラルネットワークです。"
)
説明文が追加されます。
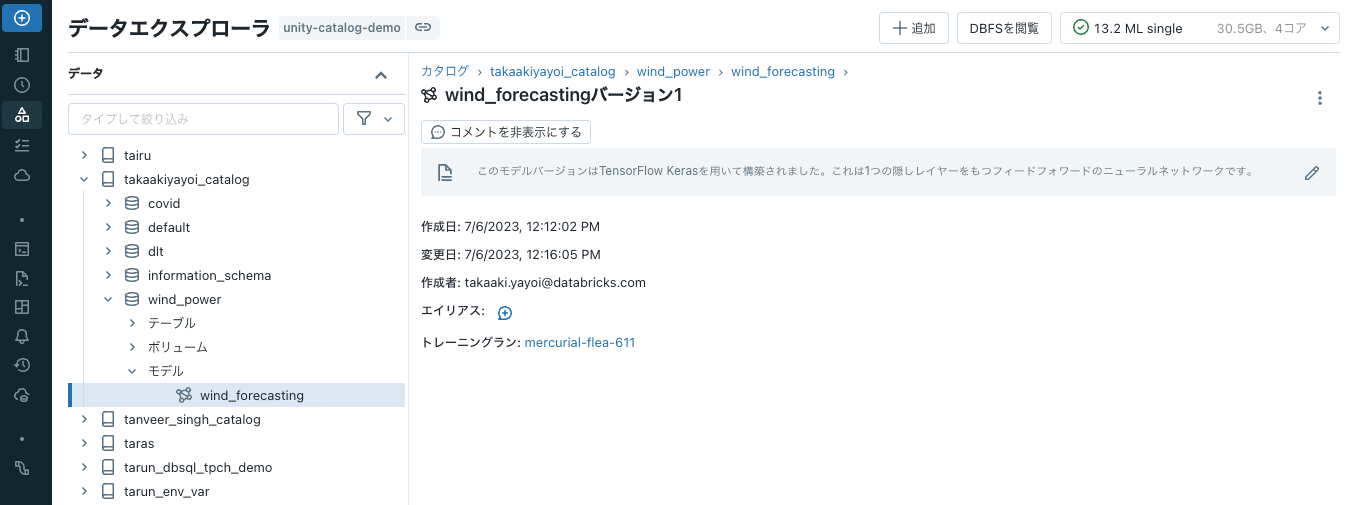
推論のためにモデルバージョンをデプロイ
Unity Catalogのモデルはモデルデプロイメントにおけるエイリアス(AWS|Azure|GCP)をサポートしています。
エイリアスによって、登録モデルの特定のバージョンに変更可能で名前付きの参照(例 「チャンピオン」、「チャレンジャー」)を提供するので、後段の推論ワークフローで参照、ターゲティングすることができます。以下のセルでは、新たにトレーニングしたモデルバージョンに"Champion"エイリアスを割り当てるために、MLflow APIの使い方を示しています。
client = MlflowClient()
latest_version = get_latest_model_version(MODEL_NAME)
client.set_registered_model_alias(MODEL_NAME, "Champion", latest_version)
エイリアスにChampionと表示されます。
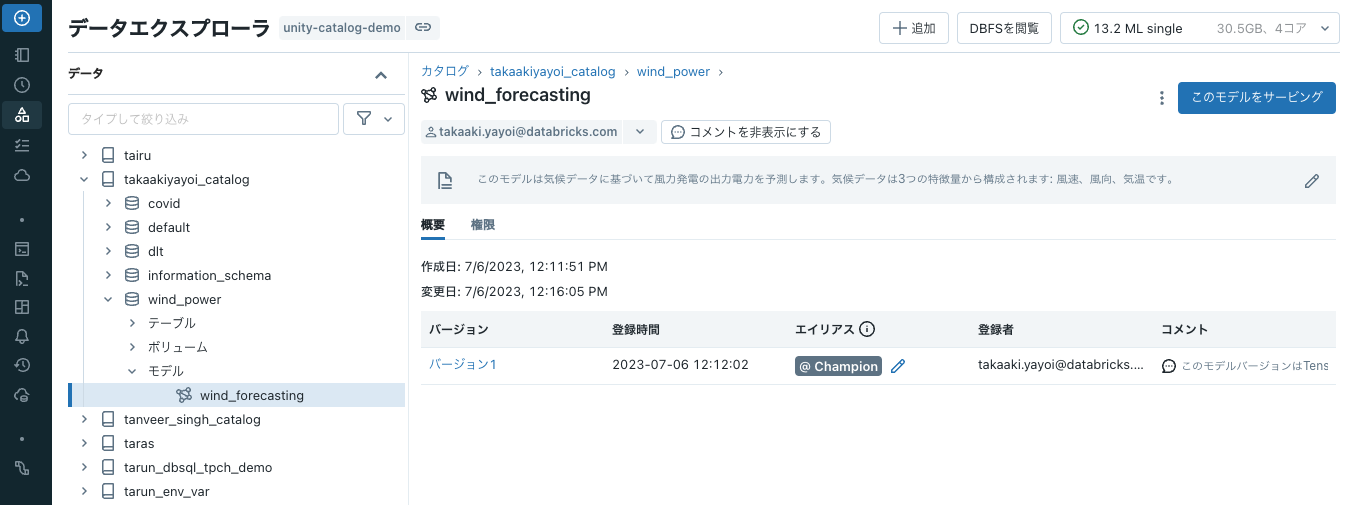
APIを用いたモデルバージョンのロード
MLflowモデルコンポーネントは、いくつかの機械学習フレームワークからのモデルをロードするための関数を定義します。例えば、MLflowフォーマットで保存されたTensorFlowモデルをロードするために、mlflow.tensorflow.load_model()が使用され、MLflowフォーマットで保存されたscikit-learnモデルのロードにmlflow.sklearn.load_model()が使用されます。
これらの関数は、バージョン番号あるいはエイリアスを用いてUnity Catalogのモデルをロードすることができます。
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=MODEL_NAME)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_champion_uri = "models:/{model_name}@Champion".format(model_name=MODEL_NAME)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_champion_uri))
champion_model = mlflow.pyfunc.load_model(model_champion_uri)
Loading registered model version from URI: 'models:/takaakiyayoi_catalog.wind_power.wind_forecasting/1'
/local_disk0/.ephemeral_nfs/envs/pythonEnv-b25cc221-fc0c-4552-a0b9-399443ac71a3/lib/python3.10/site-packages/keras/src/backend.py:452: UserWarning: `tf.keras.backend.set_learning_phase` is deprecated and will be removed after 2020-10-11. To update it, simply pass a True/False value to the `training` argument of the `__call__` method of your layer or model.
warnings.warn(
Loading registered model version from URI: 'models:/takaakiyayoi_catalog.wind_power.wind_forecasting@Champion'
/local_disk0/.ephemeral_nfs/envs/pythonEnv-b25cc221-fc0c-4552-a0b9-399443ac71a3/lib/python3.10/site-packages/keras/src/backend.py:452: UserWarning: `tf.keras.backend.set_learning_phase` is deprecated and will be removed after 2020-10-11. To update it, simply pass a True/False value to the `training` argument of the `__call__` method of your layer or model.
warnings.warn(
チャンピオンモデルを用いた電力出力の予測
このセクションでは、風力発電の気候予測データを評価するためにチャンピオンモデルを使用します。forecast_power()アプリケーションは、指定されたステージから予測モデルの最新バージョンをロードし、次の5日の電力出力を予測するために使用します。
from mlflow.tracking import MlflowClient
def plot(model_name, model_alias, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nwith alias '%s' (Version %d)" % (model_name, model_alias, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_alias):
client = MlflowClient()
model_version = client.get_model_version_by_alias(model_name, model_alias).version
model_uri = "models:/{model_name}@{model_alias}".format(model_name=MODEL_NAME, model_alias=model_alias)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_alias, int(model_version), power_predictions, past_power_output)
forecast_power(MODEL_NAME, "Champion")
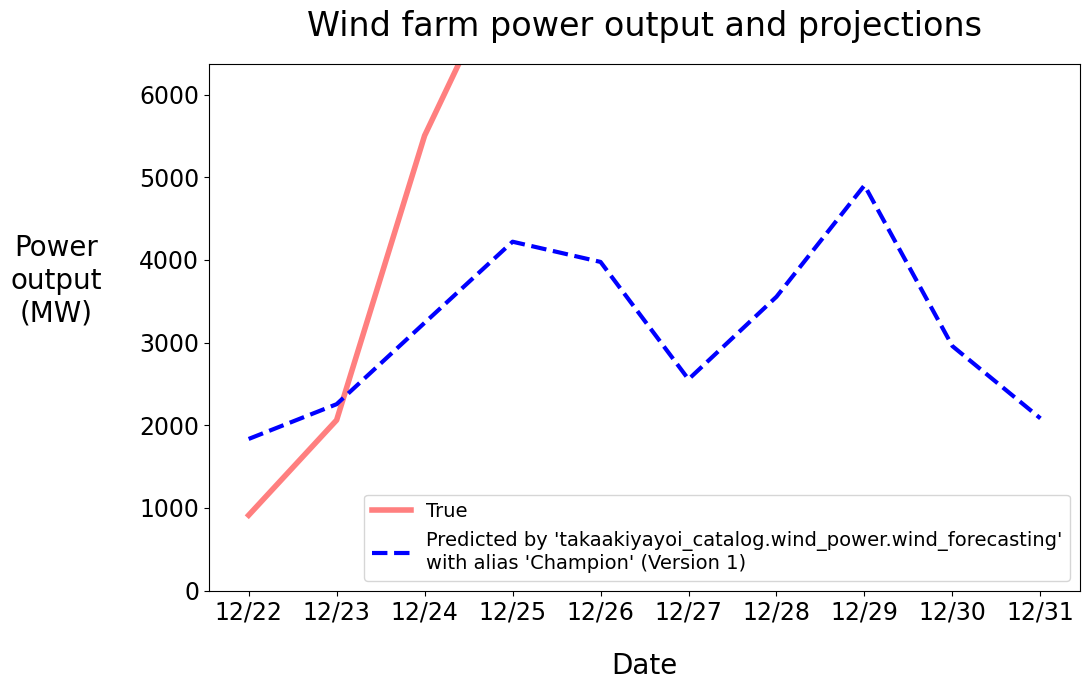
新規モデルバージョンの作成とデプロイ
電力予測では古典的な機械学習テクニックも有効です。以下のコードでは、scikit-learnを用いてランダムフォレストモデルをトレーニングし、mlflow.sklearn.log_model()関数を通じてUnity Catalogに登録しています。
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# <UC>にモデルを登録するために、`mlflow.sklearn.log_model()`関数の`registered_model_name`パラメーターを指定します。
# これによって、自動で新規モデルバージョンが作成されます。
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=MODEL_NAME,
signature=infer_signature(val_x, val_y)
)
新規モデルバージョンに説明を追加
new_model_version = get_latest_model_version(MODEL_NAME)
client.update_model_version(
name=MODEL_NAME,
version=new_model_version,
description="このモデルは、100の決定木を含むランダムフォレストであり、scikit-learnでトレーニングされました。"
)
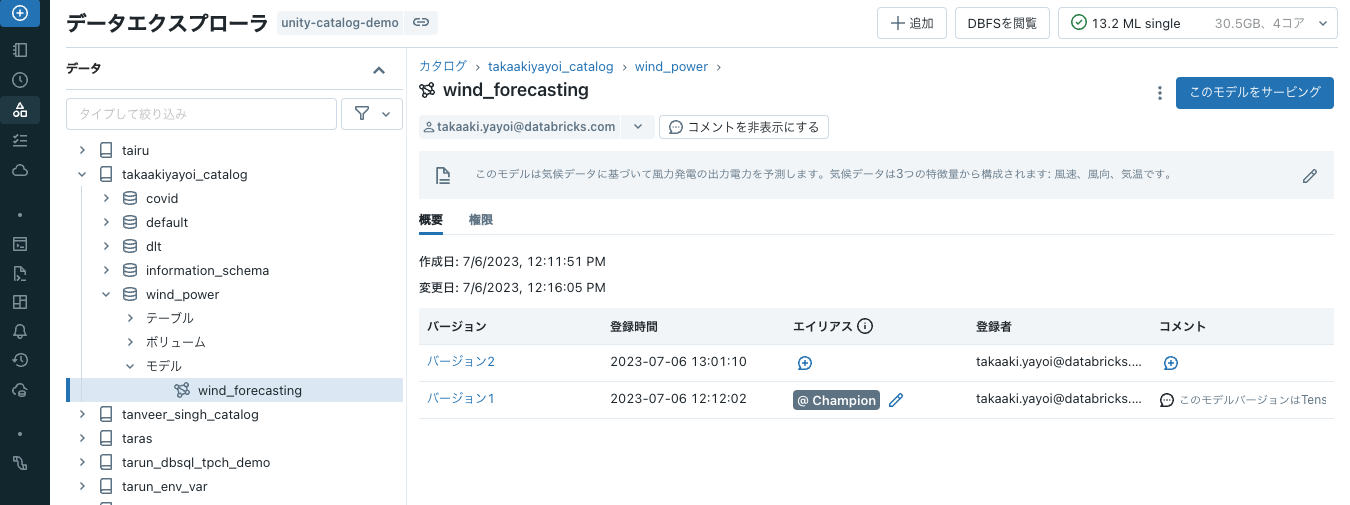
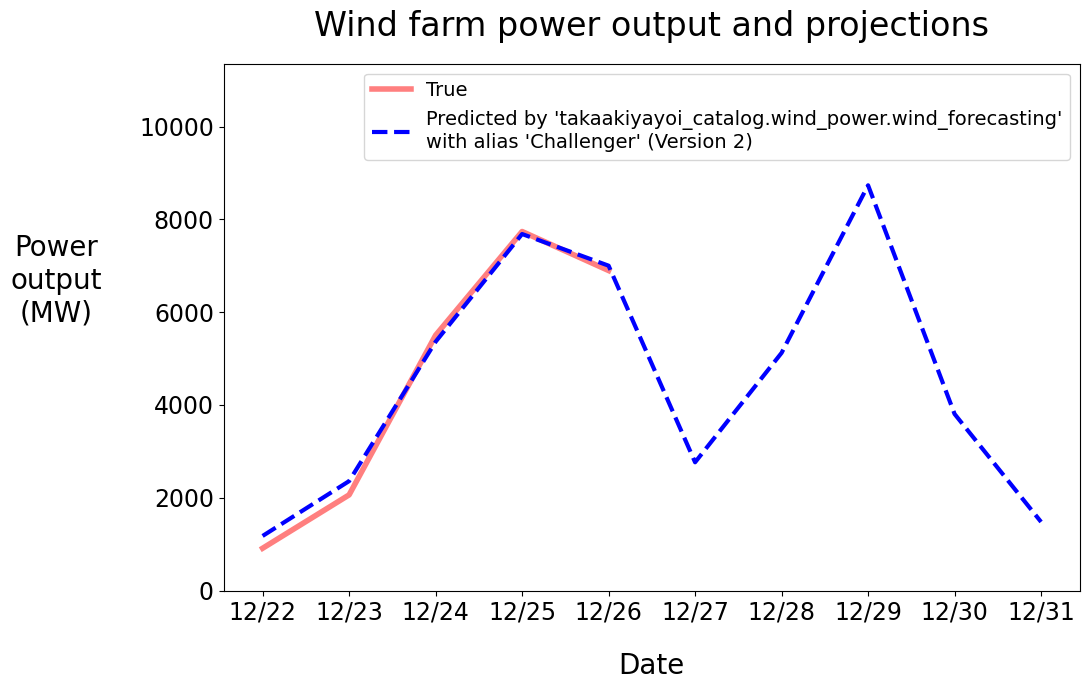
新規モデルバージョンをチャレンジャーとマークしてモデルをテスト
モデルをプロダクションのトラフィックにデプロイする前に、多くの場合、プロダクションデータあるいはトラフィックのサンプルでテストを行うことがベストプラクティスとなります。これまでは、このノートブックはプロダクションワークロードの大部分にサービングしているモデルに"Campion"エイリアスを割り当てていました。以下のコードでは、新規モデルバージョンに"Challenger"エイリアスを割り当てて、パフォーマンスを評価します。
client.set_registered_model_alias(
name=MODEL_NAME,
alias="Challenger",
version=new_model_version
)
forecast_power(MODEL_NAME, "Challenger")
新規モデルバージョンをチャンピオンモデルバージョンとしてデプロイ
テストで新規モデルバージョンが優れたパフォーマンスを示すことを確認した後で、以下のコードでは新規モデルバージョンに"Champion"エイリアスを割り当て、電力予測を行うために、同じforecast_powerアプリケーションを使用します。
client.set_registered_model_alias(
name=MODEL_NAME,
alias="Champion",
version=new_model_version
)
forecast_power(MODEL_NAME, "Champion")
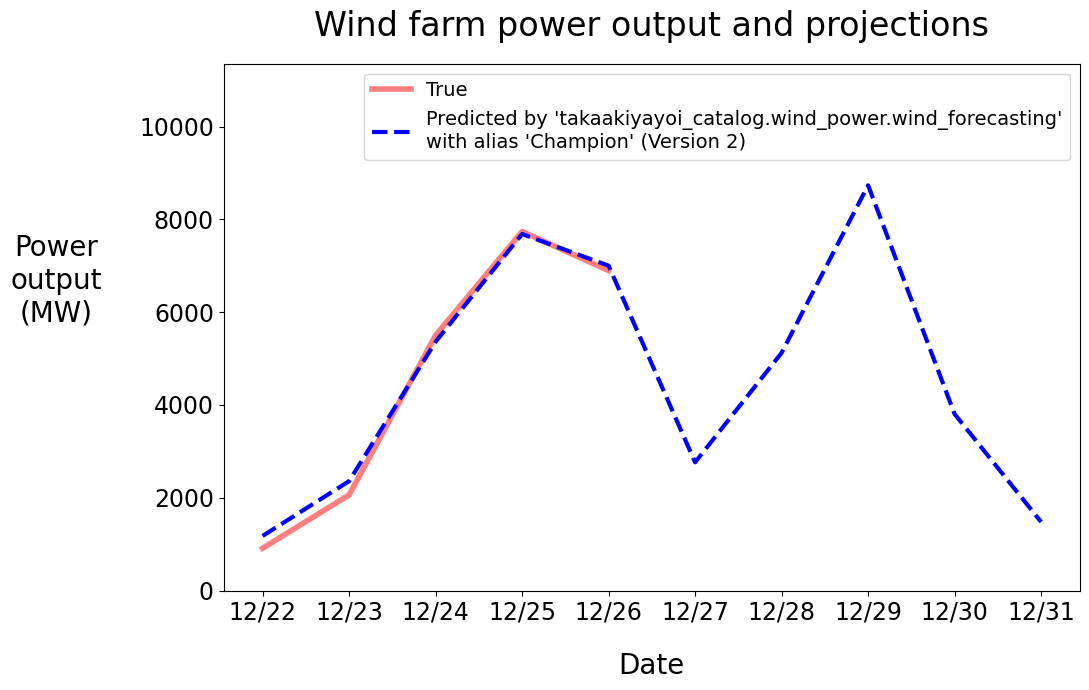
これで、予測モデルの2つのバージョンがあることになります: Kerasモデルでトレーニングされたモデルバージョンとscikit-learnでトレーニングされたバージョンです。"Challenger"エイリアスが新たなscikit-learnに割り当てられたままであり、"Challenger"モデルバージョンをターゲットとする後段のすべてのワークロードが動作し続けることに注意してください。
モデルのアーカイブと削除
モデルバージョンがもう使われなくなった場合には削除することができます。また、登録モデル全体を削除することができます。これによって、関連づけられているすべてのモデルバージョンが削除されます。モデルバージョンの削除によって、モデルバージョンに割り当てられているすべてのエイリアスも削除されることに注意してください。
# モデルバージョンの削除
client.delete_model_version(
name=MODEL_NAME,
version=1,
)
# 登録モデル全体の削除
client = MlflowClient()
client.delete_registered_model(name=MODEL_NAME)
前よりもモデルへのアクセスがシンプルになっていい感じです。